







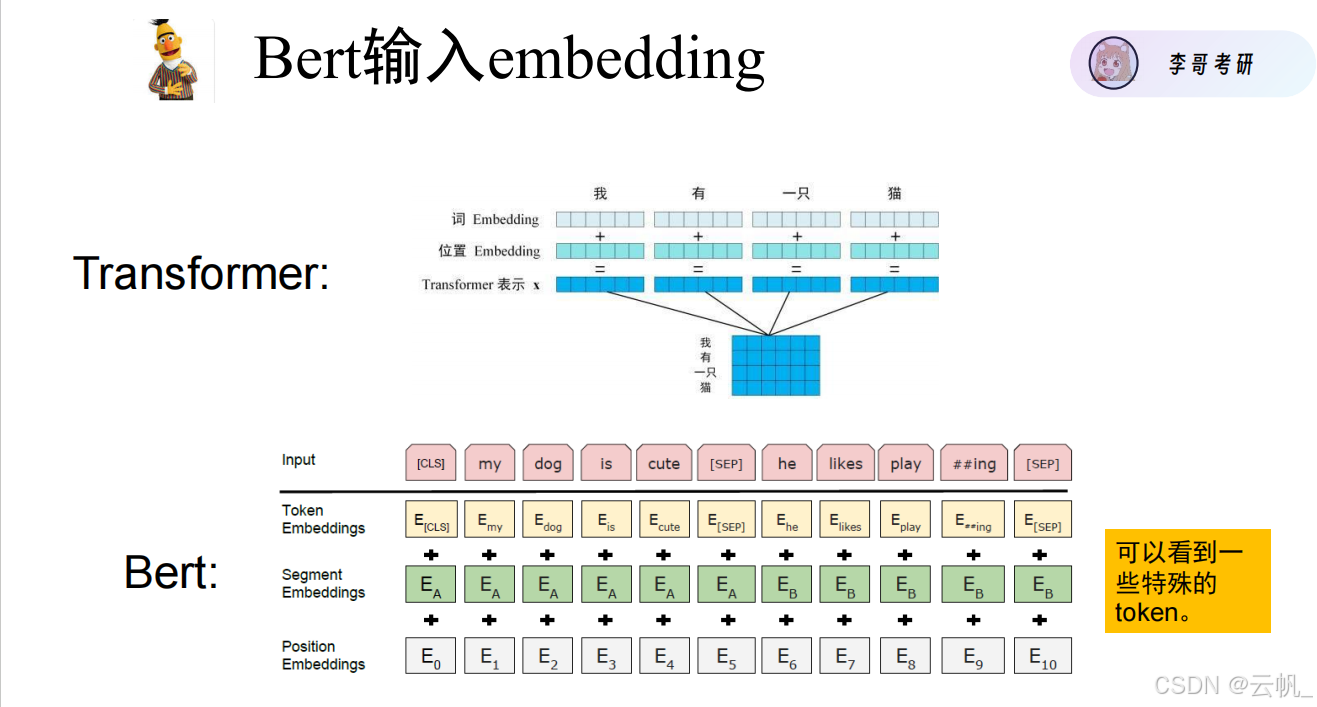
输入长度要保持一致:所以需要分词

其中:Mask用来控制输入的长度。
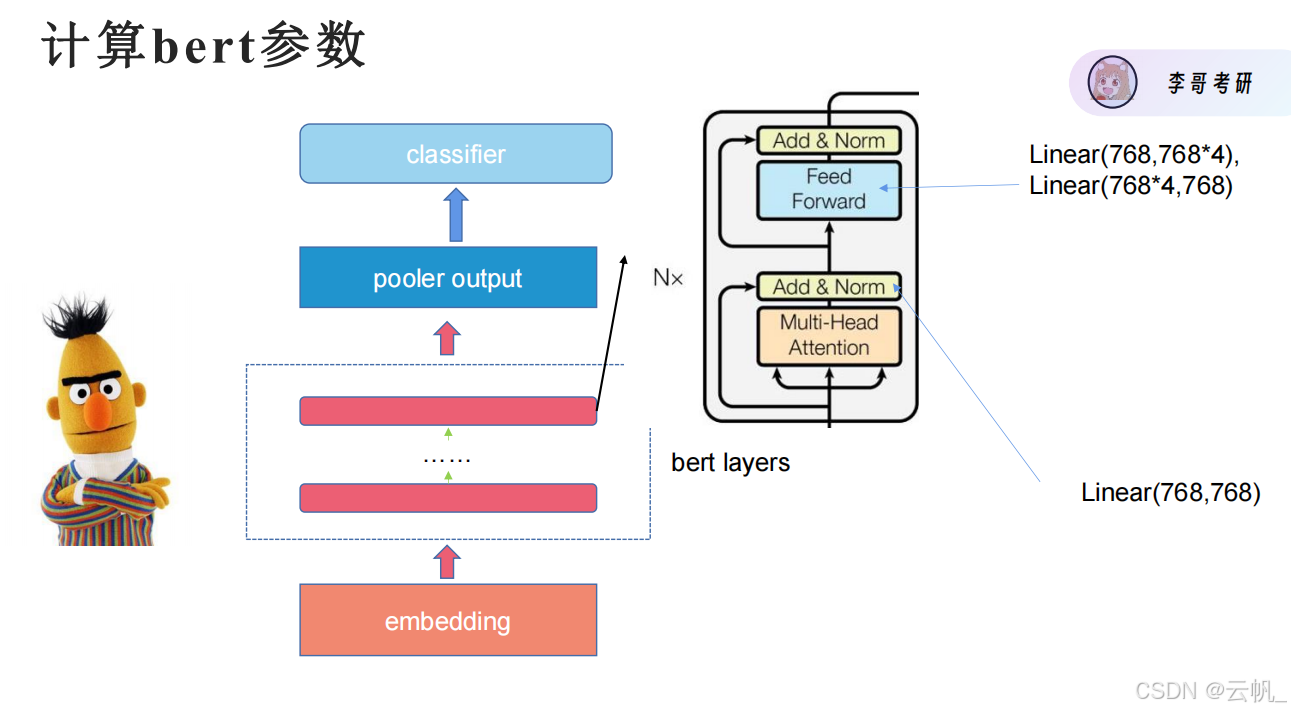
BERT 模型的参数数量取决于其架构设计(如层数、隐藏层大小、注意力头数等)。以下是计算 BERT 参数数量的详细方法,以及如何通过代码查看 BERT 模型的参数。
(注:vocab_size,
hidden_size等均在bert-base-chinese 的config.json文件中定义)
1. BERT 参数组成
BERT 的参数主要来自以下几个部分:
(1) Embedding 层
Token Embeddings:
词表大小(
vocab_size) × 隐藏层大小(hidden_size)。例如,
bert-base-chinese的词表大小为 21128,隐藏层大小为 768,因此参数数量为:21128×768=16,248,06421128×768=16,248,064
Position Embeddings:
最大序列长度(
max_position_embeddings) × 隐藏层大小(hidden_size)。例如,
bert-base-chinese的最大序列长度为 512,因此参数数量为:512×768=393,216512×768=393,216
Segment Embeddings:
2(句子 A 和句子 B) × 隐藏层大小(
hidden_size)。例如,
bert-base-chinese的参数数量为:2×768=1,5362×768=1,536
Embedding 层总计:
16,248,064+393,216+1,536=16,642,81616,248,064+393,216+1,536=16,642,816
(2) Transformer 编码器层
每一层 Transformer 编码器包含以下参数:
1. 多头自注意力机制(Multi-Head Self-Attention)
Query、Key、Value 的线性变换:
每个头的参数数量:
hidden_size×head_size。总参数数量:
3 × hidden_size × hidden_size。例如,
bert-base-chinese的隐藏层大小为 768,因此参数数量为:3×768×768=1,769,4723×768×768=1,769,472
输出线性变换:
参数数量:
hidden_size × hidden_size。例如,
bert-base-chinese的参数数量为:768×768=589,824768×768=589,824
2. 前馈神经网络(Feed-Forward Network, FFN)
第一层:
参数数量:
hidden_size × intermediate_size。例如,
bert-base-chinese的intermediate_size为 3072,因此参数数量为:768×3072=2,359,296768×3072=2,359,296
第二层:
参数数量:
intermediate_size × hidden_size。例如,
bert-base-chinese的参数数量为:3072×768=2,359,2963072×768=2,359,296
3. 层归一化(Layer Normalization)
每层有两个 Layer Normalization(自注意力层和 FFN 层各一个)。
每个 Layer Normalization 的参数数量:
2 × hidden_size。例如,
bert-base-chinese的参数数量为:2×2×768=3,0722×2×768=3,072
4. 每层 Transformer 编码器总计
1,769,472+589,824+2,359,296+2,359,296+3,072=7,080,9601,769,472+589,824+2,359,296+2,359,296+3,072=7,080,960
5. 所有 Transformer 编码器层总计
bert-base-chinese有 12 层 Transformer 编码器,因此参数数量为:12×7,080,960=84,971,52012×7,080,960=84,971,520
(3) Pooler 层
参数数量:
hidden_size × hidden_size。例如,
bert-base-chinese的参数数量为:768×768=589,824768×768=589,824
2. BERT 总参数数量
将以上各部分相加,
bert-base-chinese的总参数数量为:16,642,816 (Embedding)+84,971,520 (Transformer)+589,824 (Pooler)=102,204,16016,642,816 (Embedding)+84,971,520 (Transformer)+589,824 (Pooler)=102,204,160
代码:
from transformers import BertModel, BertTokenizer
bert = BertModel.from_pretrained("bert-base-chinese")
def get_parameter_number(model):
# 计算模型中所有参数的总数
total_num = sum(p.numel() for p in model.parameters())
# 计算模型中可训练参数的数量
trainable_num = sum(p.numel() for p in model.parameters() if p.requires_grad)
# 返回一个字典,包含总参数数量和可训练参数数量
return {'Total': total_num, 'Trainable': trainable_num}
print(get_parameter_number(bert))
emb_num = 21128 * 768 + 2 * 768 + 512 * 768 # embedding层的参数,忽略了bias
self_att_num = 768 * 768 * 3 + 768 * 768 + 768 * 3072 + 3072 * 768
all_att_num = 12 * self_att_num
pool_num = 768 * 768
print(emb_num + all_att_num + pool_num)
# for name, para in bert.named_parameters():
# print(name, para.shape)
下面代码的主要功能是使用 transformers 库中的 BertTokenizer 对中文文本进行分词和编码处理。
步骤如下:
- 加载分词器:使用
BertTokenizer.from_pretrained("bert-base-chinese")从预训练的bert-base-chinese模型中加载对应的分词器。- 定义输入文本:定义一个中文句子
"我爱你"作为输入。- 对输入文本进行编码:调用分词器的
__call__方法(通过tokenizer(input, ...)调用)对输入文本进行编码,设置truncation=True表示如果输入文本长度超过max_length则进行截断,padding="max_length"表示将输入填充到max_length指定的长度,max_length=128表示最大长度为 128。- 打印编码结果:打印编码后的结果。
from transformers import BertModel, BertTokenizer
tokenizer=BertTokenizer.from_pretrained("bert-base-chinese")
input="我爱你"
out=tokenizer(input,truncation=True,padding="max_length",max_length=128)
print(out)输出为:
{
'input_ids': [101, 2769, 4263, 872, 102, 0, 0, 0, 0, 0, ..., 0],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ..., 0],
'attention_mask': [1, 1, 1, 1, 1, 0, 0, 0, 0, 0, ..., 0]
}
input_ids:
101是 [CLS] 标记的索引,它通常位于输入序列的开头,用于分类任务。2769、4263、872分别是 “我”、“爱”、“你” 这三个汉字在词汇表中的索引。102是 [SEP] 标记的索引,用于分隔不同的句子(这里虽然只有一个句子,但 BERT 模型仍需要这个标记)。- 后面的 0 是填充值,因为输入文本长度不足 128,所以用 0 进行填充。
token_type_ids:所有值都为 0,表示这些词元都属于同一个句子。attention_mask:
- 前 5 个位置(对应 [CLS]、“我”、“爱”、“你”、[SEP])为 1,表示这些是真实的输入词元。
- 后面的位置为 0,表示这些是填充词元,在模型计算注意力时会被忽略。

















 974
974

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









