







注:该学习笔记是根据曾志贤老师编写的《Python数据分析实战:从Excel轻松入门Pandas》所学习整理的笔记。
第5章 数据处理基础
一、数据运算处理
1、运算符与运算函数
注意:使用函数符号进行的运算,可以使用函数。使用运算符号进行的运算,不能使用函数。
| 运算符类型 | 运算符号 | 函数 | 注释 |
|---|---|---|---|
| 算术运算符 | + | add | 加 |
| 算术运算符 | - | sub | 减 |
| 算术运算符 | * | mul | 乘 |
| 算术运算符 | / | div | 除 |
| 求模运算符 | % | mod | 求余数 |
| 求幂运算符 | ** | pow | 幂次方 |
| 比较运算符 | == | 等于 | |
| 比较运算符 | != | 不等于 | |
| 比较运算符 | > | 大于 | |
| 比较运算符 | >= | 大等于 | |
| 比较运算符 | < | 小于 | |
| 比较运算符 | <= | 小等于 | |
| 连接运算符 | + | 连接 | |
| 逻辑运算符 | & | and | 与 |
| 逻辑运算符 | | | or | 或 |
| 逻辑运算符 | ~ | not | 非 |
2、Series与单值的运算
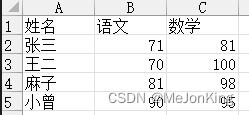
import pandas as pd
df1 = pd.read_excel(
io='5-2.xlsx',
sheet_name='1月'
)
df1['数学'] = df1['数学'] + 1
df1['语文'] = df1['语文'].add(1)
# 返回
姓名 语文 数学
0 张三 72 82
1 王二 71 101
2 麻子 82 99
3 小曾 91 96
3、DataFrame与单值的运算
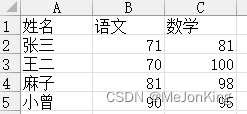
import pandas as pd
df1 = pd.read_excel(
io='5-2.xlsx',
sheet_name='1月'
)
df1[['语文', '数学']] = df1[['语文', '数学']] + 1
df1[['语文', '数学']] = df1[['语文', '数学']].add(1)
# 返回
姓名 语文 数学
0 张三 73 83
1 王二 72 102
2 麻子 83 100
3 小曾 92 97
4、Series与Series运算
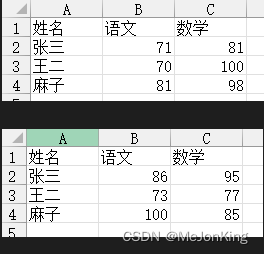
import pandas as pd
df1 = pd.read_excel(
io='5-3.xlsx',
sheet_name='1月'
)
df2 = pd.read_excel(
io='5-3.xlsx',
sheet_name='2月'
)
# 使用Series与seize数据相加,放入新的DataFrame表中
df3 = pd.DataFrame({
'姓名': df1['姓名'],
'语文': (df1['语文']+df2['语文']),
'数学': (df1['数学']+df2['数学'])
})
# 返回
姓名 语文 数学
0 张三 157 176
1 王二 143 177
2 麻子 181 183
# 仅保存合计工作表
df3.to_excel('5-3-1.xlsx', sheet_name='合计', index=False)
# 保存所有工作表在同一个工作簿内
with pd.ExcelWriter('5-3-1.xlsx') as writer:
df1.to_excel(writer, sheet_name='1月', index=False)
df2.to_excel(writer, sheet_name='2月', index=False)
df3.to_excel(writer, sheet_name='合计', index=False)
5、DataFrame与DataFrame运算
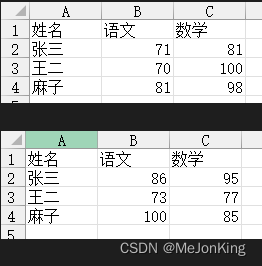
import pandas as pd
df1 = pd.read_excel(
io='5-3.xlsx',
sheet_name='1月'
)
df2 = pd.read_excel(
io='5-3.xlsx',
sheet_name='2月'
)
# 使用DataFrame表与DataFrame表相加,放入原来的DataFrame表副本中
df1.iloc[:, 1:] = df1.iloc[:, 1:] + df2.iloc[:, 1:]
print(df1)
# 返回
姓名 语文 数学
0 张三 157 176
1 王二 143 177
2 麻子 181 183
6、DataFrame与Series运算
1)、列方向相加
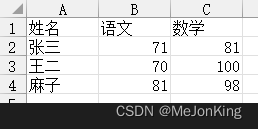
import pandas as pd
df = pd.read_excel(
io='5-4.xlsx',
sheet_name=0
)
# 列方向相加
s1 = pd.Series(['A', 100, 200], index=['姓名', '语文', '数学'])
print(df+s1)
# 返回
姓名 语文 数学
0 张三A 171 281
1 王二A 170 300
2 麻子A 181 298
2)、行方向相加
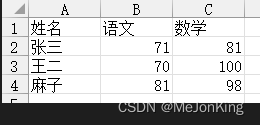
import pandas as pd
df = pd.read_excel(
io='5-4.xlsx',
sheet_name=0
)
# 行方向相加,使用函数运算符,可使用函数。而使用运算符运算,则不可使用函数。
s1 = pd.Series([1, 10, 100])
print(df.iloc[:, 1:].add(s1, axis=0))
# 返回
语文 数学
0 72 82
1 80 110
2 181 198
7、数据运算时的对齐特性
两个Series或两个DataFrame在进行运算时,是具有对其特性的,也就是它们的运算不是按位置对齐运算,而是按照索引对齐运算。
1)、Series的对齐特性
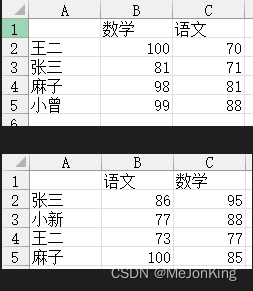
import pandas as pd
df1 = pd.read_excel(
io='5-5.xlsx',
sheet_name='1月',
index_col=0
)
df2 = pd.read_excel(
io='5-5.xlsx',
sheet_name='2月',
index_col=0
)
# Series与Series的对齐特性
# 将Series中的缺失值默认填充为0,才能正常进行运算。
print(df1['数学'].add(df2['数学'], fill_value=0))
# 返回
小新 88.0
小曾 99.0
张三 176.0
王二 177.0
麻子 183.0
Name: 数学, dtype: float64
2)、DataFrame的对齐特性
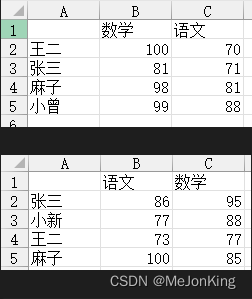
import pandas as pd
df1 = pd.read_excel(
io='5-5.xlsx',
sheet_name='1月',
index_col=0
)
df2 = pd.read_excel(
io='5-5.xlsx',
sheet_name='2月',
index_col=0
)
# DataFrame与DataFrame的对齐特性
# 将DataFrame中的缺失值默认填充为0,才能正常进行运算。
print(df1.add(df2, fill_value=0))
# 返回
数学 语文
小新 88.0 77.0
小曾 99.0 88.0
张三 176.0 157.0
王二 177.0 143.0
麻子 183.0 181.0
二、数据分支判断
1、条件判断处理1(mask( )与where( ))
- mask( )函数与where( )函数结构相同,含义相反:
- mask( )函数:在条件成立时做处理。
- where( )函数:在条件不成立时做处理。
1)、Series数据条件判断
import pandas as pd
df = pd.read_excel(
io='5-6.xlsx',
sheet_name=0
)
# 对Series数据的条件判断
df['总分'].mask(
# 条件判断
df['民族'] != '汉',
# 当条件满足时
df['总分'] + 10,
# 在原表修改
inplace=True
)
2)、DataFrame数据条件判断
import pandas as pd
# 对DataFrame数据的条件判断
df = pd.read_excel(
io='5-6.xlsx',
sheet_name=1
)
df.iloc[:, 1:] = df.iloc[:, 1:].mask(df.iloc[:, 1:] == '差', '?')
2、条件判断处理2(np.where( ))
同时处理使用np.where( )函数,由于是NumPy库中的函数,所以返回值的数据类型也是数组。
1)、Series数据条件判断
import pandas as pd
import numpy as np
s = pd.Series([48, 99, 68, 100, 87, 75])
print(np.where(s >= 90, '优', '差'))
import pandas as pd
import numpy as np
df = pd.read_excel(
io='5-7.xlsx',
sheet_name=0
)
df['等级'] = np.where(df['分数'] >= 90, '优', '差')
2)、DataFrame数据条件判断
import pandas as pd
import numpy as np
df = pd.DataFrame({
'分数1': [89, 59, 92, 58],
'分数2': [52, 86, 71, 96]
})
print(np.where(df >= 80, '优', '差'))
import pandas as pd
import numpy as np
df = pd.read_excel(
io='5-7.xlsx',
sheet_name=1
)
df.iloc[:, 1:] = np.where(df.iloc[:, 1:] >= 40000, '已达标', '未达标')
print(df)
三、数据遍历处理
1、遍历Series元素(map( ))
map( )函数对Series中的每个元素执行遍历处理,该函数的参数可以是字典,也可以是函数。
1)、map( )的参数为字典
import pandas as pd
s = pd.Series(['优', '良', '优', '中', '差', '良'])
s1 = s.map({
'优': 10,
'良': 8,
'中': 5,
'差': 1
})
print(s1)
2)、map( )的参数为内置函数
import pandas as pd
s = pd.Series([98, 100, 63, 9, 88])
s1 = s.map(
'{}分'.format
)
print(s1)
3)、map( )的参数为自定义函数
import pandas as pd
def fun(n):
return n/2
s = pd.Series([98, 100, 63, 9, 88])
print(s.map(fun))
4)、map( )的参数为匿名函数
import pandas as pd
s = pd.Series([98, 100, 63, 9, 88])
print(s.map(lambda x: x/2))
2、遍历DataFrame行和列(apply( ))
- apply( )函数可以像map( )函数一样遍历Series中的每个元素,但主要是使用apply( )函数函数来遍历DataFrame的行与列,遍历出来每行或每列均是Series数据。
- apply( )函数也可以接收内置函数、自定函数、匿名函数作为参数。
1)、遍历DataFrame的每列
import pandas as pd
df = pd.read_excel('5-9.xlsx', sheet_name=0)
# 按列进行求和,axis可不写,默认为0,返回Series数据
df.loc[len(df)] = df.iloc[:, 1:].apply(sum, axis=0)
df.iloc[-1, 0] = '合计'
2)、遍历DataFrame的每行
import pandas as pd
df = pd.read_excel('5-9.xlsx', sheet_name=0)
# 按行进行求和,axis为1,返回Series数据
df['总分'] = df.iloc[:, 1:].apply(sum, axis=1)
3、遍历DataFrame元素(applymap( ))
- applymap( )函数是对DataFrame中的每个元素执行指定函数的处理。
- 由于map函数与apply函数是对Series数据的每个元素进行处理,无法与DataFrame每个元素处理,这是需要用到applymap函数。
import pandas as pd
df = pd.read_excel('5-10.xlsx', 0)
# 如果使用apply函数来实现的话,需要进行两次变量
df.iloc[:, 1:] = df.iloc[:, 1:].apply(lambda s: s.apply('{:.2f}'.format))
# 使用applymap函数只需要一次遍历即可,遍历结束后是字符串类型,还需要转换为浮点数
df.iloc[:, 1:] = df.iloc[:, 1:].applymap('{:.2f}'.format).astype(float)
print(df)
四、数据统计处理
1、聚合统计
| 统计方式 | Python | Pandas | NumPy |
|---|---|---|---|
| 求和 | sum( ) | sum( ) | np.sum( ) |
| 求最大值 | max( ) | max( ) | np.max( ) |
| 求最小值 | min( ) | min( ) | np.min( ) |
| 求平均值 | 无 | mean( ) | np.mean( ) |
| 求计数值 | len( ) | count( ) | 无 |
- Python:聚合函数可以对一组任意形式的序列值做统计。
- Pandas:聚合函数只能对Series和DataFrame做统计。
- NumPy:聚合函数可以对数组、Series和DataFrame做统计。
- Pandas与NumPy的聚合函数在对二维数据统计时,可以指定聚合方向。
1)、Series数据统计
import pandas as pd
import numpy as np
lst = [85, 990, 1000]
s = pd.Series([85, 990, 1000])
arr = np.array([85, 990, 1000])
print(sum(lst), sum(s), sum(arr))
print(s.sum(), arr.sum())
print(np.sum)
2)、DataFrame数据统计
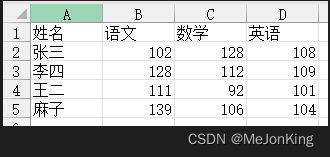
(1)按行统计
import pandas as pd
df = pd.read_excel(io='5-12.xlsx', sheet_name=0)
df['合计'] = df.iloc[:, 1:].sum(axis=1)
print(df)
# 返回
姓名 语文 数学 英语 合计
0 张三 102 128 108 338
1 李四 128 112 109 349
2 王二 111 92 101 304
3 麻子 139 106 104 349
(2)按列统计
import pandas as pd
df = pd.read_excel(io='5-12.xlsx', sheet_name=0)
s = df.iloc[:, 1:].sum(axis=0)
df.loc[len(df)] = s
df.iloc[-1, 0] = '合计'
print(df)
# 返回
姓名 语文 数学 英语
0 张三 102.0 128.0 108.0
1 李四 128.0 112.0 109.0
2 王二 111.0 92.0 101.0
3 麻子 139.0 106.0 104.0
4 合计 480.0 438.0 422.0
2、逻辑统计
| 逻辑运算方式 | Pandas | NumPy | 注释 |
|---|---|---|---|
| 逻辑与 | all | np.all | 如果Series中的所有布尔值为True,则返回值为True,否则返回值为False。 |
| 逻辑或 | any | np.any | 如果Series中有1个及以上布尔值为True,则返回值为True;如果全部为False,则返回值为False。 |
1)、Series逻辑统计
import numpy as np
import pandas as pd
s = pd.Series([98, 57, 96, 88])
# 使用逻辑与,当所有条件达到时,返回True,否则返回False。
# 常规的写法,需要写完所有数据,不方便。
print((s[0] >= 90) & (s[1] >= 90) & (s[2] >= 90))
# 使用Pandas库中all函数的写法
print((s >= 90).all())
# 使用NumPy库中的np.all函数的写法
print(np.all(s >= 90))
# 使用逻辑或,当至少有1个条件达到时,返回True,否则返回False。
# 常规的写法,需要写完所有数据,不方便。
print((s[0] >= 90) | (s[1] >= 90) | (s[2] >= 90))
# 使用Pandas库中all函数的写法
print((s >= 90).any())
# 使用NumPy库中的np.all函数的写法
print(np.any(s >= 90))
2)、DataFrame逻辑统计
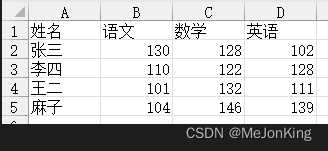
(1)按行统计
要求:在每个人的3个科目中,如果至少有1个及以上科目的分数大于或等于130,则返回“√”否则返回“×”。
import pandas as pd
import numpy as np
df = pd.read_excel(io='5-14.xlsx', sheet_name=0)
# 使用逻辑或进行判断,将返回的Series数据在使用where条件判断修改为√与×。
df['达标情况'] = np.where((df.iloc[:, 1:] >= 130).any(axis=1), '√', '×')
print(df)
# 返回
姓名 语文 数学 英语 达标情况
0 张三 130 128 102 √
1 李四 110 122 128 ×
2 王二 101 132 111 √
3 麻子 104 146 139 √
(2)按列统计
要求:每列科目所有分数大于等于120分则返回“√”,否则返回“×”。
新知识点: 使用np.concatenate( )函数可以组合数组,采用的是列表结构。
import pandas as pd
import numpy as np
df = pd.read_excel(io='5-14.xlsx', sheet_name=0)
# 使用逻辑与进行判断,将返回的Series数据在使用where条件判断修改为√与×。
arr = np.where((df.iloc[:, 1:] >= 120).all(axis=0), '√', '×')
# 使用np.concatenate函数组合数据,放入新行中。
df.loc[len(df)] = np.concatenate([np.array(['达标情况']), arr])
print(df)
# 返回
姓名 语文 数学 英语
0 张三 130 128 102
1 李四 110 122 128
2 王二 101 132 111
3 麻子 104 146 139
4 达标情况 × √ ×
3、极值统计
获取前几个最大值或最小值,需要使用极值函数。
| 极值 | 函数及参数 |
|---|---|
| Series极大值 | s.nsmallest(n,keep=‘first’) |
| Series极小值 | s.nlargest(n,keep=‘first’) |
| DataFrame极大值 | df.nsmallest(n,cloumns,keep=‘first’) |
| DataFrame极小值 | df.nlargest(n,cloumns,keep=‘first’) |
| 参数 | 含义 |
| n | 指定极值个数 |
| column | 如果求极值的是DataFrame表格,则要求指定求极值的列,可以指定多列。 |
| keep | 参数分别有first、last、all这3个值,含义分别如下 |
| first | 优先选取原始表格里排在前面的值,即默认值。 |
| last | 优先选取原始表格里面排在后面的值。 |
| all | 选取所有的值,即使选取的个数超过了指定的极值个数。 |
1)Series极值统计
对Series数据做极值处理后,返回结果也是Series数据。
import pandas as pd
s = pd.Series([87, 85, 96, 91, 87, 63])
print(s)
# 返回
0 87
1 85
2 96
3 91
4 87
5 63
dtype: int64
# 极大值,keep参数为默认值first时
print(s.nlargest(3))
# 返回
2 96
3 91
0 87
dtype: int64
# 极大值,keep参数为last时
print(s.nlargest(3, keep='last'))
# 返回
2 96
3 91
4 87
dtype: int64
# 极大值,keep参数为all时
print(s.nlargest(3, keep='all'))
# 返回
2 96
3 91
0 87
4 87
dtype: int64
# 极小值,keep参数为默认值first时
print(s.nsmallest(3))
# 返回
5 63
1 85
0 87
dtype: int64
# 极小值,keep参数为last时
print(s.nsmallest(3, keep='last'))
# 返回
5 63
1 85
4 87
dtype: int64
# 极小值,keep参数为all时
print(s.nsmallest(3, keep='all'))
# 返回
5 63
1 85
0 87
4 87
dtype: int64
2)DataFrame极值统计
(1)统计单列极值
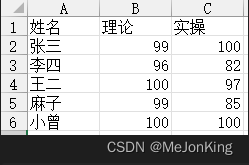
import pandas as pd
df = pd.read_excel(io='5-16.xlsx', sheet_name=0)
# 极大值,keep参数为默认值first时
print(df.nlargest(3, '理论'))
# 返回
姓名 理论 实操
2 王二 100 97
4 小曾 100 100
0 张三 99 100
# 极大值,keep参数为last时
print(df.nlargest(3, '理论', keep='last'))
# 返回
姓名 理论 实操
4 小曾 100 100
2 王二 100 97
3 麻子 99 85
# 极大值,keep参数为all时
print(df.nlargest(3, '理论', keep='all'))
# 返回
姓名 理论 实操
2 王二 100 97
4 小曾 100 100
0 张三 99 100
3 麻子 99 85
# 极小值,keep参数为默认值first时
print(df.nsmallest(3, '理论'))
# 返回
姓名 理论 实操
1 李四 96 82
0 张三 99 100
3 麻子 99 85
# 极小值,keep参数为last时
print(df.nsmallest(3, '理论', keep='last'))
# 返回
姓名 理论 实操
1 李四 96 82
3 麻子 99 85
0 张三 99 100
# 极小值,keep参数为all时
print(df.nsmallest(3, '理论', keep='all'))
# 返回
姓名 理论 实操
1 李四 96 82
0 张三 99 100
3 麻子 99 85
(2)统计多列极值
对多列统计极值,在columns参数中以列表形式写入名称,并且以列表名称在列表中的先后顺序确定关键字顺序。
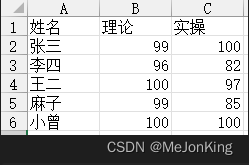
import pandas as pd
df = pd.read_excel(io='5-16.xlsx', sheet_name=0)
# 多列极大值,keep参数不在举例
print(df.nlargest(3, ['理论', '实操']))
# 返回
姓名 理论 实操
4 小曾 100 100
2 王二 100 97
0 张三 99 100
# 多列极小值,keep参数不在举例
print(df.nsmallest(3, ['理论', '实操']))
# 返回
姓名 理论 实操
1 李四 96 82
3 麻子 99 85
0 张三 99 100
4、排名统计
在Pandas中的排名函数是rank( ),数字越大,排名越低,这是因为rank( )函数的ascending参数默认值为True,也就是默认为升序排列。倒序排列将ascending设置为False即可。
import pandas as pd
s = pd.Series([89, 99, 100, 85, 89, 66])
# 默认升序排序
print(s.rank())
# 返回
0 3.5
1 5.0
2 6.0
3 2.0
4 3.5
5 1.0
dtype: float64
# 使用降序排序
print(s.rank(ascending=False))
# 返回
0 3.5
1 2.0
2 1.0
3 5.0
4 3.5
5 6.0
dtype: float64
关于排名,还有一个重要的问题需要了解,就是相同值。rank( )函数的method参数提供了对相同值的5中处理方法,如下表。
| 常量 | 注释 |
|---|---|
| average | 默认值,对相同值做平均排名 |
| min | 对相同值做最小排名(美式排名) |
| max | 对相同值做最大排名 |
| first | 对相同值出现的顺序做排名 |
| dense | 与最小排名类似,但不同名次之间差值为1(中式排名) |
注意:rank( )函数统计出的名次是小数类型,如果需要转换为整数类型,则在rank( )函数之后加astype(‘int’)即可。
import pandas as pd
s = pd.Series([89, 99, 100, 85, 89, 66])
# method参数为average时,是默认参数。相同值时,排名为平均值。
print(s.rank(ascending=False))
# 返回
0 3.5
1 2.0
2 1.0
3 5.0
4 3.5
5 6.0
dtype: float64
# method参数为min时,相同值时,取最小排名,可以理解为美式排名。
print(s.rank(ascending=False, method='min'))
# 返回
0 3.0
1 2.0
2 1.0
3 5.0
4 3.0
5 6.0
dtype: float64
# method参数为max时,相同值时,取最大排名。
print(s.rank(ascending=False, method='max'))
# 返回
0 4.0
1 2.0
2 1.0
3 5.0
4 4.0
5 6.0
dtype: float64
# method参数为first时,相同值时,按照出现的顺序觉得排名顺序。
print(s.rank(ascending=False, method='first'))
# 返回
0 3.0
1 2.0
2 1.0
3 5.0
4 4.0
5 6.0
dtype: float64
# method参数为dense时,相同值时,并列排名,不同名次之间差值为1,可以理解为中式排名。
print(s.rank(ascending=False, method='dense'))
# 返回
0 3.0
1 2.0
2 1.0
3 4.0
4 3.0
5 5.0
dtype: float64
1)Series排名统计
直接获取表格的某列做排名统计,就相当于对指定Series数据做排名。
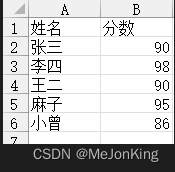
import pandas as pd
df = pd.read_excel(io='5-18.xlsx', sheet_name=0)
df['美式排名'] = df['分数'].rank(ascending=False, method='min').astype('int')
df['中式排名'] = df['分数'].rank(ascending=False, method='dense').astype('int')
print(df)
# 返回
姓名 分数 美式排名 中式排名
0 张三 90 3 3
1 李四 98 1 1
2 王二 90 3 3
3 麻子 95 2 2
4 小曾 86 5 4
2)DataFrame排名统计
如果需要对DataFrame表格做排名,并且排名方式是各行、各列单独排名,则需要指定函数的axis参数,1为按行排名,0为按列排名。
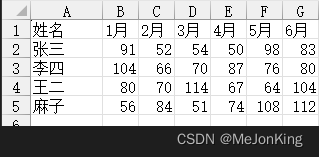
(1)按行排名
import pandas as pd
df1 = pd.read_excel(io='5-18.xlsx', sheet_name=1)
print(df1.iloc[:, 1:].rank(ascending=False, method='dense', axis=1).astype('int'))
# 返回
1月 2月 3月 4月 5月 6月
0 2 5 4 6 1 3
1 1 6 5 2 4 3
2 3 4 1 5 6 2
3 5 3 6 4 2 1
(2)按列排名
import pandas as pd
df1 = pd.read_excel(io='5-18.xlsx', sheet_name=1)
print(df1.iloc[:, 1:].rank(ascending=False, method='dense', axis=0).astype('int'))
# 返回
1月 2月 3月 4月 5月 6月
0 2 4 3 4 2 3
1 1 3 2 1 3 4
2 3 2 1 3 4 2
3 4 1 4 2 1 1
五、巩固案例
案例一:根据不同蔬菜的采购数量统计每天采购金额
原表格中净白菜、小油菜、丝瓜的单价数据存储在s=pd.Series([5.6, 1.3, 2.4], index=[‘丝瓜’, ‘净白菜’, ‘小油菜’])中,现在需要统计出每天的采购金额。
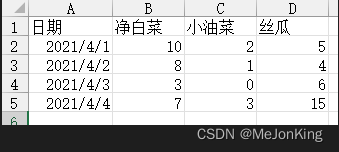
import pandas as pd
df = pd.read_excel(io='5-19.xlsx', sheet_name=0)
s = pd.Series([5.6, 1.3, 2.4], index=['丝瓜', '净白菜', '小油菜'])
df['金额'] = (df.iloc[:, 1:] * s).sum(axis=1)
print(df)
# 返回
日期 净白菜 小油菜 丝瓜 金额
0 2021-04-01 10 2 5 45.8
1 2021-04-02 8 1 4 35.2
2 2021-04-03 3 0 6 37.5
3 2021-04-04 7 3 15 100.3
案例二:筛选出成绩表中各科目均大于或等于100的记录
要求筛选出每个人3个科目的分数均大于或等于100的记录。
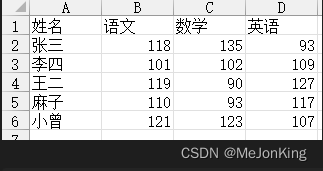
import pandas as pd
df = pd.read_excel(io='5-20.xlsx', sheet_name=0)
print(df[(df.iloc[:, 1:] >= 100).all(axis=1)])
# 返回
姓名 语文 数学 英语
1 李四 101 102 109
4 小曾 121 123 107
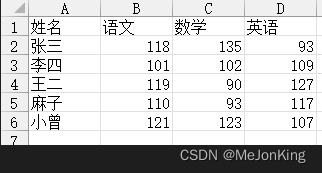
案例三:筛选出成绩表中各科目的和大于或等于330的记录
对每个人的各科分数求和,然后筛选出总分大于或等于330的记录。
import pandas as pd
df = pd.read_excel(io='5-21.xlsx', sheet_name=0)
print(df[df.iloc[:, 1:].sum(axis=1) >= 330])
# 返回
姓名 语文 数学 英语
0 张三 118 135 93
2 王二 119 90 127
4 小曾 121 123 107
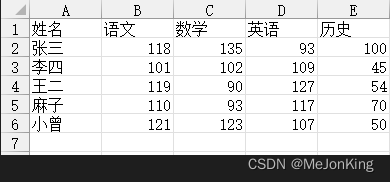
案例四:统计每个人各科目总分之和的排名
对每个人的各科分数求和,然后按总分的大小做中式排名。
import pandas as pd
df = pd.read_excel(io='5-22.xlsx', sheet_name=0)
df['排名'] = df.iloc[:, 1:].sum(axis=1).rank(ascending=False, method='dense').astype('int')
print(df)
# 返回
姓名 语文 数学 英语 历史 排名
0 张三 118 135 93 100 1
1 李四 101 102 109 45 4
2 王二 119 90 127 54 3
3 麻子 110 93 117 70 3
4 小曾 121 123 107 50 2
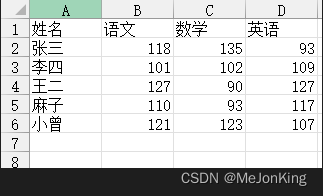
案例五:统计每个人所有考试科目的最优科目
统计每个人最高分对应的科目。
import pandas as pd
df = pd.read_excel(io='5-23.xlsx', sheet_name=0)
# 遍历数据区域的所有行,进行每行的循环极值判断,取第1个最大极值,将其转换为list,写入对应的列中。
df['最优科目'] = df.iloc[:, 1:].apply(lambda s: s.nlargest(1, keep='all').index.to_list(), axis=1)
print(df)
# 返回
姓名 语文 数学 英语 最优科目
0 张三 118 135 93 [数学]
1 李四 101 102 109 [英语]
2 王二 127 90 127 [语文, 英语]
3 麻子 110 93 117 [英语]
4 小曾 121 123 107 [数学]
















 221
221











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











