






yolov8实现猫狗识别
前言
参加一个实训项目,主要是利用yolov8实现猫狗识别。
利用的技术有:labeling yolov8等
主要的环境搭建:anaconda环境(主要是利用conda的虚拟环境来实现技术) pycharm环境(部署yolov8以及训练)
项目的关键在于环境的部署以及训练集的标记与yolov8的训练,最终实现猫狗识别
labelimg实现数据标注
创建conda虚拟环境打开labelimg软件进行数据标注进行手动标注
产生 数据集与标注集 如下

标注集与数据集一一对应
yolov8源码的部署与训练自己的训练集
在使用yolov8之前,需要下载CUDA来开启GPU加速,在下载之前要查看自己显卡适应的版本
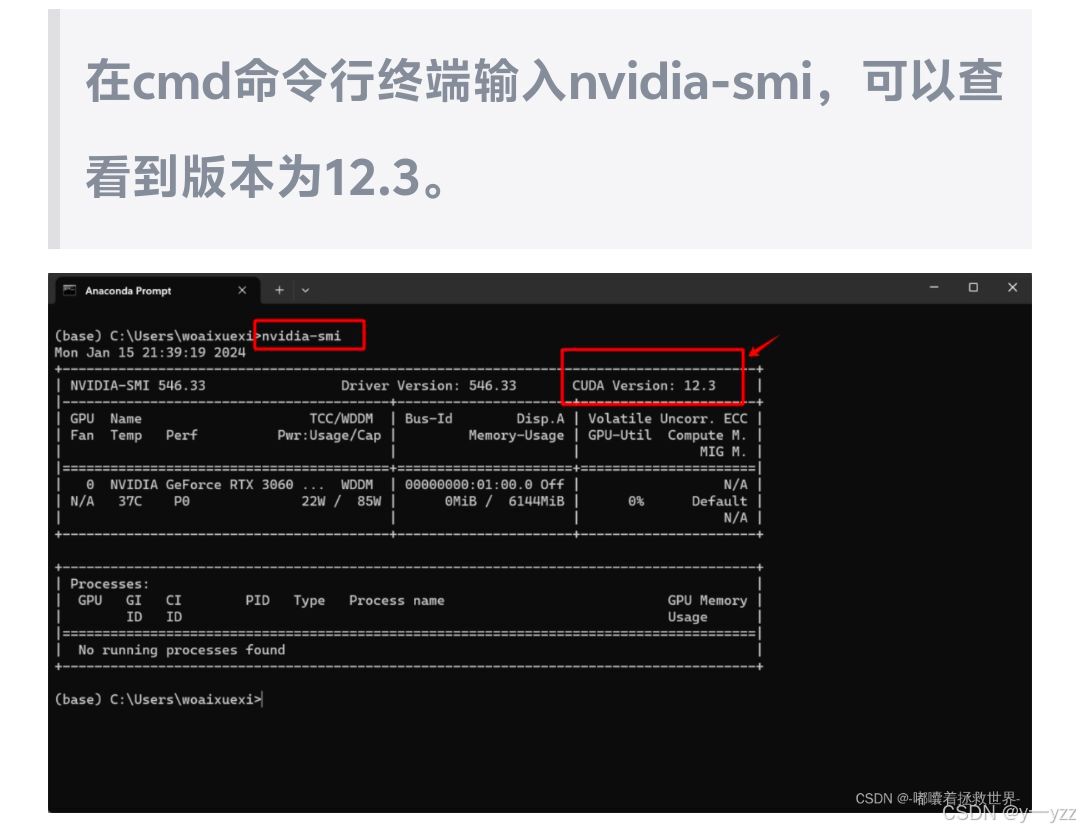
安装完之后,还需要安装pytorch-GPU,需要在conda的虚拟环境中安装(用pip命令安装),防止环境依赖之间的错误,
安装完之后就要开始部署项目了

从github上下载源码,然后在pycharm中打开,然后把与训练的权重放到代码的根目的下,如下:
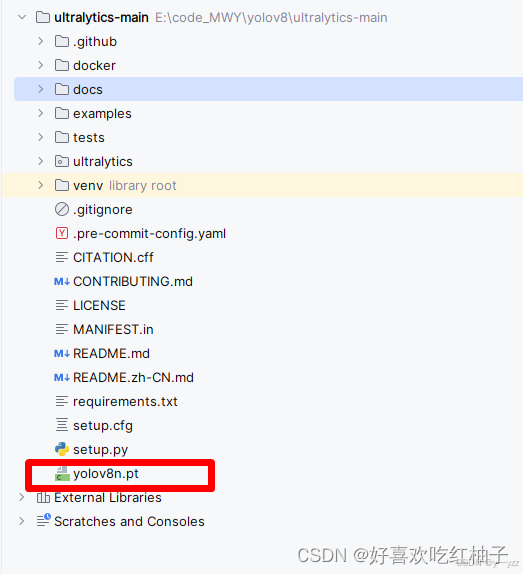
然后就把准备好的训练集放到指定位置,准备训练

将我们的imgae与label替换,文件夹下分别是cat 与 dog(就是放在datasets这个文件夹下,这里我没替换),然后创建yaml文件,文件内容如下
#Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../../person_42_yolo_format
train: # train images (relative to 'path') 16551 images
- images/train
val: # val images (relative to 'path') 4952 images
- images/val
test: # test images (optional)
- images/test
Classes
['Chave', 'DISJUNTOR', 'TP', 'Pararraio', 'TC']
names:
0: cat
1: dog
names代表训练集有几种类别,我们这里只有cat 与 dog 两种
train,val,test的比例不同,但放的图片一样,训练集里的图最多,按数量分配
├─images # 图像文件夹
│ ├─train # 训练集图像
│ ├─val # 验证集图像
│ └─test # 测试集图像
└─labels # 标签文件夹,标签格式为yolo的txt格式
├─train # 训练集标签
├─val # 验证集标签
└─test # 测试集标签
设置完之后可以执行训练脚本如下
import time
from ultralytics import YOLO
yolov8n模型训练:训练模型的数据为'A_my_data.yaml',轮数为100,图片大小为640,设备为本地的GPU显卡,关闭多线程的加载,图像加载的批次大小为4,开启图片缓存
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
results = model.train(data='A_my_data.yaml', epochs=100, imgsz=640, device=[0,], workers=0, batch=4, cache=True) # 开始训练
time.sleep(10) # 睡眠10s,主要是用于服务器多次训练的过程中使用
产生结果如下:
会在runs目录下生成一系列的结果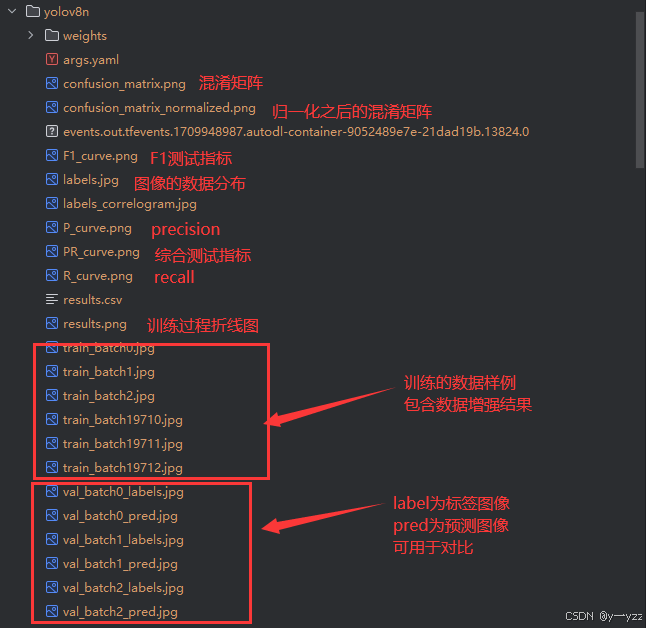
训练完之后进行模型的测试
测试脚本:
from ultralytics import YOLO
# 加载自己训练好的模型,填写相对于这个脚本的相对路径或者填写绝对路径均可
model = YOLO("runs/detect/yolov8n/weights/best.pt")
# 开始进行验证,验证的数据集为'A_my_data.yaml',图像大小为640,批次大小为4,置信度分数为0.25,交并比的阈值为0.6,设备为0,关闭多线程(windows下使用多线程加载数据容易出现问题)
validation_results = model.val(data='A_my_data.yaml', imgsz=640, batch=4, conf=0.25, iou=0.6, device="0", workers=0)
最后直接使用下面代码实现猫狗识别
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n.pt") # pretrained YOLOv8n model
# Run batched inference on a list of images
results = model(["images/resources/demo.jpg", ]) # return a list of Results objects
# Process results list
for result in results:
boxes = result.boxes # Boxes object for bounding box outputs
masks = result.masks # Masks object for segmentation masks outputs
keypoints = result.keypoints # Keypoints object for pose outputs
probs = result.probs # Probs object for classification outputs
obb = result.obb # Oriented boxes object for OBB outputs
result.show() # display to screen
result.save(filename="images/resources/result.jpg") # save to disk
最后的结果如下
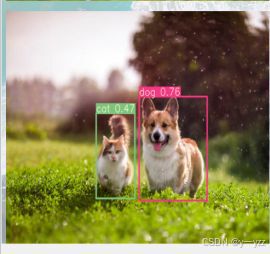
完成猫狗识别

















 1351
1351

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









