







数据结构之哈希
什么是哈希
哈希结构(Hash Table)也被称为散列表,是一种用于实现字典(Dictionary)的数据结构。哈希结构将键(Key)映射到值(Value)的过程称为哈希(Hashing),哈希函数(Hash Function)用于将键映射到一个固定大小的数组(Hash Table),数组中的每个元素称为桶(Bucket),每个桶可以存储一个或多个键值对。哈希结构的主要优点是可以在常数时间内进行插入、查找和删除操作,因此在大多数情况下,哈希结构的操作效率非常高。
哈希构造函数
哈希构造函数(Hash Constructor)是哈希结构中的一种函数,用于将键(Key)映射到哈希表中的位置。哈希构造函数通常是一个确定性函数,即对于相同的键,哈希构造函数总是返回相同的哈希值。哈希构造函数的设计非常关键,它直接影响哈希结构的查找、插入和删除等操作的效率。
哈希构造函数的设计需要满足以下几个要求:
-
一致性:对于相同的键,哈希构造函数应该总是返回相同的哈希值。
-
均匀性:哈希构造函数应该尽可能均匀地将键映射到哈希表中的位置,以避免哈希冲突。
-
高效性:哈希构造函数的计算时间应该尽可能短,以提高哈希结构的操作效率。
哈希构造函数的设计方法有很多种,常见的方法包括:
-
直接寻址法(Direct Addressing):将键直接作为哈希表中的位置,适用于键的范围比较小的情况。
-
除留余数法(Division Method):将键除以一个不大于哈希表大小的质数,然后取余数作为哈希值。
-
乘法哈希法(Multiplicative Hashing):将键乘以一个常数A(0<A<1),然后取乘积的小数部分乘以哈希表大小作为哈希值。
-
一次探测法(Linear Probing):当发生哈希冲突时,依次向后探测空桶,直到找到空桶或者遍历整个哈希表。
-
双重哈希法(Double Hashing):使用两个不同的哈希函数,当发生哈希冲突时,依次使用两个哈希函数计算出新的哈希值,直到找到空桶或者遍历整个哈希表。
选择合适的哈希构造函数需要考虑键的特点、哈希表的大小、哈希冲突的处理方法等因素,通常需要进行实验和分析来确定最优的哈希构造函数。
哈希冲突
哈希冲突(Hash Collision)指的是不同的键(Key)被哈希构造函数映射到了哈希表中的同一个位置,导致这些键在哈希表中发生了冲突。哈希冲突是哈希结构中的一个常见问题,如果不能很好地处理哈希冲突,就会导致哈希表的操作效率下降,甚至无法正常工作。
哈希冲突的发生是由于哈希构造函数的设计不够均匀,或者键的数量太多,而哈希表的大小又不够大。当哈希冲突发生时,需要采取一定的处理方法,以解决哈希冲突。常见的哈希冲突处理方法包括:
-
链表法(Chaining):将哈希表中的每个桶改为一个链表,当发生哈希冲突时,将新的键值对插入到链表的末尾。
-
开放地址法(Open Addressing):当发生哈希冲突时,依次向后探测空桶,直到找到空桶或者遍历整个哈希表。
-
再哈希法(Rehashing):当哈希冲突发生时,使用另一个哈希函数计算出新的哈希值,然后将键值对插入到新的哈希表中。
选择合适的哈希冲突处理方法需要考虑具体的应用场景和数据特点,通常需要进行实验和分析来确定最优的处理方法。
数组哈希图示
-
数组存储
-
取余法哈希函数
-
开放地址法处理冲突
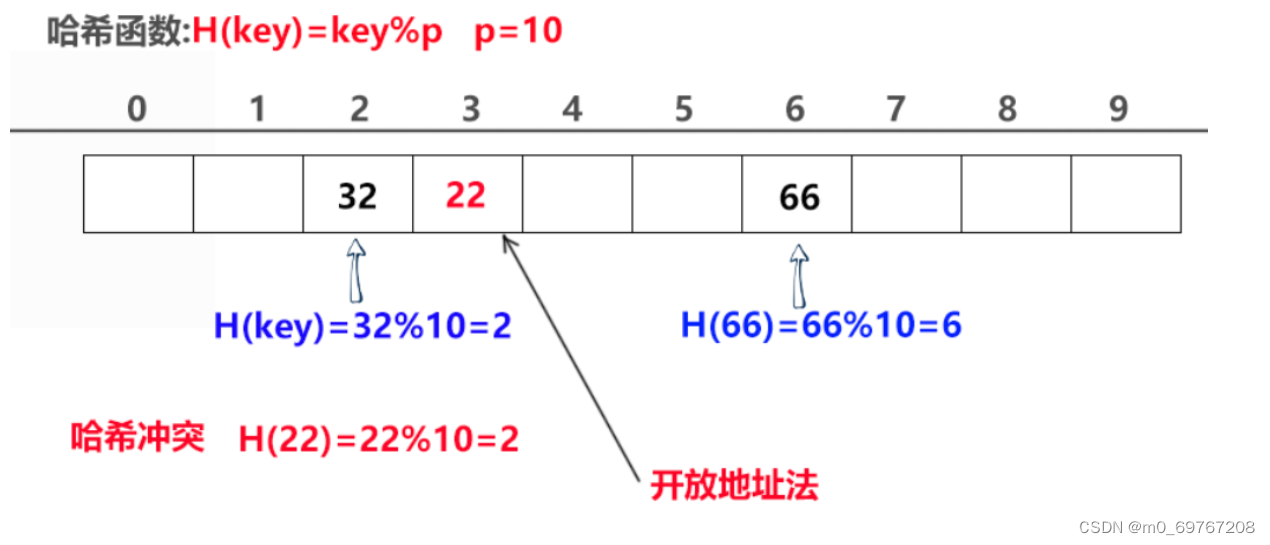
散列存储图示
-
链表存储
-
取余法哈希函数
-
链表法处理冲突
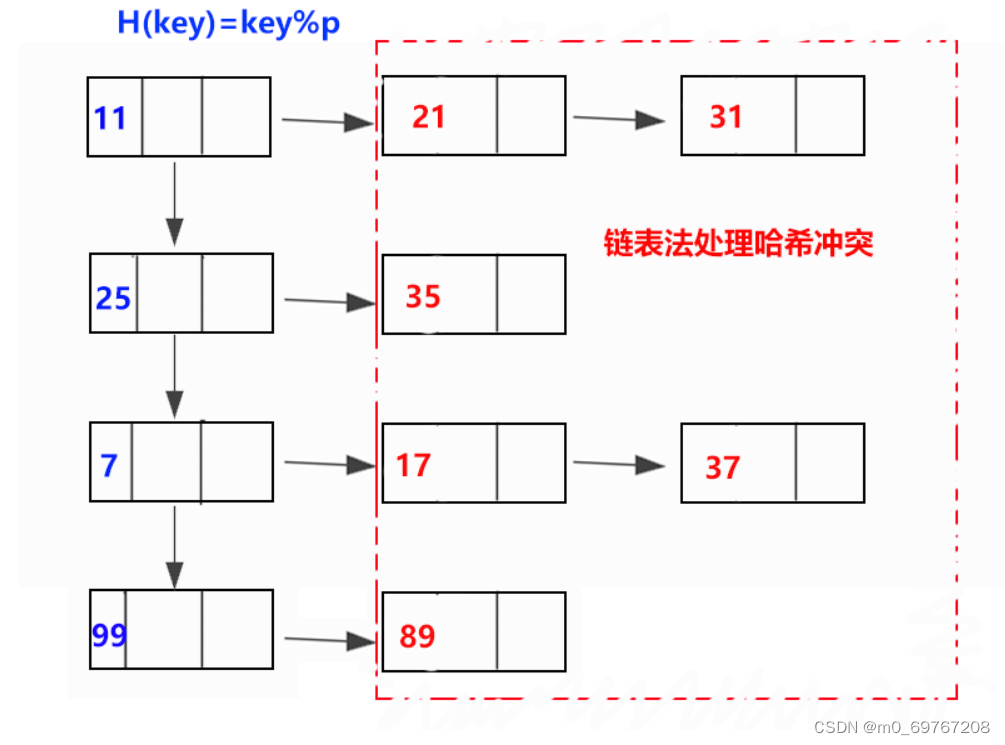
使用数组实现哈希表
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <stdbool.h>
#include <string.h>
//没有键的数据可以构建一个键处理
typedef struct pair //键的数据和键值
{
int key;
char str[20];
}Data;
typedef struct HashTable //创建哈希表
{
Data** table;//用二级指针方便赋初值,没有的话直接置为空
int divisor; //h(key)=key%p
int count;
}Hash;
Hash* create_hash(int p) //传入总长度
{
Hash* hash = (Hash*)calloc(1, sizeof(Hash));//创建并初始化为0
assert(hash);
hash->divisor = p;
hash->count = 0;
hash->table = (Data**)calloc(hash->divisor, sizeof(Data*));
assert(hash->table);
return hash;
}
int get_hash(Hash* hash, int key) //获取哈希地址
{
int pos = key % hash->divisor;
int curPos = pos;//哈希的键值
do
{
if (hash->table[curPos] == NULL || hash->table[curPos]->key == key) //哈希表该位置数据为空,或者数据相同
{
return curPos;
}
curPos = (curPos + 1) % hash->divisor;
} while (pos != curPos);//没有返回到自身
return curPos;//返回自身值 (转了一圈没有空位)
}
void push_hash(Hash* hash, Data data) //入栈
{
int pos = get_hash(hash, data.key);
if (hash->table[pos] == NULL) //为空
{
hash->table[pos] = (Data*)calloc(1, sizeof(Data));
memcpy(hash->table[pos], &data, sizeof(Data));//空数据进行内存申请
hash->count++;
}
else
{
if (hash->table[pos]->key == data.key) //建相同进行覆盖
{
strcpy_s(hash->table[pos]->str, 20, data.str);
}
else //键是满的
{
printf("Hash is Full\n");
return;
}
}
}
void print_hash(Hash* hash)
{
for (int i = 0; i < hash->divisor; i++)
{
if (hash->table[i] == NULL)
{
printf("%d:NULL\n",i);
}
else
{
printf("%d:[%d,%s]\n", i, hash->table[i]->key, hash->table[i]->str);
}
}
}
int search_hash(Hash* hash, int key)
{
int pos = key % hash->divisor;
int curPos = pos;
do
{
if (hash->table[curPos] == NULL)
{
return -1;
}
else if (hash->table[curPos]->key == key)
{
return curPos;
}
curPos = (curPos + 1) % hash->divisor;
} while (pos != curPos);
return -1;
}
int main()
{
Hash* hash = create_hash(10);
Data arr[7] = { 1,"小美",11,"小芳",25,"小小",46,"baby",78,"花花",25,"coco",21,"明明"};
for (int i = 0; i < 7; i++)
{
push_hash(hash, arr[i]);
}
print_hash(hash);
int result = search_hash(hash,1);
printf("result:%d\n", result);
result = search_hash(hash, 11);
printf("result:%d\n", result);
result = search_hash(hash, 21);
printf("result:%d\n", result);
result = search_hash(hash, 31);
printf("result:%d\n", result);
return 0;
}
链表哈希实现
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#include <string.h>
#include <assert.h>
typedef struct pair
{
int key;
char str[20];
}Data;
//横向链表
typedef struct Node
{
Data data;
struct Node* next;
}Node;
Node* create_node(Data data)
{
Node* newNode = (Node*)calloc(1, sizeof(Node));
assert(newNode);
newNode->data = data;
return newNode;
}
//纵向链表 (存储键值相同的)
typedef struct SkipListNode
{
Data data;
Node* headNode;
struct SkipListNode* next;
}SNode;
SNode* create_snode(Data data) //纵向链表结构创建
{
SNode* newNode = (SNode*)calloc(1, sizeof(SNode));
assert(newNode);
newNode->data = data;
return newNode;
}
//hash结构
typedef struct HashTable
{
SNode* headNode;
int count;
int divisor;
}Hash;
enum Type {No,SKips,Nodes};
typedef struct smatch
{
enum Type flag; //false: snode true=node
union
{
Node* p;
SNode* ps;
};
}smatch;
Hash* create_hash(int p)
{
Hash* hash = (Hash*)calloc(1, sizeof(Hash));
assert(hash);
hash->divisor = p;
return hash;
}
void push_hash(Hash* hash,Data data)
{
int pos = data.key % hash->divisor;
SNode* snode = create_snode(data);
if (hash->headNode == NULL)
{
hash->headNode = snode;
hash->count++;
}
else
{
SNode* pmove = hash->headNode;
SNode* premove = NULL;
//1.插入数据的哈希地址小于头节点
if (pmove->data.key % hash->divisor > pos)
{
//无表头链表的表头法插入
snode->next = hash->headNode;
hash->headNode = snode;
hash->count++;
}
else
{
//找第一次大于或者等于插入数据的哈希地址
while (pmove != NULL && ((pmove->data.key % hash->divisor) < pos))
{
premove = pmove;
pmove = premove->next;
}
//分析退出循环结果
if (pmove != NULL && ((pmove->data.key % hash->divisor) == pos))
{
//存在冲突
if (pmove->data.key == data.key)
{
//覆盖的方式处理键是一样的数据
strcpy_s(pmove->data.str, 20, data.str);
}
else
{
//横向链表
Node* newNode = create_node(data);
Node* ppmove = pmove->headNode;
if (ppmove == NULL)
{
//插入节点成为新表头
newNode->next = pmove->headNode;
pmove->headNode = newNode;
hash->count++;
}
else
{
//检查横向链表是否存在相同键的数据
while (ppmove != NULL && ppmove->data.key != data.key)
{
ppmove = ppmove->next;
}
if (ppmove == NULL)
{
//插入节点成为新表头
newNode->next = pmove->headNode;
pmove->headNode = newNode;
hash->count++;
}
else
{
strcpy_s(ppmove->data.str, 20, data.str);
}
}
}
}
else
{
//不存在冲突直接连接到纵向链表中即可
premove->next = snode;
snode->next = pmove;
hash->count++;
}
}
}
}
void print_hash(Hash* hash)
{
SNode* pmove = hash->headNode;
while (pmove != NULL)
{
printf("[%d,%s]:\t", pmove->data.key, pmove->data.str);
Node* ppmove = pmove->headNode;
while(ppmove!=NULL)
{
printf("[%d,%s]\t", ppmove->data.key, ppmove->data.str);
ppmove = ppmove->next;
}
printf("\n");
pmove = pmove->next;
}
}
int size_hash(Hash* hash)
{
return hash->count;
}
bool empty_hash(Hash* hash)
{
return hash->count == 0;
}
smatch search_hash(Hash* hash, int key)
{
smatch result = {0};
if (hash == NULL)
return result;
SNode* pmove = hash->headNode;
int pos = key % hash->divisor;
while (pmove != NULL && (pmove->data.key%hash->divisor) != pos)
{
pmove = pmove->next;
}
if (pmove == NULL)
return result;
else
{
if (pmove->data.key == key)
{
result.flag = SKips;
result.ps = pmove;
return result;
}
else
{
Node* ppmove = pmove->headNode;
while (ppmove != NULL && ppmove->data.key != key)
{
ppmove = ppmove->next;
}
if (ppmove == NULL)
{
return result;
}
else
{
result.flag = Nodes;
result.p = ppmove;
return result;
}
}
}
}
void print_result(smatch data)
{
switch (data.flag)
{
case No:
printf("未找到指定数据!\n");
break;
case SKips:
printf("[%d,%s]\n", data.ps->data.key, data.ps->data.str);
break;
case Nodes:
printf("[%d,%s]\n", data.p->data.key, data.p->data.str);
break;
}
}
int main()
{
Hash* hash = create_hash(10);
Data arr[10] = { 1,"小美",11,"小芳",25,"小小",46,"baby",78,"花花",
25,"coco",21,"明明",11,"妹妹",56,"小爱",45,"小雪"};
for (int i = 0; i < 10; i++)
{
push_hash(hash, arr[i]);
}
print_hash(hash);
printf("----------------------\n");
smatch result = search_hash(hash, 46);
print_result(result);
print_result(search_hash(hash, 11));
return 0;
}















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









