






深度学习-学习记录
一.如何搭建一个神经网络
一些概念
激活函数:用途是将一个无边界的输入,转变成一个可预测的形式。常用的激活函数就就是S型函数:
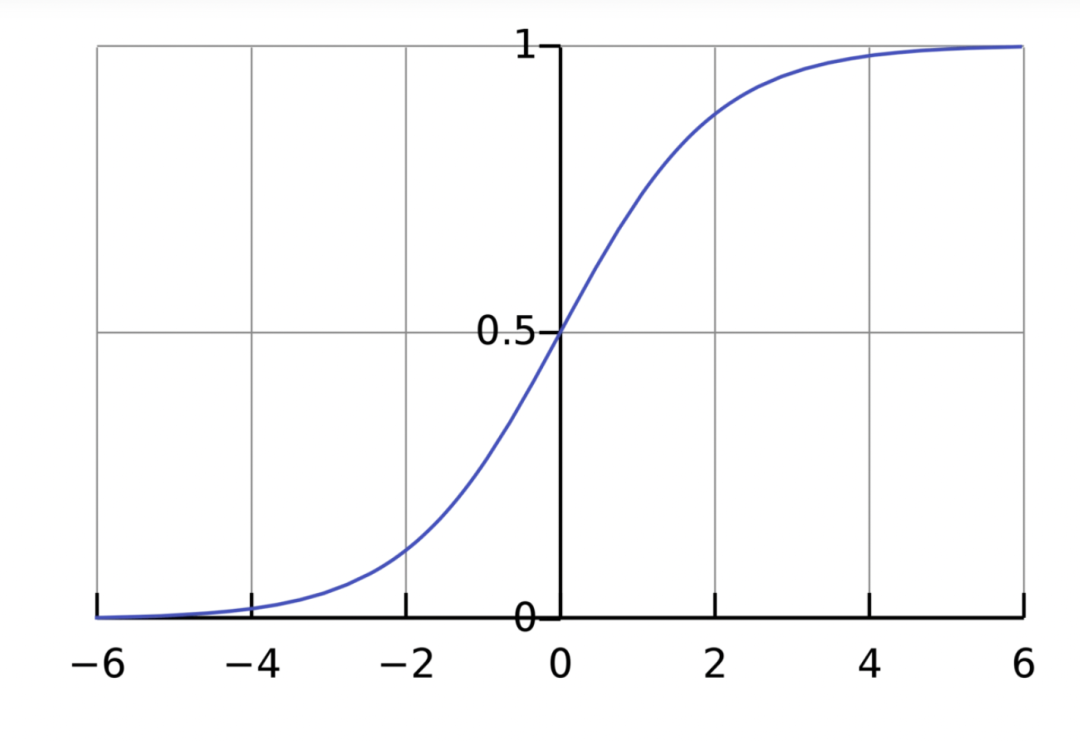
S型函数的值域是(0, 1)。简单来说,就是把(−∞, +∞)压缩到(0, 1) ,很大的负数约等于0,很大的正数约等于1。
给定输入,得到输出的过程被称为前馈(feedforward)
神经网络的基本单位:神经元,接受输入,对其做一些数据操作,然后产生输出
在神经网络的前向传播过程中,输入信号通过加权和计算后,再加上一个偏置值,被送入激活函数中进行激活操作
权重向量:用来计算输入和输出之间的映射关系,通常是一个一维向量或矩阵
偏置值(截距项)的作用是调整神经元的激活阈值,也可以看做是引入了一个额外的信号
隐藏单元:不直接与外界交互的,位于输入层和输出层之间的所有神经元;通过调整隐藏单元中的权重向量和偏置值,可以达到分类和预测的目的
关于self参数和__ init __()函数:
__ init __()函数在类实例创建后立即调用,在对象生命周期中初始化,每个对象必须正确初始化后才能正常工作。——相当于给每个创建的实例自己的属性,不许为空
(两个下划线开头的函数是声明该属性为私有,不能在类的外部被使用或访问。)
init函数的第一个参数必须是self,后面的参数则可以自由定义,和定义函数没有任何区别。
self总是指向调用时的类的实例。它作为类 class 的成员,使得成员间能互相调用
具体构建神经网络的步骤:创建矩阵 -> 转换为变量 -> 设置神经网络 -> 进行训练
把矩阵转化为变量,方便后面进行梯度计算
设置神经网络是关键部分,最简单的一种包括两个部分:__ init()__函数跟forward()函数
__ init()__函数:
包括四个参数,分别是:初始信息,特征数,隐藏单元数,输出单元数
包含三部分:首先是继承模块,此步骤是官方步骤。然后是定义输入层到隐藏层的函数,然后定义隐藏层到输出层的函数。
输入层跟隐藏层,隐藏层跟输出层的关系,对应数量分别是1对10,10对1
forward函数是神经网络的前向传播函数,此函数主要会利用到激励函数,通过前面定义的各层之间的关系,产生新的结果,即新的预测值,此值会拿来跟最终的结果做比较,通过反向传播更新参数值。
训练部分,首先要定义Loss函数和优化器;
训练的过程:得到预测值 - - 利用Loss函数得到误差 - - 梯度清零 - - 反向传播 - - 梯度优化
损失:可以把损失看成是权重和截距项的函数
编码神经元和搭建神经网络的代码和解析部分内容来自:(38条消息) Python 实现一个简单的神经网络(附代码)_神经网络算法代码_Dr.sky_的博客-CSDN博客
编码一个神经元
例:假设我们有一个神经元,激活函数就是S型函数,其参数如下:
w=[0,1],b=4
w=[0,1]就是以向量的形式表示w1=0,w2=1。现在,我们给这个神经元一个输入[2,3]。我们用点积来表示:
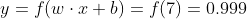
当输入是[2, 3]时,这个神经元的输出是0.999
##————编码一个神经元————##
def sigmoid(x):
# 激活函数: f(x) = 1 / (1 + e^(-x))
return 1 / (1 + np.exp(-x))
class Neuron:
def __init__(self, weights, bias):
self.weights = weights
self.bias = bias
def forward(self, inputs):
# 加权输入,加入偏置,然后使用激活函数
total = np.dot(self.weights, inputs) + self.bias #np.dot:向量点积
return sigmoid(total)
weights = np.array([0, 1]) # w1 = 0, w2 = 1 权重向量
bias = 4 # b = 4 偏置值
n = Neuron(weights, bias)
x = np.array([2, 3]) # x1 = 2, x2 = 3
print(n.forward(x)) # 0.9990889488055994把神经元组装成网络
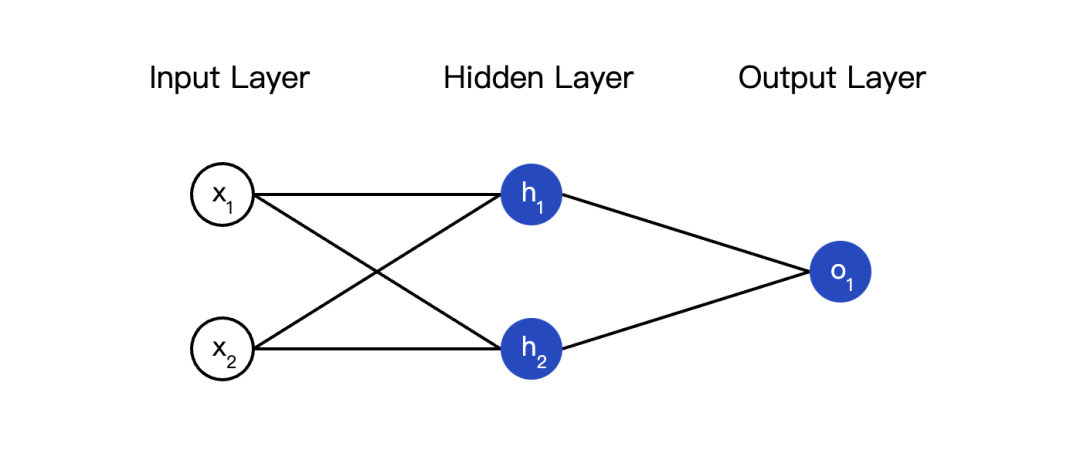
##————编码一个如图的简易神经网络————##
class NeuralNetwork:
"""''
A neural network with:
- 2 inputs
- a hidden layer with 2 neurons (h1, h2)
- an output layer with 1 neuron (o1)
Each neuron has the same weights and bias:
- w = [0, 1]
- b = 0
''"""
def __init__(self):
weights = np.array([0, 1])
bias = 0
#由上一部分神经元类而来
self.h1 = Neuron(weights, bias)
self.h2 = Neuron(weights, bias)
self.o1 = Neuron(weights, bias)
def feedforward(self, x):
out_h1 = self.h1.forward(x)
out_h2 = self.h2.forward(x)
#o1的输入是h1和h2的输出
out_o1 = self.o1.forward(np.array([out_h1, out_h2]))
return out_o1
network = NeuralNetwork()
x = np.array([2, 3])
print(network.feedforward(x)) # 0.7216325609518421训练神经网络
训练过程——最小化其损失
数据集中选择样本
计算损失
用更新等式更新每个权重和截距项
重复第一步
二. AlexNet
Alexnet共有8层结构,前5层为卷积层,后三层为全连接层
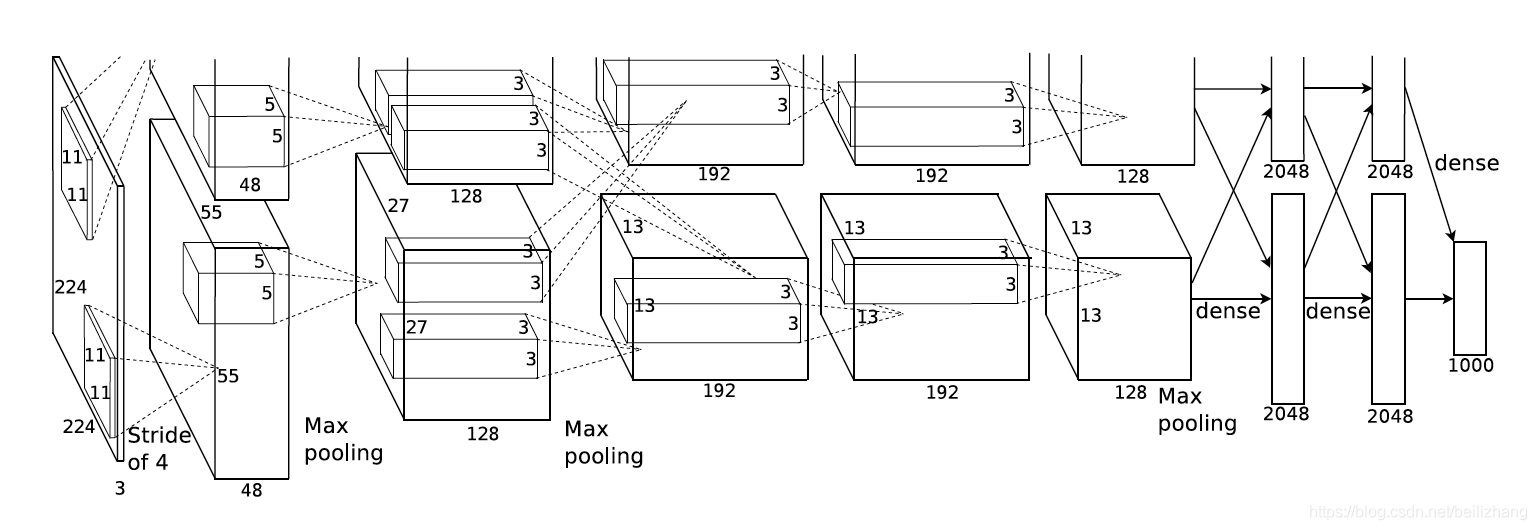
各层作用:

代码实现
注:
python中的super方法:
用来解决多重继承时父类的查找问题,在子类中需要调用父类的方法时用到。好处就是可以避免直接使用父类的名字AlexNet模型创建:
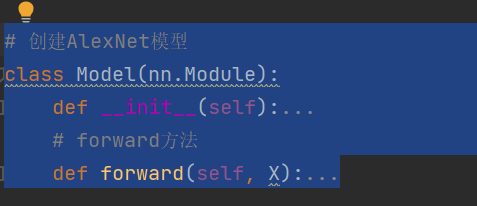
# 创建AlexNet模型
class Model(nn.Module):
def __init__(self):
super().__init__()
# 输入通道数为3,因为图片为彩色,三通道
# 而输出96、卷积核为11*11,步长为4,是由AlexNet模型决定的,后面的都同理
self.net = nn.Sequential(nn.Conv2d(3, 96, kernel_size=11, stride=4, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(96, 256, kernel_size=5, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(256, 384, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(384, 384, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
# 不要忘记在卷积--全连接的过程中,需要将数据拉平
# 传入的x为[batch(每批的个数),x(长),x(宽),x(通道数)]
# 变为[batch,x*x*x]
nn.Flatten(),
# 全连接的第一层,输入是6*6*256
# 输出是由AlexNet模型决定的,为4096
nn.Linear(256 * 5 * 5, 4096),
nn.ReLU(),
# AlexNet采取了DropOut进行正则,防止过拟合
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(0.5),
# 最后一层,输出1000个类别(softmax层)这里改为10个
nn.Linear(4096, 10))
# forward方法
def forward(self, X):
return self.net(X)加载torchvision库中的CIFAR-10数据集:
def getdata():
# 下载以及转换cifar10
# 因为图片大小不同,需要上采样为227*227
# Compose()的主要作用是串联多个图片变换的操作
transform = transforms.Compose([transforms.Resize((224, 224), interpolation=InterpolationMode.BICUBIC),
# 转为tensor对象
transforms.ToTensor(),
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.247, 0.2435, 0.2616])
# 此为训练集上的均值与方差
])
# 使用torchvision.datasets.CIFAR10()加载数据集
# train=True表示数据集为训练数据集
# train=False表示数据集为测试集
# dowwnload=True表示下载数据集
train_images = datasets.CIFAR10('./', train=True, download=True, transform=transform)
test_images = datasets.CIFAR10('./', train=False, download=True, transform=transform)
# 使用DataLoader来加载数据集
# batch_size设置为100
train_data = DataLoader(train_images, batch_size=100, shuffle=True, num_workers=2)
test_data = DataLoader(test_images, batch_size=100, num_workers=2)
return train_data, test_data进行训练+测试:
# 参数初始化
def initial(layer):
# isinstance用来判断一个对象是否是一个已知的类型
if isinstance(layer, nn.Linear) or isinstance(layer, nn.Conv2d):
# 服从正态分布
nn.init.xavier_normal_(layer.weight.data)
if __name__ == '__main__':
# 将模型放入GPU
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
# 创建模型
net = Model().to(device)
net.apply(initial)
epochs = 20 # # 训练20次
lr = 0.01 # 学习率
# 定义损失函数
# 采取分类任务常用的交叉熵损失函数
criterion = nn.CrossEntropyLoss()
# 定义优化器,采取SGD优化器(随机梯度下降)
optimizer = optim.SGD(net.parameters(), lr=lr, momentum=0.9, weight_decay=0.0005)
# 这个优化器测试后准确度只有10%
# 定义优化器,采取Adam优化器
# optimizer = optim.Adam(net.parameters(), lr=lr)
# 训练与测试
# 记录每个epoch的训练、测试误差以及准确率
train_loss, test_loss, train_acc, test_acc = [], [], [], []
train_data, test_data = getdata()
for i in range(epochs):
# 训练
net.train()
# 临时变量
temp_loss, temp_correct = 0, 0
for X, y in train_data:
X = X.to(device)
y = y.to(device)
# 一段丝滑小连招(。)
y_hat = net(X)
# 带入损失函数并产生loss
loss = criterion(y_hat, y)
# 梯度清零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 梯度更新
optimizer.step()
# 计算每次loss与预测正确的个数
label_hat = torch.argmax(y_hat, dim=1)
temp_correct += (label_hat == y).sum()
temp_loss += loss
print(f'epoch:{i + 1} train loss:{temp_loss / len(train_data):.3f}, train Aacc:{temp_correct / 50000 * 100:.2f}%',
end='\t')
train_loss.append((temp_loss / len(train_data)).item()) # 记录loss
train_acc.append((temp_correct / 50000).item()) # 记录准确度
# 测试
# 预测正确个数
temp_loss, temp_correct = 0, 0
# 不启用 BatchNormalization 和 Dropout。此时pytorch会自动把BN和DropOut固定住,不会取平均,而是用训练好的值。
# 不然的话,一旦test的batch_size过小,很容易就会因BN层导致模型performance损失较大
net.eval()
with torch.no_grad():
for X, y in test_data:
X = X.to(device)
y = y.to(device)
y_hat = net(X)
loss = criterion(y_hat, y)
label_hat = torch.argmax(y_hat, dim=1)
temp_correct += (label_hat == y).sum()
temp_loss += loss
print(f'test loss:{temp_loss / len(test_data):.3f}, test acc:{temp_correct / 10000 * 100:.2f}%')
test_loss.append((temp_loss / len(test_data)).item()) # 记录loss
test_acc.append((temp_correct / 10000).item()) # 记录准确度结果:
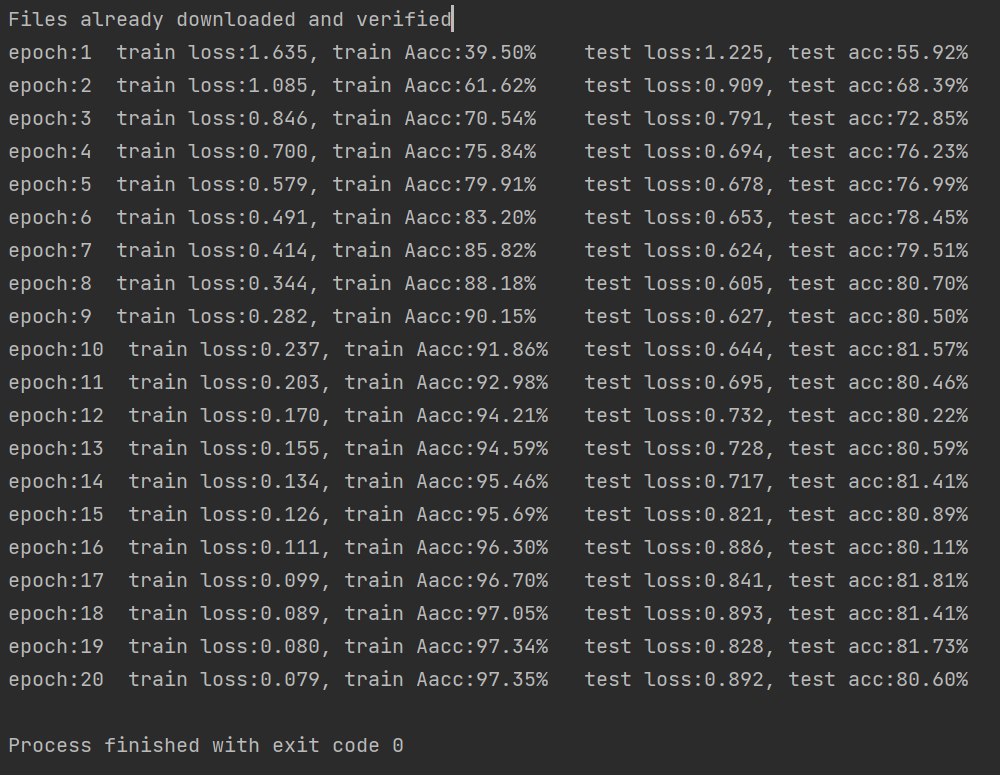
可以看到模型准确度越来越高了
遇到的问题
Adam优化器欠拟合:

????
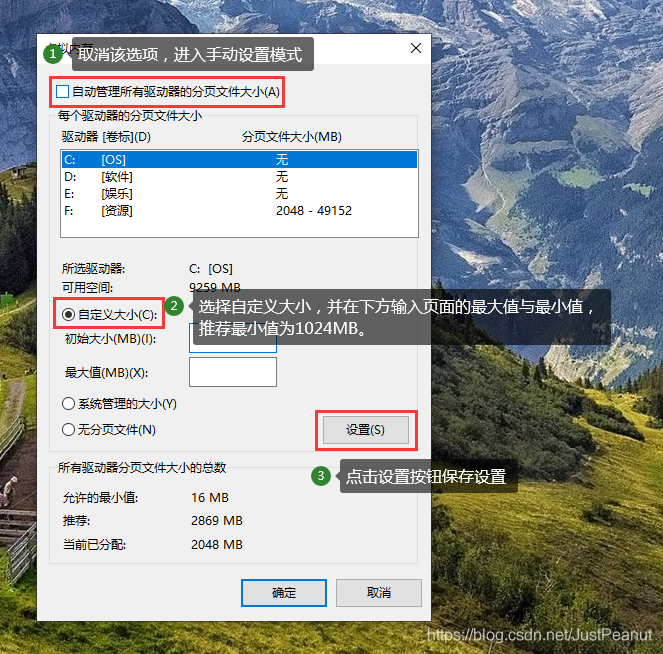
报错:“页面文件太小,无法完成操作"
解决方法:调整了虚拟内存可用硬盘空间大小
三.部署训练好的网络
onnx格式转换
pytorch模型保存:文件中保存模型结构和权重参数
import torch
torch.save(selfmodel,"save.pt")pytorch模型加载:
import torch
torch.load("save.pt")ONNX模型( Open Neural Network Exchage)
转换成这个标准格式后,就可以使用统一的 ONNX Runtime等工具进行统一部署。
pytorch模型转ONNX模型:
import torch
if __name__ == '__main__':
# 加载模型
torch_model = torch.load("MyAlexNet-CIFAR10.pt")
# 输入数据
input_shape = torch.randn(1, 3, 224, 224)
# 将Tensor转换成CUDA
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
torch_model = torch_model.to(device)
torch_model.eval()
# 目的ONNX文件名
export_onnx_file = "MyAlexNet-CIFAR10.onnx"
torch.onnx.export(torch_model, input_shape, export_onnx_file, verbose=True)结果:
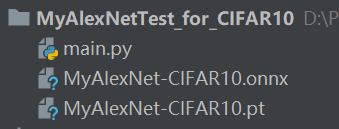
可以看到文件夹下已经有了.onnx的模型,转换成功
遇到的问题:
需要把模型代码复制进去,不然跑不通:
报错以下内容:
RuntimeError: Input type (torch.cuda.FloatTensor) and weight type (torch.FloatTensor) should be the same但是代码中已经将tensor转换成了cuda:
# 将Tensor转换成CUDA
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
torch_model = torch_model.to(device)猜想后,把模型中forward方法的net也放进gpu后解决:

opencv的DNN模块
Googlenet模型实现图像分类
SSD模型实现对象检测
MobileNetSSD模型实时对象检测
FCN模型图像分割
CNN预测年龄和性别
GOTURN模型实现对象跟踪
加载模型并测试
加载训练好的模型->加载图像并将图像准备为正确输入格式->运行模型获得输出
步骤详细解释:
从磁盘加载预训练的AlexNet模型
使用 PyTorch深度学习框架训练的模型,已经转换为.onnx格式
DNN 模块还提供了从特定框架加载模型的函数,如:readNetFromONNX():使用它来加载 ONNX 模型,只需要提供 ONNX 模型文件的路径
先检查模型的版本、图的结构、节点及其输入和输出来验证ONNX图的有效性:
import onnx
import cv2
onnx_model = onnx.load("MyAlexNet-CIFAR10.onnx")
onnx.checker.check_model(onnx_model)ok没问题就继续,下面这一句是主要的
net = cv2.dnn.readNetFromONNX("MyAlexNet-CIFAR10.onnx") # 加载训练好的识别模型解压缩二进制文件的代码:
import pickle
# 解压缩二进制文件
def unpickle(file):
fo = open(file, 'rb')
dict = pickle.load(fo, encoding='latin1')
fo.close()
return dict将datasets的数据集转换为png格式并保存
import numpy as np
from PIL import Image
import os
testXtr = unpickle('cifar-10-batches-py/test_batch')
img = np.reshape(testXtr['data'][0], (3, 32, 32))
img = img.transpose(1, 2, 0)
img_name: str = 'image/' + str(testXtr['labels'][i]) + '_' + str(i) + '.jpg'
cv2.imwrite(img_name, img)保存的图片:(标签是3)
读取图像并为模型输入做好准备
使用 OpenCV 的imread() 函数读取图像,opencv dnn 模块提供blobFromImage() 函数以便我们已正确的格式准备图像以输入模型
# 1:缩放倍数 size:缩放到的大小
blob = cv2.dnn.blobFromImage(img, 1, size=(224, 224))获取输出结果的标签:(这里卡了很久)
# 解析输出结果,获取检测物体的坐标、置信度等信息
out = []
out.append(net.forward())
boxes = []
confidences = []
class_ids = []
for output in outputs:
for detection in output:
scores = detection[5:]
class_id = np.argmax(scores)
confidence = scores[class_id]
if confidence > threshold:
center_x = int(detection[0] * width)
center_y = int(detection[1] * height)
w = int(detection[2] * width)
h = int(detection[3] * height)
x = center_x - w // 2
y = center_y - h // 2
boxes.append([x, y, w, h])
confidences.append(float(confidence))
class_ids.append(class_id)进行测试
net.setInput(blob) # 设置模型输入
out = []
out.append(net.forward())结果:class_id就是测试的标签,可以看到也是3

问题:
net.forward()提供了Numpy ndarray作为输出,网上说可以使用它在给定的输入图像上绘制方框。但具体的返回值还不清楚))
加入循环进行多个图片的测试时,只能打印出第一个测试图片的标签,可能还是因为问题(1)中说的net.forward()返回值不清楚
PS:感谢学姐的小机器人))T T















 471
471











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









