






基础作业 - 完成下面两个作业
1. 在茴香豆 Web 版中创建自己领域的知识问答助手
而RAG是解决上述问题的一套有效方案。
RAG架构
RAG的架构如图中所示,简单来讲,RAG就是通过检索获取相关的知识并将其融入Prompt,让大模型能够参考相应的知识从而给出合理回答。因此,可以将RAG的核心理解为“检索+生成”,前者主要是利用向量数据库的高效存储和检索能力,召回目标知识;后者则是利用大模型和Prompt工程,将召回的知识合理利用,生成目标答案。
- 参考视频零编程玩转大模型,学习茴香豆部署群聊助手
- 完成不少于 400 字的笔记 + 线上茴香豆助手对话截图(不少于5轮)
- (可选)参考 代码 在自己的服务器部署茴香豆 Web 版
- 笔记
-
检索增强生成(Retrieval Augmented Generation),简称 RAG,已经成为当前最火热的LLM应用方案。经历今年年初那一波大模型潮,想必大家对大模型的能力有了一定的了解,但是当我们将大模型应用于实际业务场景时会发现,通用的基础大模型基本无法满足我们的实际业务需求,主要有以下几方面原因:
- 知识的局限性:模型自身的知识完全源于它的训练数据,而现有的主流大模型(ChatGPT、文心一言、通义千问…)的训练集基本都是构建于网络公开的数据,对于一些实时性的、非公开的或离线的数据是无法获取到的,这部分知识也就无从具备。
- 幻觉问题:所有的AI模型的底层原理都是基于数学概率,其模型输出实质上是一系列数值运算,大模型也不例外,所以它有时候会一本正经地胡说八道,尤其是在大模型自身不具备某一方面的知识或不擅长的场景。而这种幻觉问题的区分是比较困难的,因为它要求使用者自身具备相应领域的知识。
- 数据安全性:对于企业来说,数据安全至关重要,没有企业愿意承担数据泄露的风险,将自身的私域数据上传第三方平台进行训练。这也导致完全依赖通用大模型自身能力的应用方案不得不在数据安全和效果方面进行取舍。
完整的RAG应用流程主要包含两个阶段:
数据准备阶段:数据提取——>文本分割——>向量化(embedding)——>数据入库 应用阶段:用户提问——>数据检索(召回)——>注入Prompt——>LLM生成答案
数据准备一般是一个离线的过程,主要是将私域数据向量化后构建索引并存入数据库的过程。主要包括:数据提取、文本分割、向量化、数据入库等环节。
下面我们详细介绍一下各环节的技术细节和注意事项:
数据准备阶段:
向量化是一个将文本数据转化为向量矩阵的过程,该过程会直接影响到后续检索的效果。目前常见的embedding模型如表中所示,这些embedding模型基本能满足大部分需求,但对于特殊场景(例如涉及一些罕见专有词或字等)或者想进一步优化效果,则可以选择开源Embedding模型微调或直接训练适合自己场景的Embedding模型。
线上茴香豆助手对话截图(不少于5轮)





- 数据提取
- 数据加载:包括多格式数据加载、不同数据源获取等,根据数据自身情况,将数据处理为同一个范式。
- 数据处理:包括数据过滤、压缩、格式化等。
- 元数据获取:提取数据中关键信息,例如文件名、Title、时间等 。
- 文本分割:
文本分割主要考虑两个因素:1)embedding模型的Tokens限制情况;2)语义完整性对整体的检索效果的影响。一些常见的文本分割方式如下:- 句分割:以”句”的粒度进行切分,保留一个句子的完整语义。常见切分符包括:句号、感叹号、问号、换行符等。
- 固定长度分割:根据embedding模型的token长度限制,将文本分割为固定长度(例如256/512个tokens),这种切分方式会损失很多语义信息,一般通过在头尾增加一定冗余量来缓解。
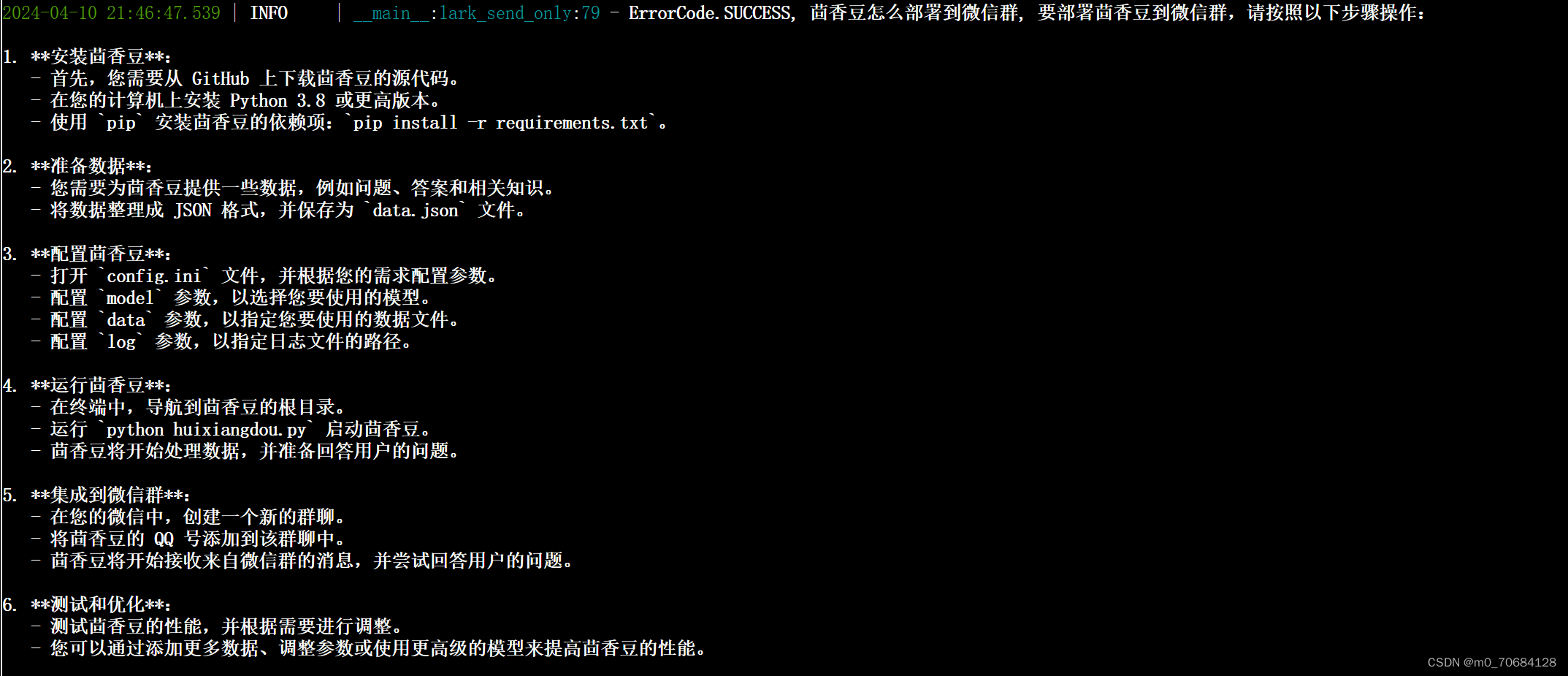
2.在 InternLM Studio 上部署茴香豆技术助手
根据教程文档搭建 茴香豆技术助手,针对问题"茴香豆怎么部署到微信群?"进行提问
完成不少于 400 字的笔记 + 截图
RAG(Retrieval Augmented Generation)技术,通过检索与用户输入相关的信息片段,并结合外部知识库来生成更准确、更丰富的回答。解决 LLMs 在处理知识密集型任务时可能遇到的挑战, 如幻觉、知识过时和缺乏透明、可追溯的推理过程等。提供更准确的回答、降低推理成本、实现外部记忆。
RAG 能够让基础模型实现非参数知识更新,无需训练就可以掌握新领域的知识。本次课程选用的茴香豆应用,就应用了 RAG 技术,可以快速、高效的搭建自己的知识领域助手。
由于茴香豆是一款比较新的应用, InternLM2-Chat-7B 训练数据库中并没有收录到它的相关信息。左图中关于 huixiangdou 的 3 轮问答均未给出准确的答案。右图未对 InternLM2-Chat-7B 进行任何增训的情况下,通过 RAG 技术实现的新增知识问答。RAG技术使得LLMs实现了提供更准确、更丰富的回答。茴香豆是一个基于 LLM 的领域知识助手,工作在群聊里(微信、飞书、钉钉等)。微信头像是俺家的布偶猫,用户更喜欢称它为“豆哥”。
进阶作业 (作业难度非常难, 不用纠结,请先学完后续的课程内容再来做此处的进阶作业~)
A.【应用方向】 结合自己擅长的领域知识(游戏、法律、电子等)、专业背景,搭建个人工作助手或者垂直领域问答助手,参考茴香豆官方文档,部署到下列任一平台。
二、创建知识库
打开茴香豆 web 版 OpenXLab浦源 - 应用中心
- 飞书、微信
- 可以使用 茴香豆 Web 版 或 InternLM Studio 云端服务器部署
- 涵盖部署全过程的作业报告和个人助手问答截图
-
一、准备工作
- 一个 android 手机,对性能和系统都没要求
- 微信版本 8.0.47 (其他版本没效果,因为微信版本强绑定了 ViewID)
- 一个测试用的微信号
三、运行
从 github release 下载编译好的 apk,安装。
1. 填写 web 版提供的微信回调地址,点击 “确定”
2. 点击 “点我”,找到“茴香豆 LLM RAG 回复” 打开或关闭
3. 不要关闭本进程,进入微信群聊天界面,请对方发送消息即可体验
















 574
574











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









