






 本文探讨了MySQL数据库如何通过使用不同数据结构(如二叉树、红黑树、B树等)解决磁盘数据存储的无序性和不均匀性问题,重点介绍了B+Tree的选择及其在索引优化中的应用,包括B+Tree的特点和MySQL对它的定制优化。
本文探讨了MySQL数据库如何通过使用不同数据结构(如二叉树、红黑树、B树等)解决磁盘数据存储的无序性和不均匀性问题,重点介绍了B+Tree的选择及其在索引优化中的应用,包括B+Tree的特点和MySQL对它的定制优化。
mysql的底层数据结构的历程
二叉树 => 红黑树 => 哈系树 => b-tree => b+Tree
在线演示连接:Data Structure Visualization
为什么要有一个优异的数据结构?
数据存储在mysql数据库磁盘位置是无序的,是不均匀分布的,为了解决持续的io(输入输出数据)流消耗问题,就必须使用合理的数据结构
如果顺序在磁盘查找,那么要n次而且线性表的插入和删除也很麻烦,如果把数据都给用数据结构排列起来,那么就不是n次,比如,二叉树,只需要logn次
索引就是为了加速对表中数据行的检索而创建的一种排好序的数据结构
索引是帮助mysql高效获取数据的排好序的数据结构
mysql的数据结构的进化过程。
排序二叉树是因为,如果是12345678一边大的话,就查询仍然很慢
平衡二叉树(左子树和右子树高度之差的绝对值不大于1)是因为,插入数据的时候要保持二叉树的平衡,而保持二叉树的平衡也需要成本,相当于用插入的成本来弥补查询的效率
如果出现插入一万次,但是查询只用了几次的情况,那么查询就很浪费资源了
红黑树(最长子树不超过最短子树的2倍即可)所以说他的平衡次数少了许多,但是毕竟是二叉树,所以树的高度上来之后,依旧会浪费性能
所以b树出现了(一个有序的多路查询数目)
cpu和磁盘交互内容
cpu和磁盘交互中间有个内存,而内存和磁盘交互,有个最下逻辑单元,称之为页,页一般由操作系统决定多大,一般是4k或者8k,我们在数据交互的时候可以取页的整数倍来进行读取 而一般的b树的一个节点会设置为16k
索引数据结构选型
默认使用B+Tree 5.5版本之前使用的是B-Tree
为什么mysql选择B+tree而不选择B-tree?
B树(B-tree)每个节点都存放了真实的数据,mysql一个根节点数据存储为16KB,会导致每一个节点存储的数据量变小,所以B树的高度会变高,维护的代价大,查询修改性能会越来越低
B+Tree(B-Tree变种,mysql默认):
B+Tree特点:非叶子节点不存储data,只存储索引(冗余),可有存放更多的节点,叶子节点包含了所有索引字段,所有的数据都存放在叶子节点上,叶子节点使用指针访问,提升区间访问性能,从左至右递增
mysql对B-Tree做了优化,叶子节点使用双向指针
mysql使用b+树根节点存储大点的bigint数据则需要8个字节,以及地址mysql中需要6个字节, 一个根节点数据存储16KB数据一个节点大概能存放16kb /(8 + 6)= 1142个元素,叶子节点存放16KB数据, 假设一个数据1KB,那么高度为3就可以存放1142 * 1142 * 16 * 16 = 328,303,488个数据
红黑树的约束
红黑树
定义:本身就是一种特殊的二叉树,每个节点上都有存储位表示节点的颜色,可以是red或black 约束:每个节点是黑色或者红色,根节点为黑色,叶子节点(特指空节点)是黑色,每个红色节点的子节点都是黑色的,任何一个节点到其每一个叶子节点的所有路径上黑色节点数相同 特点:速度特别快,趋近平衡树,查找叶子元素最少和最多次数不多余二倍
1索引结构B树,Hash、B+树详解
b-Tree的模样
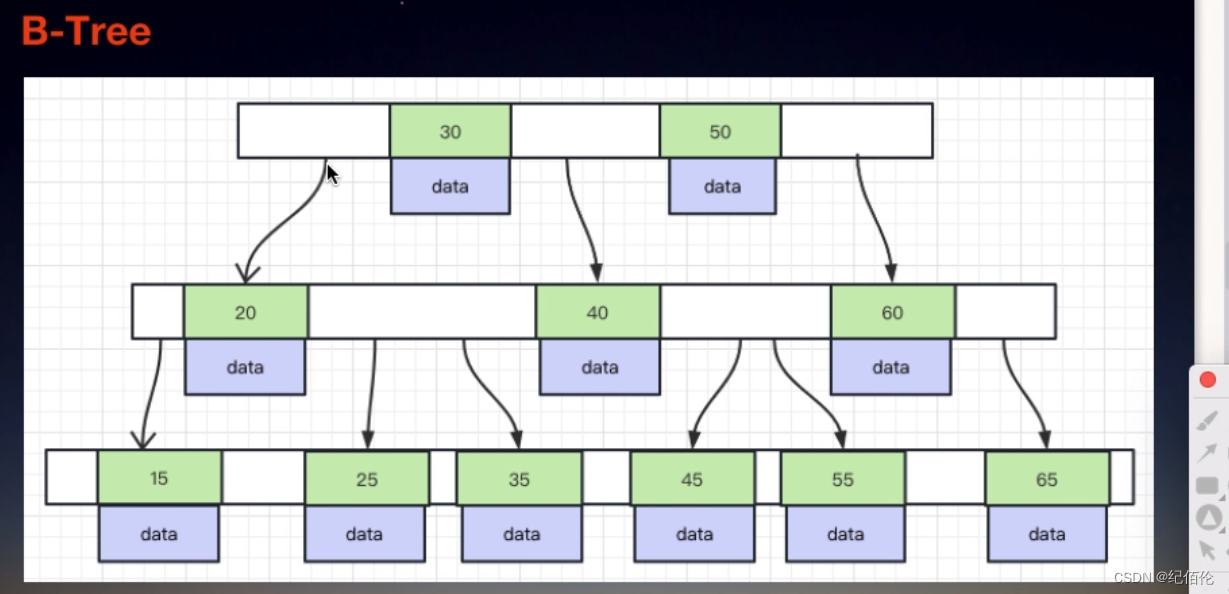
叶节点具有相同的深度,叶节点的指针为空
所有的索引元素不重复
节点中的数据索引从左到右递增排序
B+树就是特殊的B树

非叶子节点不存储data,只存储索引(冗余),可以存放更多的索引
叶子节点包含所有的索引字段
叶子节点用指针连接,提高区间访问的性能















 2919
2919











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









