







----前面的初级题目完成!今天终于刷中等题了
目录
相关表结构:
1、Order_info表:
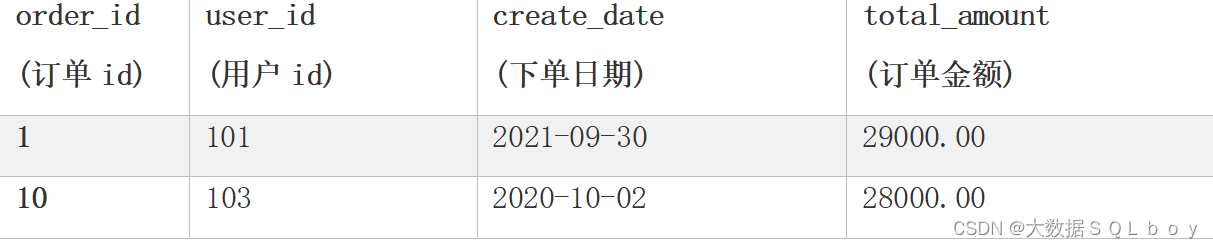
2、Order_detail表:
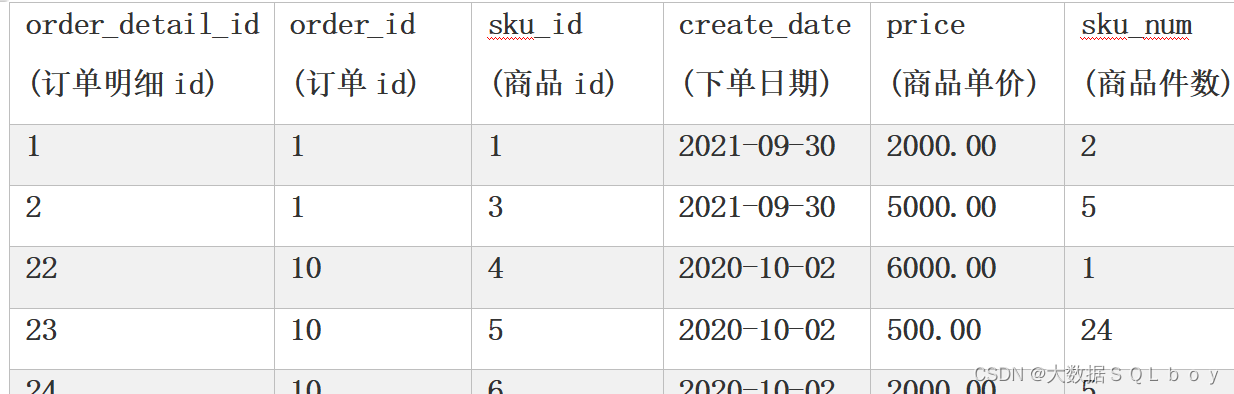
题目及思路解析:
第一题 : 查询累积销量排名第二的商品
注意:订单明细表里面存的是每个订单的购买的商品与数量
· 题目需求:
查询订单明细表(order_detail)中销量(下单件数)排名第二的商品id,如果不存在返回null,如果存在多个排名第二的商品则需要全部返回。期望结果如下(示例):

·思路解析:
1、首先需要的是每个商品的购买总数量
2、接着我们按照商品的购买数量进行降序排名
3、然后根据题目要求进行筛选得到排名第二的商品sku_idid
4、最后将最终结果右连接 {select 1},条件是1=1
·SQL代码:
select
t3.sku_id
from (
select
sku_id
from (
select
sku_id,
dense_rank() over ( order by total_num desc ) rk
from (
select
sku_id,
sum(sku_num) total_num
from order_detail
group by sku_id
)t1
)t2
where rk=2
)t3
right join --为保证,没有第二名的情况下,返回null
(select 1
)t4
on 1=1;·补充说明:
1、题目要求”如果存在多个排名第二的商品则需要全部返回“
因此排名函数的选择dense_rnak()或rank()
2、题目没有分类需求,统计的是所有商品
因此排名函数不需要进行分区
3、题目要求”如果商品id不存在返回null“
首先 这里右连接条件是1=1,因此一定可以连接得上
接着我们分析后面的右连接部分sql:
a .当sku_id存在时,右连接select 1,此时返回一行,显示对应的sku_id
b .当sku_id不存在时,右连接select 1,此时返回一行,由于右连接,但左表没有对应数据,因此补为null
再补充:
select
sku_id,
order_num,
dense_rank() over (order by order_num desc) rk
from (
select sku_id,
sum(sku_num) order_num
from order_detail
group by sku_id
) t1;上面代码还可以写得简略一点,如下所示:
select
sku_id,
sum(sku_num) total_num,
dense_rank() over ( order by sum(sku_num) desc ) rn
from order_detail;这里不建议这样写,特别是初学者,为避免以后别人这样写,自己却看不懂,先了解一下。
·结果:
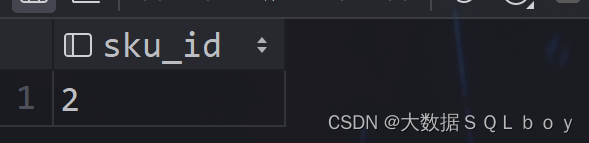
-----------------------------------------------------------------------------------------------------------------------------------
第二题: 查询至少连续三天下单的用户
Tips:关键在“连续”二字,另外本题目前有三种解法思路
题目需求:
查询订单信息表(order_info)中最少连续3天下单的用户id,期望结果如下:

思路一:(较为容易理解与想到的)
思路解析:
有日期,有范围,首先想到自然是开窗函数了,用lead()的比较合适(用lag()也行),取后n天的日期,那n取多少呢?2 即取后面第二天的日期,因为是连续三天,用后面第二天日期减去当天日期,若等于2即这三天是连续的。
SQL代码:
select
distinct user_id
from (
select
user_id,
datediff(next_date,create_date) cnt
from
(
select
user_id,
create_date,
lead(create_date,2,'1970-01-01') over (partition by user_id
order by create_date)next_date
from (
select
user_id,
create_date
from order_info
group by user_id, create_date
)t1
)t2
)t3
where cnt =2
group by user_id;SQL解析:
1、首先对原表的userid与ceate_date进行去重
2、接着使用lead()函数往下去每行的第二行的值,同时按照userid分区,createdate排序,
3、然后使用datadiff()函数将获取的数据与每行进行做差,筛选出差值为2的,由于可能出现同一用户多次连续下单,因此也要对userid去重。
关键是用每行date与下第2行date做差,相差2时即为为连续三天。
(注:前提原数据已去重,排序)
思路二:(不易想到,可能太好理解)
思路解析:
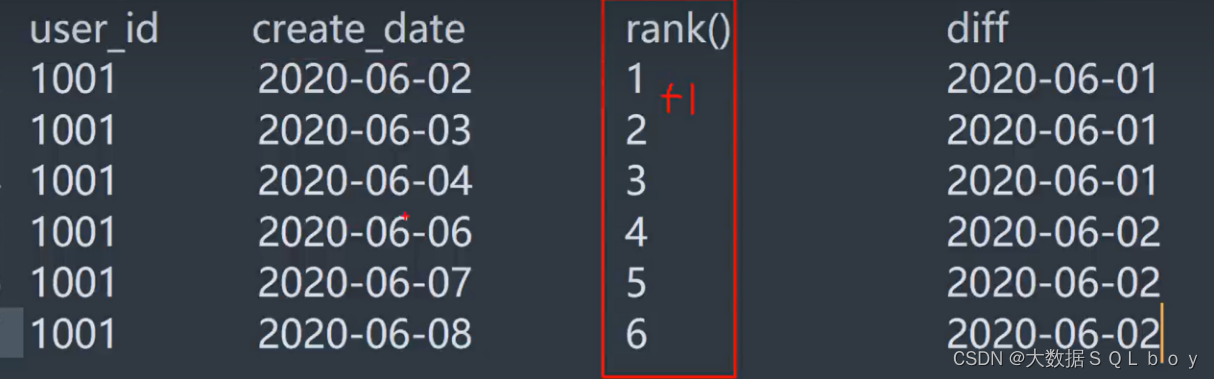
我们首先对create_date 进行排序,之后用create_date 减去 排序值(rank), 即可得到对应的日期差值,然后对日期差值进行 count() 统计,count >=3即为至少连续三天下单的用户
这里关键在于,首先rank排序结果一定连续,若create_date连续,则create_date与rank差值必定相同
SQL代码:
select
distinct user_id
from (
select
user_id,
count(*) cnt
from (
select
user_id,
create_date,
date_sub(create_date,row_number()
over (partition by user_id
order by create_date))diff
from (
select
user_id,
create_date
from order_info
group by user_id, create_date
)t1
)t2
group by user_id, diff
having cnt >=3
)t3;SQL解析:
1、首先对usrid 与create_date去重
2、接着对其进行排序用rank,接着将其结果与createdate做差,
3、然后对结果分组,注意要按照userid与diff,因为可能不同用户会出现相同的购物情况
4、之后接着用having筛选>3的
5、最后再对useid去重
注:这个方法不需要进行开窗
思路三:(比较妙)(真是妙脆角,妙到家了)
思路解析:

这里通过count() 函数开窗 即count()+over(),减1(前天) 、当天、加1(后天),若都存在则count值=3
注意:voer()里面设置range between 1 preceding and 1 follwing,即加1天和减1天,此时如果 前一天 + 当天 后一天 若都存在,count()=3
count() 即符合该范围的行,则统计在内,符合条件的结果为3
SQL代码:
select
distinct user_id
from (
select
user_id,
count(*)over(partition by user_id order by ts range
between 86400 preceding and 86400 following)cnt
from (
select
user_id,
unix_timestamp(create_date,'yyyy-MM-dd') ts
from (
select
user_id,
create_date
from order_info
group by user_id, create_date
)t1
)t2
)t3
where cnt=3;SQL解析:
1、首先获取原始数据(去重后的),由于原eate_date的值为字符串,不能直接加减,我们可以转成时间戳,另外注意,unix_timetamp中的第二个参数,它默认匹配模式时年月日时分秒,但我们表中没有时分秒,因此要写一下匹配模式。
3、接着我们利用count(*) over() 开窗函数进行统计,由于时间戳的单位时秒,因此开窗范围注意将天改为秒。
4、最后根据题意筛选得到结果,并对结果去重
结果:

总结归纳:
1、主要考察开窗函数与日期函数的结合使用,总的来说还是挺难的,因此要对相关函数至少要有一定了解
2、按照功能,常用窗口可划分为如下几类:聚合函数、跨行取值函数、排名函数。
注意哈,聚合函数也是窗口函数
知识补充:
日期函数:
1)unix_timestamp:返回当前或指定时间的时间戳
语法:unix_timestamp()
返回值:bigint
案例实操:
hive> select unix_timestamp('2022/08/08 08-08-08','yyyy/MM/dd HH-mm-ss');
输出:
1659946088
说明:-前面是日期后面是指,日期传进来的具体格式
2)datediff:两个日期相差的天数(结束日期减去开始日期的天数)
语法:datediff(string enddate, string startdate)
返回值:int
案例实操:
hive> select datediff('2021-08-08','2022-10-09');
输出:
-427
3)date_sub:日期减天数
语法:date_sub (string startdate, int days)
返回值:string
说明:返回开始日期startdate减少days天后的日期。
案例实操:
hive> select date_sub('2022-08-08',2);
输出:
2022-08-06















 2907
2907











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









