







- 1. ReLU激活函数:从趋近于零开始,然后变成一条直线,它的全称是 Rectified Linear Unit。rectify(修正)。
-
2. 神经网络的一部分神奇之处在于,当你实现它之后,你要做的只是输入𝑥,就能得到输出𝑦。因为它可以自己计算你训练集中样本的数目以及所有的中间过程。
3. 监督学习:
(1)在监督学习中你有一些输入𝑥,你想学习到一个函数来映射到一些输出𝑦,比如我们之前提到的房价预测的例子,你只要输入有关房屋的一些特征,试着去输出或者估计价格𝑦。
(2)在自动驾驶技术中,你可以输入一幅图像,就好像一个信息雷达展示汽车前方有什么,据此,你可以训练一个神经网络,来告诉汽车在马路上面具体的位置,这就是神经网络在自动驾驶系统中的一个关键成分。
(3)对于图像应用,我们经常在神经网络上使用卷积(Convolutional Neural Network),通常缩写为 CNN。对于序列数据,例如音频,有一个时间组件,随着时间的推移,音频被播放出来,所以音频是最自然的表现。作为一维时间序列(两种英文说法 one-dimensional time series / temporal sequence).对于序列数据,经常使用 RNN,一种递归神经网络(Recurrent Neural Network),语言,英语和汉语字母表或单词都是逐个出现的,所以语言也是最自然的序列数据,因此更复杂的 RNNs 版本经常用于这些应用。
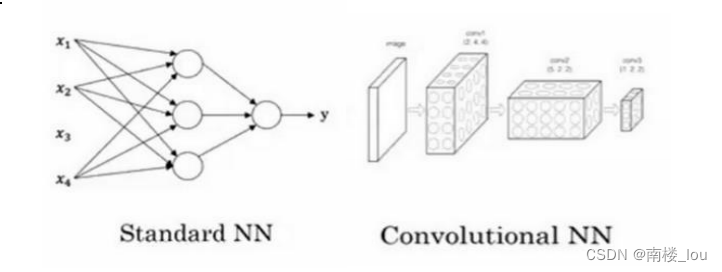
(4)结构化数据与非结构化数据的应用:结构化数据意味着数据的基本数据库。例如在房价预测中,你可能有一个数据库,有专门的几列数据告诉你卧室的大小和数量,这就是结构化数据。或预测用户是否会点击广告,你可能会得到关于用户的信息,比如年龄以及关于广告的一些信息,然后对你的预测分类标注,这就是结构化数据,意思是每个特征,比如说房屋大小卧室数量,或者是一个用户的年龄,都有一个很好的定义。相反非结构化数据是指比如音频,原始音频或者你想要识别的图像或文本中的内容。这里的特征可能是图像中的像素值或文本中的单个单词。多亏了深度学习和神经网络,计算机现在能更好地解释非结构化数据。
4.
-
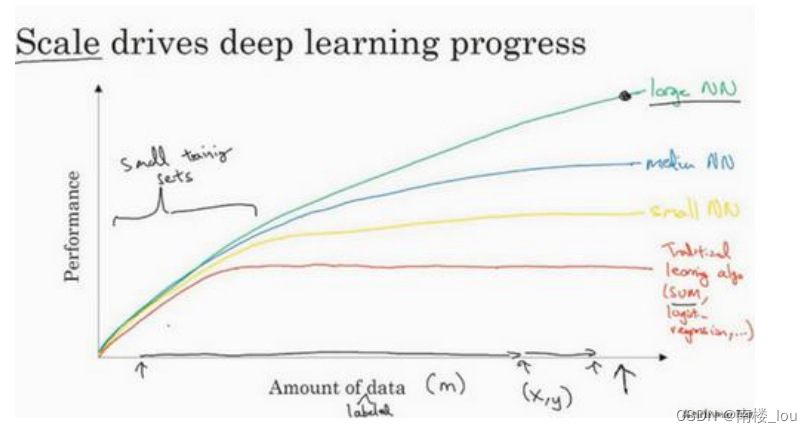
神经网络展现出的是,如果你训练一个小型的神经网络,那么这个性能可能会像下图黄色曲线表示那样;如果你训练一个稍微大一点的神经网络,比如说一个中等规模的神经网络(下图蓝色曲线),它在某些数据上面的性能也会更好一些;如果你训练一个非常大的神经网络,它就会变成下图绿色曲线那样,并且保持变得越来越好。因此可以注意到两点:如果你想要获得较高的性能体现,那么你有两个条件要完成,第一个是你需要训练一个规模足够大的神经网络,以发挥数据规模量巨大的优点,另外你需要能画到𝑥轴的这个位置,所以你需要很多的数据。因此我们经常说规模一直在推动深度学习的进步,这里的规模指的也同时是神经网络的规模,我们需要一个带有许多隐藏单元的神经网络,也有许多的参数及关联性,就如同需要大规模的数据一样。事实上如今最可靠的方法来在神经网络上获得更好的性能,往往就是要么训练一个更大的神经网络,要么投入更多的数据,这只能在一定程度上起作用,因为最终你耗尽了数据,或者最终你的网络是如此大规模导致将要用太久的时间去训练,但是仅仅提升规模的的确确地让我们在深度学习的世界中摸索了很多时间。
神经网络方面的一个巨大突破是从 sigmoid 函数转换到一个ReLU 函数。
5. 二分类
(1)当实现一个神经网络的时候,我们通常不直接使用 for 循环来遍历整个训练集。在神经网络的计算中,通常先有一个叫做前向暂停(forward pause)或叫做前向传播(foward propagation)的步骤,接着有一个叫做反向暂停(backward pause) 或叫做反向传播(backward propagation)的步骤。
(2)逻辑回归是一个用于二分类(binary classification)的算法。
(3)所以在二分类问题中,我们的目标就是习得一个分类器,它以图片的特征向量作为输入,然后预测输出结果𝑦为 1 还是 0。

6. 逻辑回归
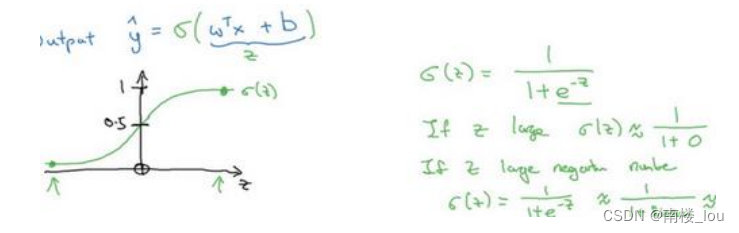
7. 逻辑回归的代价函数
(1)为了训练逻辑回归模型的参数𝑤和𝑏,我们需要一个代价函数,通过训练代价函数来得到参数𝑤和参数𝑏。
(2)损失函数:损失函数又叫做误差函数,用来衡量算法的运行情况。我们通过这个𝐿称为的损失函数,来衡量预测输出值和实际值有多接近。一般我们用预测值和实际值的平方差或者它们平方差的一半,但是通常在逻辑回归中我们不这么做,因为当我们在学习逻辑回归参数的时候,会发现我们的优化目标不是凸优化,只能找到多个局部最优值,梯度下降法很可能找不到全局最优值,虽然平方差是一个不错的损失函数,但是我们在逻辑回归模型中会定义另外一个损失函数。
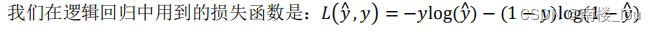
(3)代价函数:损失函数是在单个训练样本中定义的,它衡量的是算法在单个训练样本中表现如何,为了衡量算法在全部训练样本上的表现如何,我们需要定义一个算法的代价函数,算法的代价函数是对𝑚个样本的损失函数求和然后除以𝑚:
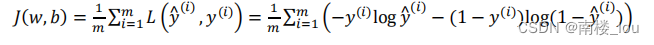
损失函数只适用于像这样的单个训练样本,而代价函数是参数的总代价,所以在训练逻辑回归模型时候,我们需要找到合适的𝑤和𝑏,来让代价函数 𝐽 的总代价降到最低。 根据我们对逻辑回归算法的推导及对单个样本的损失函数的推导和针对算法所选用参数的总代价函数的推导,结果表明逻辑回归可以看做是一个非常小的神经网络。
8. 梯度下降法:

朝最陡的下坡方向走一步,不断地迭代
9. 计算流程:可以说,一个神经网络的计算,都是按照前向或反向传播过程组织的。首先我们计算出一个新的网络的输出(前向过程),紧接着进行一个反向传输操作。后者我们用来计算出对应的梯度或导数。
10. 逻辑回归中的梯度下降:

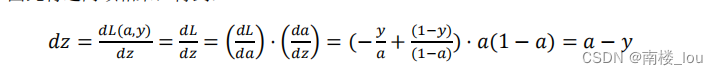



















04-20
 943
943
943
03-03
6851
6851
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









