






学习内容:
- 看懂代码,并整理逻辑思路
学习产出:
# 导入openpyxl和pandas库
import openpyxl
import pandas as pd
#from openpyxl import load_workbook
# 打开excel文件,假设文件名为excel_file.xlsx
wb = openpyxl.load_workbook("excel.xlsx")
# 获取所有的sheet名字
sheet_names = wb.sheetnames
# 定义一个空列表,用来存储每个sheet的数据
data_frames = []
# 遍历每个sheet名字
for sheet_name in sheet_names:
# 读取每个sheet的数据,返回一个DataFrame对象
df = pd.read_excel("excel.xlsx", sheet_name=sheet_name, header=None)
# 定义一个空列表,用来存储每个sheet的每一列
col_list = []
# 遍历每个sheet的每一列
for col in df.columns:
# 定义一个空列表,用来存储每一列的满足条件的单元格内容
sub_list = []
# 定义一个标志变量,用来判断是否遇到“质量问题”
flag = False
# 遍历每一列的每一个单元格
for cell in df[col]:
# 如果遇到“质量问题”,将标志变量设为True
if "质量问题" in str(cell):
flag = True
# 如果标志变量为True,并且单元格不为空,将单元格的内容添加到sub_list中
if flag and not pd.isna(cell):
if "质量问题" in str(cell) or not len(str(cell)):
continue
else:
sub_list.append(cell)
# 如果标志变量为True,并且单元格为空,将标志变量设为False,结束当前列的循环
if flag and pd.isna(cell):
flag = False
if sub_list:
# 将sub_list添加到col_list中
col_list.append(sub_list)
if col_list:
#将col_list添加到data_frames中
data_frames.append(col_list)
# 打印data_frames
print(data_frames)
# 遍历data_frames列表,将每个子列表转换为一个DataFrame对象,并写入到一个新的sheet中
sheet = wb.create_sheet(f"结果")
for index, row in enumerate(data_frames):
# 创建一个新的sheet,并指定一个唯一的名字
# sheet = wb.create_sheet(f"结果{index + 1}")
for i in row:
# 将每一行数据写入到新的sheet中
print(i)
sheet.append(i)
# 保存工作簿
wb.save('excel_file.xlsx')
# 关闭工作簿
wb.close()
1、逻辑思路
1)首先导入openpyxl库和pandas库,并定义wb来接收读入的excel.xlsx文件
pandas库
pandas库中最常用的数据类型是Series和DataFrame。Series是一维数组,拥有数据与索引。DataFrame则是一个类似于表格的二维数据结构,其中储存了多个Series。
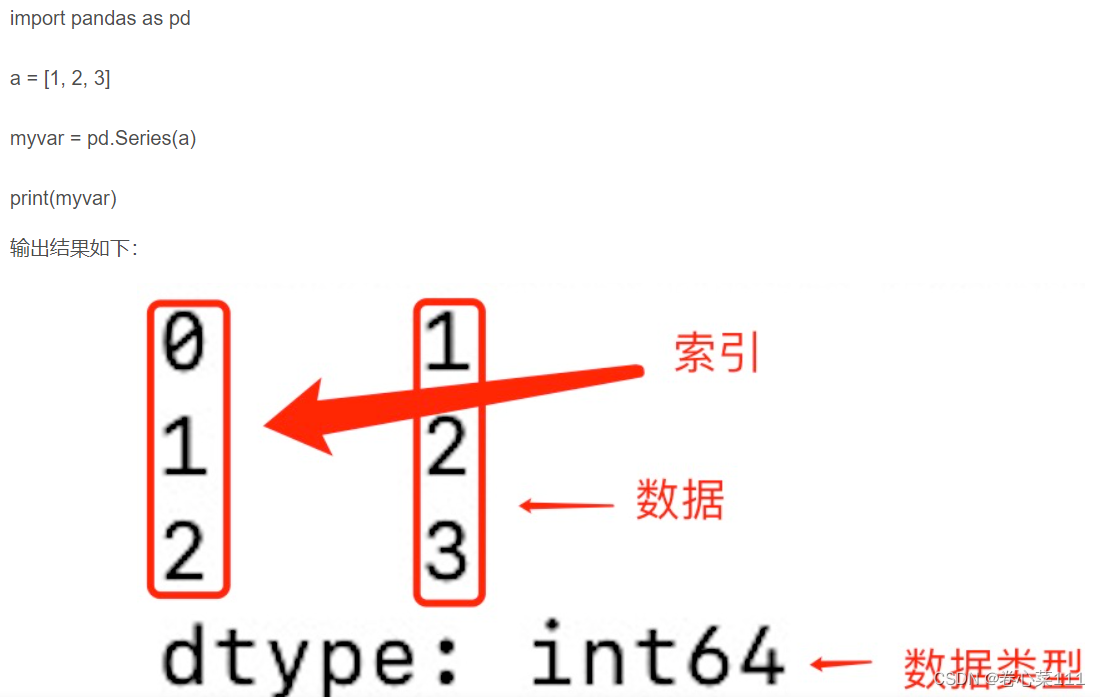
1.1)Pandas Series 类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型。
Series 由索引(index)和列组成,函数如下:
pandas.Series( data, index, dtype, name, copy)
参数说明:
- data:一组数据(ndarray 类型)。
- index:数据索引标签,如果不指定,默认从 0 开始。
- dtype:数据类型,默认会自己判断。
- name:设置名称。
- copy:拷贝数据,默认为 False。
实例:
1.2)DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame
既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。Pandas DataFrame 是一个二维的数组结构,类似二维数组。
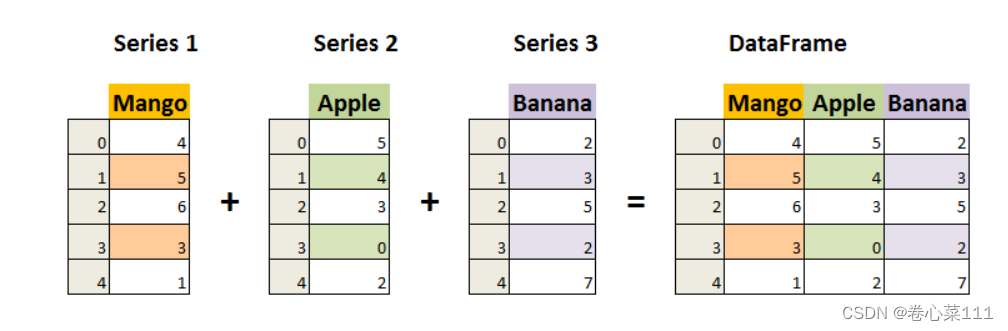
DataFrame 构造方法如下:
pandas.DataFrame( data, index, columns, dtype, copy)
参数说明:
- data:一组数据(ndarray、series, map, lists, dict 等类型)。
- index:索引值,或者可以称为行标签。
- columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) 。
- dtype:数据类型。
- copy:拷贝数据,默认为 False。
实例:

openpyxl库
主要用途:openpyxl库是用于读取、修改和创建Excel xlsx/xlsm/xltm文件的Python库。 它可以用于:
- 创建Excel文件和工作表,以及添加和修改数据。
- 读取Excel文件中的数据。
- 使用Excel图表。
- 使用Excel公式和函数。
- 处理大量数据。
开发人员可以利用这些功能,快速而准确地处理工作簿和工作表。
包含的函数:
以下是openpyxl库中的一些非常有用的功能:
- load_workbook() – 用于加载Excel文件。
- sheet.cell() – 用于选择单元格。
- sheet.iter_rows(min_row=1, min_col=1, max_row=10, max_col=3) –
用于迭代二维数据区域 - sheet.iter_cols(min_row=1, min_col=1, max_row=10, max_col=3) –
用于迭代二维数据区域的列。 - ws.rows – 返回工作表所有行的元组。
- ws.columns – 返回工作表所有列的元组。
- ws.append() – 用于向工作表添加行。
- ws.delete_rows() – 删除行。
- ws.cell(row=1, column=1).value = 1 – 在指定位置写入一个值。
因为openpyxl里面已经封装好了,所以不会对excel表格进行无下限的遍历操作—https://blog.csdn.net/2201_75571291/article/details/130941458
pandas和openpyxl的区别
- Openpyxl是一个专门用于处理Excel文件的库,它提供了一些API用于读取、写入、修改Excel文件,并支持Excel的各种特性,如图表、数据透视表等。
- 而Pandas则是一个用于数据分析和处理的库,它可以从多种数据源中读取数据(包括Excel文件),并提供了丰富的数据操作和分析功能。
- Openpyxl读取和写入Excel文件时速度比Pandas更快,但Pandas的处理和分析大量数据时更加高效。
https://blog.csdn.net/2201_75571291/article/details/130941458
2)定义一些空列表
- 定义data_frames = []空表,用来存储excel表中子表sheet的数据
- 定义 col_list = []空列表,用来存储每个sheet的每一列
- 定义 sub_list = []空列表,用来存储每一列的满足条件的单元格内容
- 定义一个标志变量 flag ,用来判断是否遇到“质量问题”,flag=true则为遇到质量问题的单元格
3)以遍历第一个sheet的第一列为例
3.1)读取第一个sheet数据,返回一个DataFrame对象
df = pd.read_excel("excel.xlsx", sheet_name=sheet_name, header=None)
3.2)遍历第一列的单元格
for cell in df[col]:
3.3)扫描第一列,若第一次遇到“质量问题”的单元格则将flag=true
# 如果遇到“质量问题”,将标志变量设为True
if "质量问题" in str(cell):
flag = True
3.4)若一列中第一个有“质量问题”的单元格设上了标志变量flag,则这列下面的单元格就进行以下判断,如果遇上有“质量问题”或为空的单元格则continue,不加入sub_list;其他不为空且没有“质量问题”的单元格则加入到sub_list中
# 如果标志变量为True,并且单元格不为空,将单元格的内容添加到sub_list中
if flag and not pd.isna(cell):
if "质量问题" in str(cell) or not len(str(cell)):
continue
else:
sub_list.append(cell)
# 如果标志变量为True,并且单元格为空,将标志变量设为False,结束当前列的循环
if flag and pd.isna(cell):
flag = False
3.5)以此类推,遍历每个sheet的每列的每一个单元格,最后得到有质量问题数据的data_frames列表
3.6)遍历得到的data_frames列表,将数组按行存放转为按列存放,并添加进sheet表中。
# 遍历data_frames列表,将每个子列表转换为一个DataFrame对象,并写入到一个新的sheet中
sheet = wb.create_sheet(f"结果")
for index, row in enumerate(data_frames):
# 创建一个新的sheet,并指定一个唯一的名字
# sheet = wb.create_sheet(f"结果{index + 1}")
for i in row:
# 将每一行数据写入到新的sheet中
print(i)
sheet.append(i)
3.7)输出结果
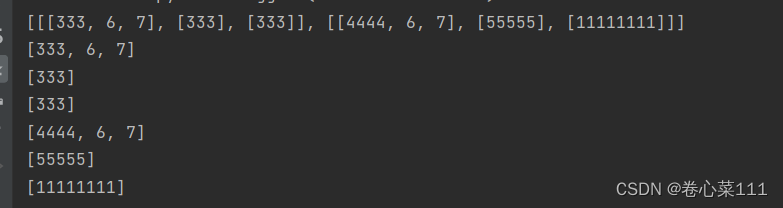
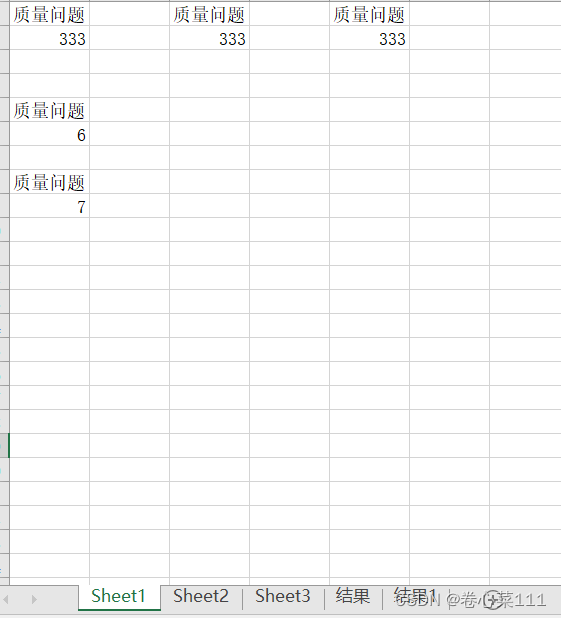
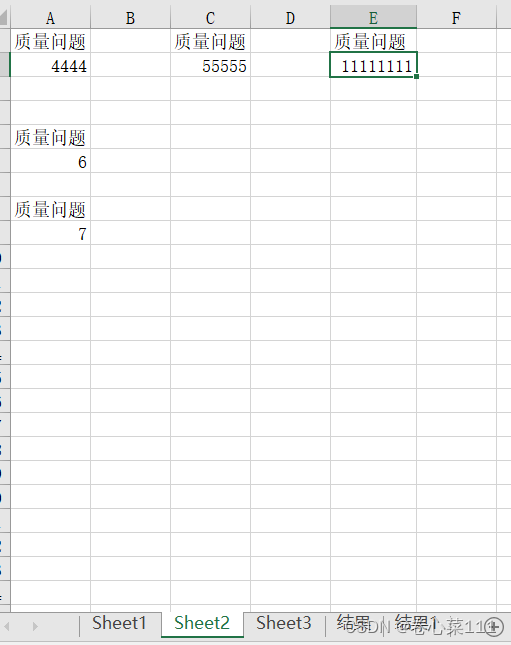
















 228
228











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









