






学习目标:
- 掌握 词云的相关知识
学习内容:
- 词云
- 出现的小问题
- 小任务:1.对词组出现次数排序,把常见的依次排; 2.研究词云图的生成原理,字体是否能够全部放正;3、一次性显示词条的个数;4、更换词条颜色
学习时间:
- 周二 19:00-21:0
- 周三 8:30-10:00
学习产出:
一、词云
1、定义:
词云是一种将文本中的高频词汇以不同的大小和颜色呈现在图片上的可视化方法,它可以帮助我们快速地发现文本的主题和关键信息。
2、步骤
- 安装Python的wordcloud库,
(pip install wordcloud) - 读取我们想要生成词云的文本文件,可以是任何格式的文本,如txt、csv、json等。我们可以使用Python的内置函数**open()**来读取文本文件,如:
with open('text.txt', 'r', encoding='utf-8') as f: txt = f.read()。
as f: txt = f.read()指将文本text重命名为f
- 对文本进行分词处理,为了让wordcloud库能够识别出文本中的单词和词频。对于英文文本,wordcloud库会自动根据空格或标点符号进行分词;对于中文文本,我们需要使用jieba库来进行分词,jieba库是一个优秀的中文分词库,它可以根据中文词典和概率模型来切分中文句子。可以使用pip命令来安装jieba库,如:
pip install jieba。然后我们可以使用jieba.lcut()函数来对中文文本进行分词,并用空格连接成一个字符串,如:
words = jieba.lcut(txt)
newtxt = ' '.join(words)。 - 创建一个WordCloud对象,并设置相关的参数,如字体、背景色、最大词数、最大字号、遮罩图片等。
- 字体参数font_path需要指定一个支持中文的字体文件,否则中文会显示为方框;
- 遮罩图片参数mask需要指定一个有透明背景的png格式图片,这样词云会根据图片的形状生成;其他参数可以根据自己的喜好调整。
- 例如:
wc= WordCloud(font_path='msyh.ttf', background_color='white', max_words=100, mask=mask).generate(newtxt)。
- 保存或显示生成的词云图片,我们可以使用WordCloud对象的
to_file()方法来保存图片到本地文件,或者使用matplotlib库来显示图片到屏幕上。- 例如:
wc.to_file('wordcloud.png')
plt.imshow(wc)
plt.axis('off')
plt.show()。
3、wordcloud.WordCloud()相关参数
-
font_path:字体位置,中文的时候需要制定一些。
-
prefer_horizontal:float,水平方向的拟合次数,如果小于1,一旦水平方向不合适就旋转这个词。意思就是词云的算法水平词和竖直方向词的一种数量衡量。
-
mask :控制词云的背景。
//如果不设置,则词云是正规矩形。
//如果 mask 非空,设置的宽高值将被忽略,遮罩形状被 mask 取代。
//使用蒙版图片:mask = np.array(Image.open(“3. alice3.png”)) ,将图片中不是白色的地方作为轮廓。 -
scale:缩放图片–scale : float (default=1)
//按照比例进行放大画布,如设置为1.5,则长和宽都是原来画布的1.5倍。 -
max_words:显示的最大词 --max_words : number (default=200)
//要显示的词的最大个数 -
stopwords:停用词,设置需要屏蔽的词,如果为空,则使用内置的STOPWORDS
-
relative_scaling:这个比较有意思,如果true,字体的大小与词语顺序有关。false,字体大小与词云频率有关。
-
font_path : string —
font_path="simhei.ttf"
//字体路径,词云图默认不支持中文,所以一般都要设置该参数 -
font_step : int (default=1)
//字体步长,如果步长大于1,会加快运算但是可能导致结果出现较大的误差 -
width : int
//输出的画布宽度,默认为400像素,越宽,词云中包含的关键词越多 -
height : int
//输出的画布高度,默认为200像素 -
prefer_horizontal : float (default=0.90)
//词语水平方向排版出现的频率,默认 0.9 (所以词语垂直方向排版出现频率为 0.1 ) -
min_font_size : int (default=4)
//显示的最小的字体大小 -
colormap : string or matplotlib colormap, default=”viridis”
//给每个单词随机分配颜色,若指定color_func,则忽略该方法 -
background_color : color value (default=”black”)
//背景颜色,如background_color=‘white’,背景颜色为白色。 -
max_font_size : int or None (default=None)
//显示的最大的字体大小 -
color_func : callable, default=None
//生成新颜色的函数,如果为空,则使用 self.color_func -
regexp : string or None (optional)
//使用正则表达式分隔输入的文本
4、相关函数
- fit_words(frequencies) 根据单词与频率生成词云 ,必须传入字典形式的!
- generate(tex) 根据文本直接生成词云,仅限英文的
- generate_from_frequencies(frequencies, max_font_size=None)
根据单词与频率生成词云,可以指定最大数目 - generate_from_text()根据文本直接生成词云,英文的
- process_text(text) 根据text生成单词的统计数目,返回{word,int},去除了停用词。只限于英文的
5、颜色方案
- ‘viridis’: 这是一种逐渐变化的颜色方案,从浅绿色到深紫色。它在视觉上有很好的对比度和感知平衡。
- ‘plasma’: 从亮粉红色到深紫色变化。它在视觉上具有高对比度和明亮感。
- ‘inferno’: 从黄色到黑色变化。它在视觉上具有高对比度和明亮感,适合表示温暖和热度。
- ‘magma’: 从浅粉红色到深紫色变化。它在视觉上具有高对比度和渐变效果。
- ‘cividis’: 从黄色到深蓝色变化。它在视觉上具有高对比度和明亮感,适合表示连续性和变化。
- ‘cool’: 从蓝色到紫色变化。它给人一种冷静和科技感的印象,适合表示数字、科技和数据相关的主题。
- ‘coolwarm’:从蓝色到红色变化,通过冷色和暖色的组合来表示正负变化。
- ‘twilight’: 从深蓝色到淡黄色变化,给人一种神秘和夜晚的感觉。
- ‘twilight_shifted’: 这是 ‘twilight’ 颜色方案的偏移版本,从深紫色到浅绿色变化,带有一种幻幽的感觉。
- ‘hsv’: 这是一种颜色方案,从红色开始,沿着色相环绕变化。它在视觉上具有鲜艳和多样性。
6、例子
https://zhuanlan.zhihu.com/p/639766442
#导入所需的包
import pandas as pd #用于数据处理和读取 Excel 文件。
from wordcloud import WordCloud #用于生成词云图。
import numpy as np #用于处理数组数据。
from PIL import Image #用于处理图像数据。
import jieba #用于中文分词。
txt = open(r"C:\Users\admin\Desktop\上海市_2020_名词.txt", encoding= "utf-8").read()
#中文使用utf-8解码,read为全部读取,同类的还有readline()
txt = jieba.lcut(txt) #jieba分词为列表
txt = " ".join(txt) #用空格分隔词语,转化为一个长字符串
stop = [] #设置停止词,如果长度小于等于1,则设置为停止词,例如标点符号和单个字
for i in txt:
if len(i) <= 1:
stop.append(i)
# 加载字体文件和词云形状图片
font_path = r"fonts/STXINGKA.TTF" # 替换为您的字体文件路径,可以去网上下载,或者在电脑上搜索fonts,看看有没有相关ttf文件
mask_image_path = r"C:\Users\admin\Desktop\词云轮廓.jpg" #加载词云形状图片作为 mask,即想要词云呈现什么形状
mask_image = Image.open(mask_image_path).convert('L')
mask_array = np.array(mask_image)
wordcloud = WordCloud(
width=800,
height=400,
background_color="white", # 设置词云背景颜色为白色
font_path=font_path, # 设置词云中的字体样式
colormap='viridis', # 设置词云颜色方案为viridis
max_words=1000, # 词云中显示的最大词语数量
max_font_size=500, # 设置词云中的最大词语字体大小为500
scale=10, # 控制词云图像的清晰度,值越大越清晰
mask=mask_array, # 设置词云的形状为mask
collocations=True, # 启用词语组合,使词云中的词语能够形成搭配
prefer_horizontal=0.7 # 控制词云中横排文字的比例,值越大横排文字越多
)
# 根据词频数据生成词云图并保存
wordcloud.generate(txt)
wordcloud.to_file(r'C:\Users\admin\Desktop\wordcloud.png') #默认保存为桌面
二、出现的问题
1、安装worldcloud库时报错:
ERROR: Could not find a version that satisfies the requirement worldcloud (from versions: none)
ERROR: No matching distribution found for worldcloud
解决办法:
法一: 出现这个问题的原因是pip升级到7.0以后, pip包管理工具直接从镜像源下载相关的依赖库时,所需要的镜像源必须是HTTPS协议的网络地址,不能直接从非HTTPS协议的镜像源地址下载依赖库。如果想从非HTTPS协议的镜像源地址下载依赖库,在使用pip命令下载依赖库的时候需要添加–trusted-host域名配置
法二、
给python配置一个国内镜像

在pycharm终端成功进行pip
下载SimHei字体https://www.duote.com/soft/915316.html
三、小任务
1、对词组出现的常见词条按由高到低的次数进行排序


2、研究词云图的生成原理,并将字体全部放正–
prefer_horizontal : float (default=0.90) //词语水平方向排版出现的频率,默认 0.9 (所以词语垂直方向排版出现频率为 0.1 )

3、一次性显示词条的个数

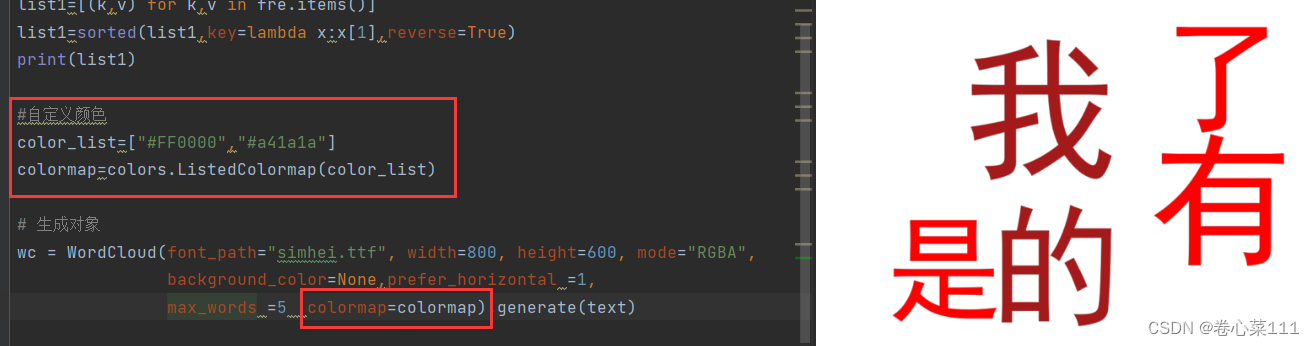
4、更换词条颜色















 1941
1941











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









