






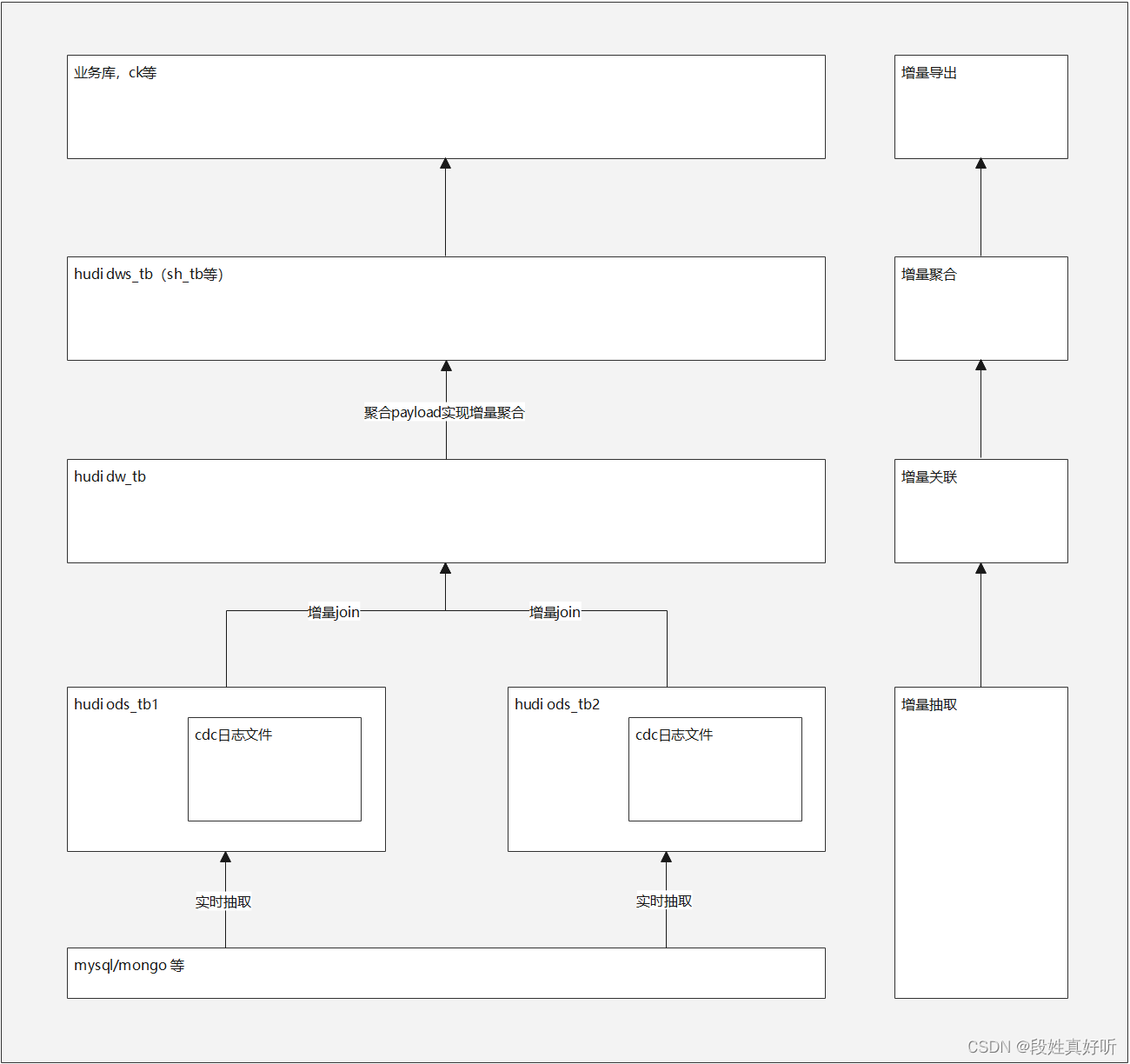
一:简介
1.ods层采用实时抽取到hudi表的方式,生成cdc文件
2.dw层在处理大表关联大表的时候,通过ods表的cdc文件获取ods的增量信息,然后进行增量关联,关联完毕后生成dw表的结果和cdc文件
3.dws层的hudi表,定义聚合的payload,在处理dw层表的聚合的时候,先处理增量部分的聚合再将结果与历史的做整合处理即可
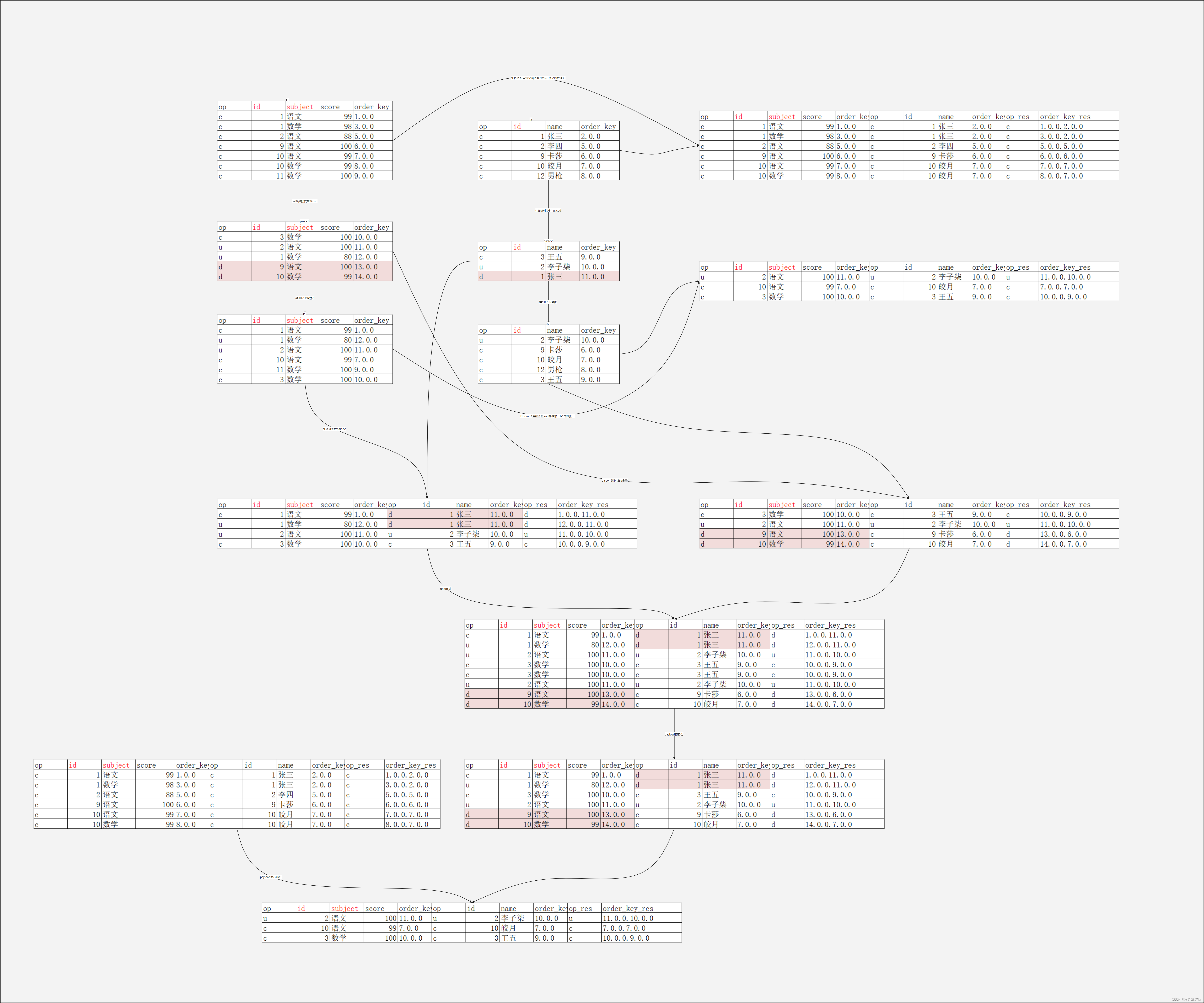
二:dw层增量join设计
1.左表全量join关联右表的增量为tmp1
2.左表增量join关联右表的全量为tmp2
3.tmp1 union all tmp2为tmp3
4.将tmp3 insert into到历史数据得到最新的数据(payload的预聚合和聚合部分)
tips:
| join的情况: 1.有一个d则为d 2.两个都为c则为c 3.为c和u的情况,有u则u | ||
| tb_1_op | tb_2_op | res_op |
| c | c | c |
| c | u | u |
| c | d | d |
| u | c | u |
| u | u | u |
| u | d | d |
| d | c | d |
| d | u | d |
| d | d | d |
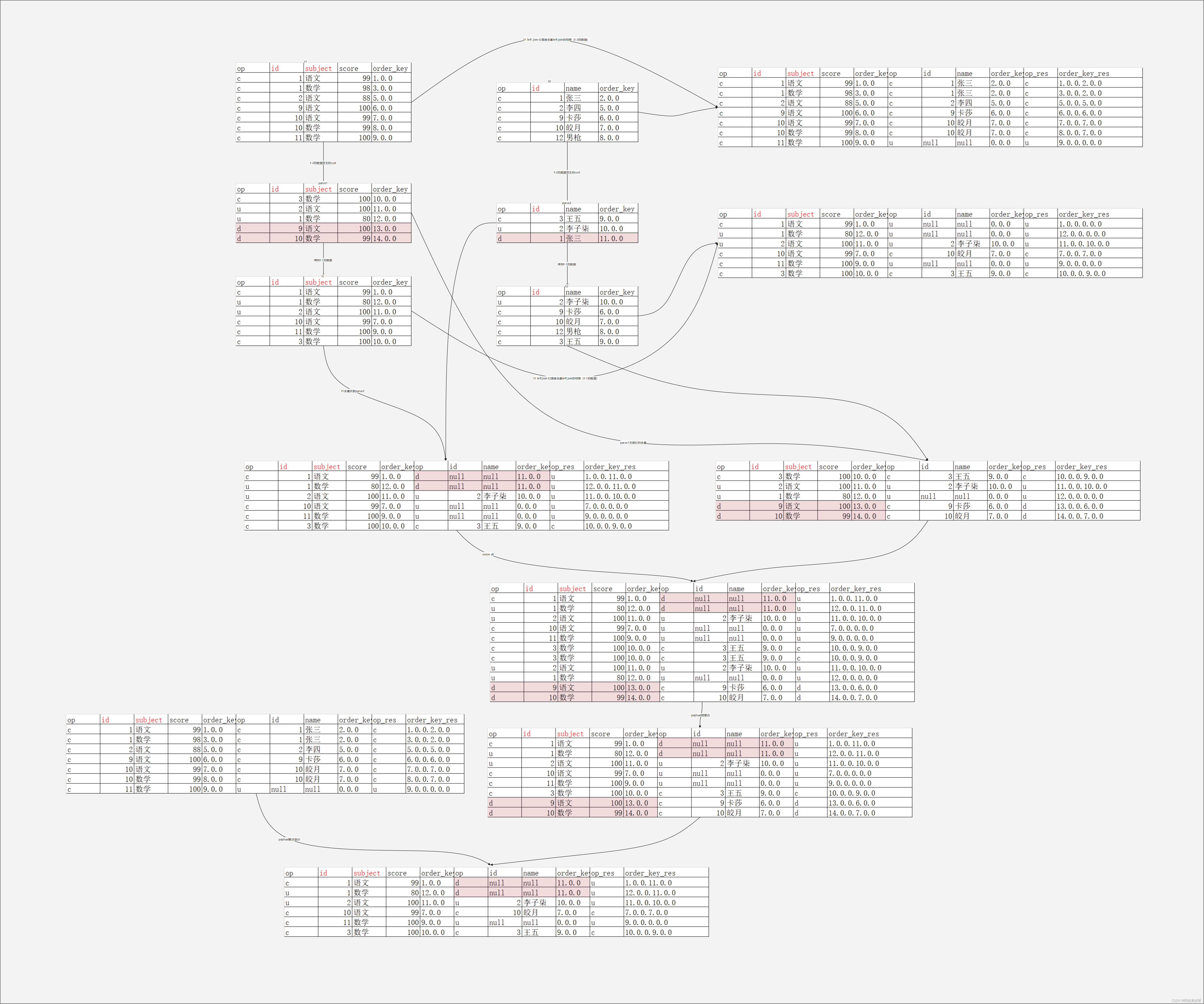
三:dw层增量left join设计
1.左表全量left join关联右表的增量为tmp1
| 左表全量关联右表增量,null的右表op认为是u,null的order_key认为是0.0.0 |
| null的原因 |
| 1.右表本身就没有改变的数据 |
| 2.右表本身没有的数据 |
| 操作后将右表为d的数据部分改为null |
2.左表增量left join关联右表的全量为tmp2
| 左表增量关联右表全量,null的右表op认为是u,null的order_key认为是0.0.0 |
| null的原因 |
| 1.右表对应的数据删除了 |
3.tmp1 union all tmp2为tmp3
4.将tmp3 insert into到历史数据得到最新的数据(payload的预聚合和聚合部分)
tips:
| left join的情况: 1.左表u、d跟随左表 2.左表为c的时候,右表为c则为c,其他情况为u | ||
| tb_1_op | tb_2_op | res_op |
| c | c | c |
| c | u | u |
| c | d | u |
| u | c | u |
| u | u | u |
| u | d | u |
| d | c | d |
| d | u | d |
| d | d | d |
四:dws层增量聚合
















 1236
1236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









