







⭐博客主页:️CS semi主页
⭐欢迎关注:点赞收藏+留言
⭐系列专栏:C++初阶
⭐代码仓库:C++初阶
家人们更新不易,你们的点赞和关注对我而言十分重要,友友们麻烦多多点赞+关注,你们的支持是我创作最大的动力,欢迎友友们私信提问,家人们不要忘记点赞收藏+关注哦!!!
vector
前言
vector是一个和string类似,但比string高级又难理解的新的知识,我们本次仅仅讲解vector的使用,而模拟实现身临其境一下我将会在接下来的章节中进行重新讲解。
一、vector的介绍
- vector是表示可变大小数组的序列容器。
- 就像数组一样,vector也采用的连续存储空间来存储元素。也就是意味着可以采用下标对vector的元素进行访问,和数组一样高效。但是又不像数组,它的大小是可以动态改变的,而且它的大小会被容器自动处理。
- 本质讲,vector使用动态分配数组来存储它的元素。当新元素插入时候,这个数组需要被重新分配大小为了增加存储空间。其做法是,分配一个新的数组,然后将全部元素移到这个数组。就时间而言,这是一个相对代价高的任务,因为每当一个新的元素加入到容器的时候,vector并不会每次都重新分配大小。
- vector分配空间策略:vector会分配一些额外的空间以适应可能的增长,因为存储空间比实际需要的存储空间更大。不同的库采用不同的策略权衡空间的使用和重新分配。但是无论如何,重新分配都应该是对数增长的间隔大小,以至于在末尾插入一个元素的时候是在常数时间的复杂度完成的。
- 因此,vector占用了更多的存储空间,为了获得管理存储空间的能力,并且以一种有效的方式动态增长。
- 与其它动态序列容器相比(deque, list and forward_list), vector在访问元素的时候更加高效,在末尾添加和删除元素相对高效。对于其它不在末尾的删除和插入操作,效率更低。比起list和forward_list统一的迭代器和引用更好。

二、 vector的使用

1、constructor
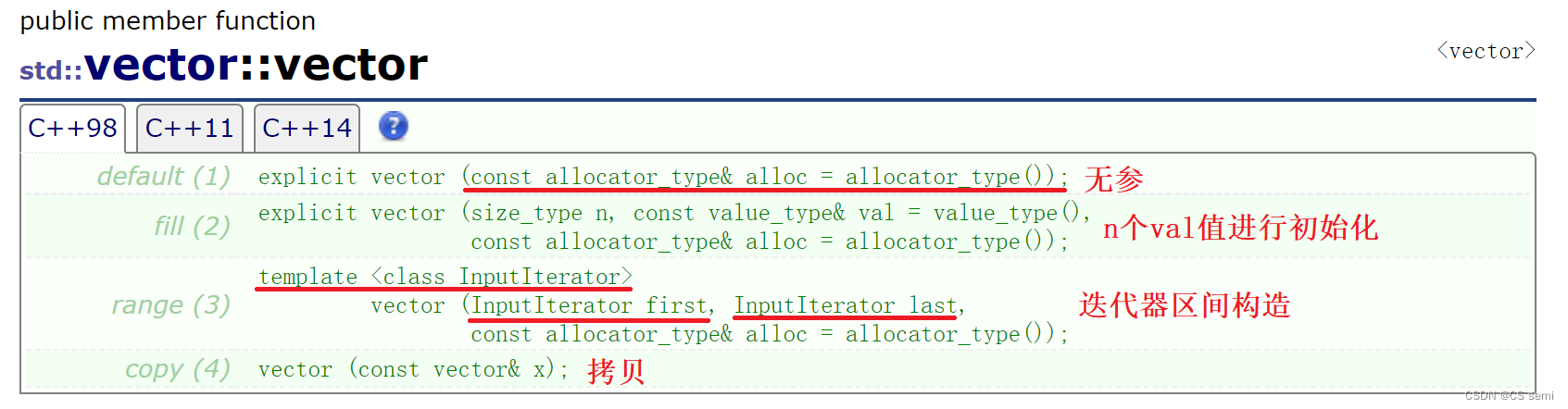
(1)无参构造
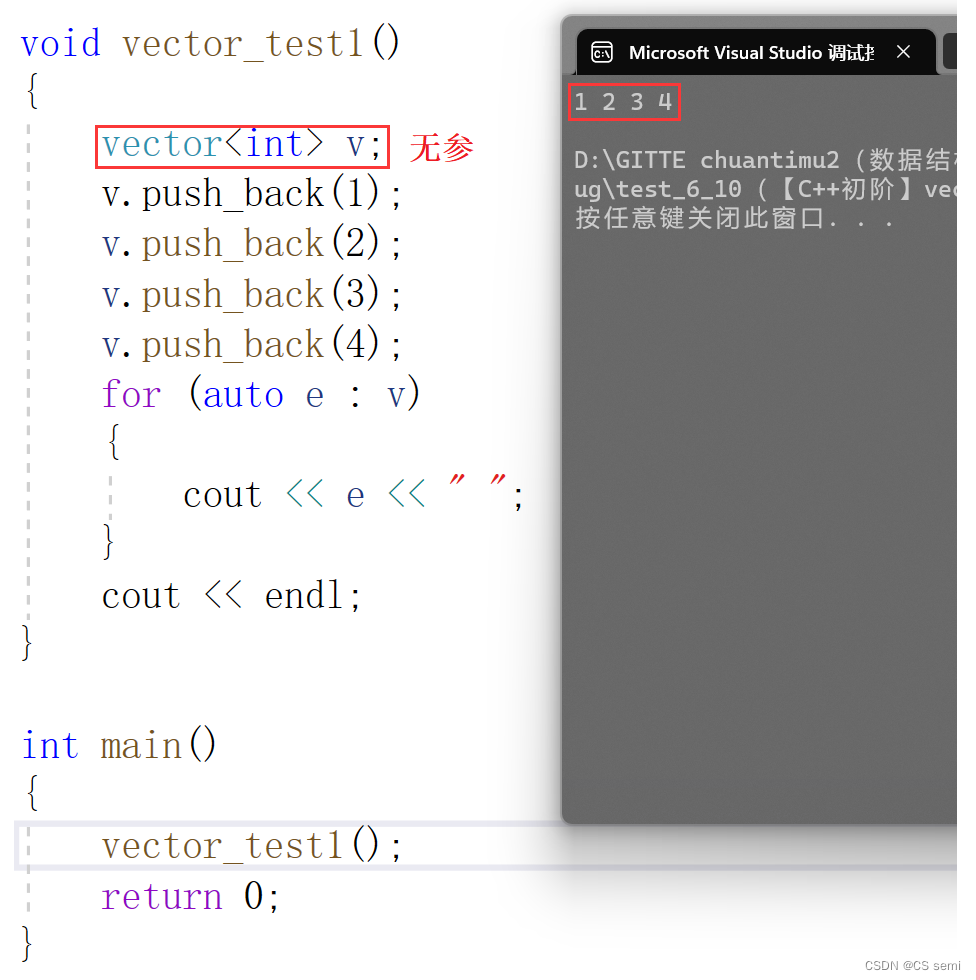
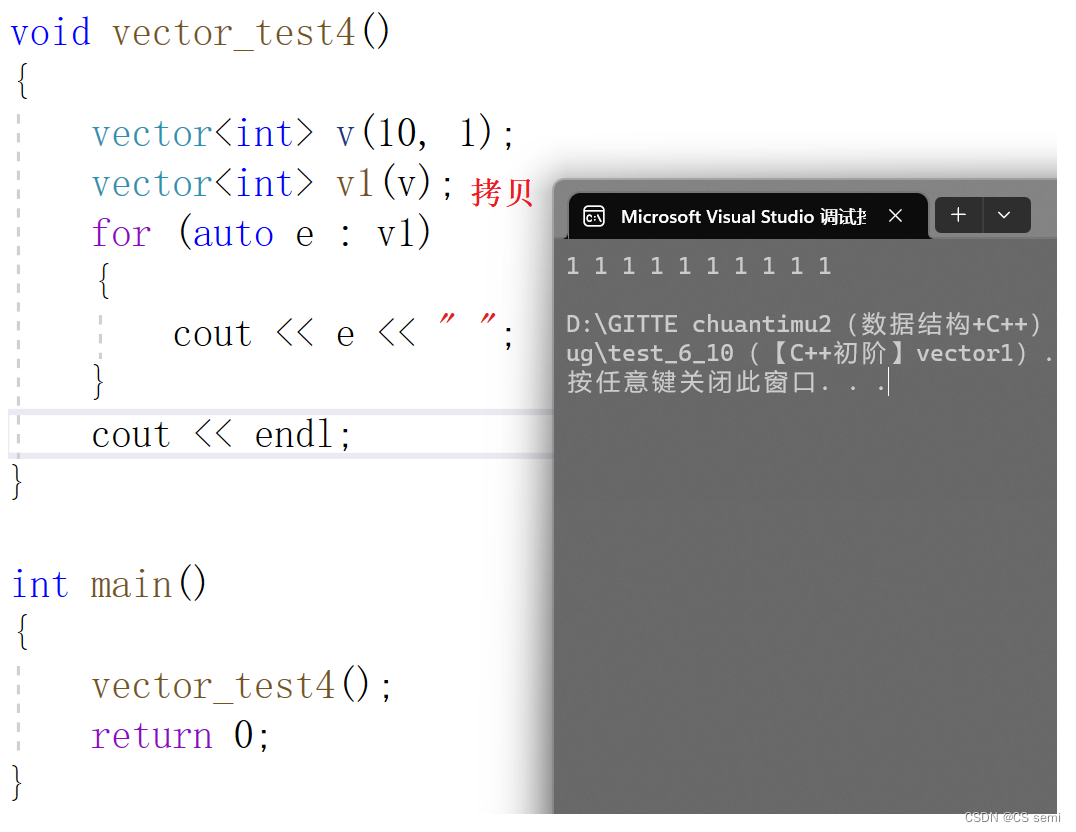
(2)n个val值进行初始化
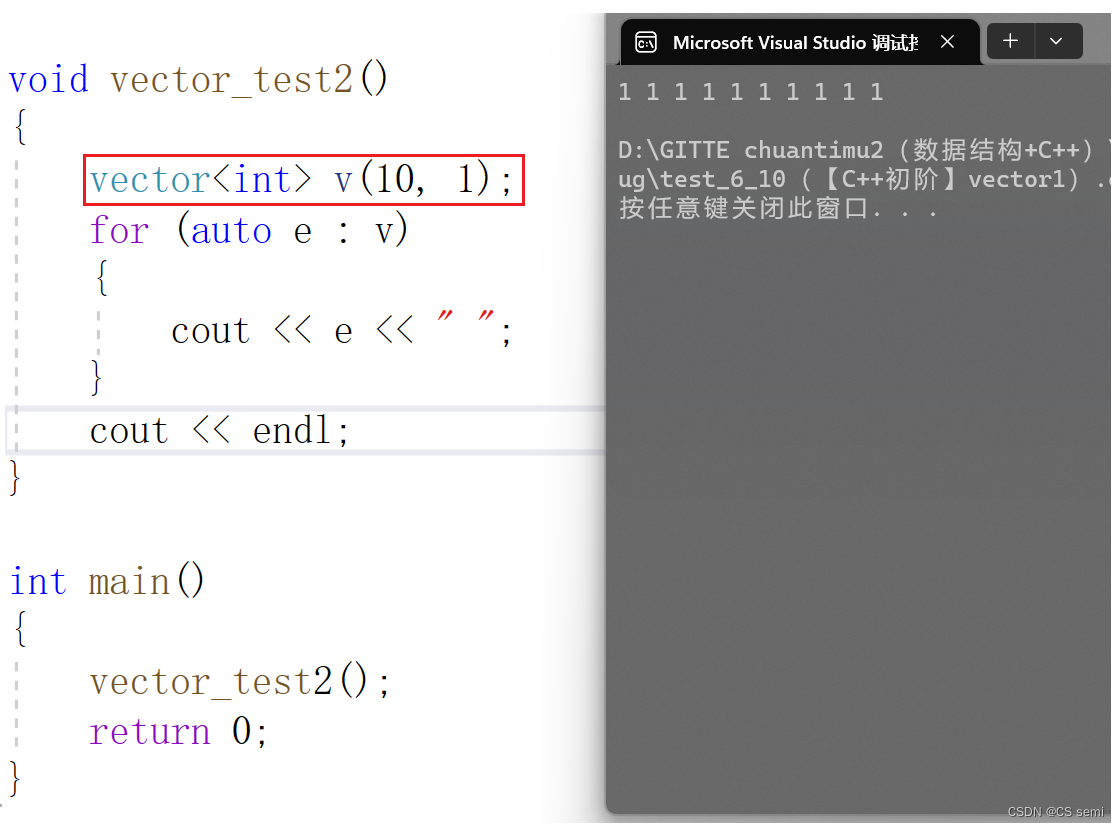
(3)迭代器区间构造
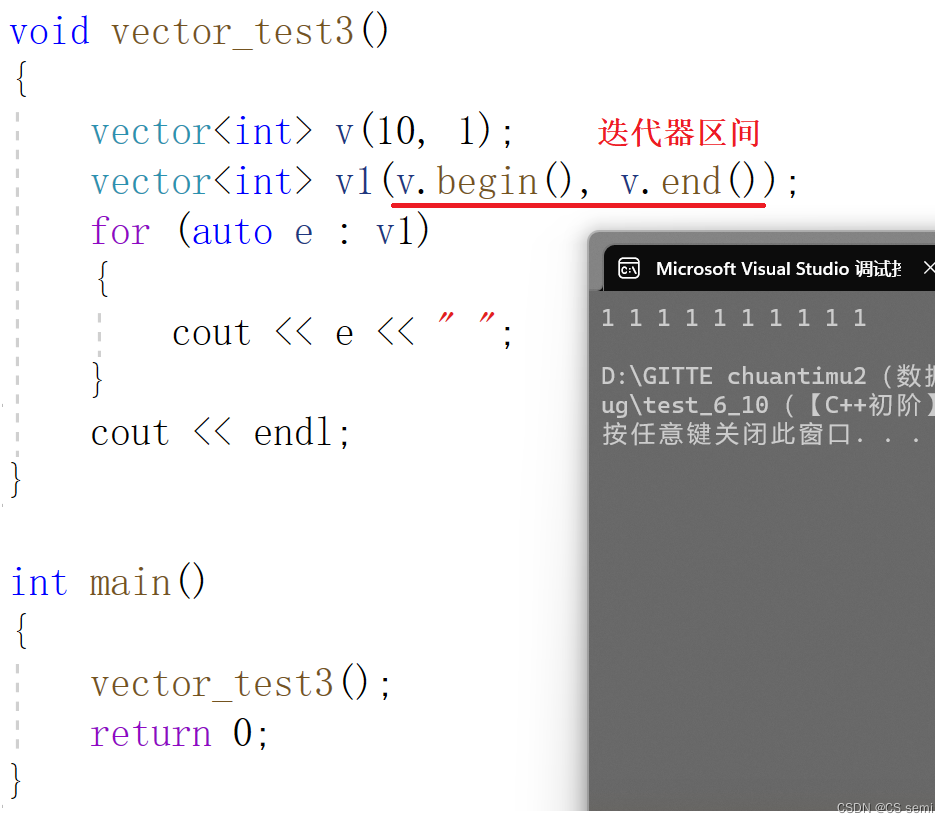

我们敲一下string代码并将其赋给vector试一下:
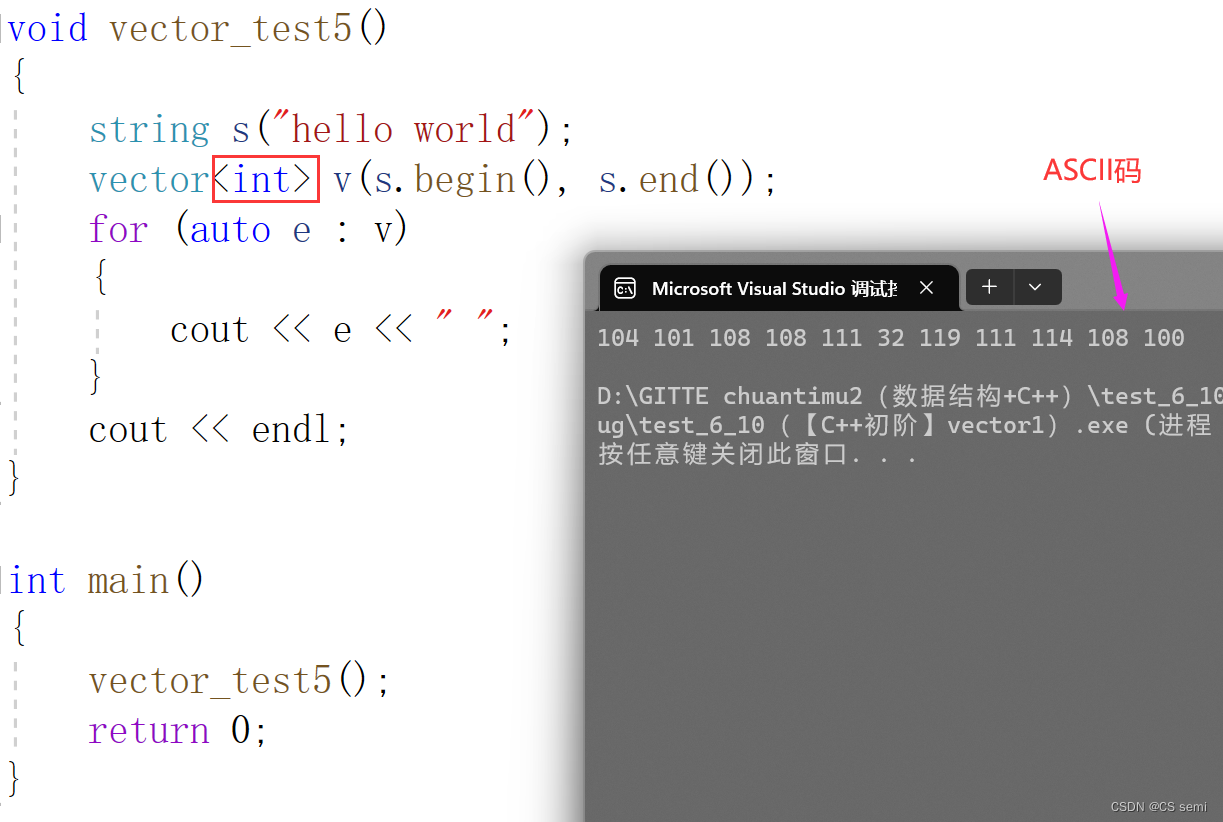
(4)拷贝
2、destructor

3、Iterator

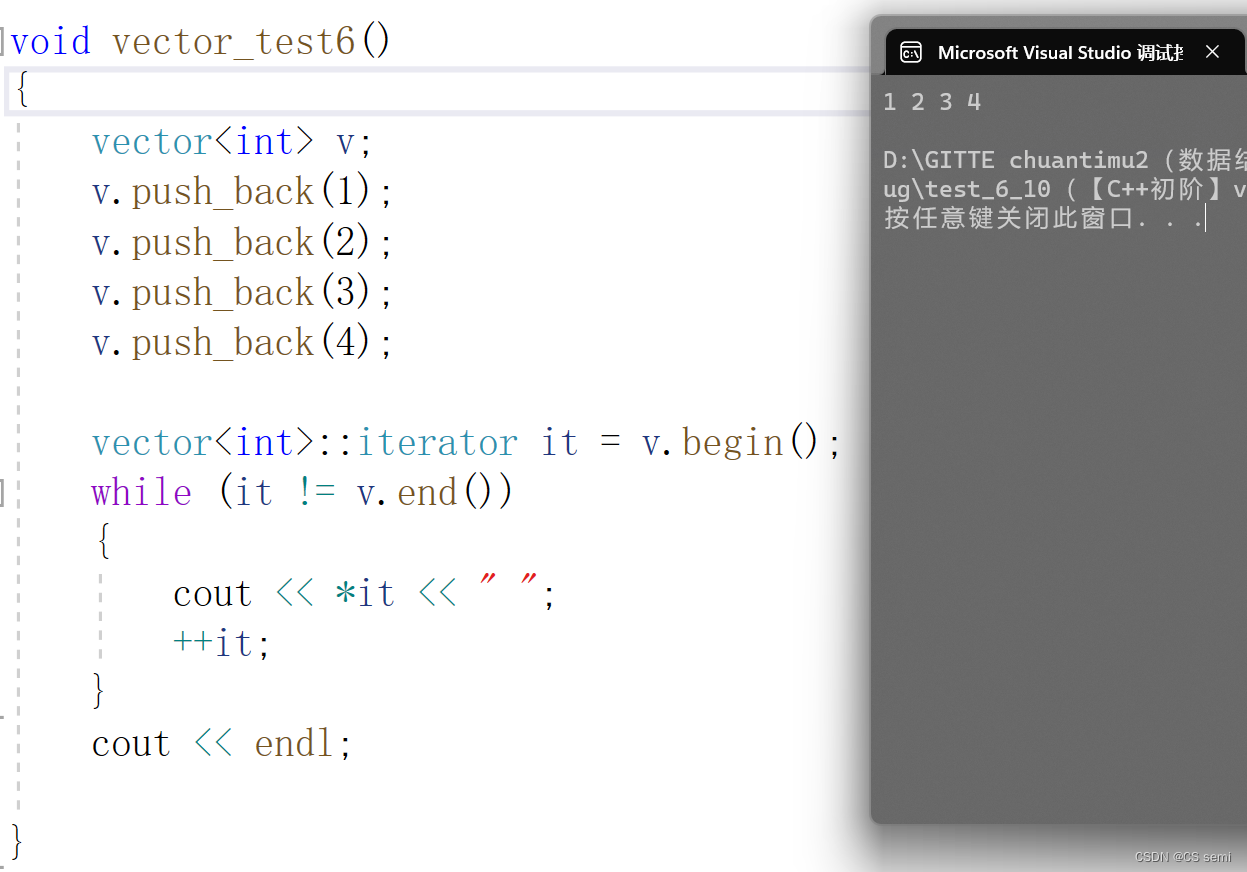
(1)正向迭代器
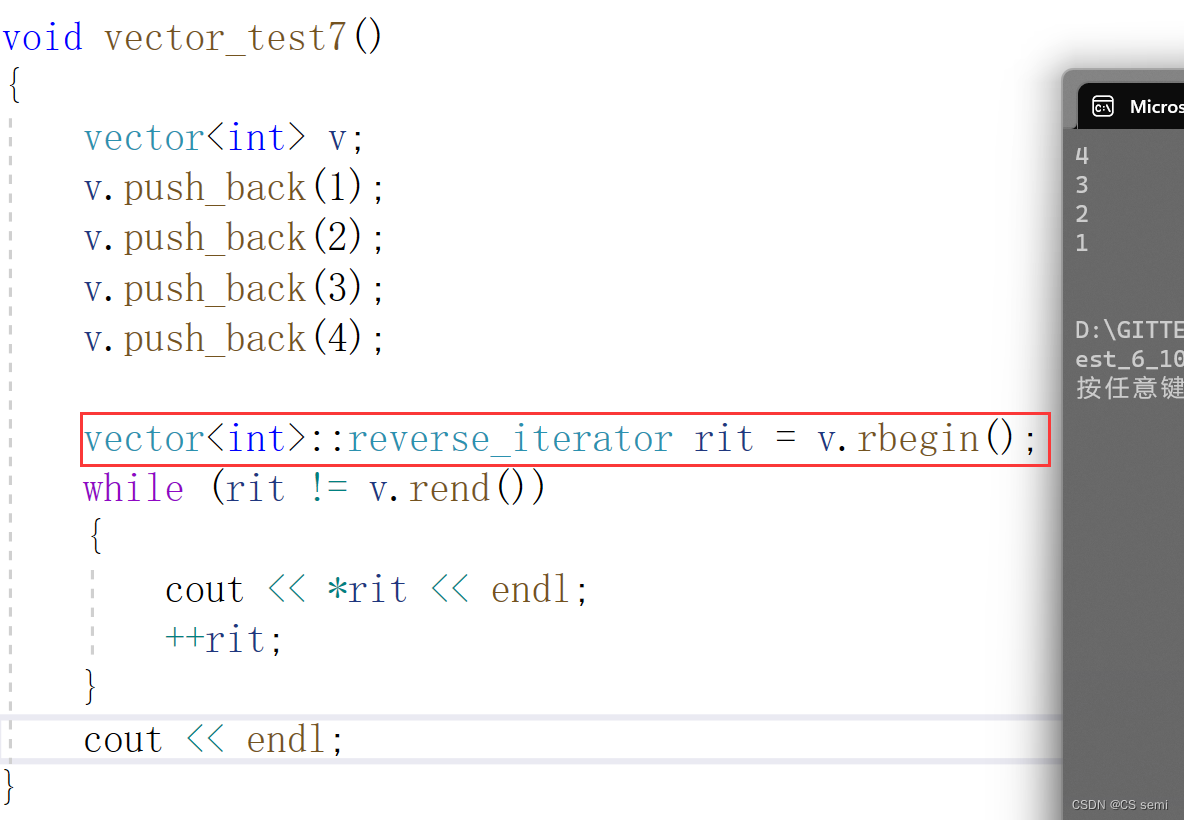
(2)反向迭代器
(3)const正向 / 反向迭代器
4、Capacity

我们在string已经讲过这些函数的接口,这里的vector与string的实现方式大同小异,我们就不细讲,下面我们讲一些不同的类型。
(1)size&&max_size


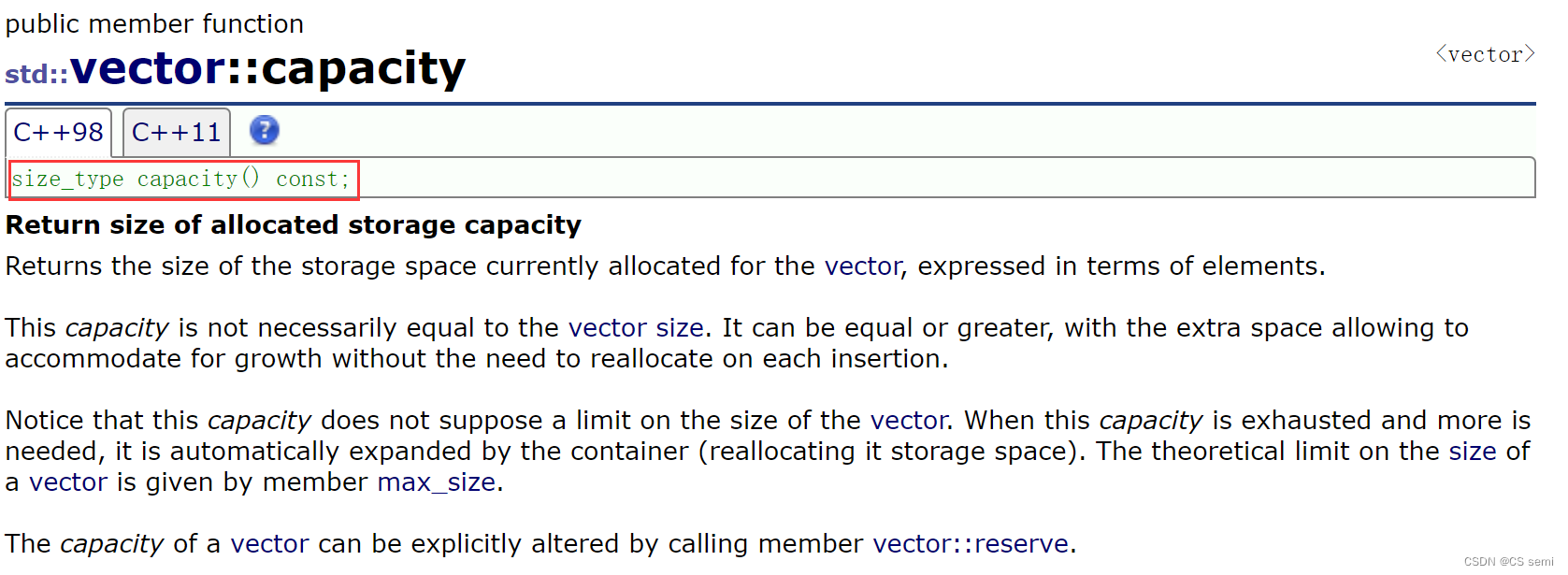
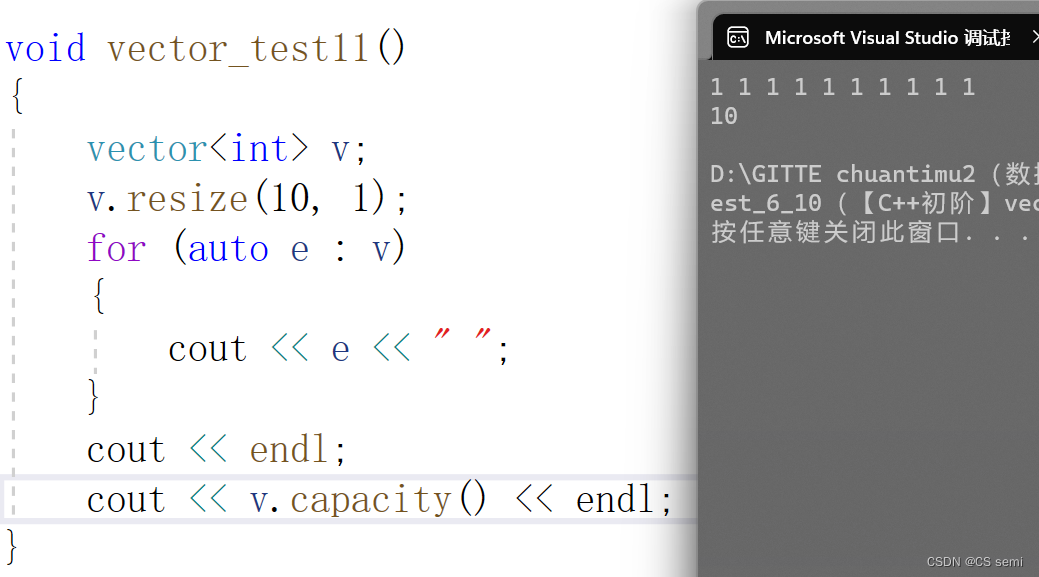
(2)resize 和 capacity
开空间并初始化值:

看一下空间的容量:
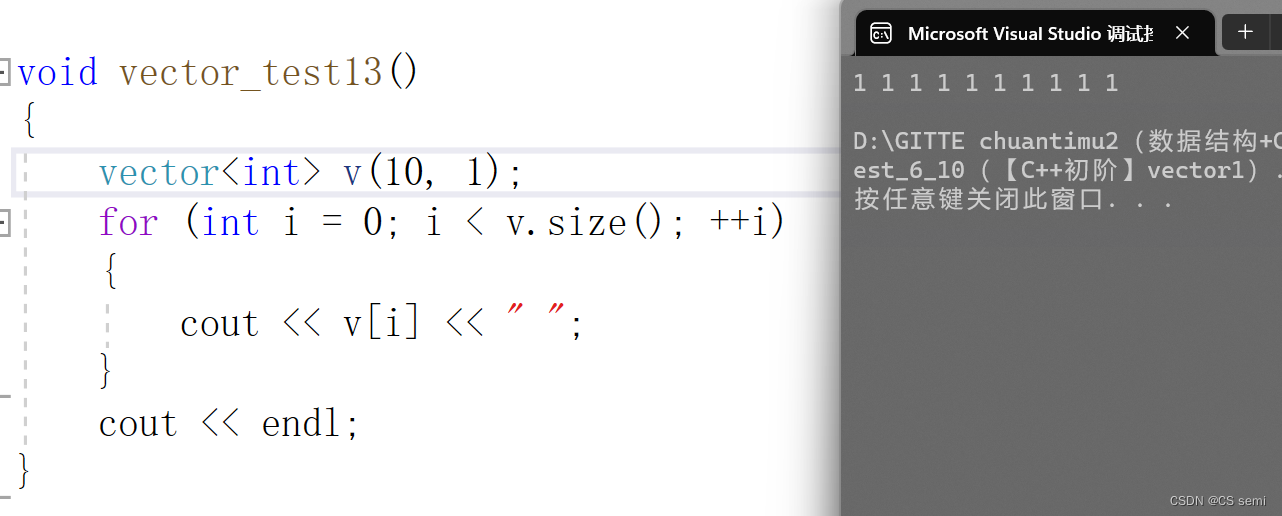
如下图,开辟10个为1的空间。
(3)empty
判断这个vector的size是否为空:
(4)reserve


(5)shrink_to_fit
缩容到合适的容量。


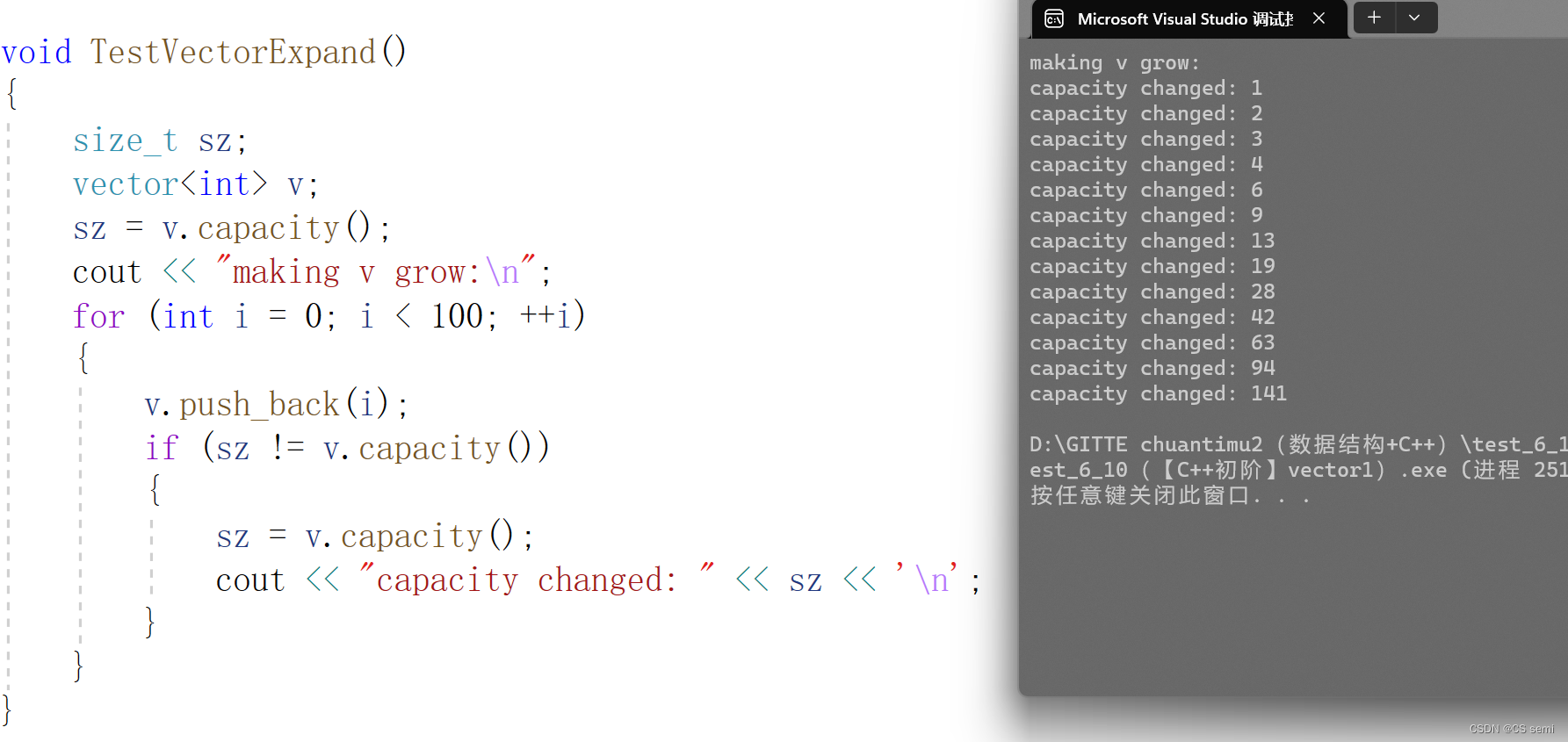
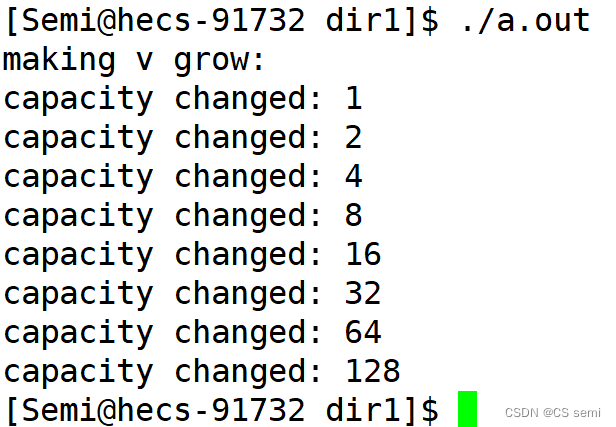
(6)扩容 ---- 重点
capacity的代码在vs和g++下分别运行会发现,vs下capacity是按1.5倍增长的,g++是按2倍增长的。这个问题经常会考察,不要固化的认为,vector增容都是2倍,具体增长多少是根据具体的需求定义的。vs是PJ版本STL,g++是SGI版本STL。
reserve只负责开辟空间,如果确定知道需要用多少空间,reserve可以缓解vector增容的代价缺陷问题。
resize在开空间的同时还会进行初始化,影响size。
vs下:
Linux下:
5、Element access

(1)operator[]

(2)front && back


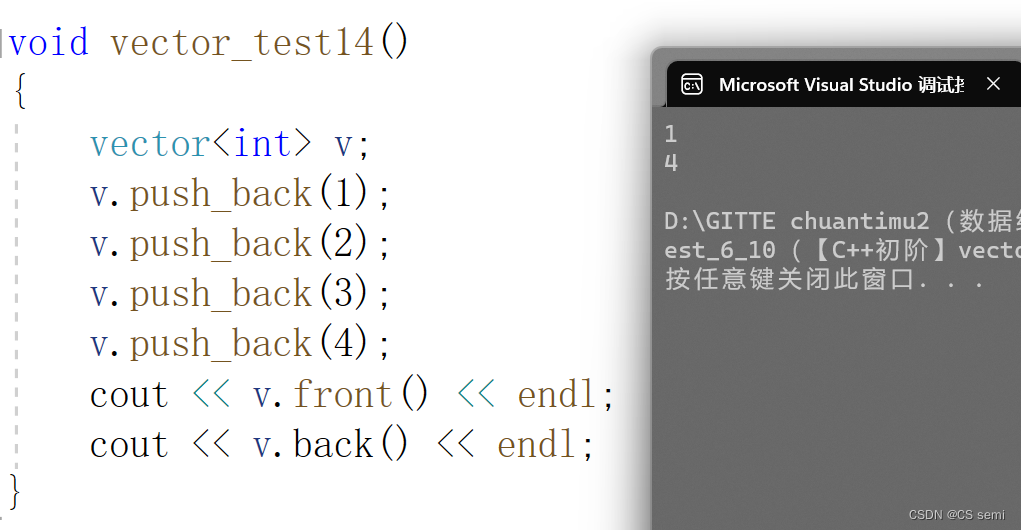
6、Modifiers

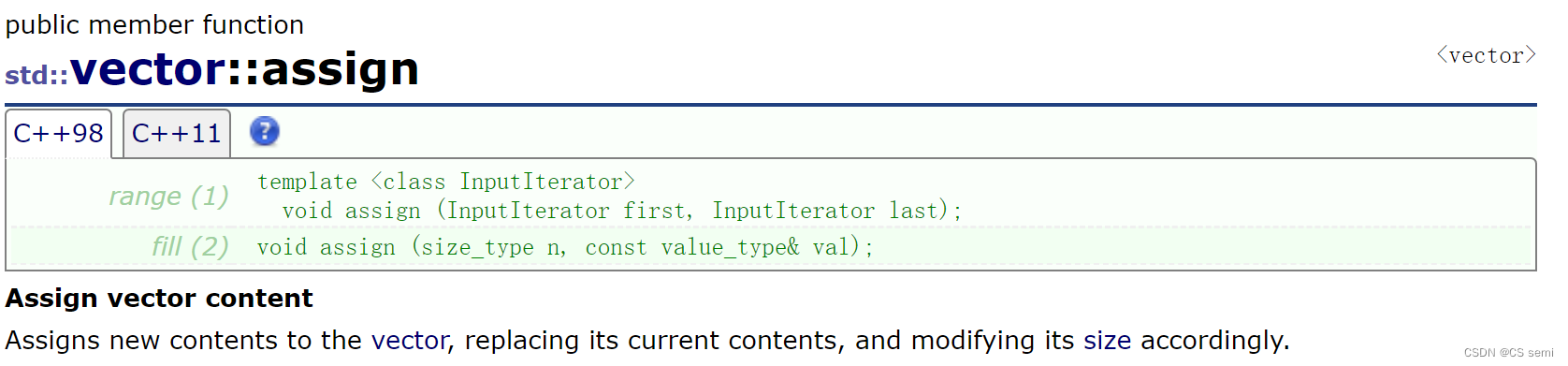
(1)assign
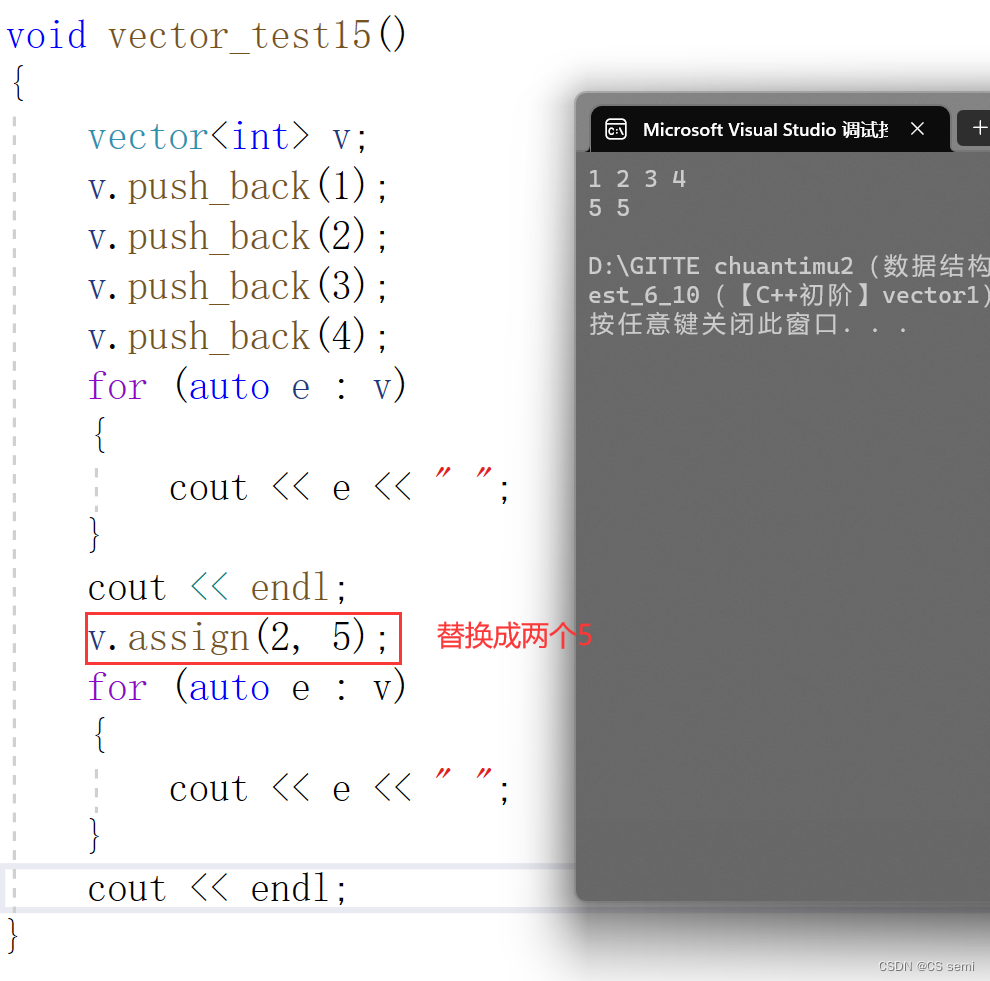
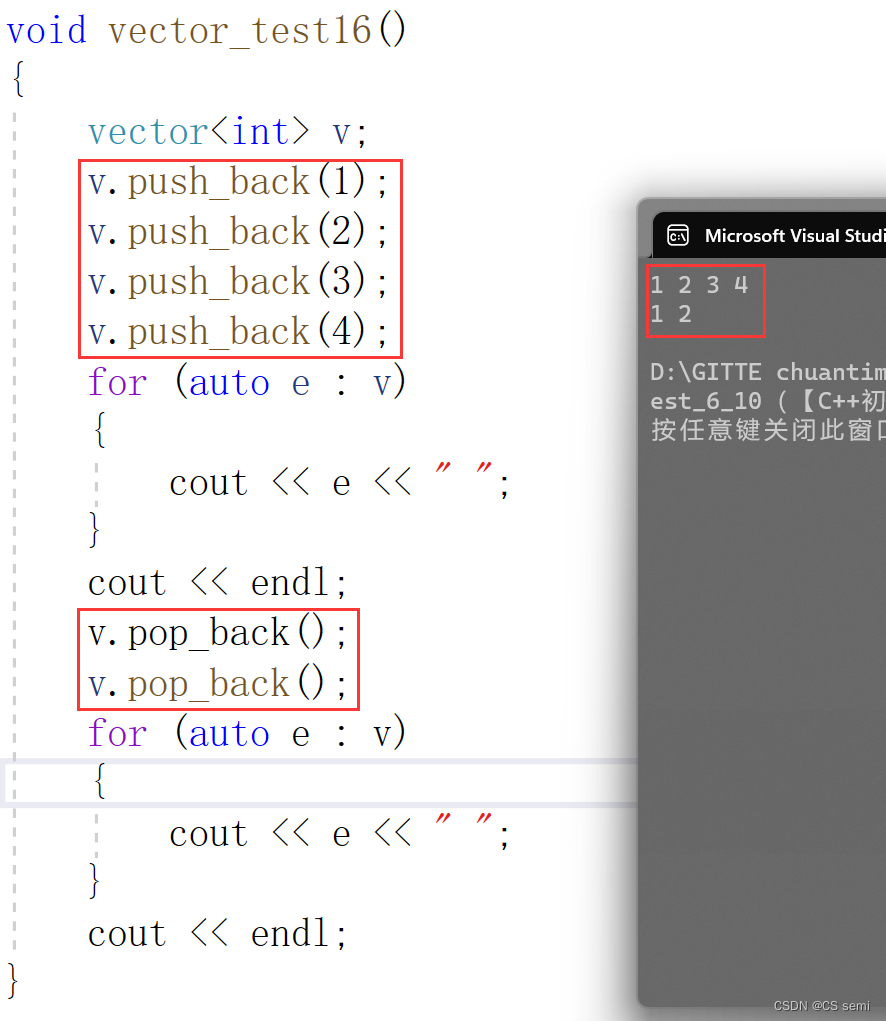
(2)push_back && pop_back
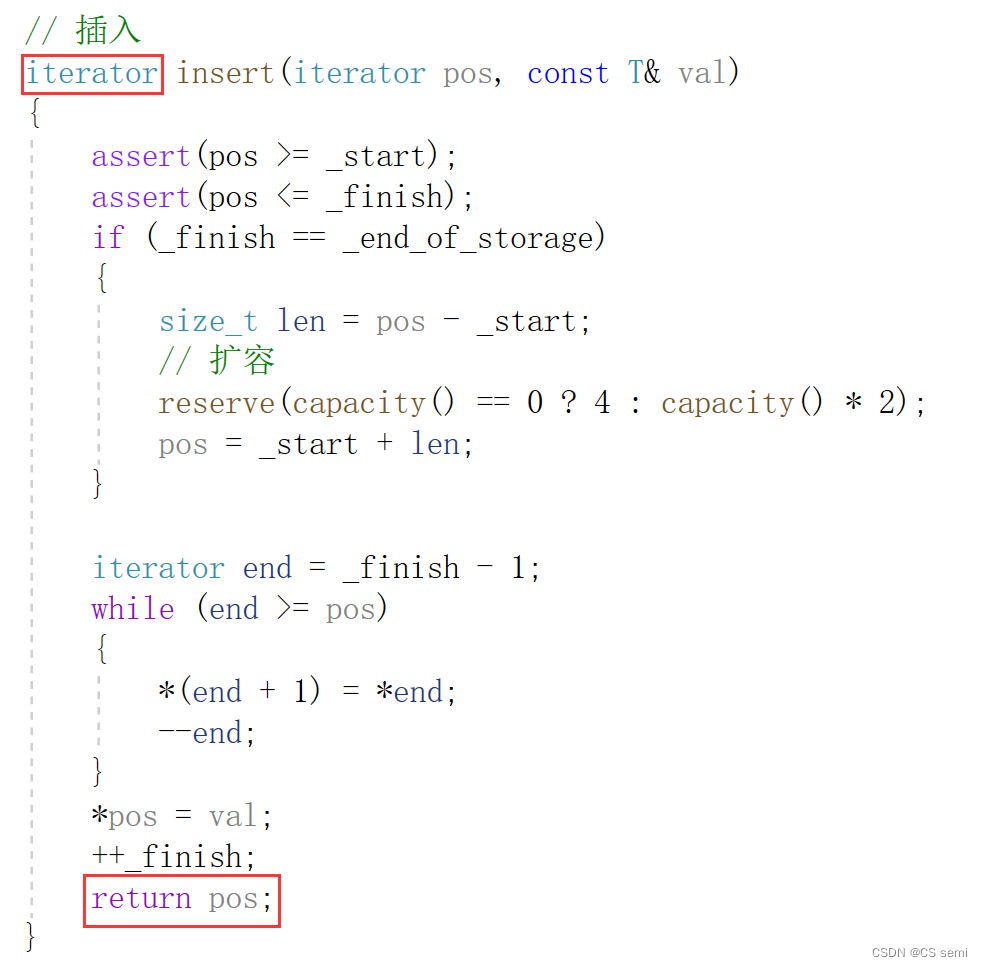
(3)insert

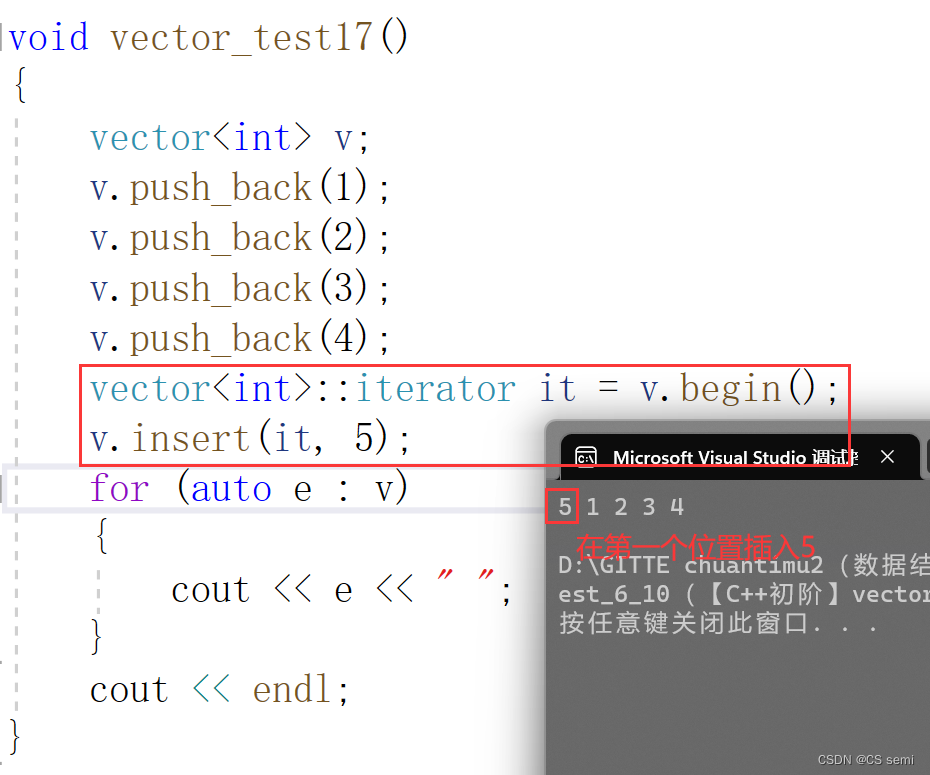
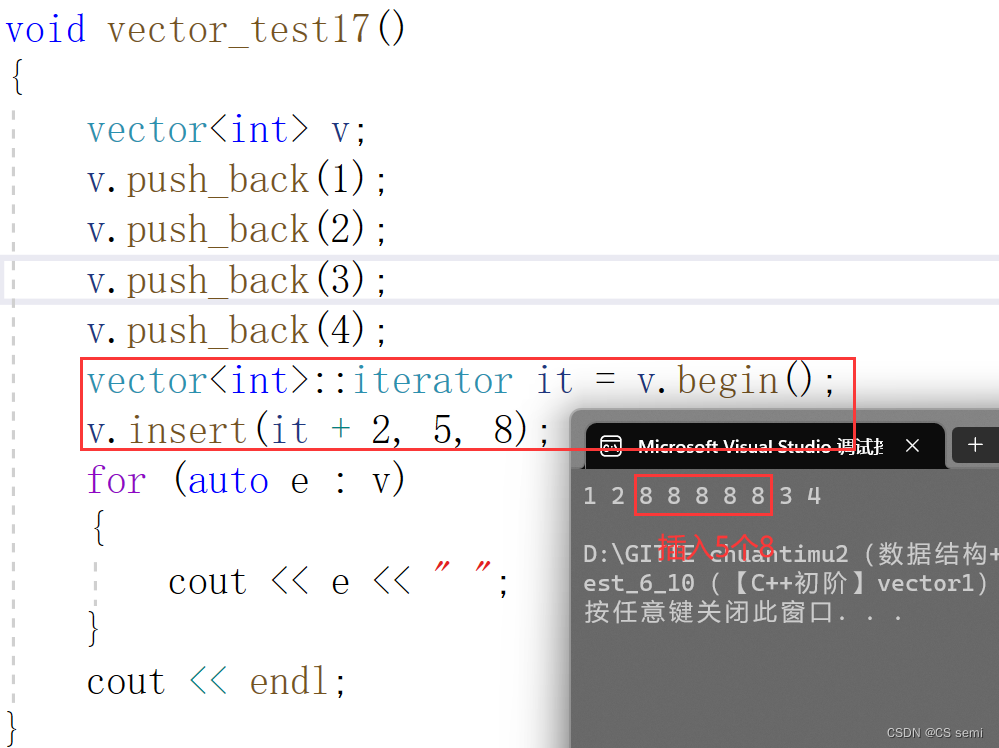
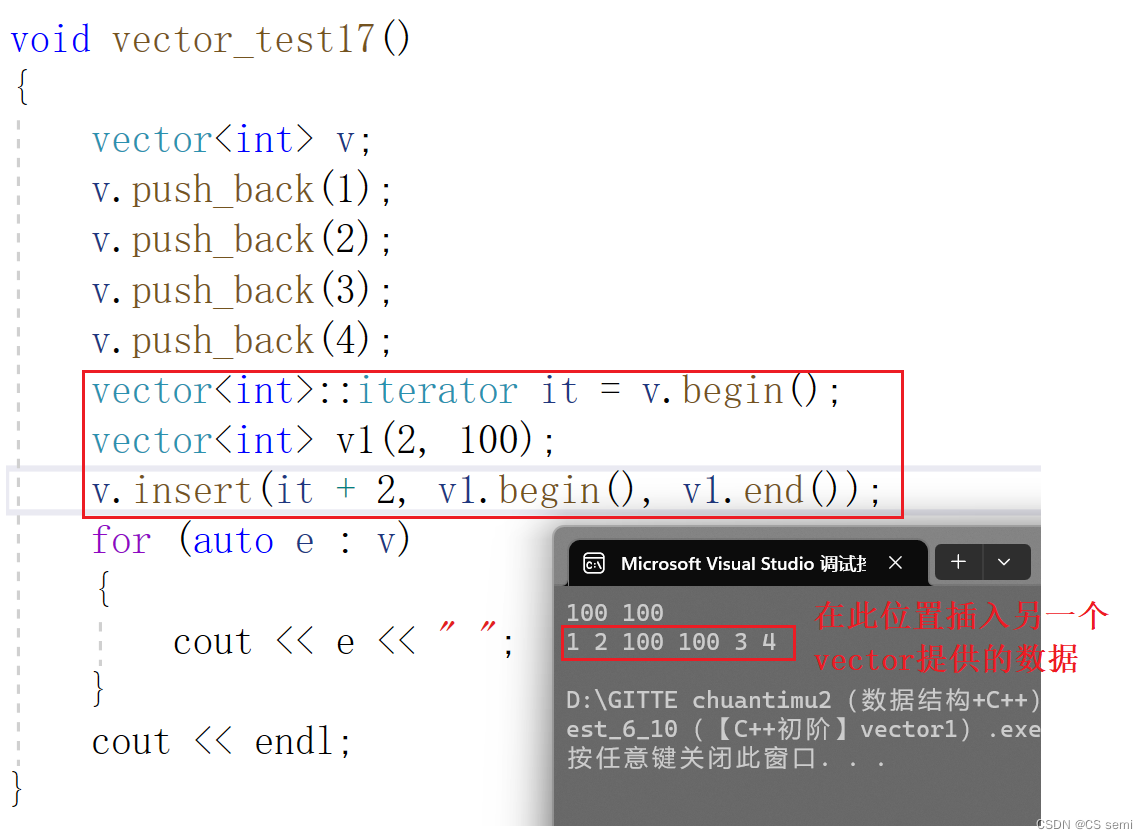
(4)erase

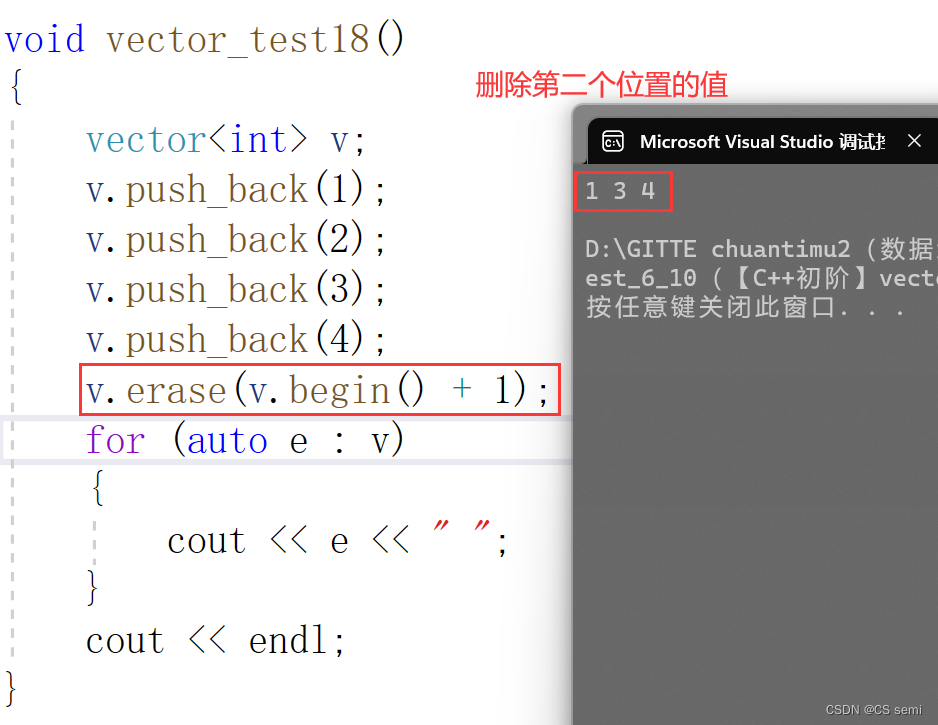
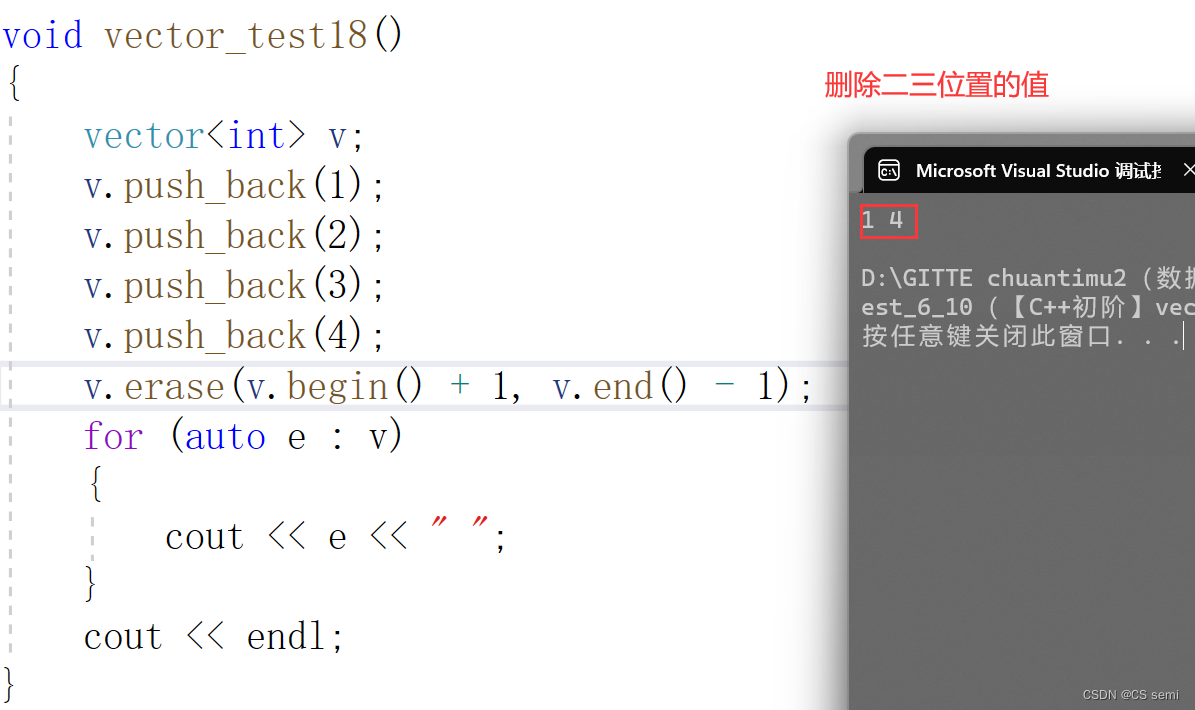
(5)swap

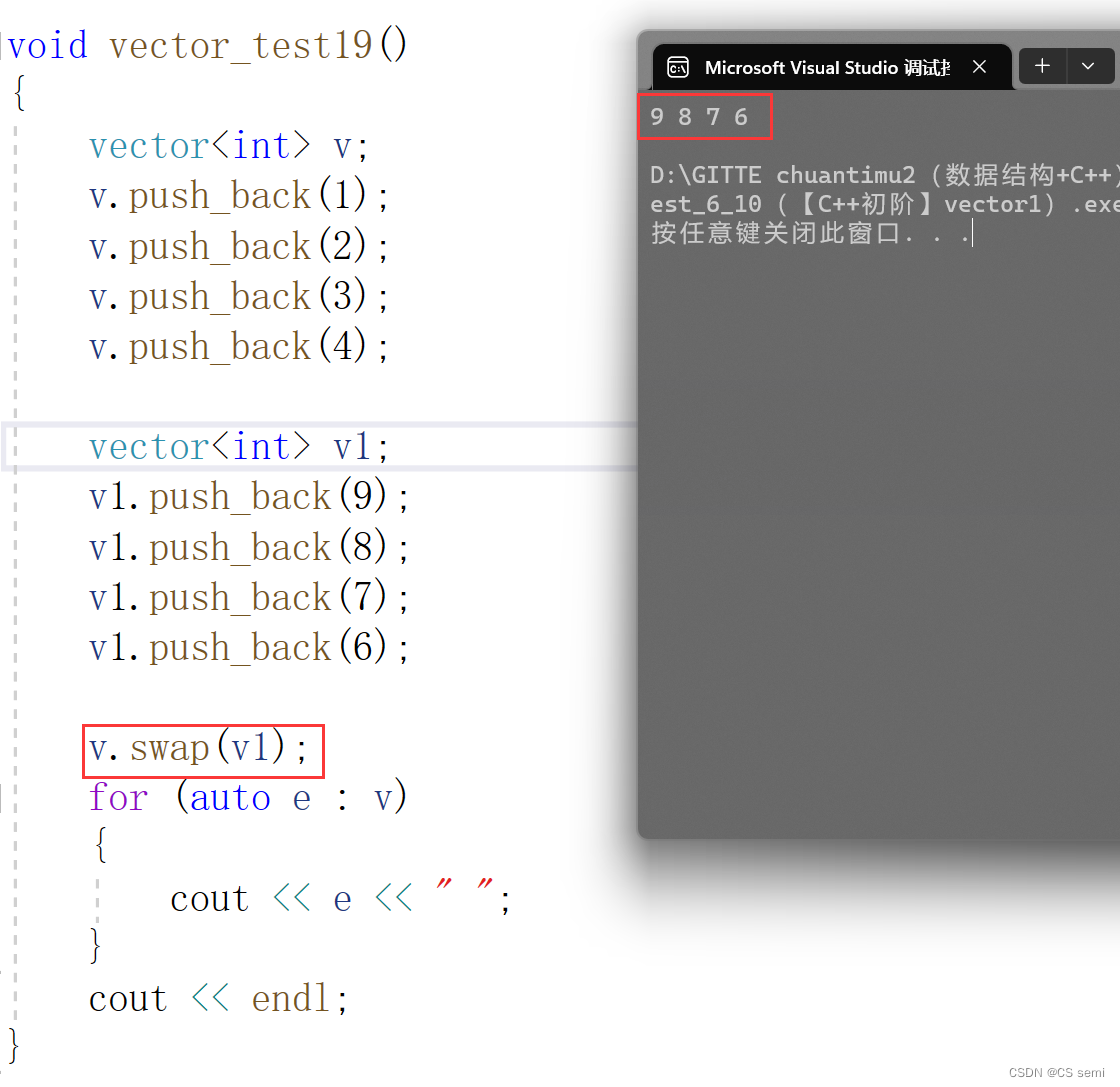
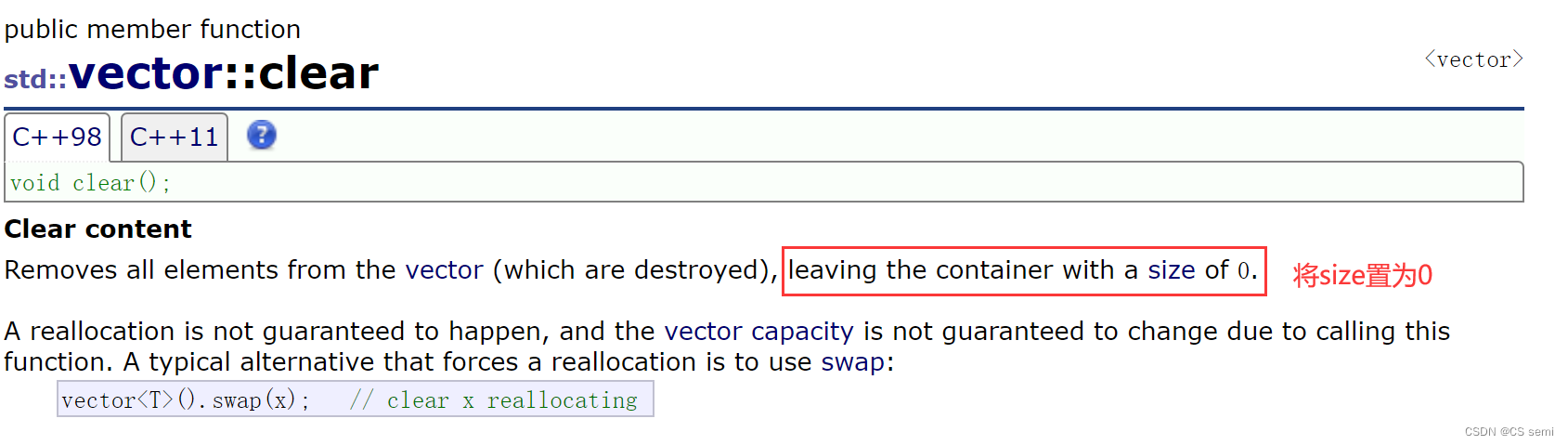
(6)clear
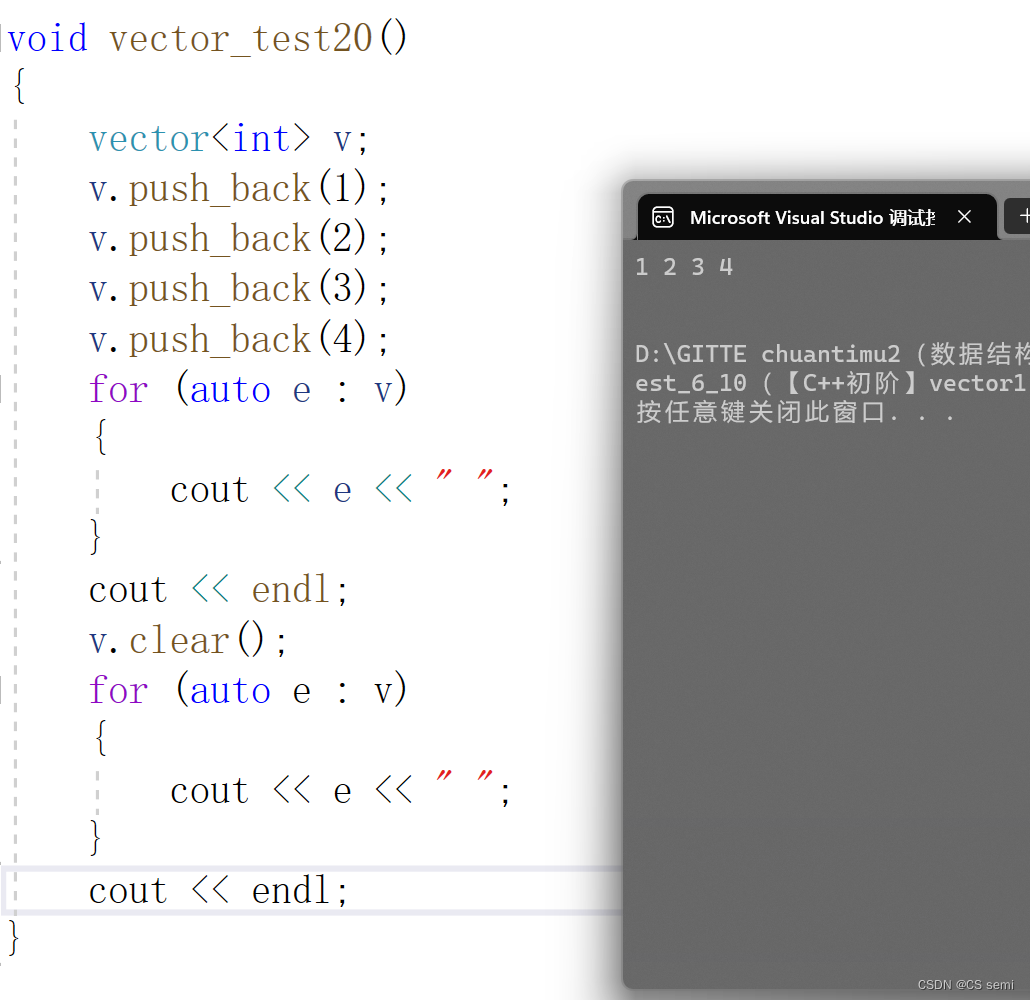
(7)find
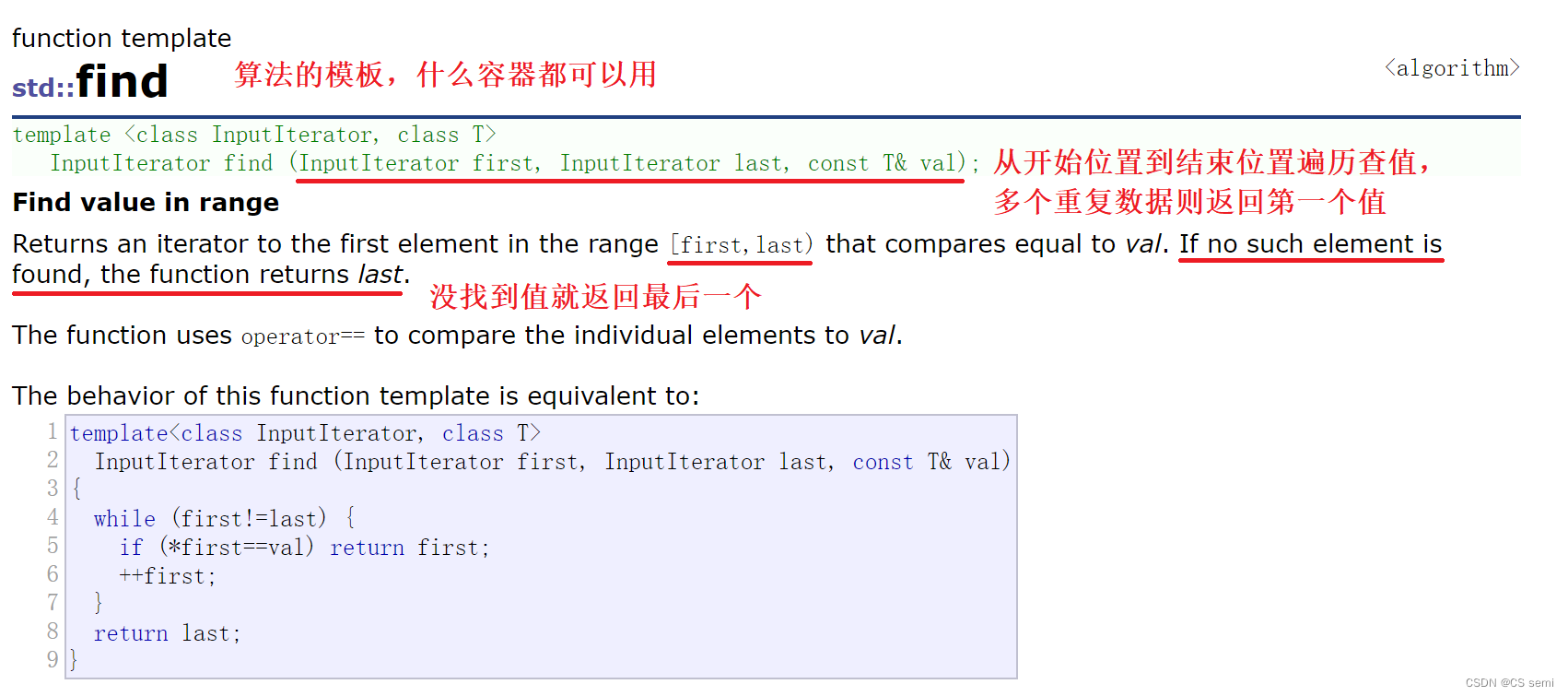

三、vector<>
1、解释
我们在前面讲了那么多的vector发现和string怎么那么相似呢,那为什么string不用<>而vector要用<>呢?我们接下来详细讲一下这个<>的秒用。
<>内部加上我们的类型发现可以接收不同的类型,怎么越看越像类模板,当然,它就是一个类模板。
我们先简单画个图:
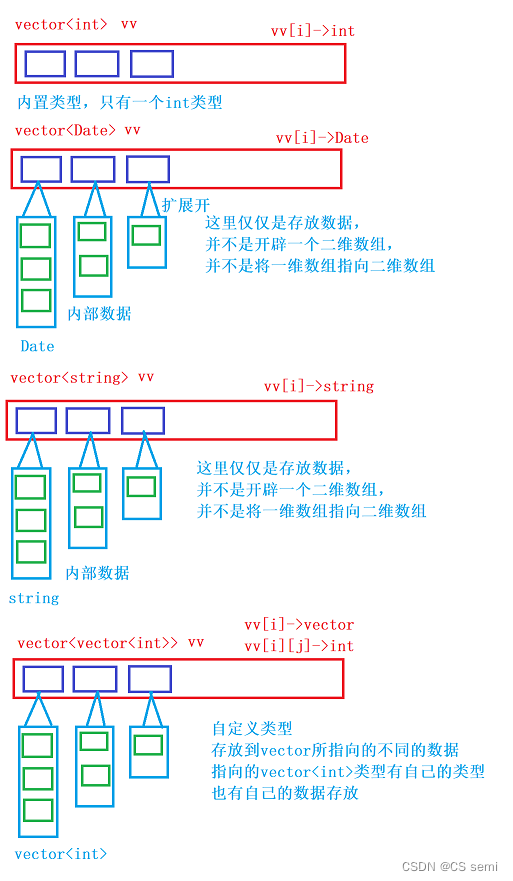
看起来是不是很妙,是用的同一个模板去实例化,<>中可以放不同的类型,甚至是可以放自己本身,与数组有本质的区别,在存放自定义类型和内置类型的存放逻辑是一样的,只能说用法和数组类似,但底层的实现下完全不同。
2、题目
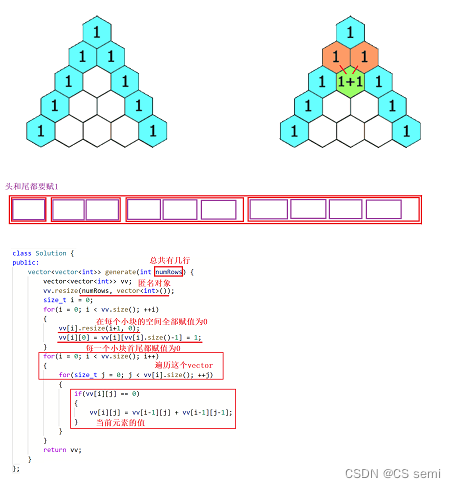
class Solution {
public:
vector<vector<int>> generate(int numRows) {
vector<vector<int>> vv;
vv.resize(numRows, vector<int>());
size_t i = 0;
for(i = 0; i < vv.size(); ++i)
{
vv[i].resize(i+1, 0);
vv[i][0] = vv[i][vv[i].size()-1] = 1;
}
for(i = 0; i < vv.size(); i++)
{
for(size_t j = 0; j < vv[i].size(); ++j)
{
if(vv[i][j] == 0)
{
vv[i][j] = vv[i-1][j] + vv[i-1][j-1];
}
}
}
return vv;
}
};
代码解释:

我们画一下递归展开图解释一下吧:
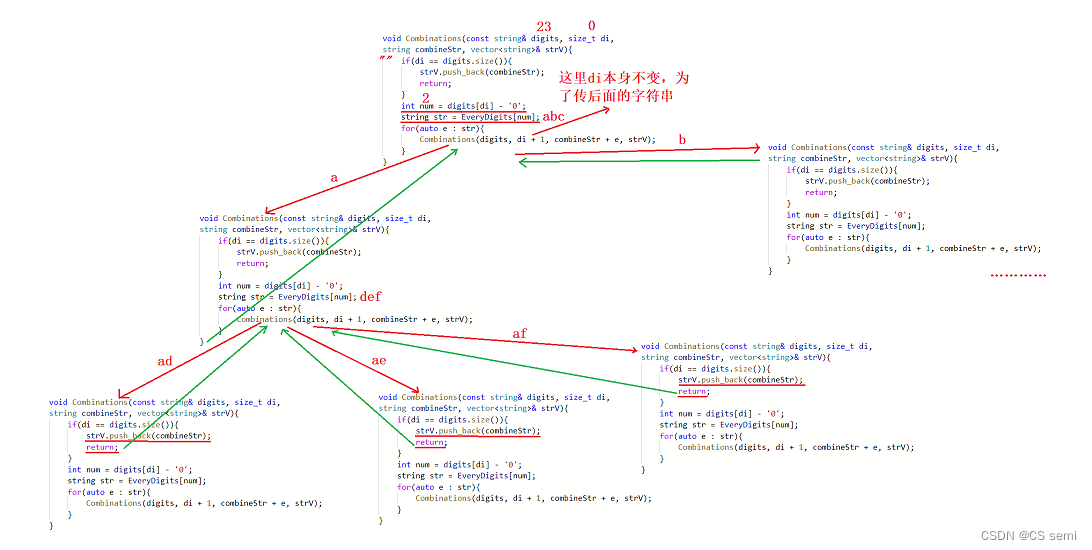
四、重点:迭代器的失效问题
1、insert迭代器失效问题

看起来很正常的样子,我们进行测试一下不同的数据:
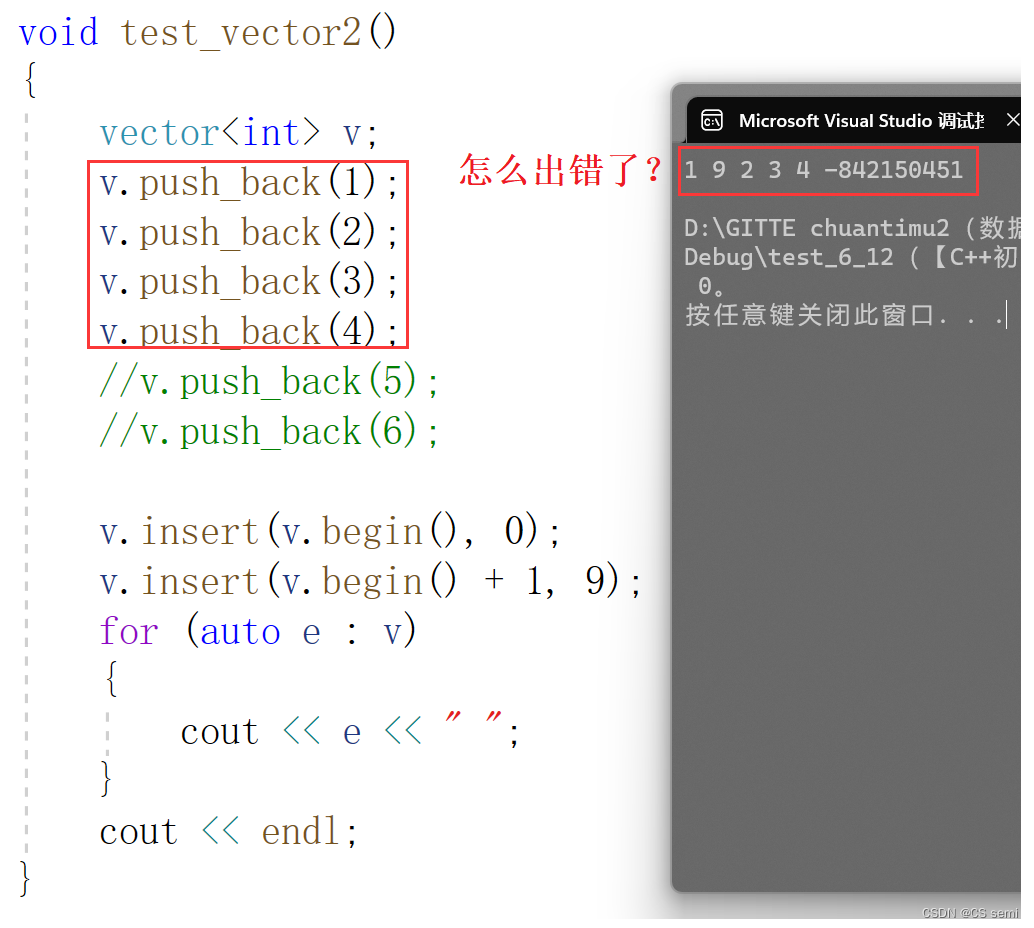
我们可以重新看一下push_back的代码:

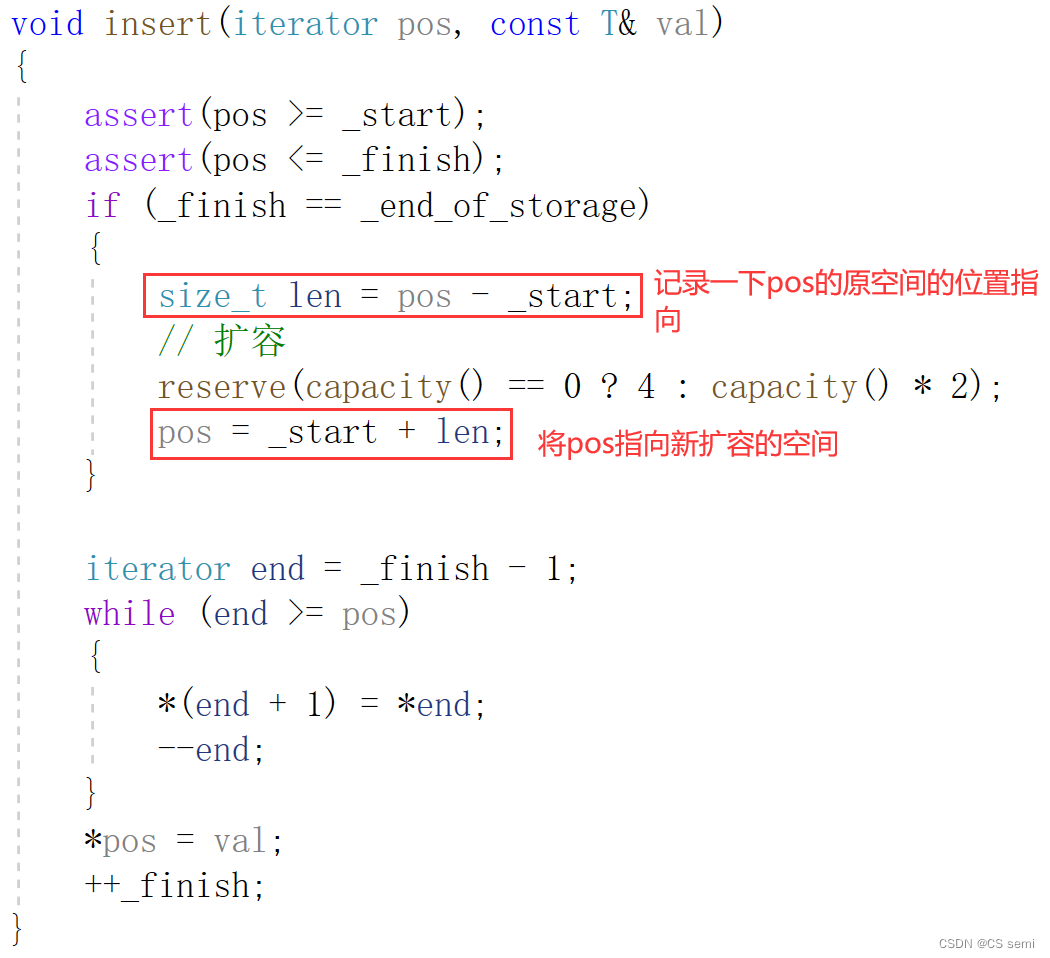
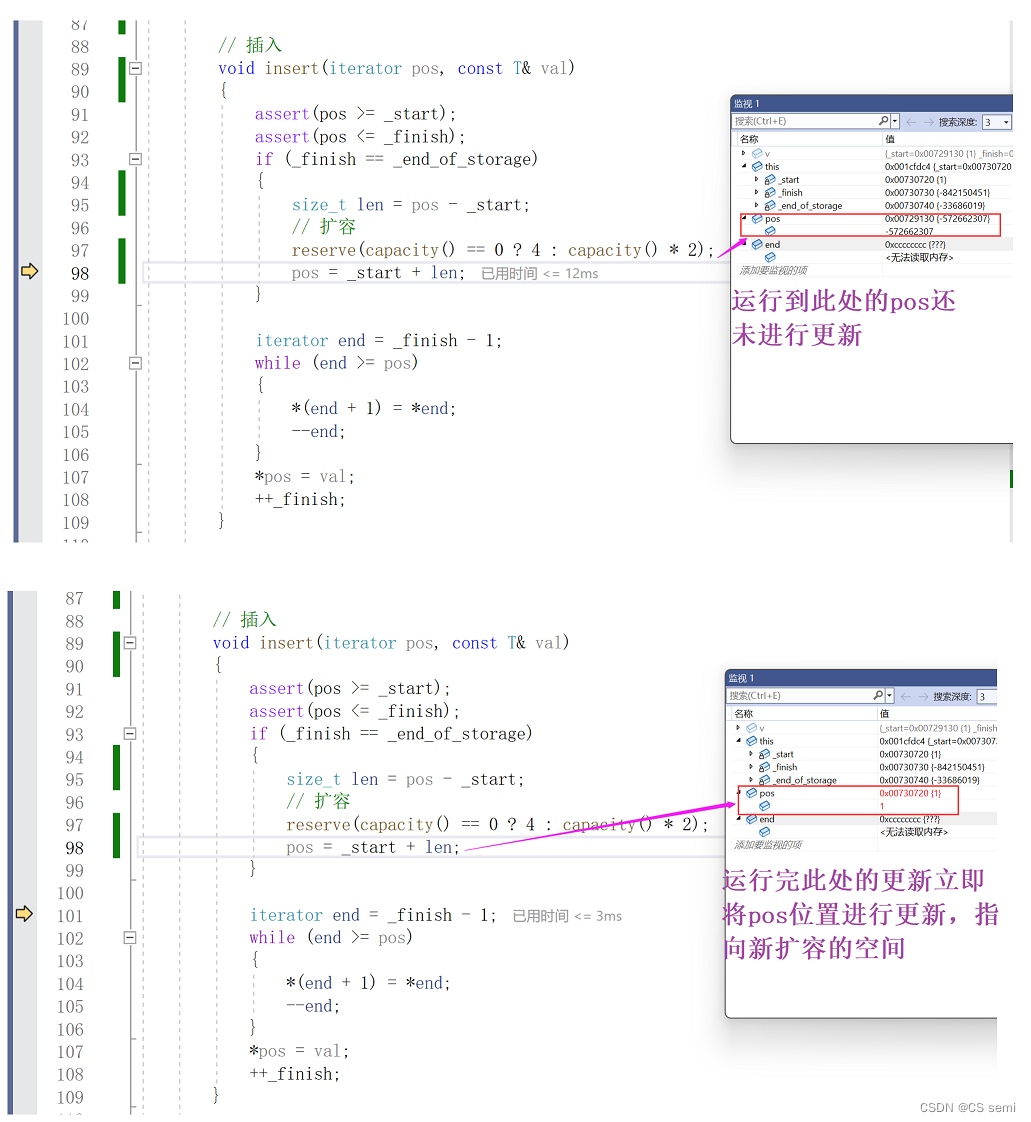
有扩容的,我们就可以理解一个很深刻的问题,我们如果在main函数中的push_back很多值,则会进行扩容到有容量的地方,则insert函数内是不会进入扩容的,所以我们的pos依旧用的是原本的空间,因为我们知道,迭代器的扩容是将原本空间存放到新的空间,再释放掉原本的空间,我们利用调试来看一下为什么这个iterator会变成野指针了。可以理解为_start,_finish,_end_of_storage都跟着扩容的新空间进行跑路了,而只有傻傻的pos留在原空间,成为野指针。
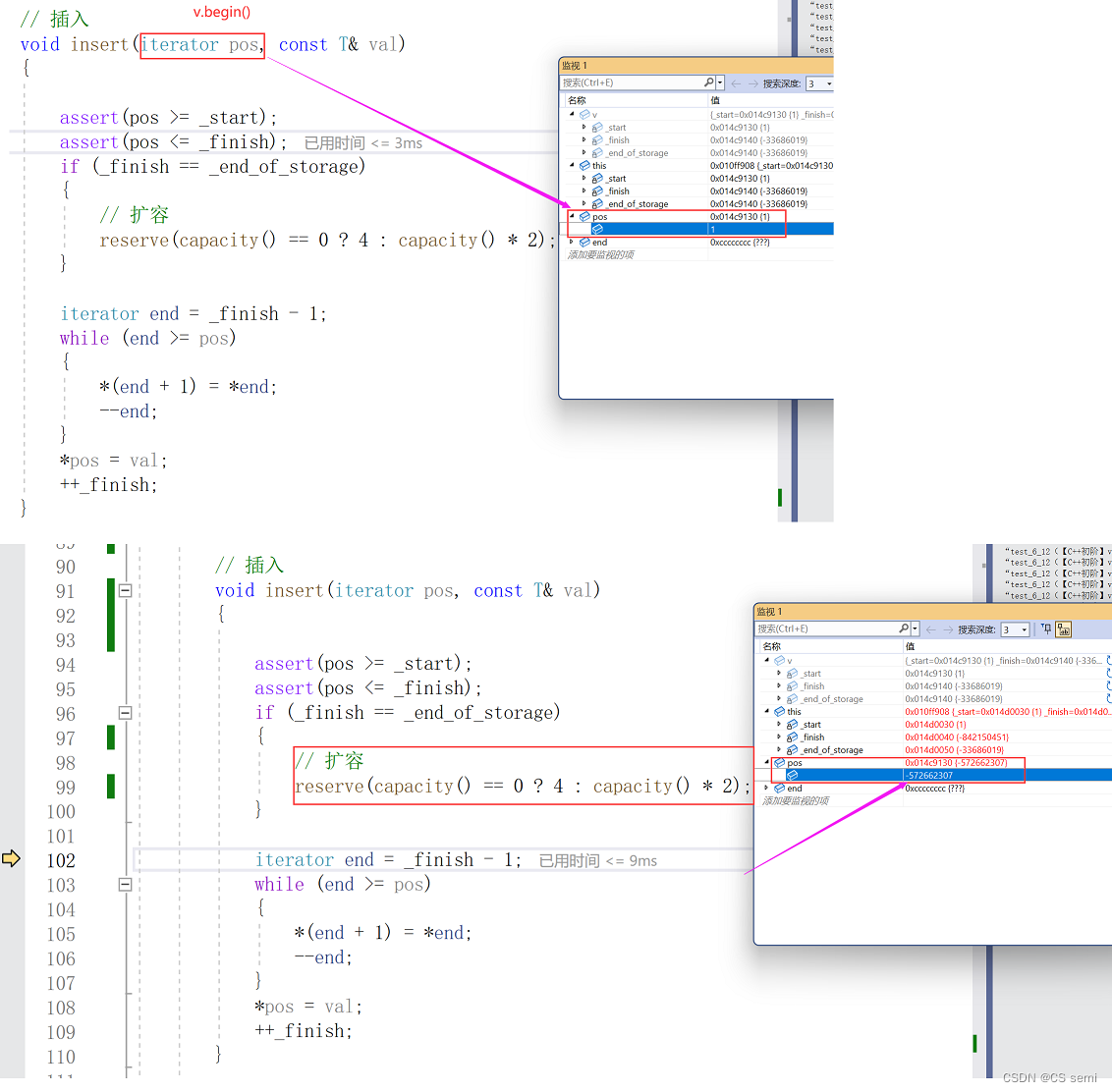
我们看一下我们的画图解释:这是在insert函数内部进行扩容的逻辑。
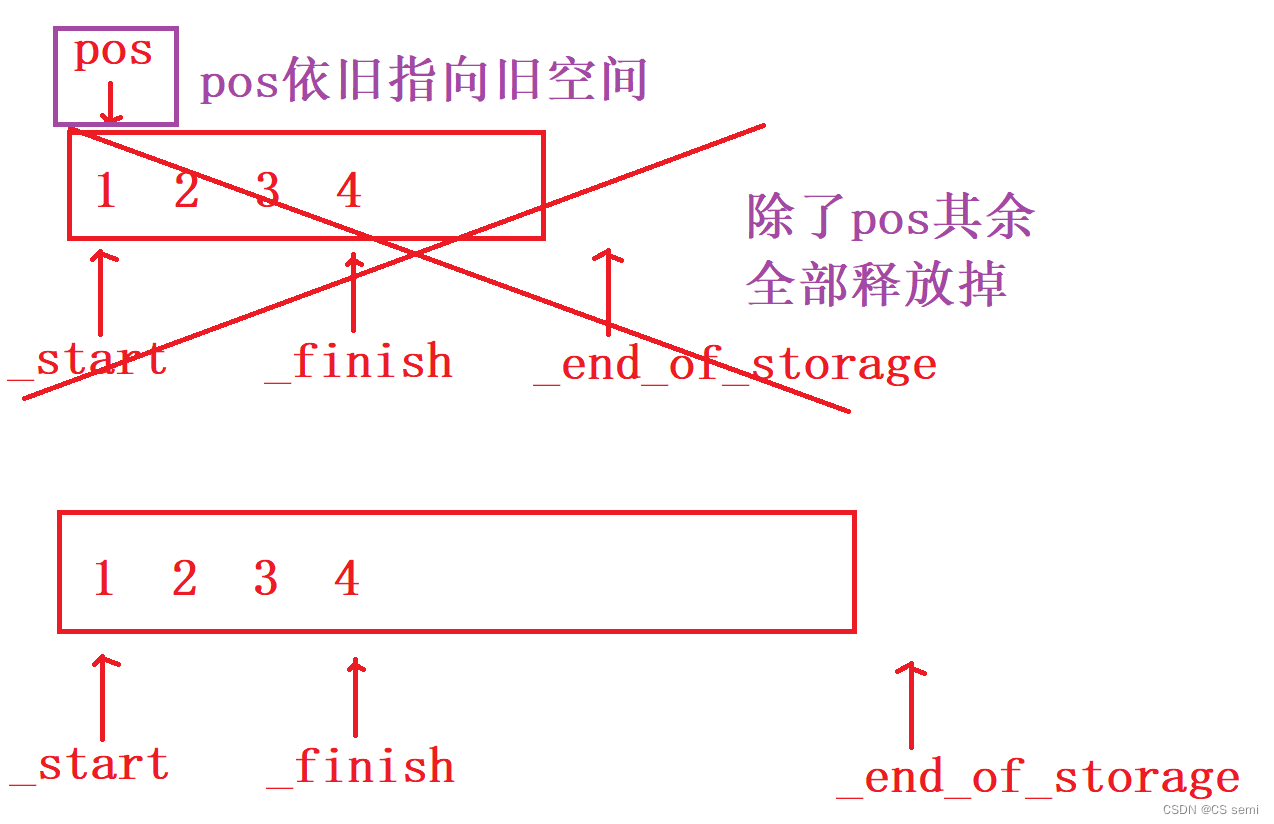
解决方法:在扩容后更新一下迭代器的位置。
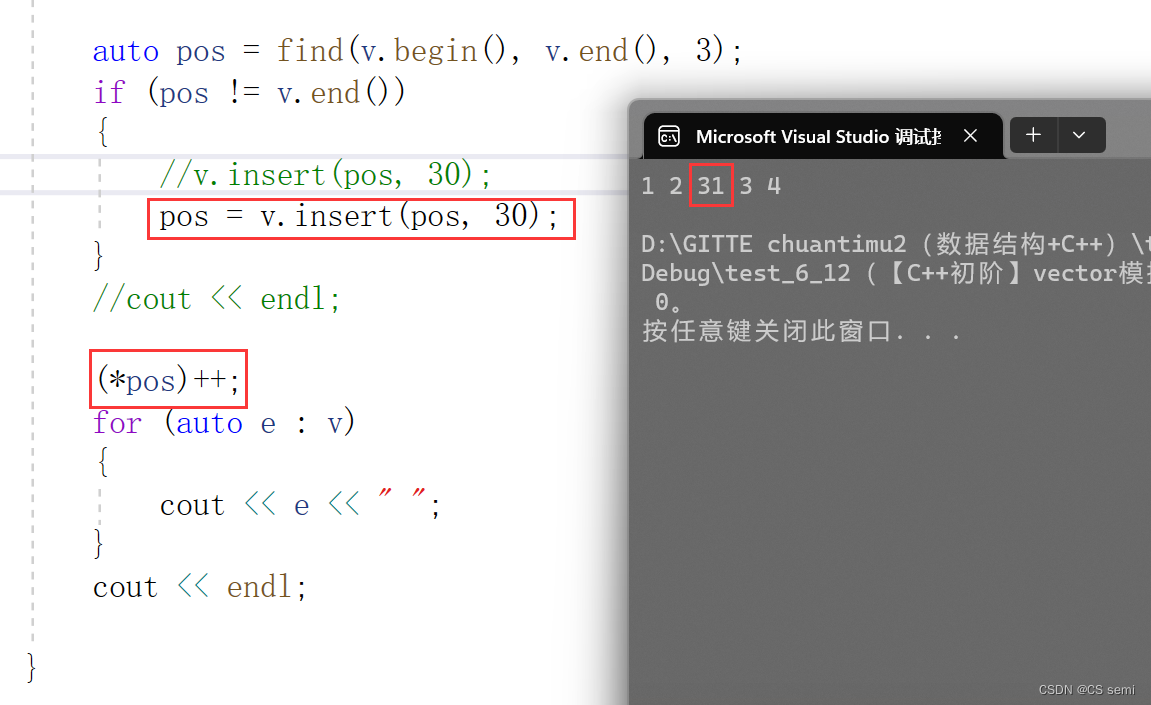
2、insert在main和insert
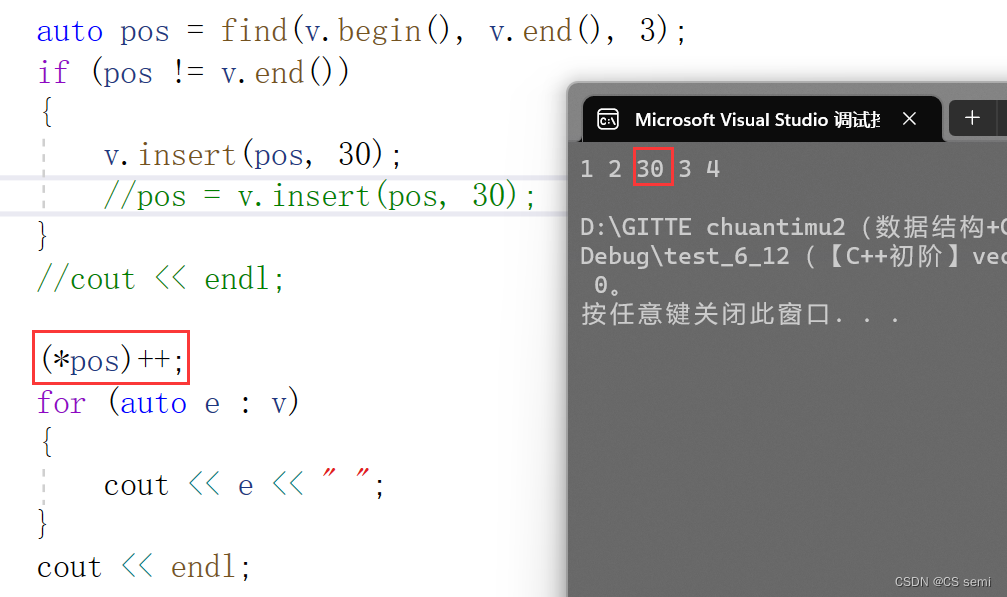
insert后面没有返回值以后没有返回iterator以后我们认为pos失效了,不能在使用了。
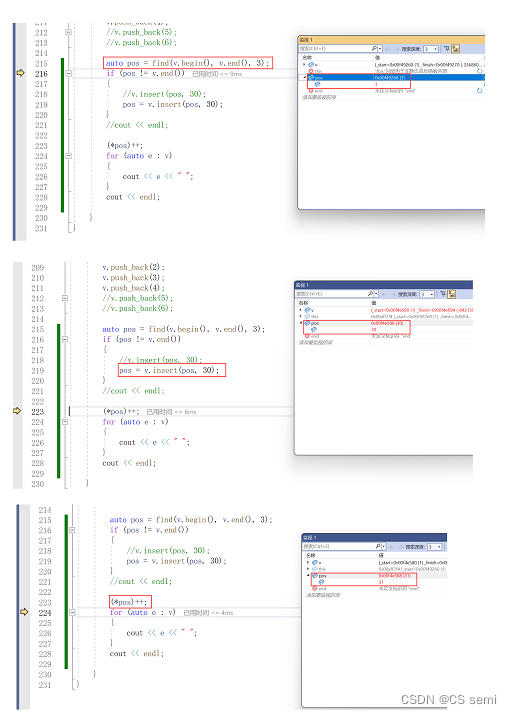
我们走入调试看一下:
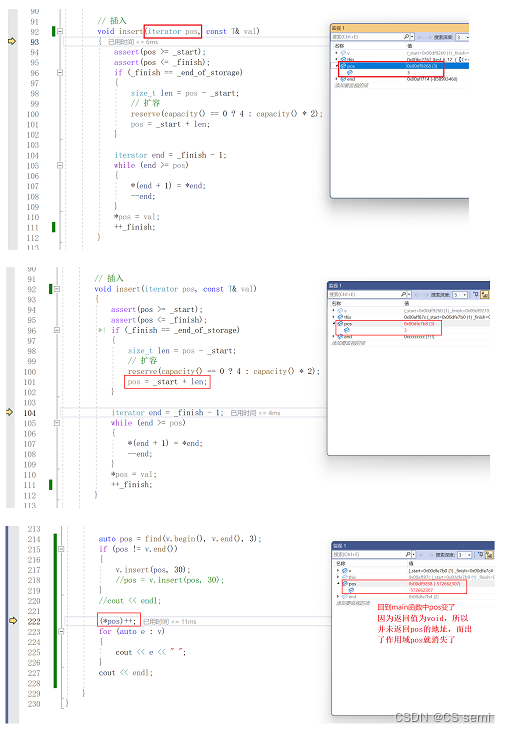
解决方法:
调试走一下:
3、erase在linux的g++情况下和在vs情况下迭代器失效问题的不同
这段较为长,我们细细来讲解。
vs下:
首先我们先写一下erase函数:
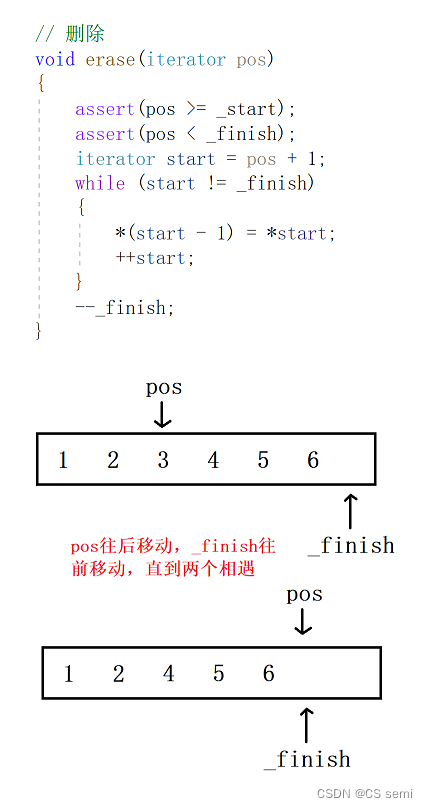
我们进入一下测试,发现很不错,很香,和我们的顺序表一样,都是可以的:
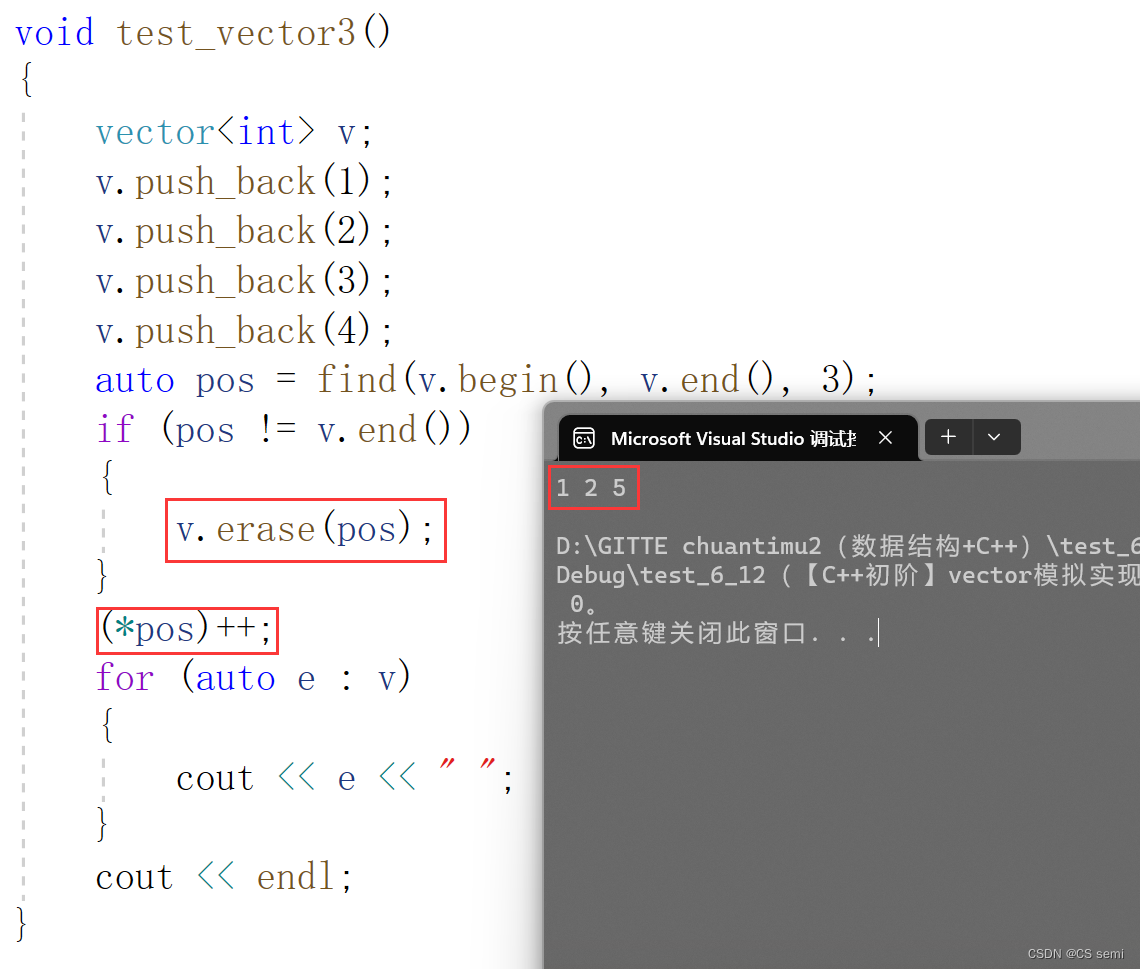
可是事实真是这样吗?我们看一下库函数erase的实现吧:
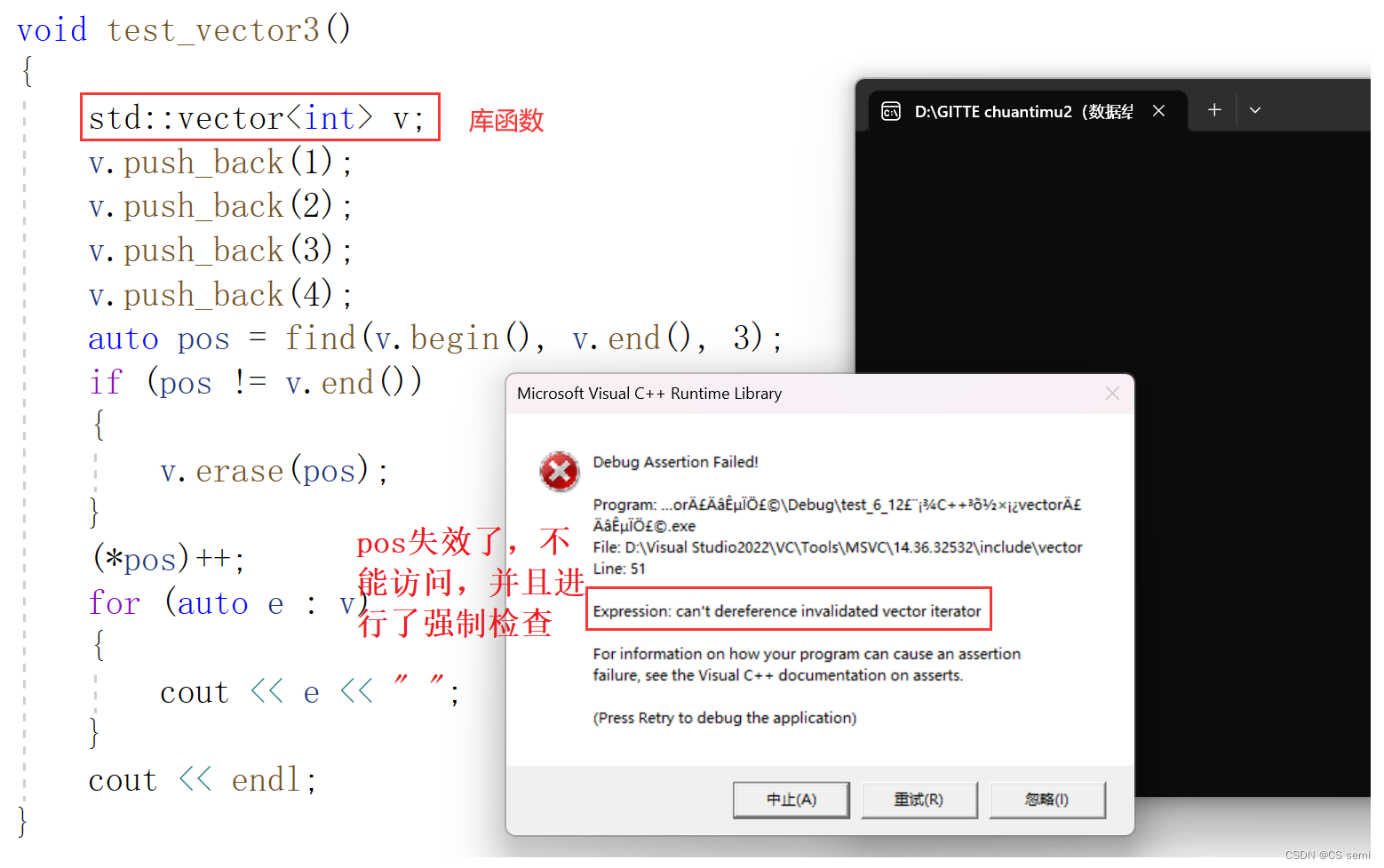
发现怎么会这样报错呢?迭代器是失效了,说明我们的代码是错误的,我们走一下linux下g++来看一看吧。
linux下:
发现没问题啊!
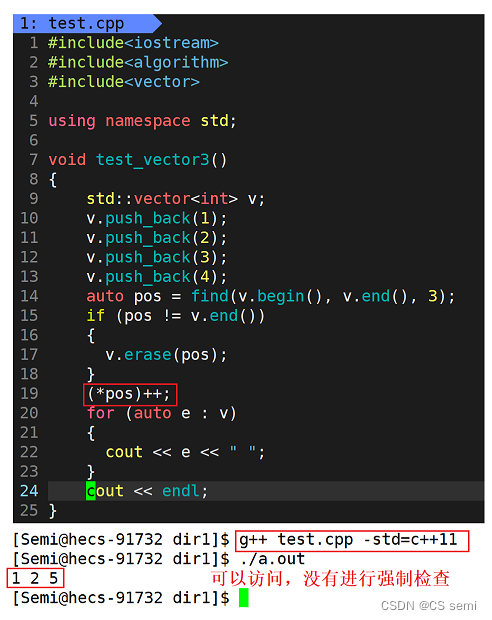
接下来我们思考一个问题,如果我们想要删除的在最后那个位置呢(也就是尾删)?我们在vs下走自己写的和库函数一下一看,以及我们在linux下跑的代码:
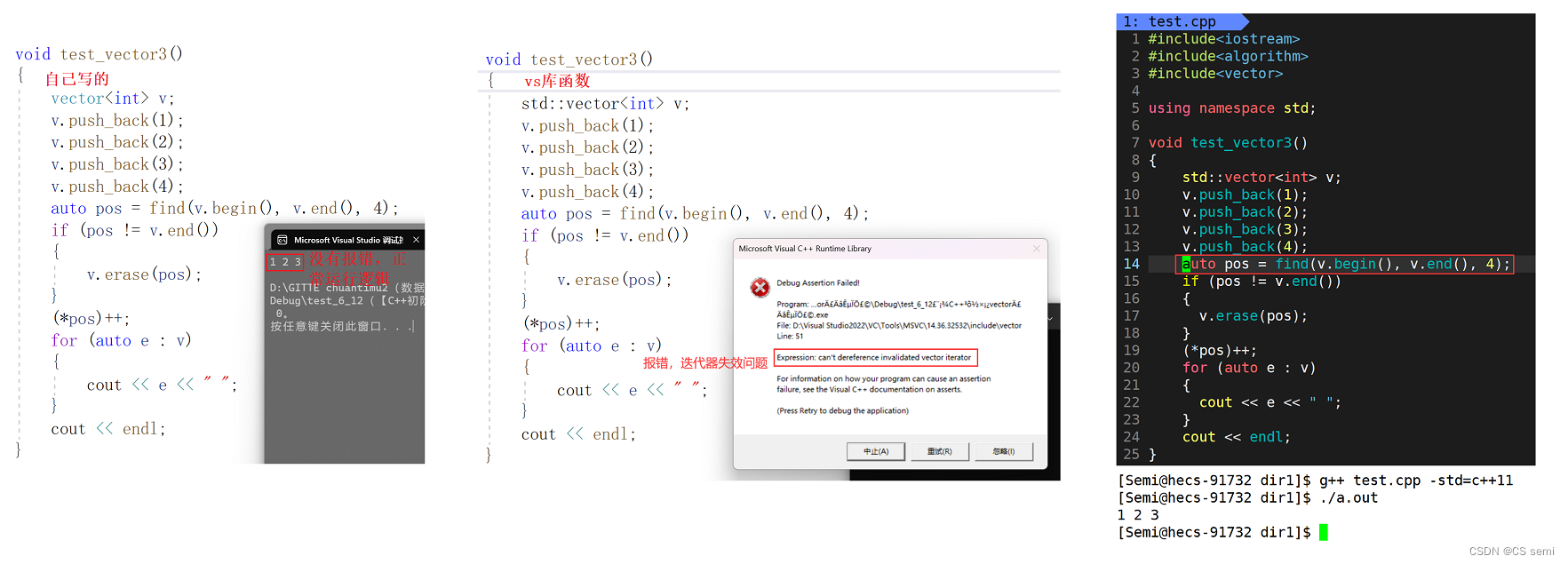
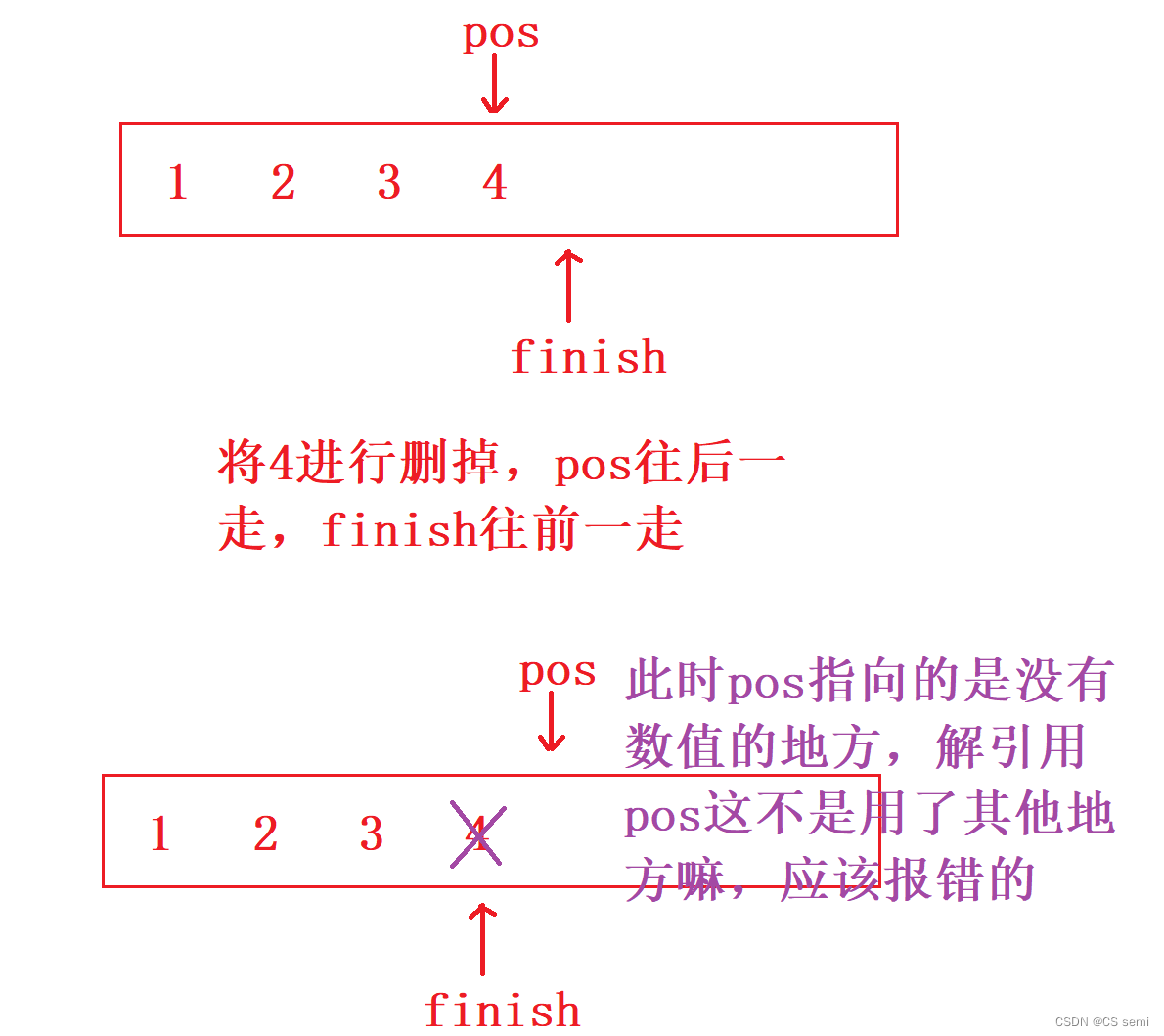
我们引入一个话题,我们做一个要求删除所有的偶数的小练习:
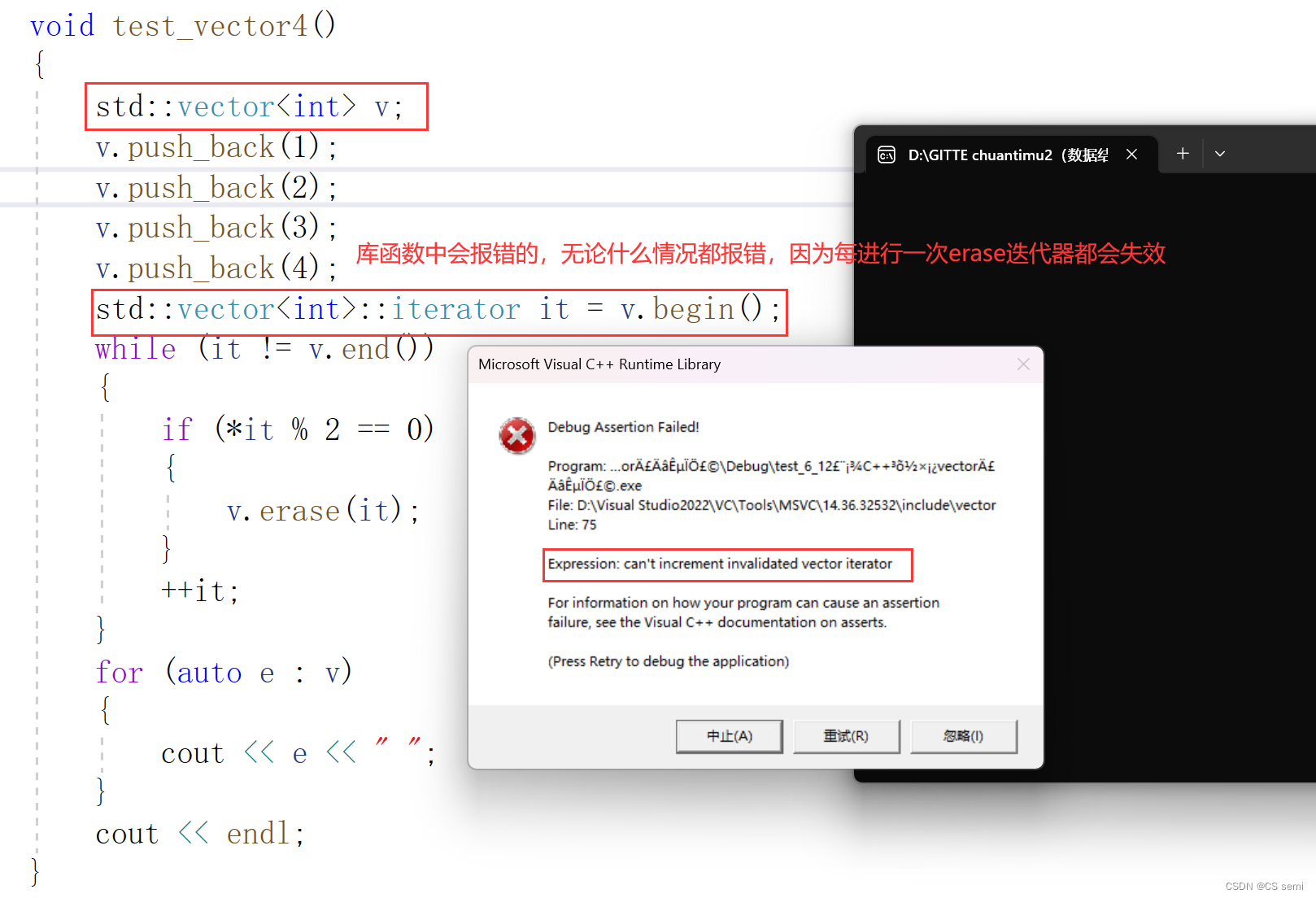
vs库函数下:
vs库函数下实现用的是封装的指针。
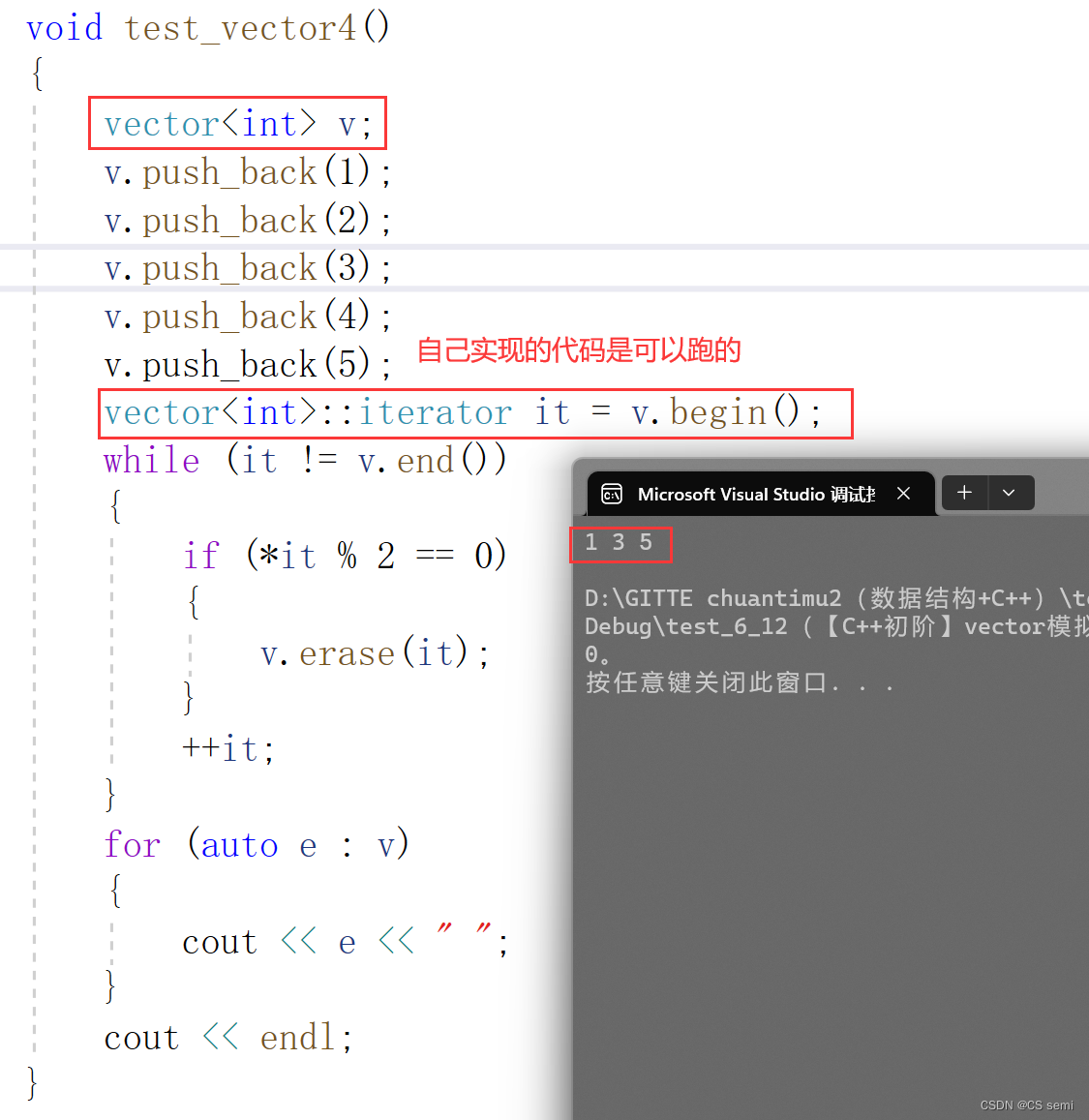
vs自己实现的:
因为我们自己实现的erase函数是用的是原生指针。
linux下:
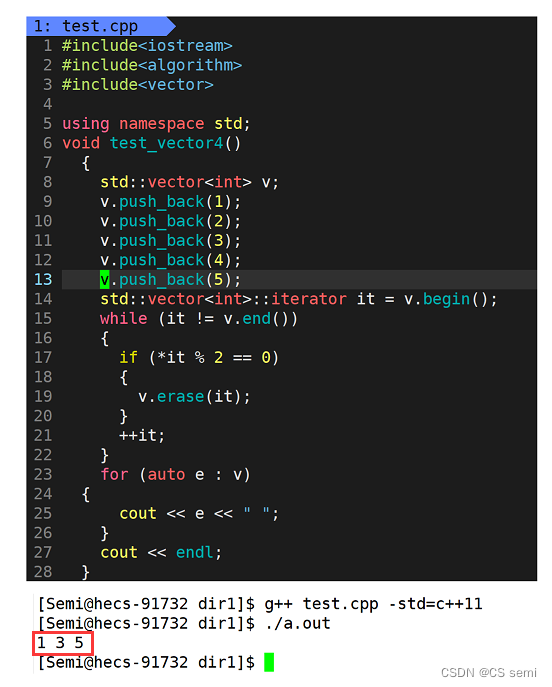
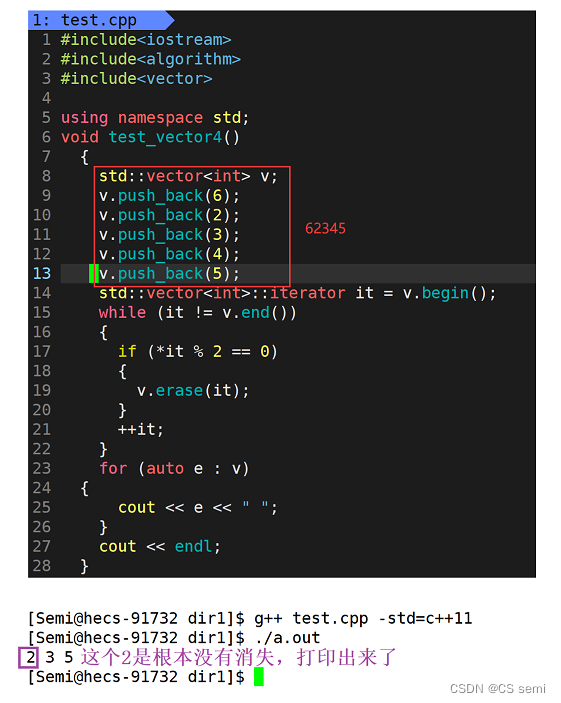
linux下看似没问题,我们改成1234:
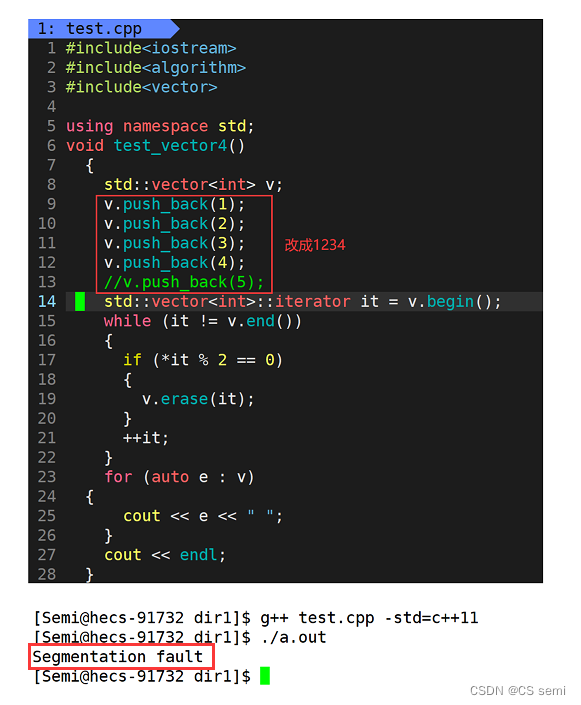
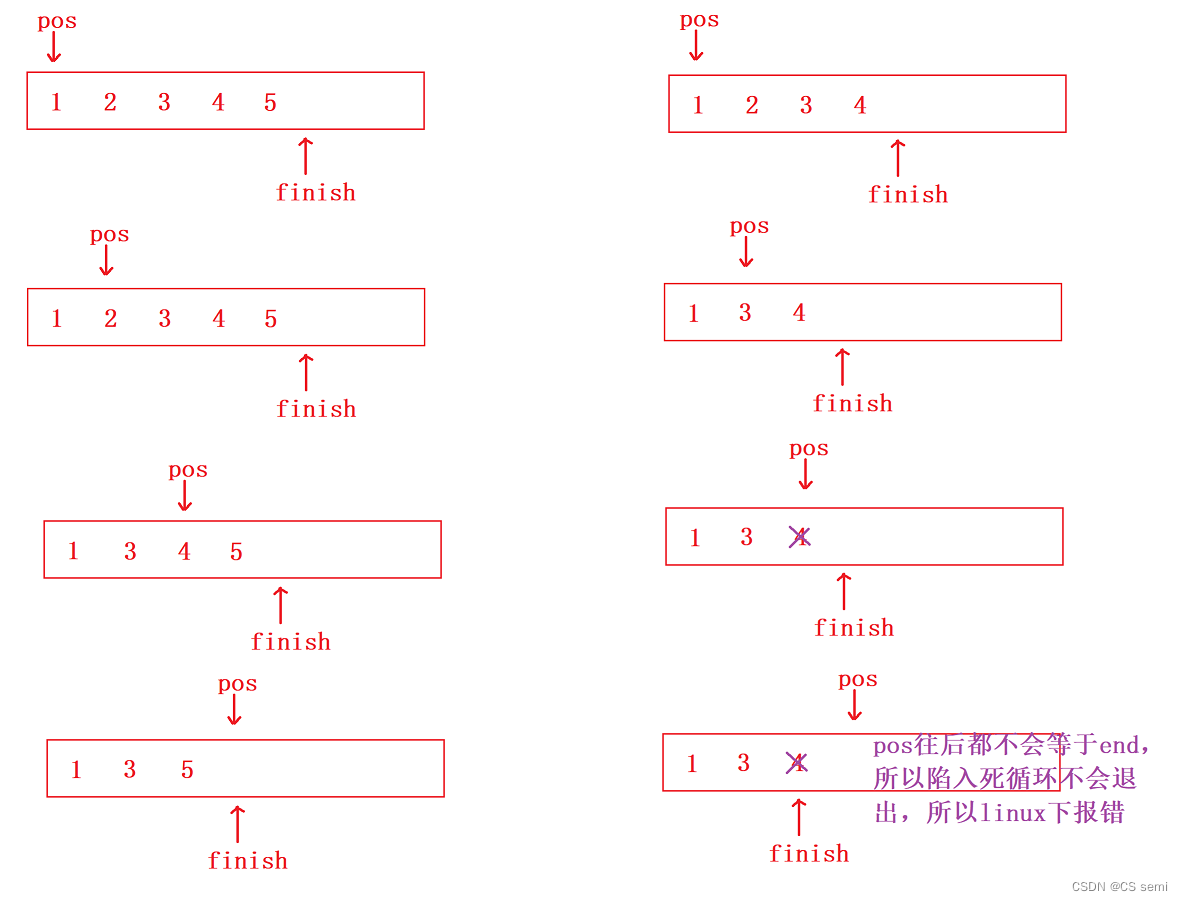
我们想一想一个深层的东西,如果仅仅是将pos改成小于号呢?逻辑上是成立的(这里我们就不演示了),但是我们再用一个连续偶数的例子来打破我们的思维:
我们画一下图来进行演示一下:
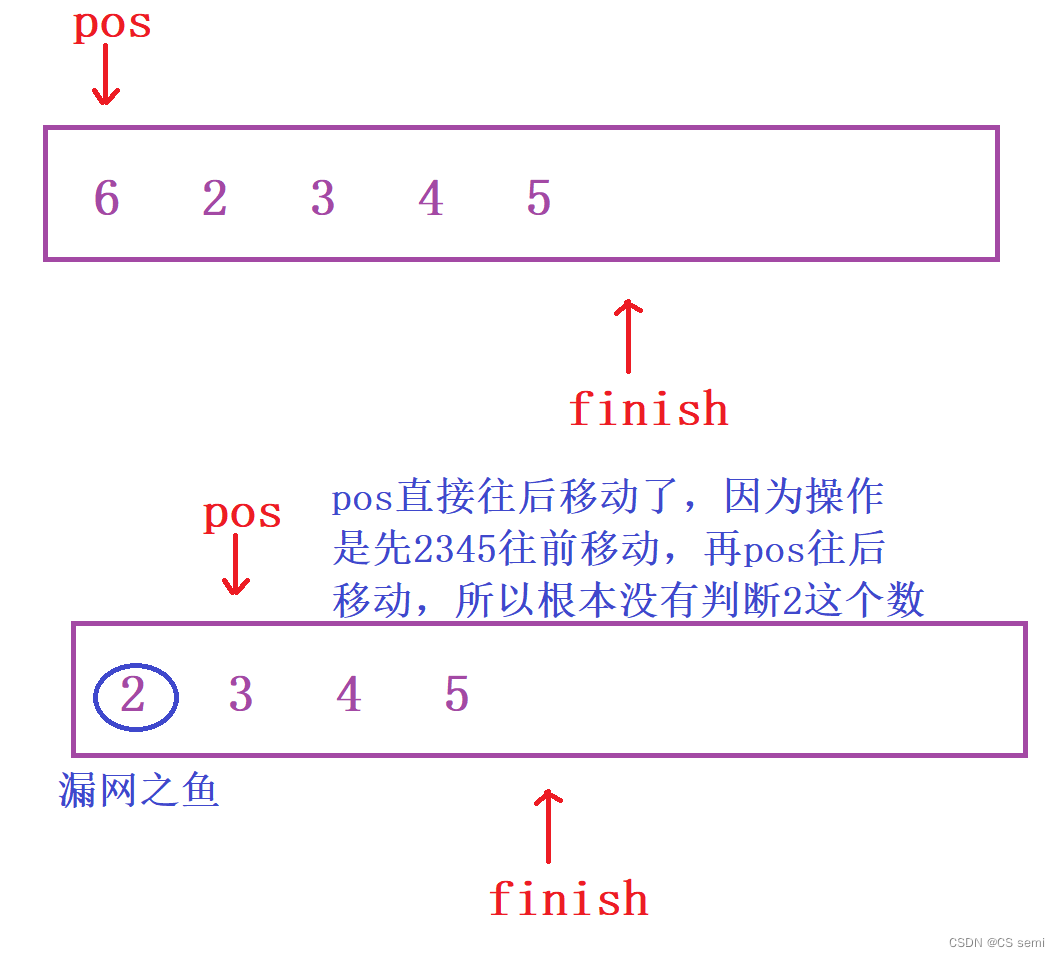
解决方法(加上返回值):
这是库里面实现的:


vs下:
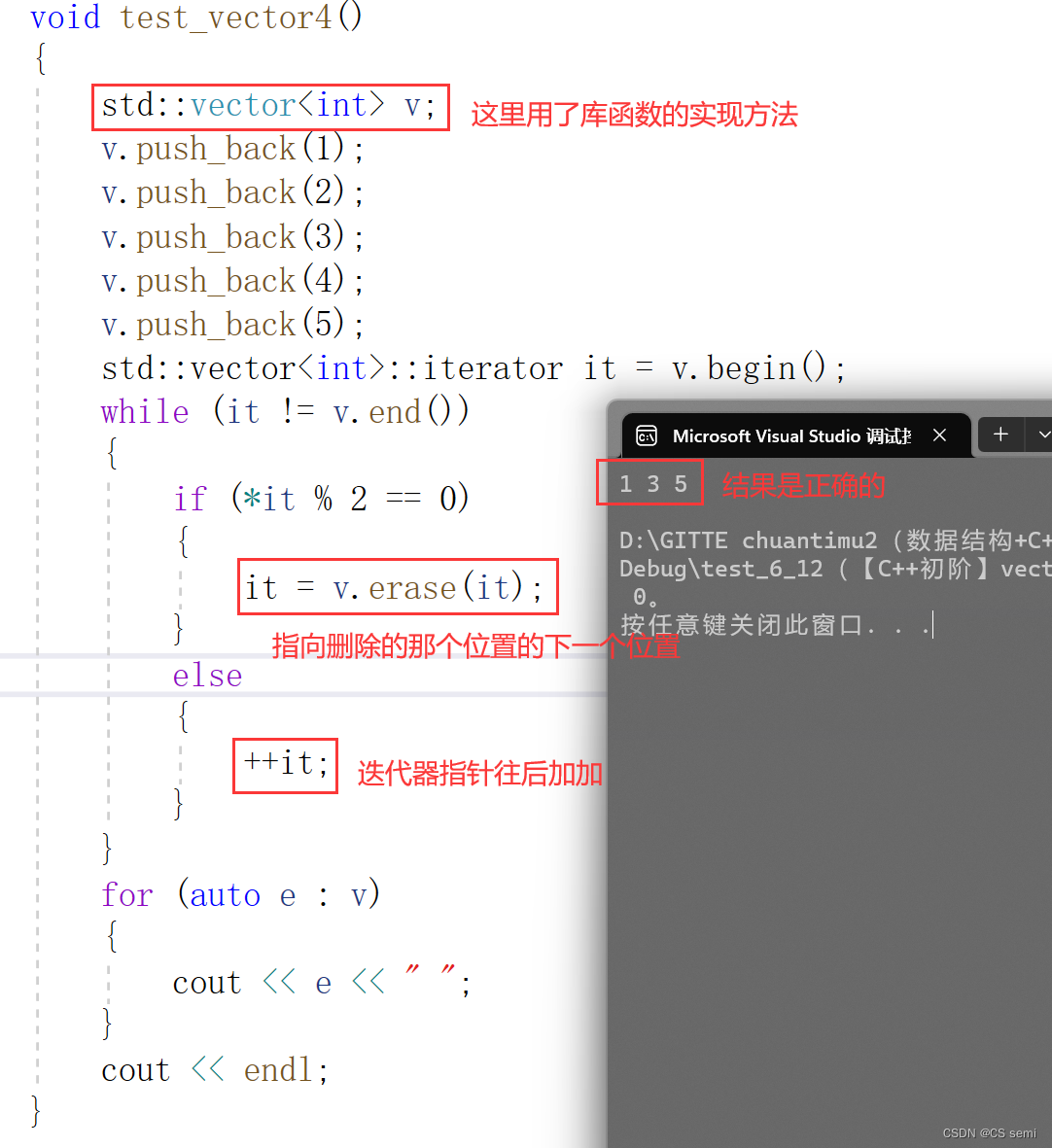
linux下:
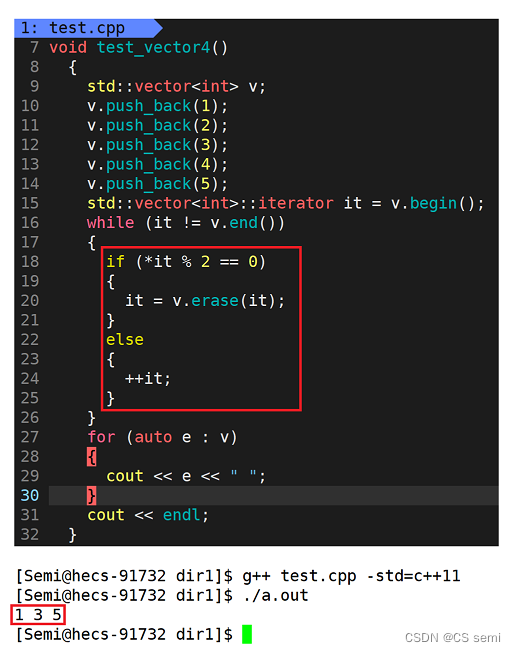
结论
我们的linux的g++下的关于迭代器不更新以后导致的错误是编译器不进行检查,具体问题具体分析,会出现错误;而我们的vs编译器会进行强制检查迭代器是否进行更新,如果未及时更新,那么编译器直接强制报错,所以我们最终加了一个iterator的返回值,使迭代器每进行一次erase就更新一次,这样才不会导致出错。
4、与vector类似,string在插入+扩容操作+erase之后,迭代器也会失效
但我们的string不经常用迭代器,更多的是用下标,所以我们的string用到迭代器失效问题很少。
家人们不要忘记点赞收藏+关注哦!!!
















 5913
5913











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











