







1.本课题的目的、意义
我国高校研究生教育正在持续向更深层次发展,2024年教育部提出了稳步扩大研究生人才培养规模的目标。为了实现这一目标,各个承担研究生教育服务的部门正在积极采用智能技术,旨在提升研究生培养的效率和服务质量,进而促进研究生培养质量的整体提高。在研究生教育的各个环节中,毕业设计答辩是最后一环,同时也是至关重要的一环,它不仅检验了研究生在专业领域的学习成果,也是研究成果展示和学术交流的重要平台。
智能技术在研究生答辩流程中的应用,不仅优化了答辩过程的组织和管理,提高了工作效率,还通过精准匹配评审专家、智能评估答辩决议等方式,保障了整个答辩环节的专业性和公正性。此外,通过收集和分析答辩过程中的数据,该系统还能够为研究生教育的质量监控和改进提供科学依据,促进研究生教育的持续优化与发展。
2.本课题国内外研究现状
随着我国各大高校的研究生教育日益智能化,为了响应国家教育部号召扩大研究生人才培养规模的目标,各个负责研究生教育的部门正在积极采用各种智能化技术提高教育水平和服务质量。目前智能化技术主要围绕着自然语言处理(NLP)、大语言模型(LLM)、知识图谱、深度学习等展开。在中文分词方面,传统的基于字典和统计的方法如Jieba分词,已广泛应用于工业界。中文分词技术属于自然语言处理技术的子集,中文分词是其他中文信息处理的根基,因此,对中文分词技术在机器翻译、智能问答、文摘生成、舆情分析、知识图谱等应用方面的探究是一个漫长的过程[1]。近年来,基于深度学习的分词方法如双向编码器表征法—条件随机场(BERT-CRF)、中文命名实体识别模型等,进一步提升了分词的精确率,并能有效处理歧义和未登录词[2]。
随着大语言模型的兴起在多种自然语言处理任务并表现出若干涌现能力上取得了显著的成果InstructGPT、ChatGPT、GPT4等自回归大语言模型通过预训练、微调(fine-tuning)等技术理解并遵循人类指令,使其能够正确理解并回答复杂问题[3]。然而,这些模型都存在一些固有的局限性,包括处理中文能力较差,部署困难,无法获得关于最近事件的最新信息以及产生有害幻觉事实等[4]。
与中文相比较而言,英文的分词要相对简单一点。英语分词任务由于英语单词之间一般都是以空格分隔的,所以相对于中文分词来说相对简单一些。在处理衍生词、缩略词、数字和特殊符号时,就需要考虑词形还原、词性标注和句法结构等因素[5]。常用的技术包括正则表达式匹配、动态规划算法以及基于机器学习的方法。近年来,深度学习技术的引入进一步提升了英文分词的性能,尤其是在处理不规则单词和上下文依赖的应用场景中[6]。
关键词抽取是文本处理和信息检索领域中的一个重要研究方向,其目的是从文本中自动识别和提取出能够反映文档主题和核心内容的词语或短语[7]。近年来,随着自然语言处理技术的不断进步,关键词抽取技术也取得了显著的发展如表2-1。关键词抽取主要有传统的TF-IDF算法、DF算法;也有基于图的TextRank算法;还有基于机器学习的通过训练有标签的数据集,使用分类算法(如 SVM、决策树、随机森林等)来识别关键词;还有近年来愈加热门的基于深度学习的方法。
表2-1关键词抽取国外典型的方法[8]
| 研究人员 | 主要工作 |
| Turney P D | Turney提出了基于遗传算法的 |
| Witten I H | Witten提出了基于朴素贝叶斯的关键词自动抽取方法。主要的思路是通过对文本预处理(去除格式、特殊字符、停用词以及大小写转换和词性还原)获取候选关键词,然后计算候选关键词的特征项 |
| Samhaa R | Samhaa通过以标点符号和停用词为词语间隔,抽取词语组成一个序列,以此序列和序列的 |
| Niraj K | Niraj通过 |
3.本课题设计任务与要求
本毕设任务完成基于智能赋能的研究生答辩系统设计与实现。
3.1研究方向相似性答委匹配
研究方向相似性委员匹配是指在给定的研究领域分类体系下,根据研究生的学术论文题目、论文内容等文本内容,通过算法自动分析这些题目的主题、研究方向等信息,从而匹配具有相似研究方向或相关研究背景的答委老师。在传统的委员匹配过程中,通常需要依赖人工判断,这样的方法不仅耗时耗力,而且容易受到个人偏见或信息不足的影响,导致匹配不够精准。随着统计方法和机器学习技术的发展,自动化的研究方向相似性匹配技术逐渐被开发出来,并广泛应用于研究生答辩、科研项目评审、会议论文选择等多个领域。
4.拟采取的技术路线与实验方案
4.1需求分析
(1)系统预计实现的目标
a)提升研究生答辩的效率,通过减少人工所需要的操作,降低答辩组织的时间并且提高答辩安排的合理性
b)提高答辩的整体质量,通过合理匹配答委,并且智能化安排答辩的时间地点等安排,提高答辩整体质量
c)支持多方之间的协作和信息沟通,支持教务、学生、答委之间多角色的相互协作,确保通知信息等可以及时发送。
(2)功能设计需求(功能结构如图4-1)
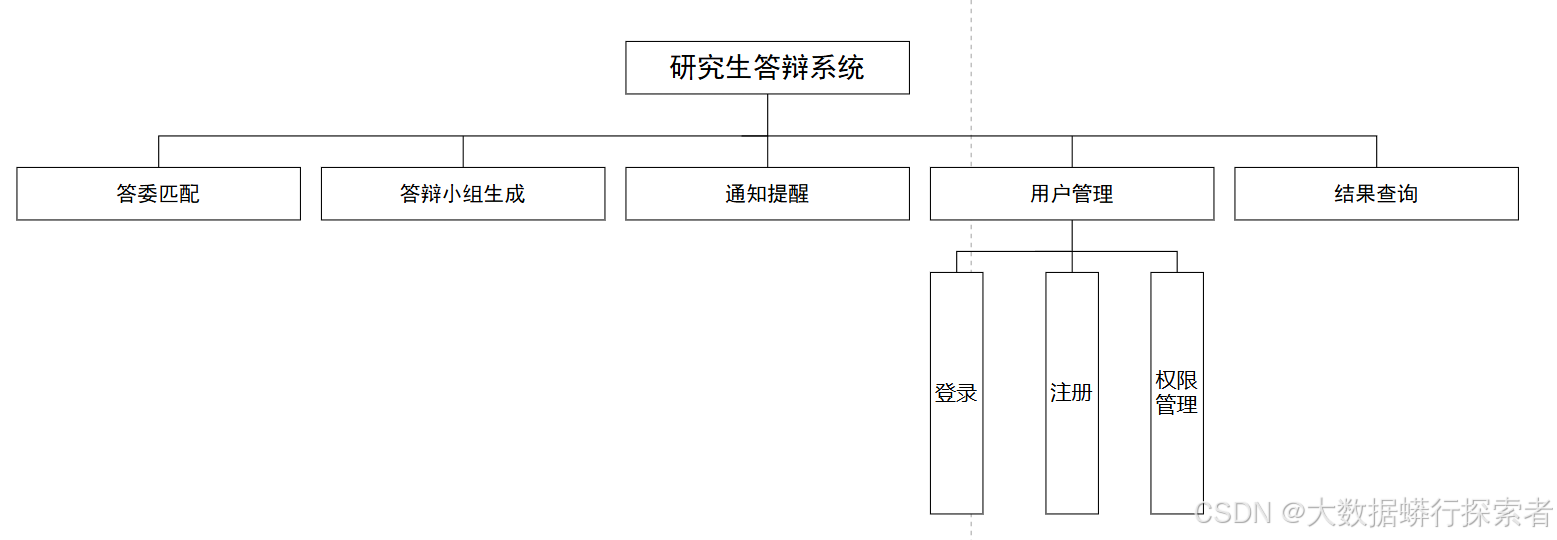
图4-1:系统功能结构图
a)答委匹配:通过对于历史数据的分析,获取到每一个老师涉及的研究方向,通过分析论文题目以及每一个研究生的研究方向进行相似度计算匹配,将相似度较高的老师匹配成为答委,进而使得答辩更加合理高效。
b)答辩小组生成:根据研究生(答辩学生)可用时间、答委时间偏好、答辩地点容量等约束条件自动生成答辩日程安排。同时通过遗传算法对于日程安排进行优化,获得全局最优解,进而提高答辩的效率。
c)用户管理:系统支持多种不同角色注册、登录,并且根据角色的不同给予不同的权限。
d)结果查询:学生可以查看答辩安排、答辩结果,教务部门可以查看所有答辩结果。
f)通知提醒:系统可以根据答辩日程安排,发送答辩安排的通知、答辩结果等消息供使用者及时查看。
(3)非功能设计需求
a)系统性能:系统需要具备良好的响应速度和高可用性,在正常操作的情况下系统响应时间应该少于2秒,在答辩日程安排、答委匹配这几个关键性功能中响应时间不应超过5秒,能够有效保证系统的稳定性。
b)可靠性需求:系统需要具备完善的安全机制,保护用户数据和文档的安全,同时系统应该定期数据备份涵盖多方面信息,并且在发生故障时可以及时恢复到最近备份的状态。
c)用户体验:系统界面设计简洁明了,对于用户友好,操作简单,符合用户习惯,尽可能减少用户的学习成本,提高用户体验。
d)合规性:系统设计需要符合教育部和学校的各项规定和标准,遵守有关法律法规,确保用户在使用过程中的个人信息不被泄露,用户个人信息仅用于系统服务所需范围,禁止任何未经授权的第三方使用和访问。
项目的技术路线图如图4-2
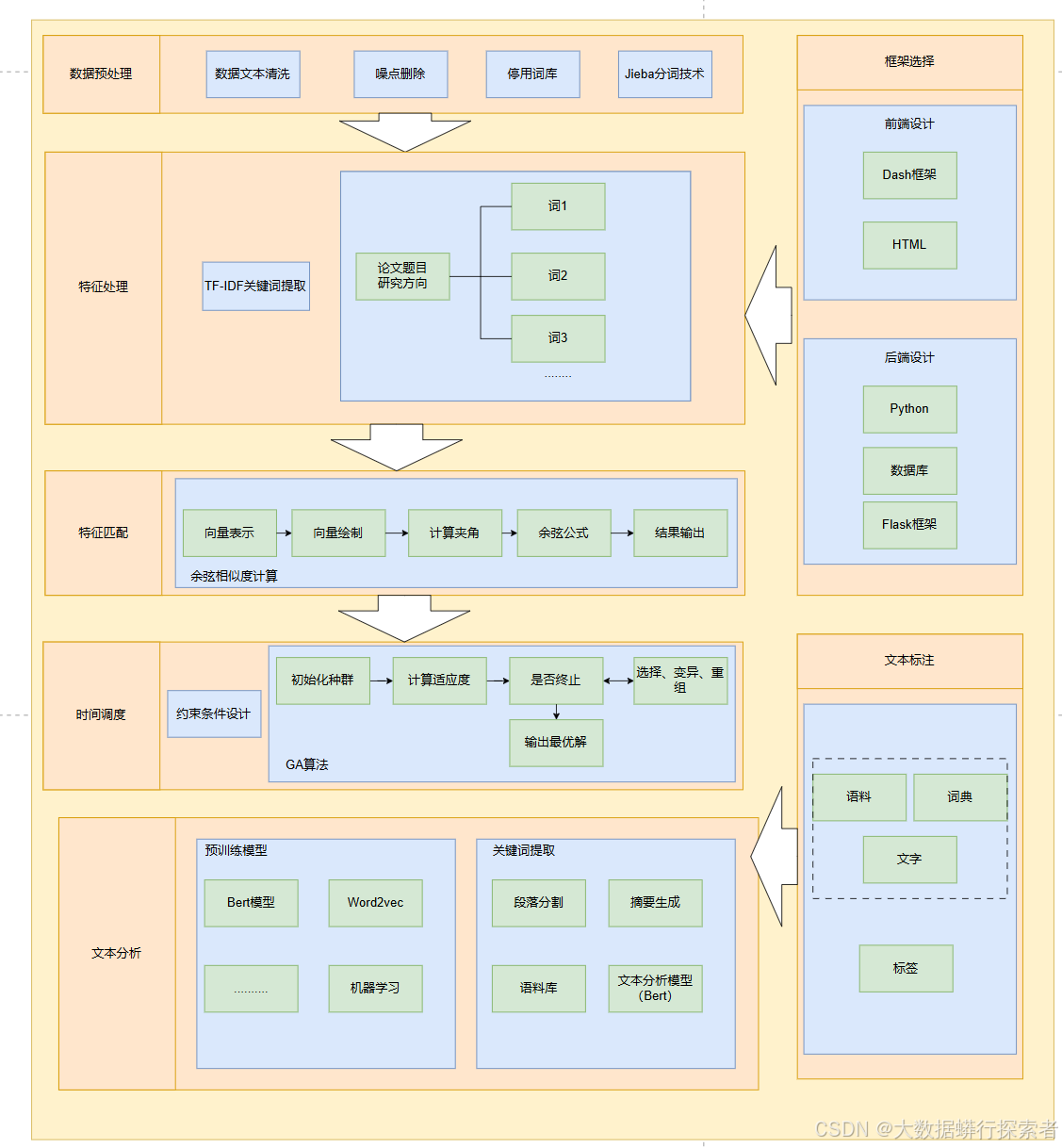
图4-2:技术路线图
4.2数据预处理
对研究生的研究方向和答辩委员的研究领域进行预处理,包括:文本清洗、分词、去除停用词。其中中文分词与英文分词存在差异,由于中文文本中词语之间没有明显的界限标志,因此这一任务对计算机来说极具挑战性,而英文分词需要考虑词形还原、词性标注和句法结构等因素
a)数据文本清洗
数据文本清洗的主要目标是将已经准备好的原始数据进行处理使其转换成为更干净、更结构化的格式。主要的方式是降噪:去除无关的字符以及标点符号;标准化:统一文本的格式包括大小写、将缺失的数据进行补全等
b)分词
通过Jieba分词,将研究方向以及题目中的文本内容,切分成单词或者字典中存在的词组,同时新增自定义词典来添加Jieba词库中不存在的词提高辨识能力。虽然jieba具有对新的词汇进行辨别的能力, 但单独添加这些词可以确保更高的正确率, 还能够解决未登录词的问题, 然而人们对分词技术和汉语结构的理解程度也会影响着自定义词典的准确度[13]。
c)引入停用词
停用词通常不携带具体的意义,去除它们可以使模型更关注那些对文本意义有重要贡献的词汇。停用词在很多数据中都会出现,例如“的”、“和”等,它们的出现对区分不同文本内容帮助不大,去除这些词汇可以减少噪声,提高模型的区分能力。
4.3特征处理与匹配
a)特征处理
通过TF-IDF进行关键词抽取,将题目以及研究方向中的关键词进行抽取,计算出每一个词在数据中出现的次数![]() 以及逆向文件频率
以及逆向文件频率![]() ,确定为关键词,之后根据TF-IDF值
,确定为关键词,之后根据TF-IDF值![]() 对关键词进行排序,选取排名靠前的若干个词作为主要关键词[14]
对关键词进行排序,选取排名靠前的若干个词作为主要关键词[14]
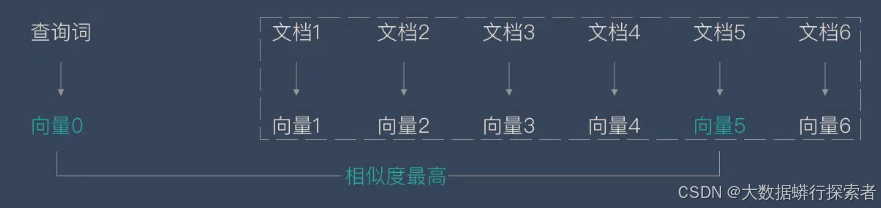
图4-3:TF-IDF算法图解
b)特征匹配
利用余弦相似度将研究方向、论文题目进行相似度计算匹配,将题目、研究方向和答辩委员的研究领域转换成向量形式。使用余弦相似度公式计算向量之间的相似度。根据相似度得分进行答委匹配,确保匹配结果的准确性和公正性[15]
4.4时间调度
将答辩日程安排问题建模为优化问题,考虑时间、地点、答辩委员等约束条件
a)约束条件设计
答辩人(研究生)可用时间:获取每个答辩研究生的可用时间。
答委偏好设置:获取每一个答委老师的偏好时间进行记录(如:不希望周一有安排、一般希望是上午等)
地点安排:安排答辩的地点,考虑该地点的容量等是否符合需求
b)遗传算法(GA)
优化研究生答辩日程安排,确保在综合考虑多方面因素的情况下,生成高效、合理且可行的安排方案,遗传算法结构如图4-4,通过模拟自然选择和遗传机制,随机生成初始种群,并通过选择、交叉和变异等操作不断优化种群。利用这种机制能够避免陷入局部最优解,提高找到全局最优解的概率
初始化种群:生成初始的答辩日程安排方案。
适应度函数:定义适应度函数,评估每个安排方案的优劣。适应度函数可以考虑以下因素:
时间冲突:避免同一时间多个答辩安排。
地点冲突:避免同一地点同时进行多个答辩。
答委时间偏好:满足答委的时间偏好。
答辩安排的均匀性:尽量将答辩安排均匀分布,避免某些时间段过于集中。
选择、交叉和变异:通过选择、交叉和变异操作生成新的安排方案。
迭代优化:多次迭代,逐渐优化答辩安排方案,直至达到满意的结果。
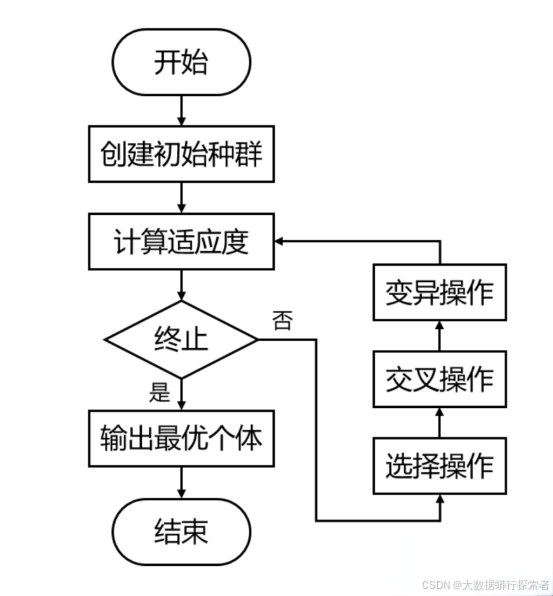
图4-4:遗传算法结构
4.5文本分析
文本分析技术在处理论文摘要时非常重要,因为在论文之中通常包含丰富的信息和复杂的结构。文本分析的目标是从大量的文本数据中提取有意义的信息。
1)预处理
在前文提到的基础之上增加段落和句子分割,将长文本分割成段落和句子,以便后续的处理;关键词提取,从文本中提取重要的关键词和短语,这些关键词可以作为文本特征的一部分,帮助模型更好地理解文本;增强实体识别,识别文本中的命名实体,如人名、地名、组织名等;生成文本的摘要,以减少分析的体积,同时保留核心信息。
2)选择预训练模型
预计会选择BERT模型:BERT 是一种基于 Transformer 的预训练语言模型,可以用于多种自然语言处理任务,包括文本分析,之后通过微调预训练的 BERT 模型,使其可以较好地对论文摘要的内容有一个进一步的了解更好有助于文本的分类处理。
4.6预计使用模型框架
1)后端开发:Flask框架
Flask作为一个轻量级框架其基本框架如图4-5,Python Flask基于Python实现,简单易学,扩展性极高,采用的MVC构架也非常符合软件设计的原则,它不仅支持常规的网页设计,还支持小程序等多种形式的网络应用设计[17-18]。
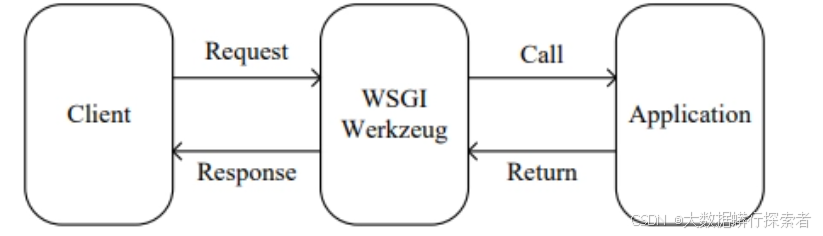
图4-5:Flask框架工作示意图
2)前端开发:Dash框架
Dash是一个高效简洁的Python框架,建立在Flask、Poltly.js以及React.js的基础上,以纯Python编程的方式快速开发出交互式的数据可视化web应用[19]。Dash更加灵活,适合构建复杂的用户界面,可以集成多种数据可视化工具。
5.预期成果
(1)智能技术实现
实现研究方向相似性答委匹配功能:通过智能化的方法为答辩学生匹配最适合的答辩委员会委员;答辩日程安排:能够根据参与答辩的各方需求和限制,自动生成最优的答辩排程;实现对论文摘要或创新点分类:能够有效根据提交的论文,从论文的摘要之中内容研究方向或创新点进行分类。
(2)实现各模块基础功能与系统测试
区分不同角色在系统之中所拥有的不同权限以及可以使用的不同功能,确保系统功能的完整性。完成系统的编写、调试、测试和优化,确保系统的稳定性和可靠性,满足实际使用过程中的需求。
(3)完成论文攥写
按照要求按时按量完成《基于智能技术赋能的研究生答辩系统设计与实现》论文,按照开发流程以及使用到的技术等给出一个完整的总结,对思路和使用到的关键技术与模型给出阐述与解释说明。
(4)完成不少于10000字符的英文文献阅读
英文文献在技术研究领域占据着举足轻重的地位,尤其是在前沿科技和创新领域,许多突破性的研究成果和技术进展往往首先发表在英文文献中。因此,具备英文文献的翻译能力是获取最新技术信息、跟踪国际研究动态的关键途径。在毕业设计过程中,阅读英文文献不仅有助于深入理解研究背景和技术细节,还能为项目的创新提供理论支持和实践参考。
参考文献
王朝辉.基于Flask框架的测试集成系统设计与实现[J].科技创新与应用,2024,14(33):115-118.DOI:10.19981/j.CN23-1581/G3.2024.33.028.
- 史国举;.基于Python的中文分词技术探究[J].无线互联科技,2021,(23):116-117.
- 祝永志;荆静;.基于Python语言的中文分词技术的研究[J].通信技术,2019,(07):70-77.
- 马伟民.自然语言大模型技术在政务服务智能客服系统建设中的应用[J].信息与电脑(理论版),2024,36(8):86-88.
- WANG Y, KORDI Y, MISHRA S, et al. Self-Instruct:aligning language model with self generated instructions[J].arXiv:2212.10560, 2022.
- GUU K, LEE K, TUNG Z, et al. Retrieval augmented language model pre-training[C]//Proceedings of the 37th International Conference on Machine Learning, Vienna, Jul 12-18, 2020. New York:PMLR, 2020:3929-3938.
- 高群.一种设备端中英分词算法的设计与实现[J].电脑知识与技术,2024,20(16):19-22.DOI:10.14004/j.cnki.ckt.2024.0815.
- 严明, 郑昌兴.Python环境下的文本分词与词云制作[J].现代计算机 (专业版) , 2018 (34) :86-89.YAN Ming, ZHENG Chang-xing.Word Segmentation and Word Cloud Production in Python Environment[J].Modern Computer, 2018 (34) :86-89.
- 肖根胜.改进TF-IDF和谱分割的关键词自动抽取方法研究[D].华中师范大学,2012.
- 方俊,郭雷,王晓东.基于语义的关键词提取算法[J].计算机科学,2008,(06):148-151.
- 赵鹏,蔡庆生,王清毅,等.一种基于复杂网络特征的中文文档关键词抽取算法[J].模式识别与人工智能,2007,20(06):827-831.
- 章成志.自动标引研究的回顾与展望[J].现代图书情报技术,2007,(11):33-39.
- 赵磊.考虑篇章结构和自动摘要的学术论文关键词抽取研究[D].南京理工大学,2023.DOI:10.27241/d.cnki.gnjgu.2023.000391.
- 江华丽.中文分词算法研究与分析[J].物联网技术,2016,6(01):87-89.DOI:10.16667/j.issn.2095-1302.2016.01.030.
- 邵泽明,李宇昂,杨可,等.基于改进TF-IDF算法的用户画像构建方法研究(英文)[J].印刷与数字媒体技术研究,2024,(06):110-116.DOI:10.19370/j.cnki.cn10-1886/ts.2024.06.014.
- 胡雪,赵佳英.基于余弦相似度的内容比对程序设计与实现[J].电脑知识与技术,2024,20(27):42-44+55.DOI:10.14004/j.cnki.ckt.2024.1391.
- Doneva E S ,Qin S ,Sick B , et al.Large language models to process, analyze, and synthesize biomedical texts: a scoping review[J].Discover Artificial Intelligence,2024,4(1):107-107.
- 李超,徐云龙,华中伟,等.一种基于Python Flask的Web服务器端设计[J].信息与电脑(理论版),2019,(08):87-88.
- 肖曼,曾狄仪,袁小语,等.基于Flask框架的“珠游”系统[J].现代计算机,2024,30(17):112-116.




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











