






环境配置
首先到官网下载python、pycharm(参考网上安装教程)
安装到特定文件夹后,打开安装python的文件夹,找到scripts文件夹,复制路径后输入cmd打开命令控制行窗口
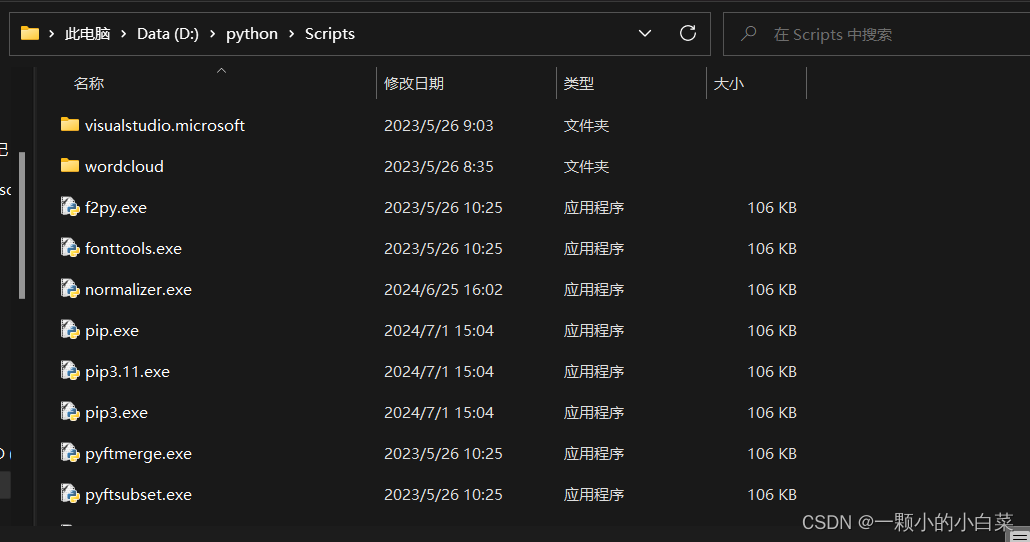
![]()
PIP国内镜像源安装,以此输入下面三条语句,此处参考以下文章Python入门教程:pip永久镜像源的配置方法_python镜像源-CSDN博客
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install pyperclip
pip config list

开始安装pandas、requests库(openpyxl库和pandas库作用一样,只是速度更快)
pip install pandas
pip install requests
pip install openpyxl如果报错出现
 输入
输入
pip install --upgrade pip![]()
如果没有安装如上所述长期镜像,则找到python.exe的位置,输入以下语句
D:\python\python.exe -m pip install --upgrade pip -i https://pypi.tuna.tsinghua.edu.cn/simple/编写爬虫代码
import requests
import pandas as pd
url = 'https://www.zhipin.com/wapi/zpgeek/search/joblist.json?scene=1&query=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90&city=101070200&experience=&payType=&partTime=°ree=&industry=&scale=&stage=&position=&jobType=&salary=&multiBusinessDistrict=&multiSubway=&page=2&pageSize=30'
# 请求头,模拟常见的AJAX请求
# 伪装请求头,在网络【名称】【标头】里去对应找来填
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36',
'Cookie': 'wd_guid=fb55536d-9c5b-4db6-9c47-1b5bdee02b8b; historyState=state; lastCity=101270100; __zp_seo_uuid__=136911d7-eca2-4bb1-8d87-b0e2472a3107; __l=r=https%3A%2F%2Fcn.bing.com%2F&l=%2F&s=1; __g=-; Hm_lvt_194df3105ad7148dcf2b98a91b5e727a=1718952547,1719382587,1719454227,1719815113; boss_login_mode=sms; wt2=D4zzQ_H5LNSy2_UM_DtuZu0CEAXvMC0HK0Dm2cgPEwz61YzHfrrGmy259wU0liET99n33MYkLPm72HYDKGYvEZA~~; wbg=0; zp_at=Di5Qw1ZGjQAMl9zl_NhLkEhtAtoe4qPDCt4aYde5gYU~; Hm_lpvt_194df3105ad7148dcf2b98a91b5e727a=1719815160; __c=1719815113; __a=89692386.1718608840.1719454227.1719815113.17.6.5.17; __zp_stoken__=d96dfMzzDpMKzwrDCsj8gDgsDAwY6JjY8IWg%2BMyA5NjozPDcwRDM8PxY2I1DCtcONecK8X8OCEjMgPDc7MzM%2BNzY4EDw7xLzCtjwzLmHCscOUesKwWcOGUcONwrJQwprCtgEjB8K%2FwrYJMMK1ICHChMKwMzY%2BNVLCsDbCuAXCtTPCuAbCsjLCuTY2NTIpMlEOBVAyNkBBUABAZEJeXlQHSVRNIDU7NTPDrcK4LTAUFAsIDRQUCwgNDAwDCwoICA8UCQ0NDgkUKzPCn8Kyw4XFqcSnw5PElsWhw43Cq8SQxITEv8KkxKvCp8OVw7%2FElsKbxLnCtcOLwpDEt8KDw7vCosO7wqnDocKvw7LCncOOwpHDikPDgsK%2Bw7fChcOrwpDDusKDw6LCgcO0wqjCl8K%2FwozClcKkwqnDpcKSwpVZwpfCkcKXwqPCh8KhTljCvcK9wqNZwrXCtl3CsUnChMKSa8KgUMKnwr90TGJLXVJ7dVAKa21QWwoJXzZXB8OZw4U%3D; geek_zp_token=V1R98uFez0211vVtRuzhQQKC2x5DnXxCs~'
,'X-Requested-With': 'XMLHttpRequest',
'Priority': 'u=1, i',
'Sec-Ch-Ua-Mobile': '?0',
'Referer': 'https://www.zhipin.com/web/geek/job?query=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90&city=101070200',
'Accept': 'application/json',
'Sec-Ch-Ua': '"Google Chrome";v="125", "Chromium";v="125", "Not.A/Brand";v="24"',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
}
response = requests.get(url, headers=headers)
data = response.json()
print(data)
r0 = []
# data['zpData']['jobList'][0]['salaryDesc']
for i in range(len(data['zpData']['jobList'])):
r0.append(data['zpData']['jobList'][i]['salaryDesc'])
print(r0)
r1 = {'数据分析': r0}
df = pd.DataFrame(r1)
# 将 DataFrame 写入 Excel 文件
df.to_excel('D:/output2.xlsx', index=False)
代码中的url和伪装请求头headers里的cookie按照以下步骤查询复制粘贴
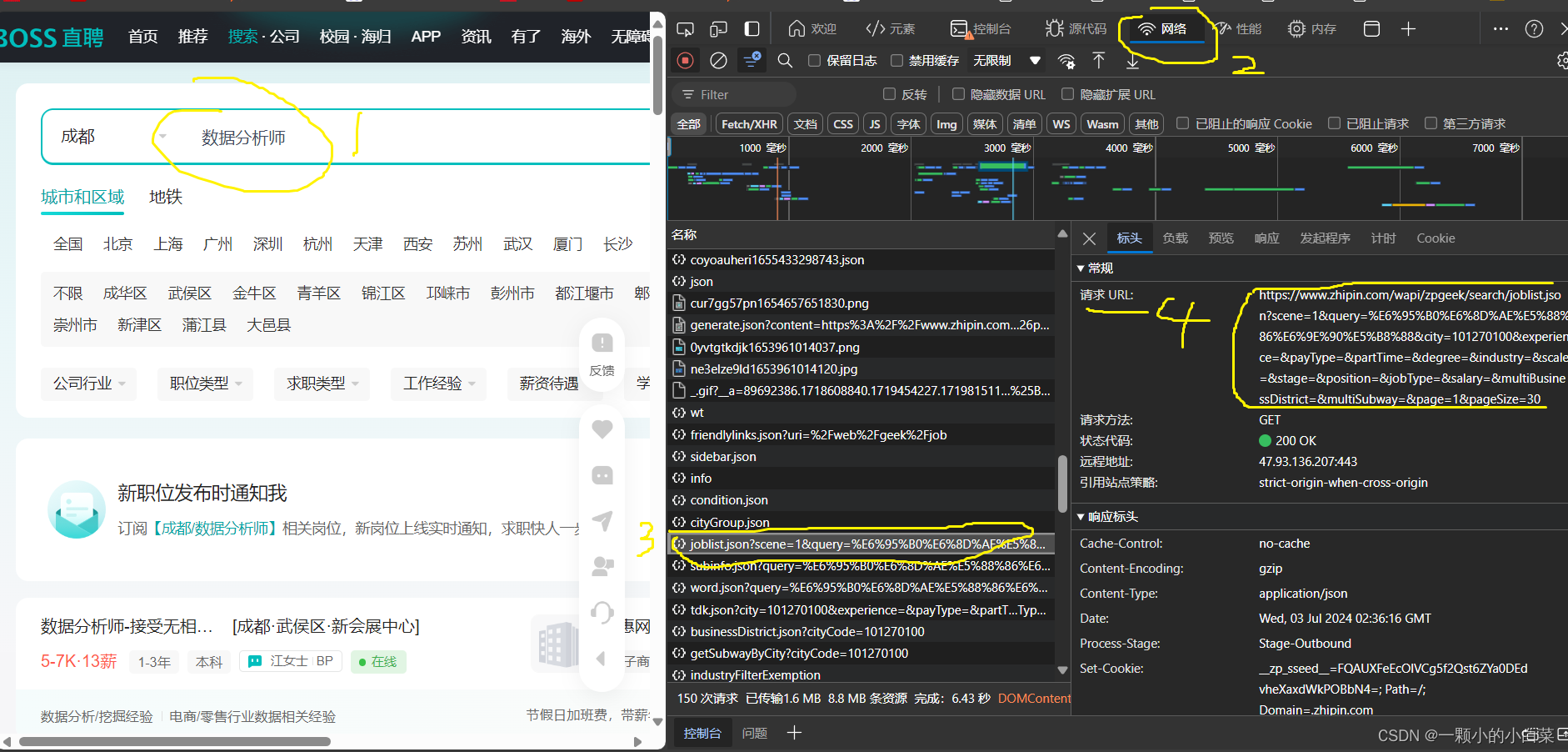
打开boss直聘官网
1.在搜索框随便输入一个类别,比如数据分析师
2.点击F12或者鼠标右键打开检查,找到网络,在名称框找到
![]()
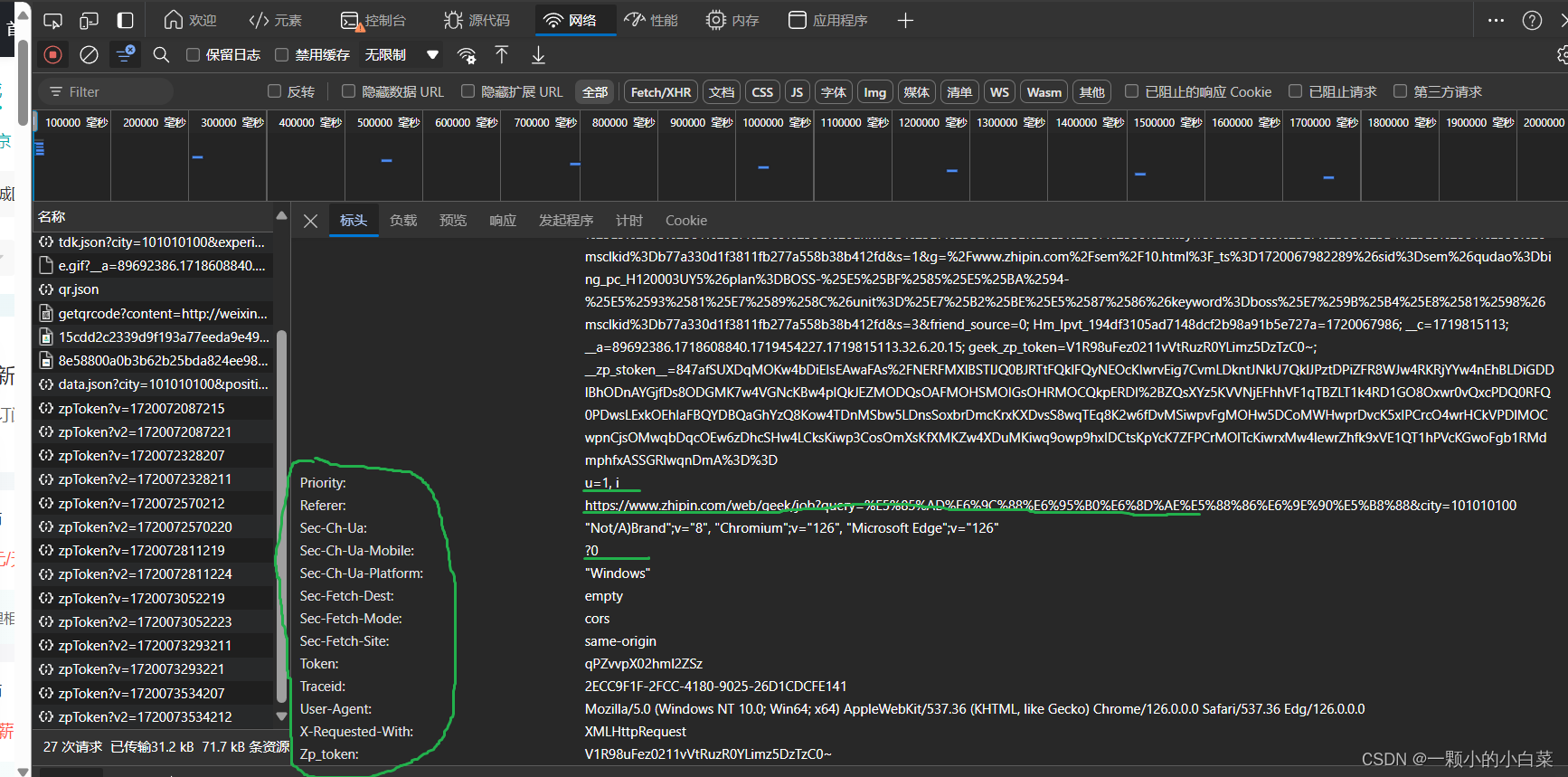
3.点进去,在标头里找到URL和Cookie
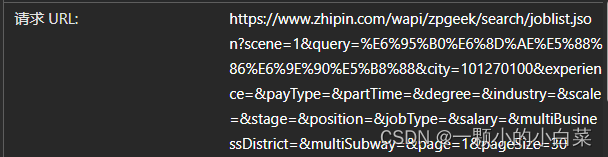
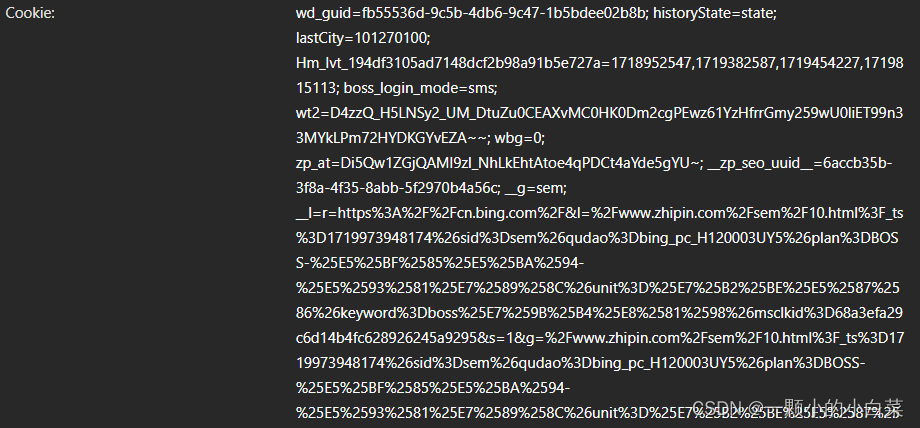
双击打开![]() ,找到对应名称
,找到对应名称
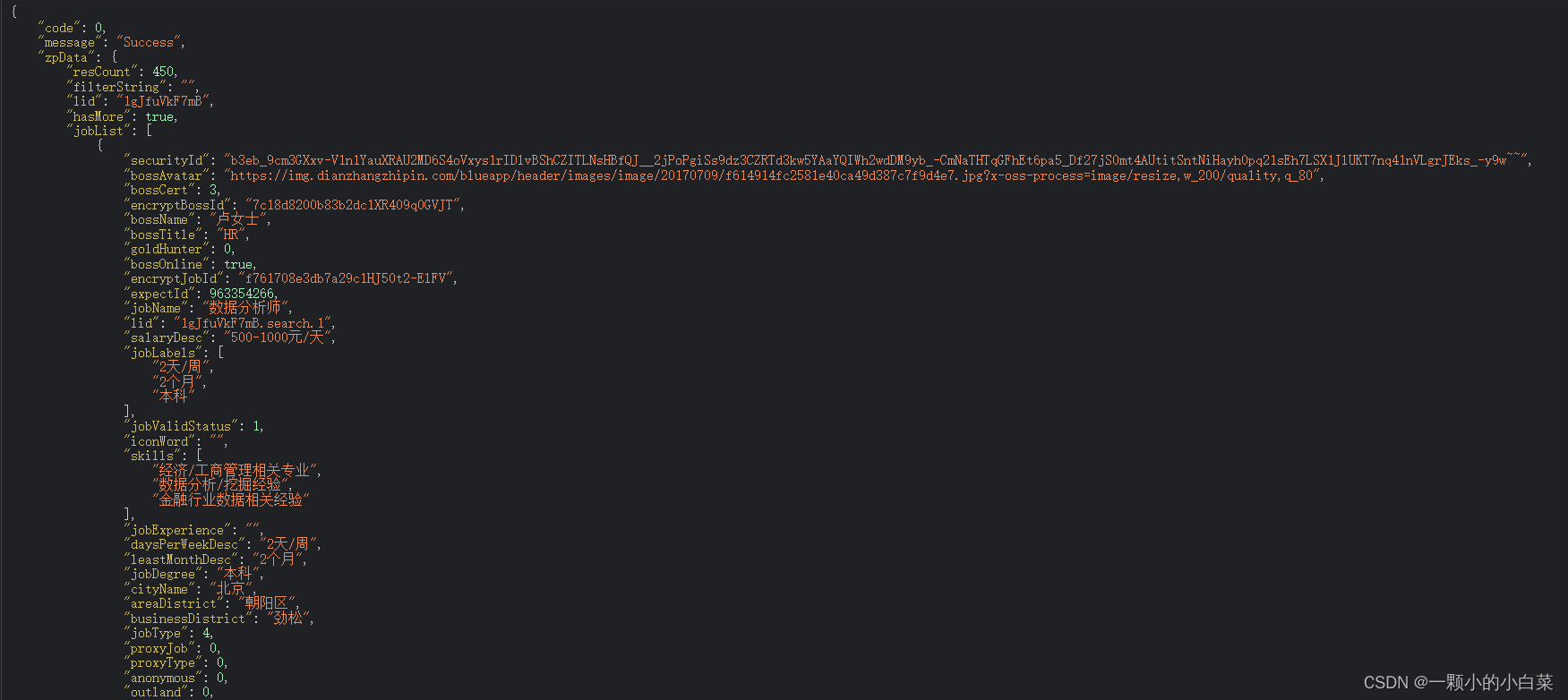
数据导出
按照代码所写,数据导出为excel文件且放在D盘中,大家可以按需修改。


还有一点不足之处,导出文件里面文字格式是字符类型,没办法转换成文本类型,如果有知道怎么更改的请不吝赐教。
完结

















 2976
2976

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









