



线程与线程之间数据交互
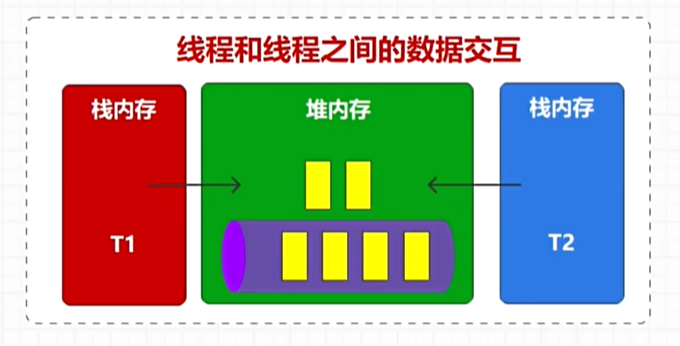
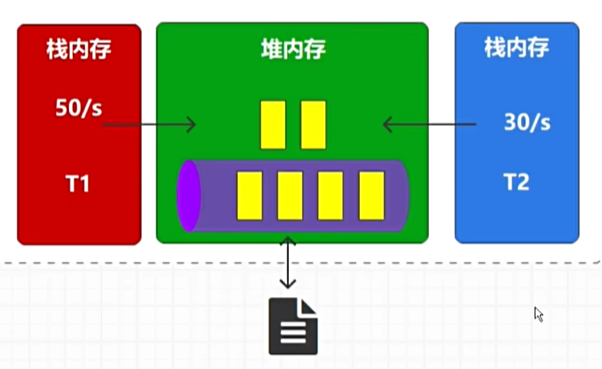
问题1:长时间的消耗消息与发送速率不匹配,就会导致数据积压,导致资源消耗,导致系统不可用
进程与进程之间的数据交互
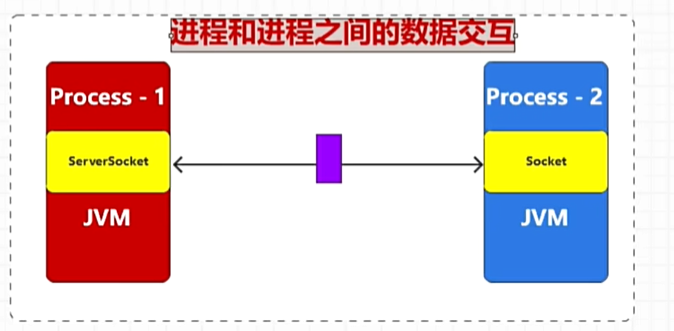
问题1:会增加逻辑判断标记数据具体是发送给谁的,消耗计算资源,降低系统相应速度
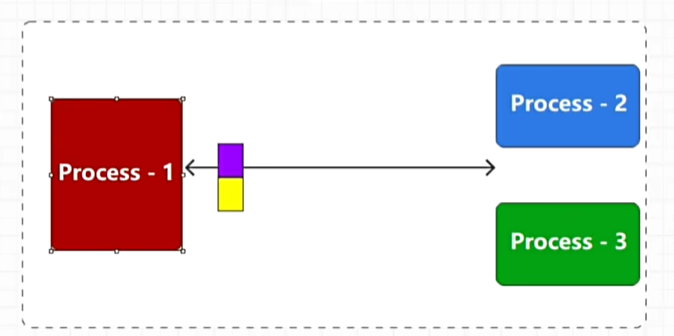
解决:
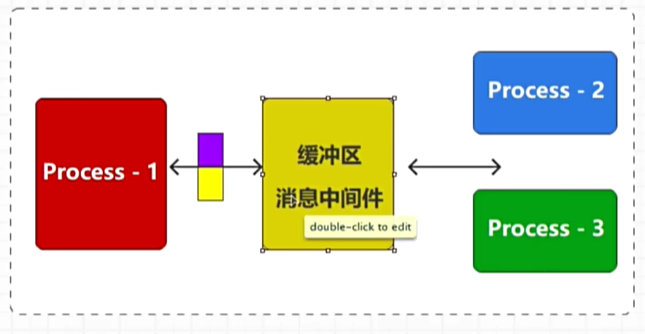
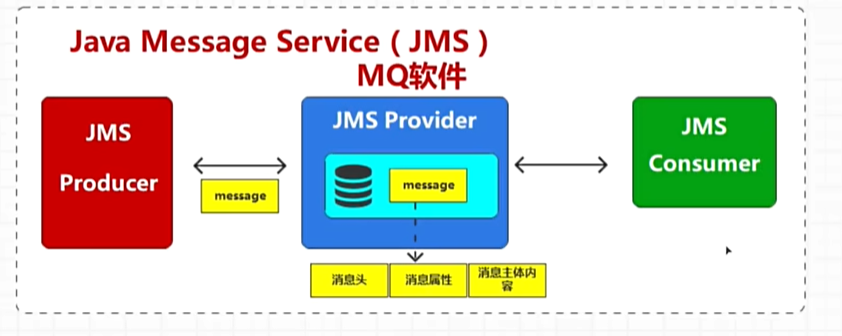
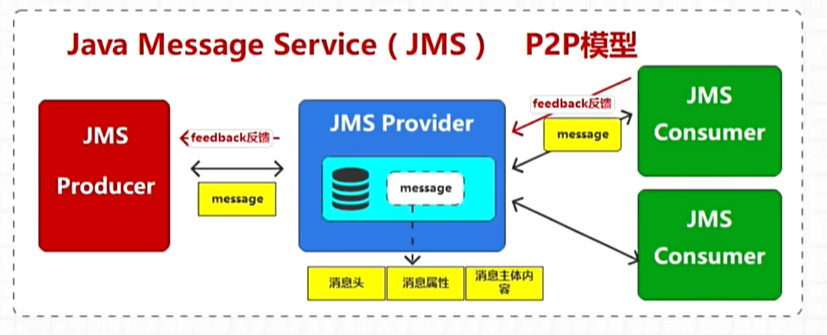
点对点模型:消息队列中的消息每个只能被消费一次
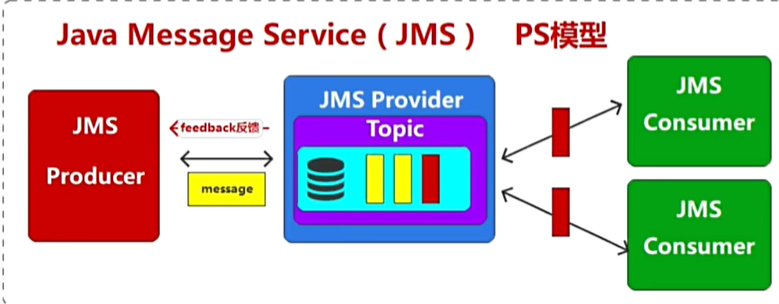
发布订阅模型(PS):
第一节
开发中消息中间件对比
| 特性 | ActiveMQ | RabbitMQ | RocketMQ | Kafka |
| 单机吞吐量 | 万级,比RocketMQ,Kafka低一个数量级 | 万级,比RocketMQ,Kafka低一个数量级 | 10万级,支持高吞吐 | 10万级,支持高吞吐 |
| Topsic数量对于吞吐量的影响 | Topic可以达到几百/几千量级 | Topic可以达到几百量级.如果更多的话,吞吐量会大幅下降 | ||
| 时效性 | ms级 | 微秒级别,延迟较低 | ms级 | ms级 |
| 可用性 | 高,基于主从架构实现高可用 | 高,基于主从架构实现高可用 | 非常高,分布式架构 | 非常高,分布式架构 |
| 消息可靠性 | 有较低概率丢失数据 | 基本不丢失 | 经过参数优化配置,可以做到0丢失 | 经过参数优化配置,可以做到0丢失 |
| 功能支持 | MQ领域的功能极具完备 | 并发能力强,性能极好,延时很低 | MQ功能较为完善,分布式,拓展性好 | 功能较简单,支持简单的MQ功能,再大数据领域被广泛使用 |
| 其他 | 再很早的软件,社区不是很活跃 | 开源,稳定社区活跃度高 | 阿里开发,社区活动不高 | 开源,高吞吐量,社区活跃度极高 |
Kafka-组件
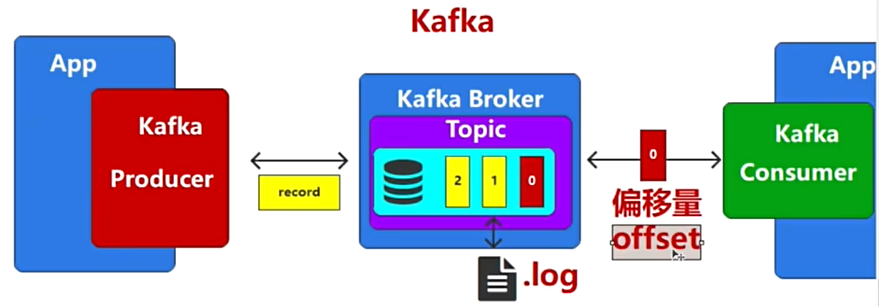
Kafka代码-生产者
Kafka代码-消费者
kafka-基础架构图形推演
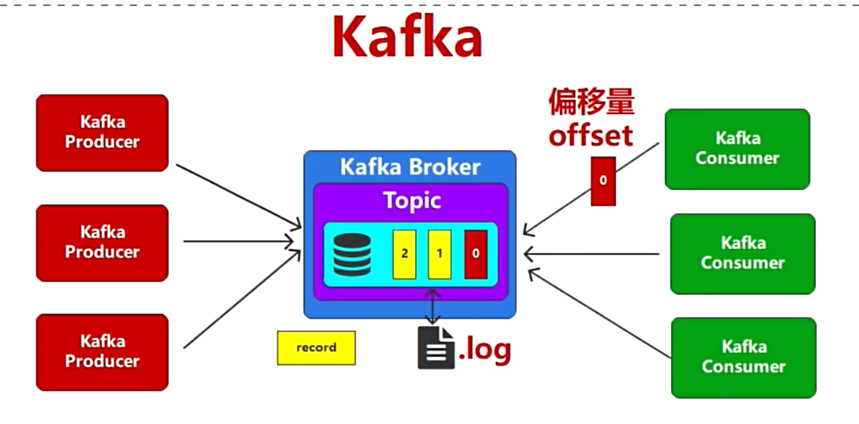
问题:因为有很多的生产和和很多的消费者,导致大量的吞吐数据导致IO热点问题,导致单一的节点变成系统的瓶颈,降低系统稳定性
解决方案:
- 横向扩展:增加服务节点,搭建服务器集群,降低单点故障带来的风险
- 纵向扩展:增加系统的资源配置
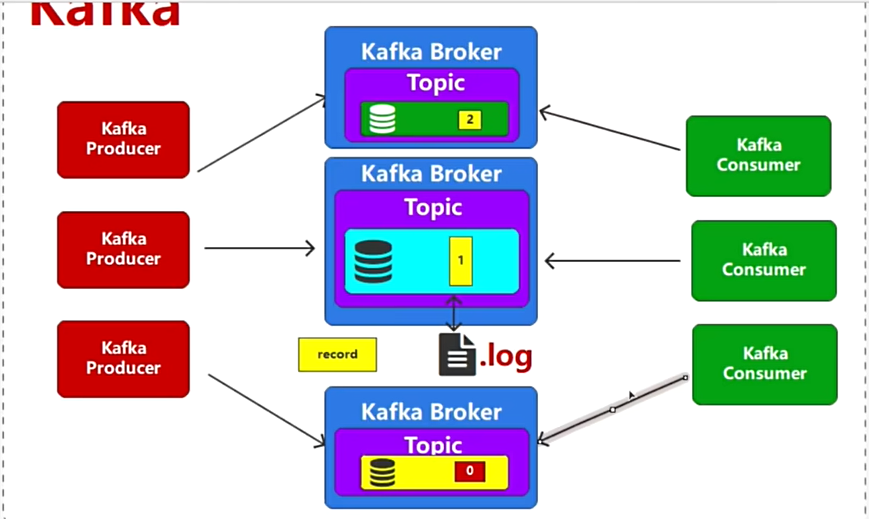
注意:当前topic切换成多块,这样的话数据也会切割成多块,要给不同的数据库增加编号(分区:顺序号--partition:1)
问题提出:当其中一个Broker down掉之后会丢失一条数据,这样数据不安全,如何破局--互相备份
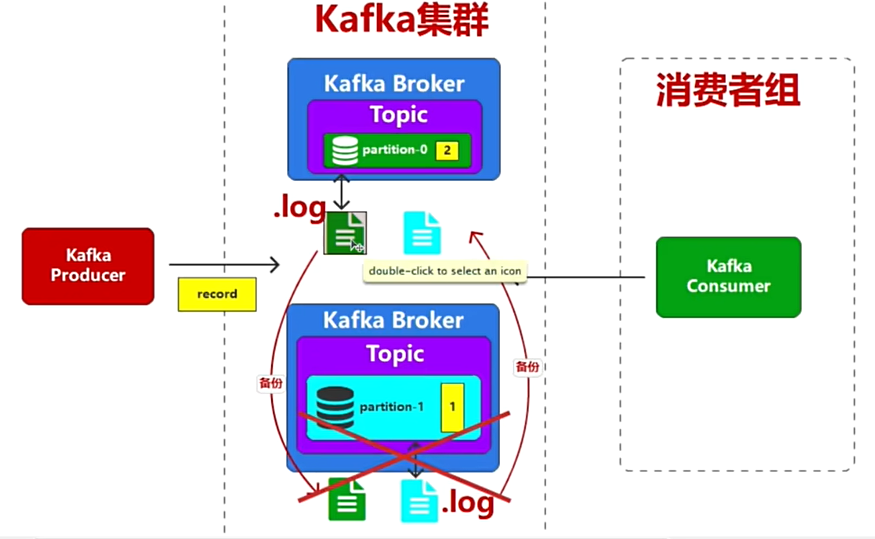
为了数据的可靠性,可以将数据文件进行备份,但是在kafka中没有备份的概念,在kafka中称之为副本
在kafka中多个副本只能由一个副本进行读写操作,其他副本只能做备份操作
具有读写的副本称为:leader副本
具有备份的副本称为:foolower副本
基础组件图形推演
为了防止某个服务节点因为某种原因导致down掉-但实际并没有down掉,为了监控集群各个节点的运行情况提高集群服务的可用性,会在集群中找一个节点做集群的管理者
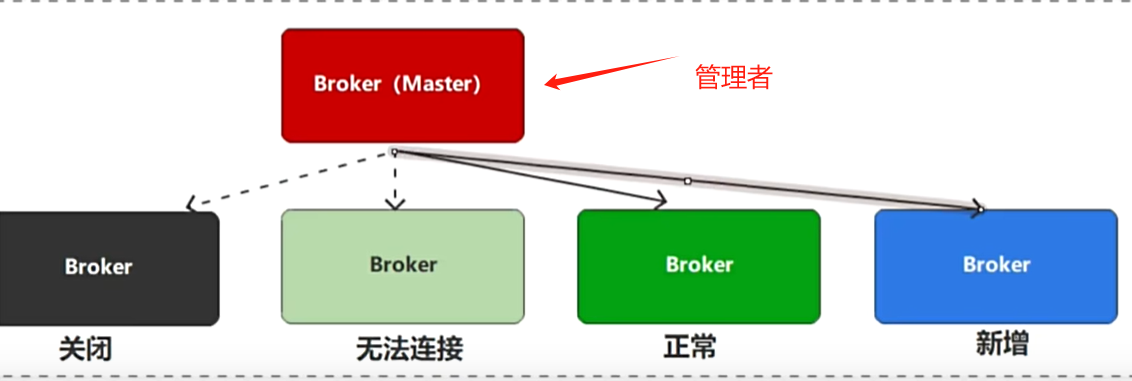
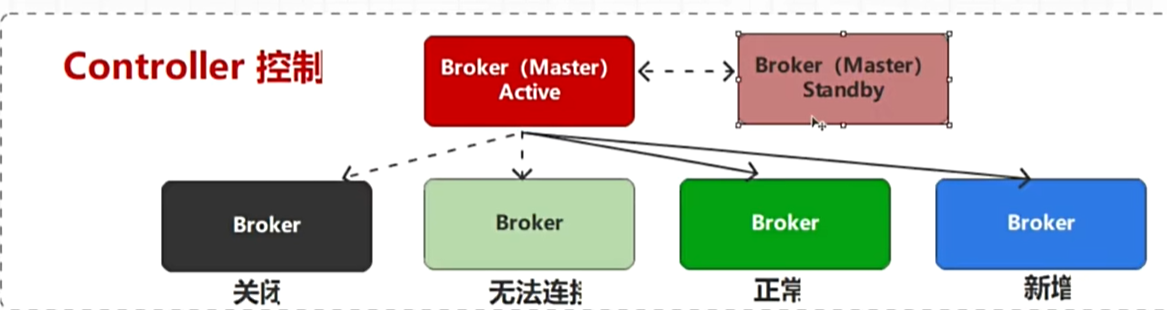
但是此时又有一个问题,当一个管理者出现问题,此时他下边的所有Broker都有问题这时,如何破局
- 给管理者增加备份(存在问题-两个都down掉)
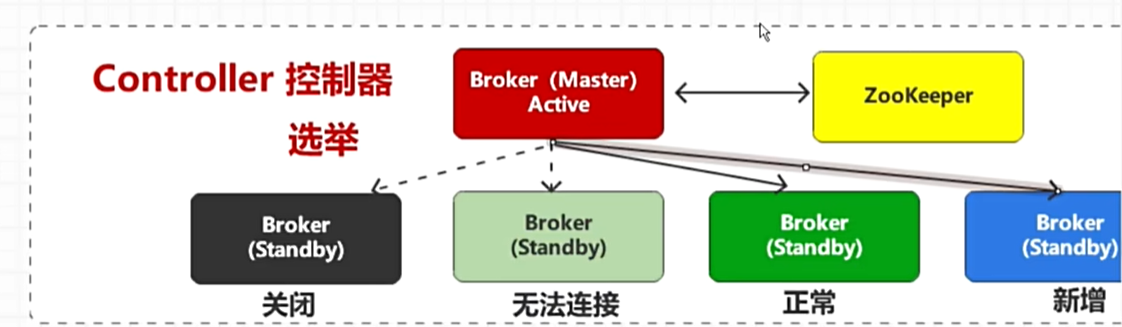
- 任何一个节点都可以做备份(存在问题--备份太多了,那个做管理者(ZppKeeper选举插件))

















 2266
2266

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









