







注:该学习笔记是根据曾志贤老师编写的《Python数据分析实战:从Excel轻松入门Pandas》所学习整理的笔记。
第4章 表格管理技术
一、表格属性获取与修改
1、表格属性的获取
1)、表格行数、列数和元素个数获取
- df.shape属性:获取DataFrame表格的行数与列数
- df.size属性:获取DataFrame表格的元素个数
注意:df.shape属性获取df表的行数和列数是存储在元组中的,所以只获取行数可用df.shape[0]表示,只获取列数用df.shape[1]表示。
import pandas as pd
df = pd.read_excel('4-1.xlsx', 0)
# 获取行、列数
print(df.shape)
# 返回 (行, 列)
# 只获取行数
print(df.shape[0])
# 返回行数
# 只获取列数
print(df.shape[1])
# 返回列数
# 获取元素个数
print(df.size)
# 返回 元素个数
2)、表格行索引和列索引的获取
- df.index属性:获取DataFrame表格的行索引
- df.columns属性:获取DataFrame表格的列索引
- df.axes属性:同时获取DataFrame表格的行、列索引
注意:df.axes属性获取df表格的行、列索引是存储在列表中的,所以只获取行索引可以用df.axes[0]表示,只获取列索引可以用df.axes[1]表示。
import pandas as pd
df = pd.read_excel('4-1.xlsx', 0)
# 获取行索引
print(df.index)
# 获取列索引
print(df.columns)
# 同时获取行、列索引
print(df.axes)
# 通过对axes切片获取行索引
print(df.axes[0])
# 通过对axes切片获取列索引
print(df.axes[1])
3)、表格列数据类型的获取
df.dtypes属性:获取DataFrame表格中各列的数据类型
import pandas as pd
df = pd.read_excel('4-1.xlsx', 0)
# 获取表格中各列的数据类型
print(df.dtypes)
4)、表格数据的获取
(1)以数组方式获取表格数据
df.values属性:以数组的方式获取DataFrame表格数据
import pandas as pd
import numpy as np
df = pd.read_excel('4-2.xlsx', 0)
# 获取DataFrame全部数据(不含列标题)
print(df.values)
# 通过转换格式获取数据
print(df.to_numpy())
# 通过NumPy的数组来获取数据
print(np.array(df))
(2)以生成器方式获取表格数据
df.iterrows( )属性:按行获取DataFrame数据,返回生成器,如果不加( ),则直接返回值
df.iteritems( )属性:按列获取DataFrame数据,返回生成器,如果不加( ),则直接返回值
import pandas as pd
# 按行获取数据,返回生成器
print(df.iterrows())
# 按列获取数据,返回生成器
print(df.iteritems())
(3)、循环输出表格数据
注意:除了通过循环方式获取df.iteritems( )和df.iterrows( )中的数据外,还可以用列表函数list( )将df.iteritems( )和df.iterrows( )中的数据转换为列表,如list(df.iteritems( ))和list(df.iterrows( )),但如果数据太大不建议这样做。
import pandas as pd
import numpy as np
df = pd.read_excel('4-2.xlsx', 0)
# 循环行获取的数据
for key, val in df.iterrows():
# 返回行索引的值
print(key)
# 按照行的形式返回数据,使用的Series数据结构
print(val)
# 循环列获取的数据
for key, val in df.iteritems():
# 返回列索引的值
print(key)
# 按照列的形式返回数据,使用的Series数据结构
print(val)
# 循环values获取数据的方式
for val in df.values:
# 按行的形式返回数据,使用的是数组的数据结构
print(val)
# 循环转换格式方式获取的数据
for val in df.to_numpy():
# 按行的形式返回数据,使用的是数组的数据结构
print(val)
# 循环NumPy数组结构的方式获取的数据
for val in np.array(df):
# 按行的形式返回数据,使用的是数组的数据结构
print(val)
# 使用Python的类型函数转换
print(list(df.iterrows()))
2、表格属性修改
1)、创建表格时修改行索引和列索引
(1)新建表格时修改属性
在使用pd.DataFrame( )函数创建表格时,对index参数设置行索引,对columns参数设置列索引,对dtype参数设置数据类型。
import pandas as pd
df = pd.DataFrame(
[[1, 2, 3], [4, 5, 6], [7, 8, 9]],
index=['001', '002', '003'],
columns=['A', 'B', 'C'],
dtype='int'
)
注意:pd.DataFrame( )函数中的dtype参数只能对整个表格设置,如果需要对指定列设置类型,则data参数只能是数组,并且在生成数组时设置。
import pandas as pd
import numpy as np
# 修改每列单独的数据类型时,必须先单独创建好列标题组
dt = np.dtype([('姓名', 'U4'), ('年龄', 'int'), ('分数', 'float')])
# 创建数组时,将数据类型设置为单独创建好列标题组
arr = np.array([
('张三', 15, 96.3),
('李四', 12, 94.3),
('王五', 13, 97),
('赵六', 18, 98.8)],
dtype=dt)
print(pd.DataFrame(arr))
(2)导入外部数据时修改属性
- pd.read_excel( )函数自动将工作表的第1行设置为表格的列索引,而行索引则默认为序列值。
- 将工作表中的第2行作为表格的列索引,则需要将pd.read_excel( )函数中的header参数设置为1。
- 将工作表中的第1列作为表格的行索引,则需要将pd.read_excel( )函数中的index_col参数设置为0。
- 如果需要将某列修改为特定数据类型,则需要将dtype参数设置为{‘A列标题’: ‘数据类型’, ‘B列标题’: ‘数据类型’}的方式。
import pandas as pd
df = pd.read_excel(
# 读取工作簿
io='4-4.xlsx',
# 读取工作表
sheet_name=0,
# 设置指定行为列标题
header=1,
# 设置指定列为行标题
index_col=0,
# 修改指定列的数据类型
dtype={'部门': 'str', '销售额': 'float'}
)
print(df)
2)、已经存在表格的修改
(1)重新设置行索引和列索引
- df.index属性:对行索引进行修改
- df.columns属性:对列索引进行修改
import pandas as pd
df = pd.read_excel(
io='4-5.xlsx',
sheet_name=0
)
# 修改行索引
df.index = ['a', 'b', 'c', 'd']
# 修改列索引
df.columns = ['名字', '考试日期', '语文', '数学']
print(df)
(2)重新设置列数据类型
- 设置DataFrame表格的列数据类型使用astype( )函数,在此函数的参数中写入要转换的数据类型
- 对不同列设置不同数据类型,则可以在astype( )函数的参数中用字典的方式表示为{‘A列标题’: ‘数据类型’, ‘B列标题’: ‘数据类型’}的方式。
import pandas as pd
df = pd.read_excel(
io='4-5.xlsx',
sheet_name=0
)
# 修改指定类的数据类型
df.astype({
'理论': 'float',
'实操': 'int',
'通过日期': 'datetime64[Y]'
})
print(df)
二、表格的切片选择
1、切片法
切片法的基础结构为df[…],在此基础结构上进行变化,可以选择出行、列和区域。
1)、行选择
无论表格的行索引是否设置了标签,都可以按行索引序号选择行。
除了使用后行索引序号去选择行以外,也可以使用行索引的标签选择行。
注意:在使用切片法选择行时,无论是选择单行还是多行,选择的结果均返回DataFrame类型的表格。
import pandas as pd
df = pd.read_excel('4-6.xlsx', 0, index_col=0)
# 使用行索引来获取单列,左闭右开的原则
print(df[1:2])
# 使用行索引来获取多列
print(df[1:3])
# 使用标签来获取列
print(df['NED001':'NED003'])
2)、列选择
注意:如果选择的是单列,则返回的是Series类型的数据,如果选择的是多列,则返回的是DataFrame类型的表格。
(1)单列选择
单列选择不但可以表示为df[‘列标签’],还可以表示为df.列标签
import pandas as pd
df = pd.read_excel('4-6.xlsx', 0, index_col=0)
# 单列的选择
print(df['姓名'])
print(df.姓名)
(2)多列选择
多列选择试讲列索引便签放置在列表、数组和Series等数据结构中
import pandas as pd
df = pd.read_excel('4-6.xlsx', 0, index_col=0)
# 多列的选择
print(df[['姓名', '1月']])
3)、区域选择
区域选择就是多行多列的选择,也就是将行和列的选择交叉在一起,书写格式为df[行索引][列索引],从而形成选择表格部分区域的效果。
import pandas as pd
df = pd.read_excel('4-6.xlsx', 0, index_col=0)
# 区域的选择,行列部分先后
print(df[['姓名', '1月']][1:5])
print(df[1:5][['姓名', '1月']])
2、筛选法
筛选只能选择行,不能选择列
1)、行选择
行的筛选格式为df[条件表达式]
- 在df[ ]中提供了一组布尔值,这组布尔值必须遵循以下两点要求
- 布尔值的元素个数必须与df表的行数相同,因为布尔值与df表的行时意义对应的,True表示选择,False表示不选择。
- 布尔值必须存储在列表、数组和Series等数据结构中。
import pandas as pd
df = pd.read_excel('4-7.xlsx', 0)
# df['总分'] >= 150,得到一组布尔值
print(df[df['总分'] >= 150])
2)、列选择
无
3)、区域选择
import pandas as pd
df = pd.read_excel('4-7.xlsx', 0)
# 区域选择,在筛选完行后,在进行列的切片
print(df[df['总分'] >= 150][['姓名', '总分']])
3、loc切片法
loc切片法相当于直接切片法的升级,表示方法为df.loc[行切片,列切片]。在此基础结构上进行变化,可以实现行、列和区域3种选择方法。
1)、行选择
- 行的选择方式分为单行选择、连续多行选择和不连续多行选择3种。
- 如果行索引为自然序号:则格式只能表示为df.loc[行索引序号]。
- 如果行索引为标签:则格式只能表示为df.loc[‘行索引标签’]。
(1)单行选择
- 行索引是自然序号:则表示方式为df.loc[单个行索引序号]。
- 行索引是标签:则表示方式为df.loc[‘单个行索引标签’]。
注意:使用loc切片法选择的单行,返回结果不是DataFrame表格,而是Series数据。
import pandas as pd
# 行索引为自然序号
df1 = pd.read_excel('4-8.xlsx', 0)
# 选择单行,Series数据结构
print(df1.loc[1])
# 选择单行,DataFrame表格结构
print(df1.loc[1:1])
# 行索引为标签
df2 = pd.read_excel('4-8.xlsx', 0, index_col=0)
# 选择单行,Series数据结构
print(df2.loc['小曾'])
# 选择单行,DataFrame表格结构
print(df2.loc['小曾':'小曾'])
(2)连续多行选择
- 行索引是自然序号:则表示方式为df.loc[起始行索引序号:终止行索引序号]。
- 行索引是标签:则表示方法为df.loc[起始行索引标签:终止行索引标签]。
import pandas as pd
# 行索引为自然序号
df1 = pd.read_excel('4-8.xlsx', 0)
# 选择连续多行
print(df1.loc[1:3])
# 行索引为标签
df2 = pd.read_excel('4-8.xlsx', 0, index_col=0)
# 选择连续多行
print(df2.loc['小曾':'小林'])
(3)不连续多行选择
将行索引对应的序号或者标签写入列表、数组和Series等数据结构中,序号或者签标可以不按顺序排列。
import pandas as pd
# 行索引为自然序号,顺序可打乱
df1 = pd.read_excel('4-8.xlsx', 0)
print(df1.loc[[2, 0, 4]])
# 行索引为标签,顺序可打乱
df2 = pd.read_excel('4-8.xlsx', 0, index_col=0)
print(df2.loc[['小林', '小王', '小李']])
2)、列选择
- 列的选择方式分为单列选择、连续多列选择和不连续多列选择3种。
- 列索引为自然序号:格式只能表示为df.loc[:,列索引序号]。
- 列索引为标签:格式只能表示为df.loc[:,‘列索引标签’]。
(1)单列选择
- 列索引是自然序号:则表示方式为df.loc[:,单个列索引序号]。
- 列索引是标签:则表示方式为df.loc[:,‘单个列索引标签’]。
注意:使用loc切片法选择的单行,返回结果不是DataFrame表格,而是Series数据。
import pandas as pd
# 列索引为自然序号
df = pd.read_excel('4-9.xlsx', 0)
# 选择单列,Series数据结构
print(df.loc[:, '姓名'])
# 选择单列,DataFrame表格结构
print(df.loc[:, '姓名':'姓名'])
(2)连续多列选择
- 列索引是自然序号:则表示方式为df.loc[:,起始列索引序号:终止列索引序号]。
- 列索引是标签:则表示方式为df.loc[:,起始列索引标签:终止列索引标签]。
注意:loc不遵循左闭右开,loc是双开。
import pandas as pd
# 列索引为标签
df = pd.read_excel('4-9.xlsx', 0)
# 选择连续多列
print(df.loc[:, '姓名':'性别'])
(3)不连续多列选择
将列索引对应的序号或者标签写入列表、数组和Series等数据结构中,序号或者签标可以不按顺序排列。
import pandas as pd
# 列索引为标签,顺序可打乱
df = pd.read_excel('4-9.xlsx', 0)
print(df.loc[:, ['总分', '性别', '姓名']])
3)、区域选择
import pandas as pd
# 区域选择
df = pd.read_excel('4-9.xlsx', 0)
# 连续列的区域选择
print(df.loc[1:3, '姓名':'性别'])
# 非连续列的区域选择
print(df.loc[1:3, ['总分', '性别', '姓名']])
# 筛选区域选择
print(df.loc[df.总分 >= 150, '姓名':'性别'])
4、iloc切片法
iloc切片法与loc切片法的用法相似,但无论DataFrame表格的行列索引是自然序号还是标签,iloc都只能用索引序号来做切片。同时也不能像loc一样对DataFrame表格的行执行筛选。
| 选择方式 | 直接切片法 | 筛选法 | loc切片法 | iloc切片法 |
|---|---|---|---|---|
| 行选择 | df[行索引] | df[条件] | df.loc[行索引] | df.iloc[行索引] |
| 列选择 | df[列索引] | df.loc[:,列索引] | df.iloc[:,列索引] | |
| 区域选择 | df[行索引][列索引] | df[条件][列索引] | df.loc[行索引,列索引] | df.iloc[行索引,列索引] |
注意:可以将筛选法理解为直接切片法和loc切片法的补充。筛选法可以在它们的行索引中应用。
注意:iloc的行与列索引,都遵循左闭右开的原则。而loc不遵循。
三、添加表格的行和列
1、添加行
使用df.append( )函数,可添加单行与多行。
添加单行也可直接表示出添加的行索引的方式。
1)、添加单行
- 添加标签索引:在添加行时,设置了行数据Series的name属性可作为添加行的索引标签。
- 添加自然序号索引:Series的name属性可不设置。但在df.append( )函数的第2参数设置为True,此参数设置自热饭序号添加行索引,默认值为False。
注意:在使用df.append( )添加法和行数据直接添加法时,如果表示的行索引已经存在,df.append( )函数会继续添加新行,而行数据直接添加法则时替换已经存在的行。
(1)df.append( )添加法
使用df.append( )函数添加行时,函数的第1参数数据结构要求是Series或DataFrame,当参数时Series时,添加的是单行。
import pandas as pd
# 添加标签索引的方式
df = pd.read_excel('4-11.xlsx', 0)
s = pd.Series(
data=['NB003', '王二麻子', 100, 99, 120],
index=['编号', '姓名', '语文', '数学', '英语'],
name='new'
)
print(df.append(s))
# 添加自然序号索引的方式
df = pd.read_excel('4-11.xlsx', 0)
s = pd.Series(
data=['NB003', '王二麻子', 100, 99, 120],
index=['编号', '姓名', '语文', '数学', '英语'],
)
print(df.append(s, True))
(2)行数据直接添加法
直接表示出添加的行索引,添加行的数据结构可以是列表、元组、数组等。
import pandas as pd
df = pd.read_excel('4-11.xlsx', 0)
# 使用标签索引的方式添加行
df.loc['new'] = ['NB003', '王二麻子', 100, 99, 120]
# 使用自然序号索引的方式添加行
df.loc[len(df)] = ['NB004', '王二麻子', 100, 99, 120]
2)、添加多行
import pandas as pd
df1 = pd.read_excel('4-11.xlsx', 0)
df2 = pd.read_excel('4-11.xlsx', 1)
# 合并两表,保留原有索引
print(df1.append(df2))
# 合并两表,需写索引
print(df1.append(df2, True))
2、添加列
添加列时的方式:直接添加列、df.assign( )函数
- 直接添加列的方式有两种:
- 使用df[列索引标签]
- df.loc[:,列索引标签]
- df.assign( )函数,一次可添加多个单列,并且是在原始表上添加列
注意: 无论是使用直接添加列的方式,还是使用df.assign( )函数添加列,如果新增列名与原表列名相同,则新增列数据会替换原来的列数据。
import pandas as pd
df = pd.read_excel('4-12.xlsx', 0)
# 添加方式一
df['英语'] = [100, 99, 101]
# 添加方式二
df.loc[:, '生物'] = [88, 75, 94]
# assign添加方式
print(df.assign(历史=[88, 78, 98], 化学=[99, 78, 95]))
四、删除表格的行与列
1、删除行
df.drop( )函数执行删除行
- 语法结构:
- df.drop(序号或标签, axis=0, inplace=True)
- 参数说明:
- 序号或标签:指定的序号或者标签。
- axis:指定为行还是列,默认为行即0。
- inplace:表示是否在原表删除。
1)、删除指定的单行
直接在df.drop( )函数的第1参数指定行索引或行标签即可。
import pandas as pd
df1 = pd.read_excel('4-13.xlsx', 0)
# 删除单行
# inplace为默认值False时,默认将原表复制一份。
df1_fb = df1.drop(2)
print(df1_fb)
# inplace为True时,在原表中操作。
df1.drop(2, inplace=True)
print(df1)
2)、删除指定的多行
将要删除的多行索引号或多行索引标签组织在列表、数组、Series等可迭代对象中,然后放置在df.drop( )函数中的第1参数即可。
import pandas as pd
df1 = pd.read_excel('4-13.xlsx', 0)
# 删除多行
# inplace为默认值False时,默认将原表复制一份。
df1_fb = df1.drop([1, 4])
print(df1_fb)
# inplace为True时,在原表中操作。
df1.drop([1, 4], inplace=True)
print(df1)
2、删除列
df.drop( )函数执行删除列
- 语法结构:
- df.drop(序号或标签, axis=1, inplace=True)
- 参数说明:
- 序号或标签:指定的序号或者标签。
- axis:指定为行还是列,默认为行即0。
- inplace:表示是否在原表删除。
1)、删除指定的单列
直接在df.drop( )函数的第1参数指定列索引或列标签即可。
import pandas as pd
df2 = pd.read_excel('4-13.xlsx', 1, index_col=0)
# 删除单列
# inplace为默认值False时,默认将原表复制一份。
df2_fb = df2.drop('语文', axis=1)
print(df2_fb)
# inplace为True时,在原表中操作。
df2.drop('语文', axis=1, inplace=True)
print(df2)
2)、删除指定的多列
将要删除的多列索引号或多列索引标签组织在列表、数组、Series等可迭代对象中,然后放置在df.drop( )函数中的第1参数即可。
import pandas as pd
df2 = pd.read_excel('4-13.xlsx', 1, index_col=0)
# 删除多列
# inplace为默认值False时,默认将原表复制一份。
df2_fb = df2.drop(['英语', '地理'], axis=1)
# inplace为True时,在原表中操作。
df2.drop(['英语', '地理'], axis=1, inplace=True)
print(df2)
3、删除有缺失值的行和列
使用df.dropna( )专用函数
- 语法结构:
- df.dropna(axis=指定删除方向, how=指定删除方式, inplace=True)
- 参数说明:
- axis:默认值为0即行
- how:参数’all’表示全是缺失值,参数为’any’表示包含缺失值。
- inplace:表示是否在原表删除。
1)、删除整行都是缺失值的行
在df.dropna( )函数中指定axis参数为0,how参数为’all’是关键。
import pandas as pd
df1 = pd.read_excel('4-14.xlsx', 0)
# 删除整行都是缺失值的行
df1.dropna(axis=0, how='all', inplace=True)
print(df1)
2)、删除整列都是缺失值的列
在df.dropna( )函数中指定axis参数为1,how参数为’all’是关键。
import pandas as pd
df1 = pd.read_excel('4-14.xlsx', 0)
# 删除整列都是缺失值的列
df1.dropna(axis=1, how='all', inplace=True)
print(df1)
3)、删除有缺失值的所在行
在df.dropna( )函数中指定axis参数为0,how参数为’any’是关键。
import pandas as pd
df2 = pd.read_excel('4-14.xlsx', 1)
# 删除有缺失值的所在行
df2.dropna(axis=0, how='any', inplace=True)
print(df2)
4)、删除有缺失值的所在列
在df.dropna( )函数中指定axis参数为1,how参数为’any’是关键。
import pandas as pd
df2 = pd.read_excel('4-14.xlsx', 1)
# 删除有缺失值的所在列
df2.dropna(axis=1, how='any', inplace=True)
print(df2)
五、表格数据的修改
1、修改单值
使用df.loc[行索引,列索引]或者df.iloc[行索引,列索引]定位要修改的单个值即可。
import pandas as pd
df = pd.read_excel('4-15.xlsx', 0)
# 修改单值
df.loc[1, '数量'] = 500
df.iloc[2, 2] = 200
2、修改单行
使用df.col[行索引]或者df.iloc[行索引]行为要修改的单行即可。
import pandas as pd
df = pd.read_excel('4-15.xlsx', 0)
# 修改单行
df.loc[1] = ['冬瓜', 1.2, 30]
df.iloc[2] = ['青椒', 2.4, 15]
3、修改单列
使用df.col[:,列索引]或者df.iloc[:,列索引]行为要修改的单列即可。
import pandas as pd
df = pd.read_excel('4-15.xlsx', 0)
# 修改单列
df.单价 = [0.1, 0.2, 0.3, 0.4]
df.loc[:, '单价'] = [1.1, 1.2, 1.3, 1.4]
df.iloc[:, 1] = [2.1, 2.2, 2.3, 2.4]
4、修改区域
使用df.loc[行索引,列索引]或者df.iloc[行索引,列索引]定位要修改的区域即可。
import pandas as pd
df = pd.read_excel('4-15.xlsx', 0)
# 修改连续区域,iloc遵循左闭右开的原则
df.loc[1:3, '单价':'数量'] = [[1.1, 11], [1.2, 22], [1.3, 33]]
df.iloc[1:4, 1:3] = [[1.1, 11], [1.2, 22], [1.3, 33]]
# 修改非连续区域,iloc遵循左闭右开的原则
df.loc[[1, 3], ['产品', '数量']] = [['a', 100], ['b', 200]]
df.iloc[[1, 3], [0, 2]] = [['a', 100], ['b', 200]]
六、巩固练习
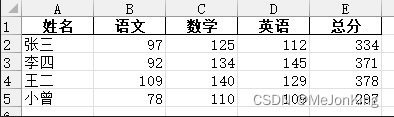
案例1、添加列应用-求每个人的总分

import pandas as pd
df = pd.read_excel(
io='4-16.xlsx',
sheet_name=0
)
df['总分'] = df['语文'] + df['数学'] + df['英语']
df.to_excel(
'4-16-1.xlsx',
index=False
)
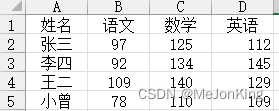
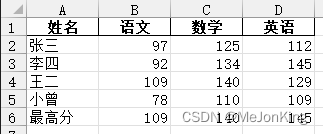
案例2、添加行应用-求各科目最高分
import pandas as pd
df = pd.read_excel(
io='4-17.xlsx',
sheet_name=0
)
df.loc[len(df)] = [
'最高分',
df['语文'].max(),
df['数学'].max(),
df['英语'].max()
]
df.to_excel(
'4-17-1.xlsx',
index=False
)
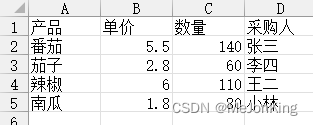
案例3、修改列应用-将单价统一上调10%
import pandas as pd
df = pd.read_excel(
io='4-18.xlsx',
sheet_name=0
)
df['单价'] = df['单价'] * 1.1
df.to_excel(
'4-18-1.xlsx',
index=False
)
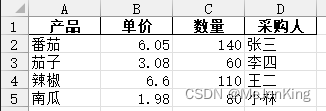
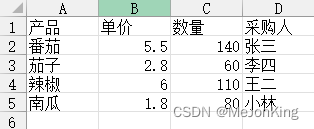
案例4、修改列应用-数量大于或等于100,则单价8折优惠
import pandas as pd
df = pd.read_excel(
io='4-19.xlsx',
sheet_name=0
)
# 通过(df['单价'] >= 100) * -0.2 + 1)构成0.8与1的数组
df['单价'] = ((df['单价'] >= 100) * -0.2 + 1) * df['单价']
df.to_excel(
'4-19-1.xlsx',
index=False
)
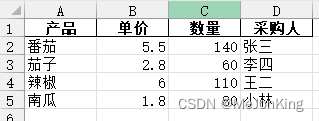
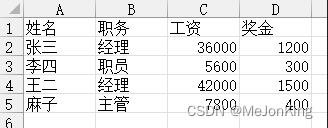
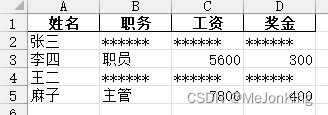
案例5、修改区域应用-将职务为经理的相关信息隐藏
import pandas as pd
df = pd.read_excel(
io='4-20.xlsx',
sheet_name=0
)
df.loc[df['职务'] == '经理', '职务':'奖金'] = '******'
df.to_excel(
'4-20-1.xlsx',
index=False
)
















 5138
5138











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











