








目录
1.二叉树的顺序结构及实现
1.1 二叉树的顺序结构
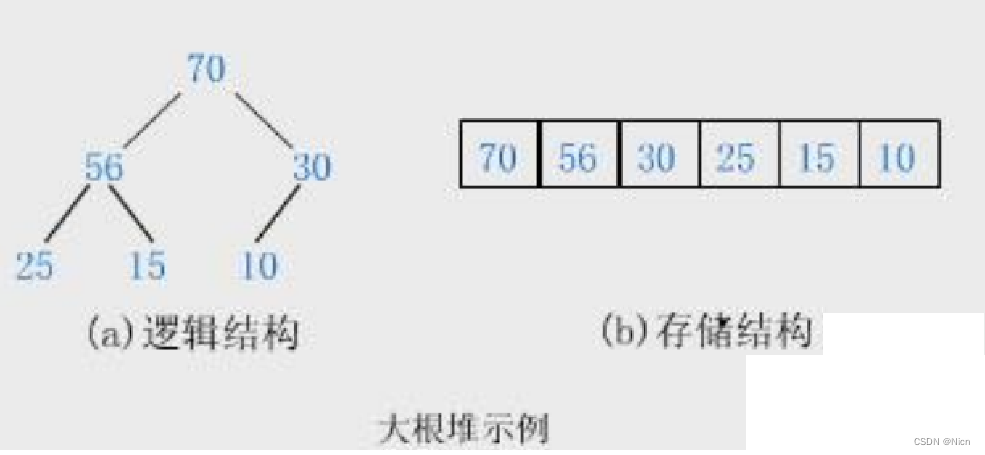
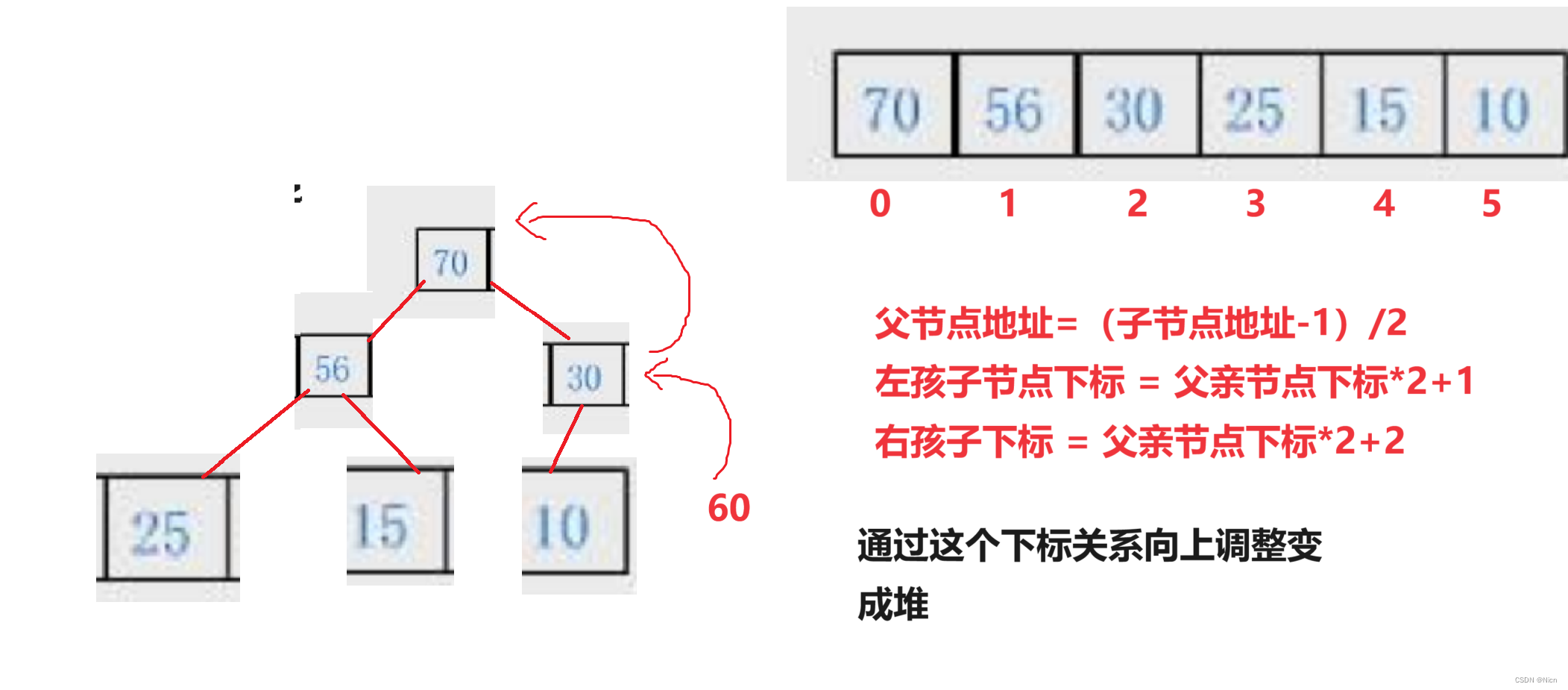
普通的二叉树是不适合用数组来存储的,因为可能会存在大量的空间浪费。而完全二叉树更适合使用顺序结 构存储。现实中我们通常把堆(一种二叉树)使用顺序结构的数组来存储,需要注意的是这里的堆和操作系统 虚拟进程地址空间中的堆是两回事,一个是数据结构,一个是操作系统中管理内存的一块区域分段。

左孩子的下标 = 父亲下标*2+1
右孩子下标 = 父亲节点下标*2+2
父亲节点下标 = (子节点下标-1)/2
2 堆的概念及结构
堆是非线性结构,是完全二叉树
如果有一个值的集合K = { , , ,…, },把它的所有元素按完全二叉树的顺序存储方式存储 在一个一维数组中,并满足: = 且 >= ) i = 0,1, 2…,则称为小堆(或大堆)。将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。 堆的性质: 堆中某个节点的值总是不大于或不小于其父节点的值;
堆总是一棵完全二叉树。
通俗来说父节点小于等于子节点的完全二叉树就叫小根堆,或者小堆,根一定是整棵树最小的。

父节点值大于等于子节点的完全二叉树叫做大根堆。或者大堆,但是底层数组不一定降序。但是大堆的根是整棵树的最大值。
3 堆的实现
3.1堆的代码定义
底层是一个顺序表
typedef int HPDataType;
typedef struct Heap
{
//底层是一个顺序表,但是数据不是随便存储,逻辑结构是二叉树
HPDataType * a;
int size;
int capacity;
}HP;堆的初始化:
void HeapInit(HP* php)
{
assert(php);
HPDataType* tmp = (HPDataType*)malloc(sizeof(HPDataType) * 2);//先为i堆空间申请两个节点
if (tmp == NULL)
{
perror("malloc");
exit(-1);
}
php->a = tmp;
php->capacity = 2;
php->size = 0;
}3.2堆插入数据
实现关键

实现原理图:向上调整:
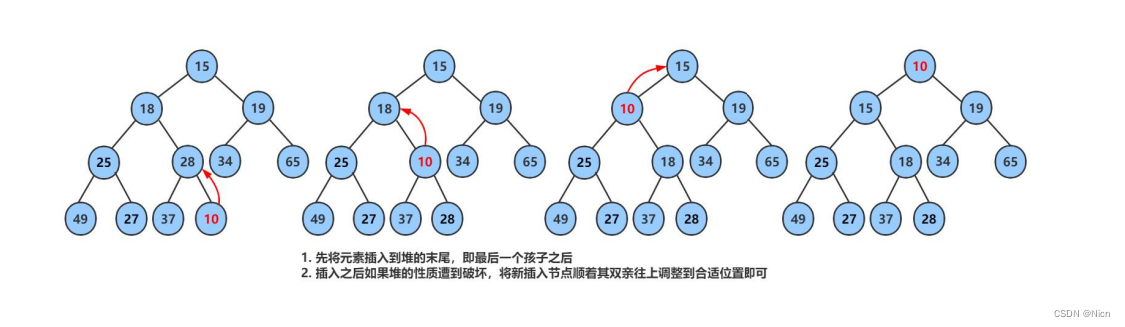
(以大堆的实现方式举例)
首先我们从有限个数据的层面来实现一下堆的实现,后面堆排序再来看对于一堆数据怎么建堆。
对于一组少量数据比如一个数组:
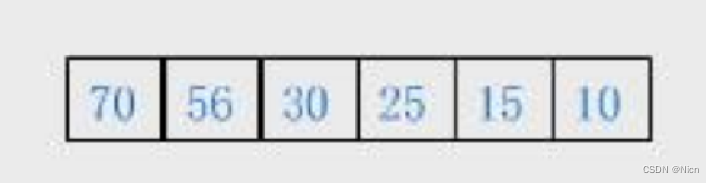
首先将数据一个一个插入到堆里面,由于数据有限可以使用这种数据插入的方式建立堆这种数据结构;
void HeapPush(HP* php, HPDataType x)
{
//尾插
assert(php);
//判断空间够不够
if (php->capacity == php->size)
{
HPDataType* tmp = (HPDataType*)realloc(php->a, sizeof(php->a) + sizeof(HPDataType) * 2);
if (tmp == NULL)
{
perror("realloc");
exit(-1);
}
php->a = tmp;
php->capacity += 2;
}
php->a[php->size] = x;
php->size++;
//调整数据,变成堆
AdjustUp(php->a, php->size-1);
}然后把这组数据调整成一个堆:
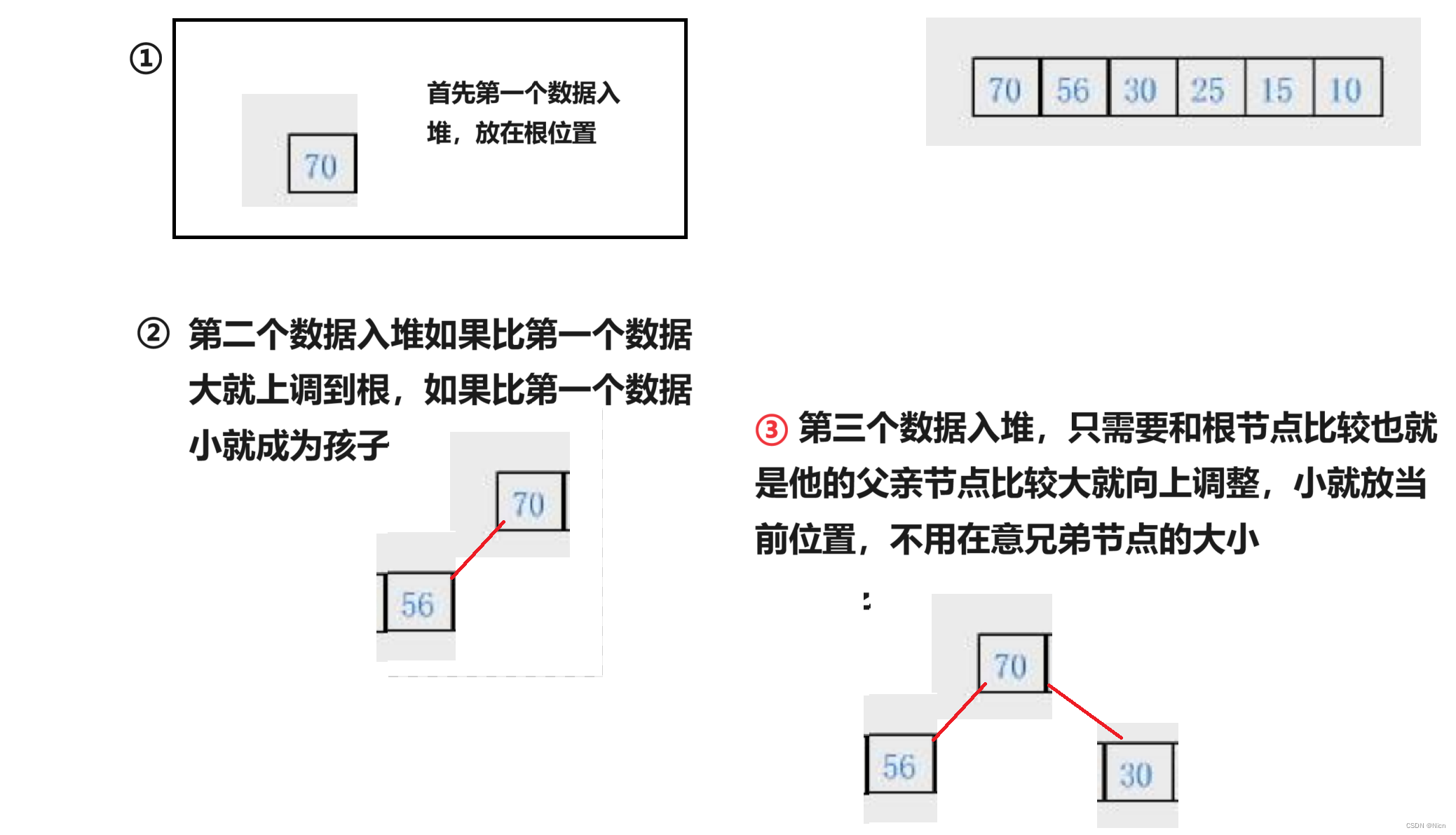
void Swap(HPDataType* child, HPDataType* parent)
{
HPDataType tmp = 0;
tmp = *child;
*child = *parent;
*parent = tmp;
}
void AdjustUp(HPDataType* a,int child)//向上调整
{
//最坏调整到根
int parent = (child - 1) / 2;
while (child>0)//注意这个判断条件
{
if (a[child] > a[parent])
{
//交换
Swap(&a[child], &a[parent]);
//继续往上深入判断,将父亲的下标给孩子,父亲的父亲的下标给父亲
child = parent;
parent = (parent - 1) / 2;
}
else
{
break;//跳出循环
}
}
}
3.3打印堆数据
为了看一下我们插入的效果我们来试一下插入一段数据
void HeapPrint(HP* php)
{
assert(php);
for (int i = 0; i < php->size; i++)
{
printf("%d ", php->a[i]);
}
} 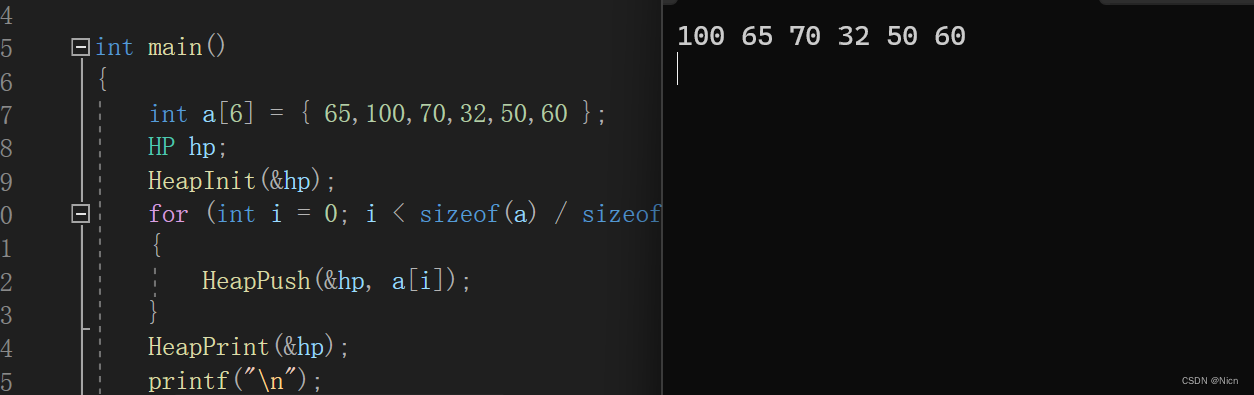
 就建成了一个大堆。
就建成了一个大堆。
3.4堆的数据的删除
堆这个数据结构有意义的一个点就是,大堆的根一定是这组数据中最大的值,小堆的根一定是这组数据中最小的值。所以如果我们能拿到这个根的数据,再删除就可以找到这堆数据中次小的数据了。那么删除根数据是这个结构比较有意义的。
想一个问题:根的删除能不能简单的数据覆盖?只是将后续的数据移动向前
答案是不能的,可以数据这样移动后续数据根本就不能成堆了。那么这里使用的方法是向下调整法
前提是左右子树是堆:
这里我们以小堆举例示范:
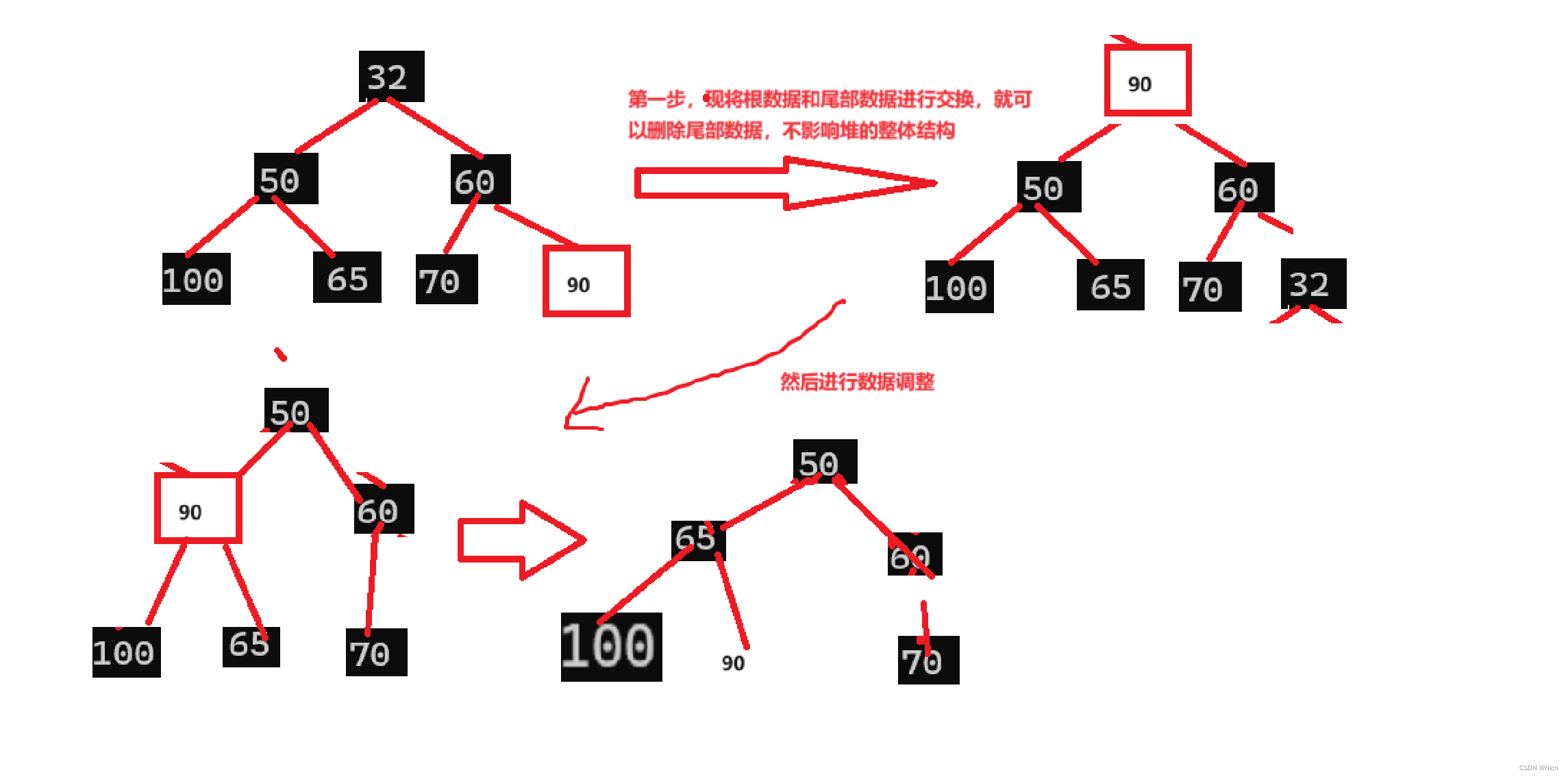
先删除
void HeapPop(HP* php)
{
assert(php);
//不可挪动覆盖。可能就不是堆了
//先交换根和最后一个值,再删除,左右子树依旧是小堆
//向下调整的算法,左右子树都是小堆或者大堆。
assert(php->size > 0);
Swap(&php->a[0],&php->a[php->size-1]);
php->size--;//删除了数据
AdjustDown(php->a,php->size, 0);
}
在调整
void AdjustDown(HPDataType* a, int n, int parent)
{
int child = parent * 2 + 1;
while (child<n)
{
if (child+1<n&&a[child + 1] < a[child])//child+1可能越界访问
{
child++;
}
if (a[child] < a[parent])
{
Swap(&a[child], &a[parent]);
//继续向下调整
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}调整是由于每次都是取两个子节点中的较小的值,所以先假设一个大,如果假设错了,就改变下标
if (child+1<n&&a[child + 1] < a[child])//child+1可能越界访问
{
child++;
}对调整循环结束的判定所示孩子下标小于n
3.5获取根部数据
//获取根部数据
HPDataType HeapTop(HP* php)
{
assert(php);
assert(php->size > 0);
return php->a[0];
}
3.6判断堆是否为空
//判断堆是否为空函数
bool HeapEmpty(HP* php)
{
assert(php);
return php->size == 0;
}3.7 堆的销毁
void HeapDestory(HP* php)
{
assert(php);
free(php->a);
php->a = NULL;
php->size = php->capacity = 0;
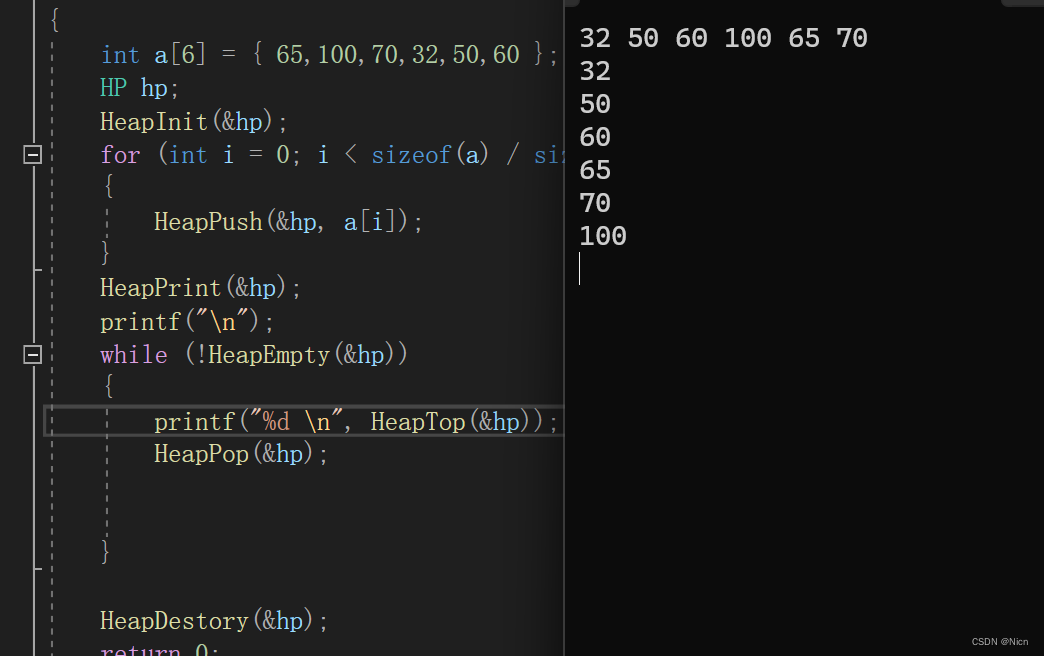
}那么如果现在我们每次拿到堆的元素在删除在获取,就可以得到一个有序的数据了:
4.建堆以及堆排序
上面我们已经掌握了堆这个数据结构的一些方法,最后通过插入数据建堆。删除数据将数据排序。可是如果我有十亿个数据,想找出最大的十个数据,如果用堆得插入10亿次数据吗?那就失去了使用这个数据结构的意义,通常来说我们只用建立一个大堆模型,这个堆的前十个数据自然就是10亿个数据中的最大的一个。
4.1堆排序---是一种选择排序
使用堆结构对一组数据进行排序,方便对数据进行处理。粗暴办法就是将原数组数据插入堆,再取堆数据覆盖,这种方法首先得有堆结构,其次插入数据就要额外开辟空间。
最好的方式就是直接将原数组或者原来的这组数据变成堆。将原数组直接看成一颗完全二叉树,一般都不是堆。那么就要将原数据之间调成堆----建堆
建堆不是插入数据,只是使用向上调整的思想。在原有数据上进行更改,调换
int a[] = { 2,3,5,7,4,6,8,65,100,70,32,50,60 };
HeapSort(a, sizeof(a) / sizeof(a[0]));
void HeapSort(int* a, int n)
{
for (int i = 0; i < n; i++)
{
AdjustUp(a, 1);
}
}
void AdjustUp(HPDataType* a,int child)//向上调整
{
//最坏调整到根
int parent = (child - 1) / 2;
while (child>0)//注意这个判断条件
{
if (a[child] < a[parent])
{
//交换
Swap(&a[child], &a[parent]);
//继续往上深入判断,将父亲的下标给孩子,父亲的父亲的下标给父亲
child = parent;
parent = (parent - 1) / 2;
}
else
{
break;//跳出循环
}
}
}4.2升序建大堆,降序建小堆
一般我们要利用堆结构将一组数据排成升序,就建立大堆
要利用堆结构将一组数据排成降序,就建立小堆。
排序和删除的原理是一样的,先找最大/最小然后次大/次小,每次选取数据后不会将后面数据覆盖上来,否则就会导致关系全乱,可能次大数据就要重新建堆,增加了工作量了。而是通过堆顶元素和最后一个数据交换位置过后,向下调整思想,将排除刚刚调整的尾部最大数据除外的剩下数据看成堆,循环排序。
最后发现:大堆这样处理的数据最大的数据在最后,最小的在最前,小堆相反。
void HeapSort(int* a, int n)
{
//对数据进行建堆
for (int i = 0; i < n; i++)
{
AdjustUp(a, 1);
}
//堆排序---向下调整的思想
int end = n - 1;
while (end > 0)
{
Swap(&a[0], &a[end]);
AdjustDown(a, end, 0);
--end;//让n-1个数据调整成堆选出次小
}
}4.3 建堆的时间复杂度
4.3.1向下调整建堆
讨论最坏的时间复杂度
将下图进行建立一个大堆
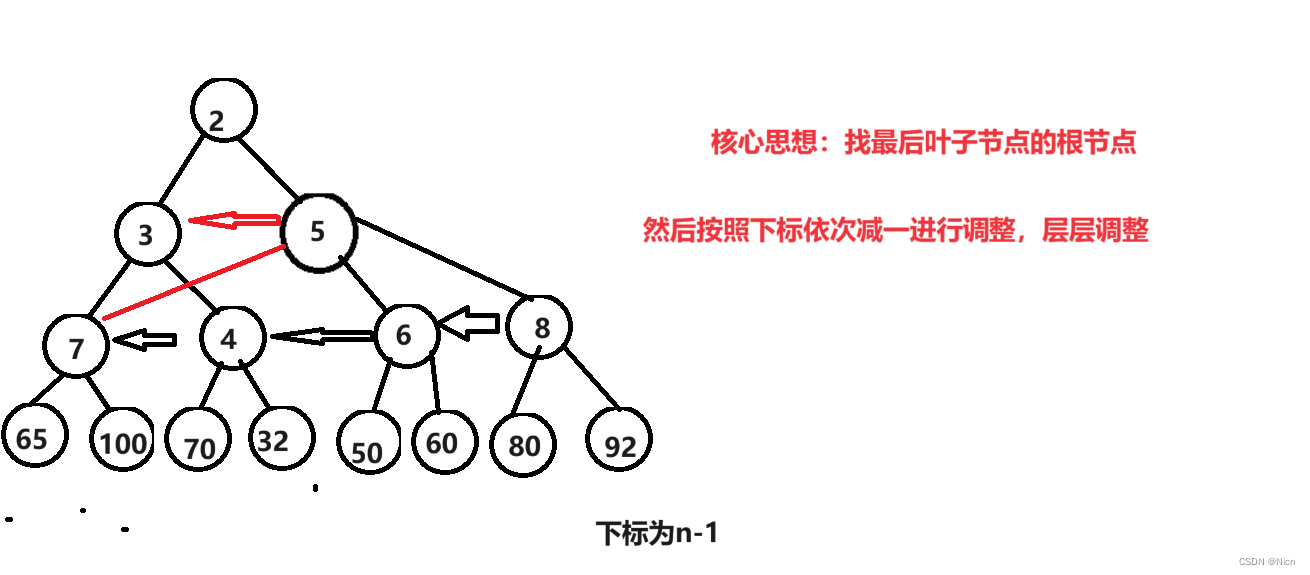
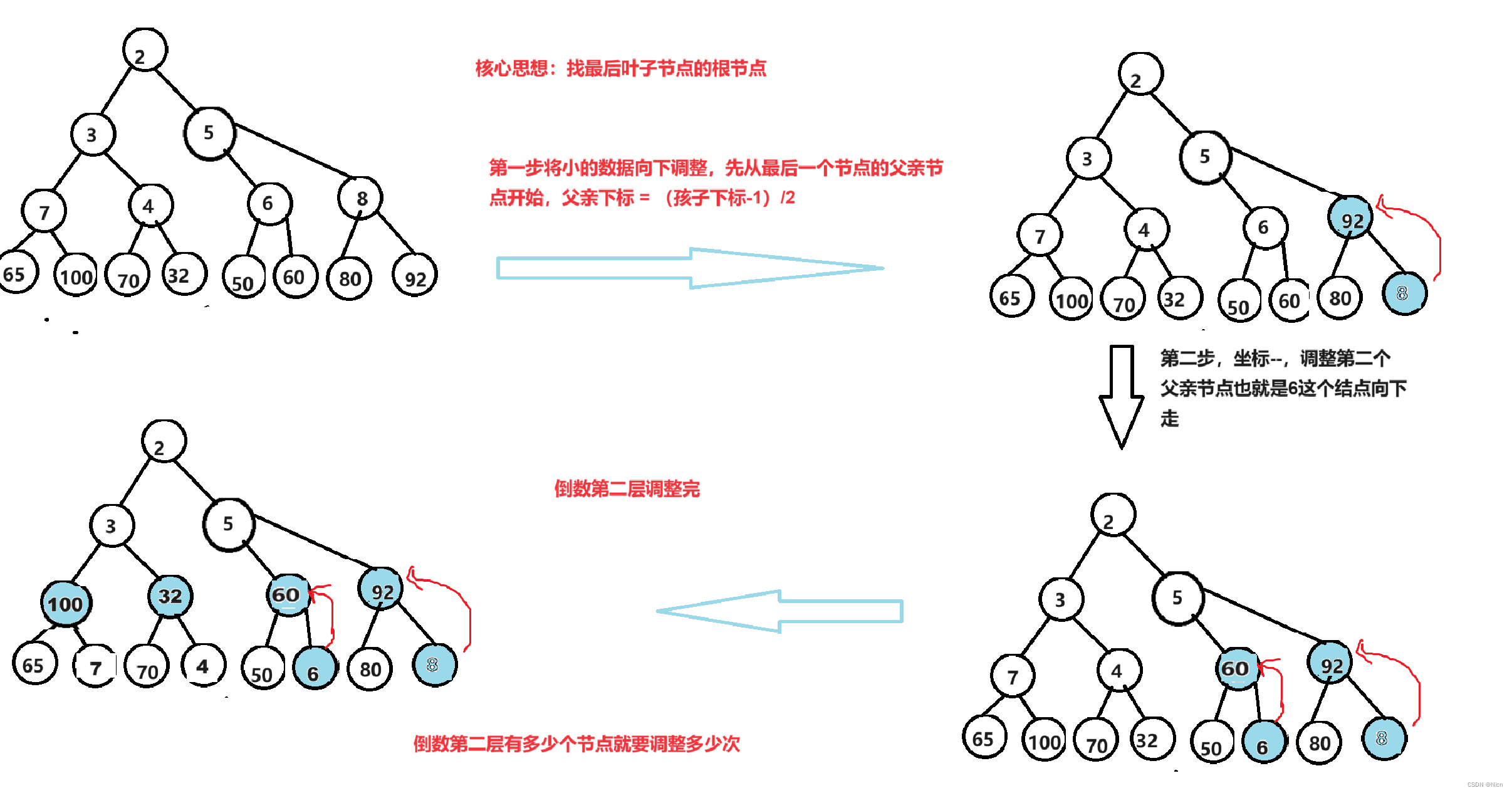
假设有h层,这里测算的时间复杂度是最坏的情况,那么就相当于调整的是一个满二叉树的堆。
第h层 ,共有2^(h-1)个节点, 需要调整0次
第h-1层,共有2^(h-2)个节点 ,每个节点调整一次,调整:2^(h-2)*1次
第h-2层,共有2^(h-3)个节点,每个节点最坏向下调整两次,调整2^(h-3)*2次
:
:
:
第3层,共有2^(2)个节点,每个节点向下调整h-3次,调整2^(2)*(h-3)次
第2层,共有2^(1)个节点,每个节点向下调整h-2次,调整2^(1)*(h-2)次
第1层,共有2^(0)个节点,每个节点向下调整h-1次,调整2^(0)*(h-1)次
时间复杂度为:
T(h) = 2^(0)*(h-1)+2^(1)*(h-2)+2^(2)*(h-3)+…………2^(h-3)*2+2^(h-2)*1①
2T(h) = 2^(1)*(h-1)+2^(2)*(h-2)+2^(3)*(h-3)+…………2^(h-2)*2+2^(h-1)*1
②
②-①得
T(h) = 2^(1)+2^(2)……+2^(h-2)+2^(h-1)+1-h
=2^0+2^(1)+2^(2)……+2^(h-2)+2^(h-1)-h
=2^h-1-h
由于h是树的层高,与节点个数的关系是:N = 2^h-1
h = log(n+1)
所以时间复杂度为:
O(N) = N-longN+1~O(N)
4.3.2向上调整建堆

假设有h层,这里测算的时间复杂度是最坏的情况,那么就相当于调整的是一个满二叉树的堆。
第2层,共有2^1个节点,每个节点向上调整1次
第3层,共有2^2个节点,每个节点向上调整2次
:
:
:
第h-2层,共有2^(h-3)个节点,每个节点向上调整h-3次
第h-1层,共有2^(h-2)个节点,每个节点向上调整h-2次
第h层 ,共有2^(h-1)个节点,每个节点向上调整h-1次
时间复杂度为:T(h) = 2^1*1+2^2*2+2^3*3……2^(h-3)*(h-3)+2^(h-2)*(h-2)+2^(h-1)*(h-1)
2 T(h) = 2^2*1+2^3*2+2^4*3……2^(h-2)*(h-3)+2^(h-1)*(h-2)+2^(h)*(h-1)
T(h) = -2-(2^2+2^3+2^4…………2^(h-1))+2^h(h-1)
= -(2^0+2^1+2^2…………2^(h-1))+2^h(h-1)+2^0
=2^h*(h-2)+2
由于h是树的层高,与节点个数的关系是:N = 2^h-1
h = log(n+1)
T(N) = (N+1)log(N+1)-2N-1
4.4 topk问题
TOP-K问题:即求数据结合中前K个最大的元素或者最小的元素,一般情况下数据量都比较大。
比如:专业前10名、世界500强、富豪榜、游戏中前100的活跃玩家等。 对于Top-K问题,能想到的最简单直接的方式就是排序,但是:如果数据量非常大,排序就不太可取了(可能 数据都不能一下子全部加载到内存中)。最佳的方式就是用堆来解决,
基本思路如下:
1. 用数据集合中前K个元素来建堆 前k个最大的元素,则建小堆 ;找前k个最小的元素,则建大堆
2. 用剩余的N-K个元素依次与堆顶元素来比较,不满足则替换堆顶元素将剩余N-K个元素依次与堆顶元素比完之后,堆中剩余的K个元素就是所求的前K个最小或者最大的元素。
比如现在我们的磁盘中有十亿个数据,我们要在十亿数据中找到前100个最大的数
第一步:读取文件的前100个数据,在内存中建立一个小堆
第二步:再依次读取剩余数据与堆顶部元素进行比较,大于堆顶就替换进堆,向下调整,所有数据读完,堆里面就是最大的100个。
首先堆顶元素就是这100个数据中最小的,如果比这个堆顶数据小的肯定不是要找的前100个最大数中的一个,如果比堆顶元素大进替换堆顶元素进堆,向下调整后找到这100个数据中次二小的,最后遍历完就得到这100个最大的数据。堆顶元素就是第100大数据,如果建立大堆一轮遍历只能找到一个最大的值,就没有必要建堆了。
向上建堆的方式的时间复杂度:K*logK+(N-K)*logk=N*logk
空间复杂度为logK
先向磁盘中写入1万个数据
void CreateNDate()
{
int n = 10000;
srand(time(0));
const char* file = "data.txt";
FILE* fin = fopen(file, "w");
if (fin == NULL)
{
perror("fopen error");
return;
}
for (int i = 0; i < n; i++)
{
int x = rand() % 1000000;
fprintf(fin, "%d\n", x);
}
fclose(fin);
}
将前k个数据从磁盘中读入内存,
// 1. 建堆--用a中前k个元素建堆
//首先读文件
FILE* fout = fopen(filename, "r");
if (fout == NULL)
{
perror("fopen");
return;
}
int* minhead = (int*)malloc(sizeof(int) * k);
if (minhead == NULL)
{
perror("malloc fail");
return;
}
for (int i = 0; i < k; i++)
{
fscanf(fout, "%d", &minhead[i]);
}利用向下调整的方式建堆,并且与磁盘中的元素进行一一比较
//建堆,也可以向上插入建堆
for (int i = (k - 2) / 2; i >= 0; i--)
{
AdjustDown(minhead, k ,i);
}
// 2. 将剩余n-k个元素依次与堆顶元素交换,不满则则替换
int x = 0;
while (fscanf(fout, "%d", &x) != EOF)
{
if (x > minhead[0])
{
minhead[0] = x;//替换进堆
AdjustDown(minhead, k, 0);
}
}
//打印一下前100个最大的数据
for (int i = 0; i < k; i++)
{
printf("%d ", minhead[i]);
}
printf("\n");
fclose(fout);然后手动修改十个·最大的值在磁盘里检测结果:


在初始堆的时候就可以直接为这段数据开辟固定空间,然后初始化堆的时候就可以直接建堆;
void HeapInitArray(HP* php, int* a, int n)
{
assert(php);
assert(a);
php->a = (HPDataType*)malloc(sizeof(HPDataType) * n);//之间开辟好对应数据大小的空间
if (php->a == NULL)
{
perror("malloc fail");
exit(-1);
}
php->size = n;
php->capacity = n;
memcpy(php->a, a, sizeof(HPDataType) * n);//将数据拷贝到空间中
for (int i = 1; i < n; i++)
{
AdjustUp(php->a, i);//向上调整成堆
}
}5.结语
以上就是本期的所有内容,知识含量蛮多,大家可以配合解释和原码运行理解。创作不易,大家如果觉得还可以的话,欢迎大家三连,有问题的地方欢迎大家指正,一起交流学习,一起成长,我是Nicn,正在c++方向前行的奋斗者,数据结构内容持续更新中,感谢大家的关注与喜欢。














 1679
1679











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









