









0 前言
基于大数据个性化音乐推荐算法分析
提示:适合用于课程设计或毕业设计,工作量达标,源码开放
1 研究目的
音乐推荐算法,就是针对音乐自身的内容特征以及用户的听歌行为,为广大用户提供可能符合他们兴趣爱好的歌曲的算法。而基于大数据的个性化音乐推荐算法,能够通过历史数据,别的用户的历史数据分析出潜在的喜好相似性,为用户更准确地挖掘出潜在的喜欢的音乐。
1995年,Ringo算法的开发成就了历史上第一个推荐算法,可以向用户推荐他们喜欢的音乐并预测用户对特定音乐的评分,之后一段时间内,音乐推荐都是基于音乐曲目的基本信息产生,缺乏针对性。国外著名网站Pandora和Last.fm是最早提出音乐个性化推荐的网站。Pandora的音乐推荐算法主要来源于音乐基因工程(music gene)的项目,根据这些基因计算歌曲的相似度,给用户推荐基因相似度高的音乐。国内也涌现了一些优秀的音乐推荐网站如豆瓣电台、虾米音乐、网易云音乐等等,根据用户平时推荐给好友的歌曲,听歌行为以及歌曲收录信息,找到“相似的品味者”,更好的做出推荐。
本文针对传统基于用户或者基于物品的协同过滤推荐方法在复杂场景下对用户进行音乐推荐占用内存大计算速度慢等缺点,提出一种基于LightGBM决策树算法的音乐推荐算法,使用相关性分析和稳定性选择中的随机逻辑回归进行特征选择,采用数值特征取代个体特征进行用户对音乐的喜好预测,根据不同的候选集,可以形成不同推荐列表。采用kkbox音乐公司公布在Kaggle比赛平台上的用户、音乐、用户操作信息进行验证,预测准确率高达76%,训练时间9min,优于该比赛第一名用户算法的准确率68.4%。采用的算法模型可拓展性强,计算效率高,占用内存小,可以迁移到其它类型的推荐系统中。
2 研究方法
2.1 传统推荐算法
传统的推荐系统方法包括基于内容推荐过滤、基于规则的推荐、协同过滤推荐。
基于内容的过滤推荐根据物品的元数据,计算物品的相似性,然后基于用户的历史行为推荐给用户相似的物品;基于规则的推荐常使用于电子商务系统,大量的交易数据中获取关联规则或者按照时间购买商品的序列模型,进行物品之间的相互推荐;协同过滤包括基于用户的协同过滤和基于物品的协同过滤;基于用户的协同过滤通过分析用户历史行为,计算用户之间相似度,利用用户相似度和用户的历史行为给用户形成推荐列表。基于物品的协同过滤与之类似,分析用户行为计算物品之间的相似度,然后根据用户的历史偏好信息,将类似的物品推荐给用户。
2.2 基于LightGBM决策树模型的推荐算法
决策树算法的发展过程从C3.0(基于信息增益) CART(基于基尼系数) 提升树(AdaBoost) 梯度提升树(GDBT) XGBosot LightGBM算法。
基于决策树模型的推荐算法具有以下优点:(1)可以并行化训练;(2)能够处理离散连续特征值和类别特征,不用对特征做归一化;(3)能够处理缺失值;(4)可以处理高维特征。
LightGBM(Light Gradient Boosting Machine)是2017年8月微软公司开源的基于决策树算法的分布式梯度提升框架,和之前的提升框架相比有更快的训练效率,更低的内存使用,更高的准确率,支持并行化学习,可以处理大规模数据等优点,可以用于排序,分类和许多其他机器学习任务。
Boosting算法(提升法)指的是迭代算法,核心思想是对训练样本进行k次迭代,每次迭代形成一个弱学习器,然后根据学习误差对分类错误的样本加大训练权重,形成新的带有权重的训练集,训练形成新的弱学习器;最后将这些弱学习器根据结合策略形成一个强学习器。
此外LightGBM利用Histogram的决策树算法,先把连续的浮点特征值离散化为k个整数,构造一个宽度为k的直方图,如图2.2所示,遍历数据时,根据离散化后的值作为索引在直方图中累积统计量,然后根据直方图的离散值,遍历寻找最优的分割点。使用直方图算法因为只保存特征离散化后的值,内存消耗可以降低为原来的1/8左右;此外计算的成本也大大降低,因为预排序算法每遍历一个特征值就需要计算一次分裂的增益,而直方图算法只用计算k(k为直方的个数),时间复杂度从从O(datafeature)优化到O(kfeatures)。
和Xgboost采用level-wise策略相比,LightGBM采用更高效Leaf-wise策略(如图2.3所示),每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分类,如此循环,和Level-wise相比,分裂次数相同的情况下,可以降低更多的误差,获得更高的精度。同时LightGBM可以通过最大深度的限制防止过拟合。
并且最新的LightGBM可以自动处理缺失值,可以进一步优化类别特征(Categorical Feature),不再使用类似one-hot coding的分割方式,对于类别数量很多的类别特征采用one-vs-other的切分方式长出的不均衡的树,采用many-vs-many的切分方式,寻找最优分割。
3 研究结论
本文采用新的ligthgbm算法对用户是否会在一个月内重复收听某一首歌曲进行预测,以此作为个性化推荐的目标。通过分析数据特征,使用相关性以及稳定性选择等方法选择特征,随后通过对训练输入数值特征,分类特征和全部特征的性能比较,创新性选择用数值特征完全取代分类特征去训练模型进行预测,使得模型在有效性和准确性上都有稳定的提升,对于其余需要再分类特征上建模的实验具有参考意义。
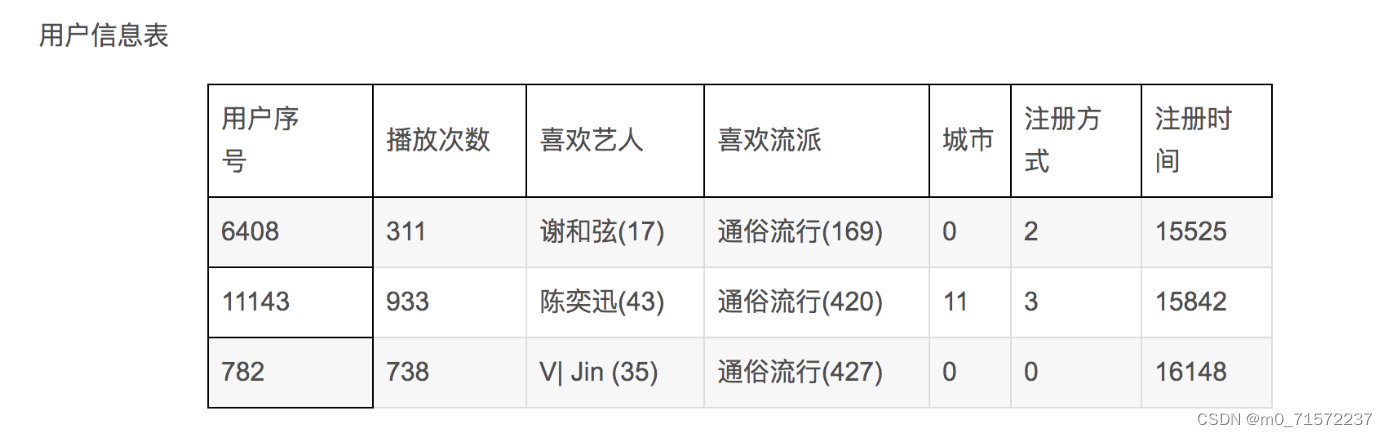
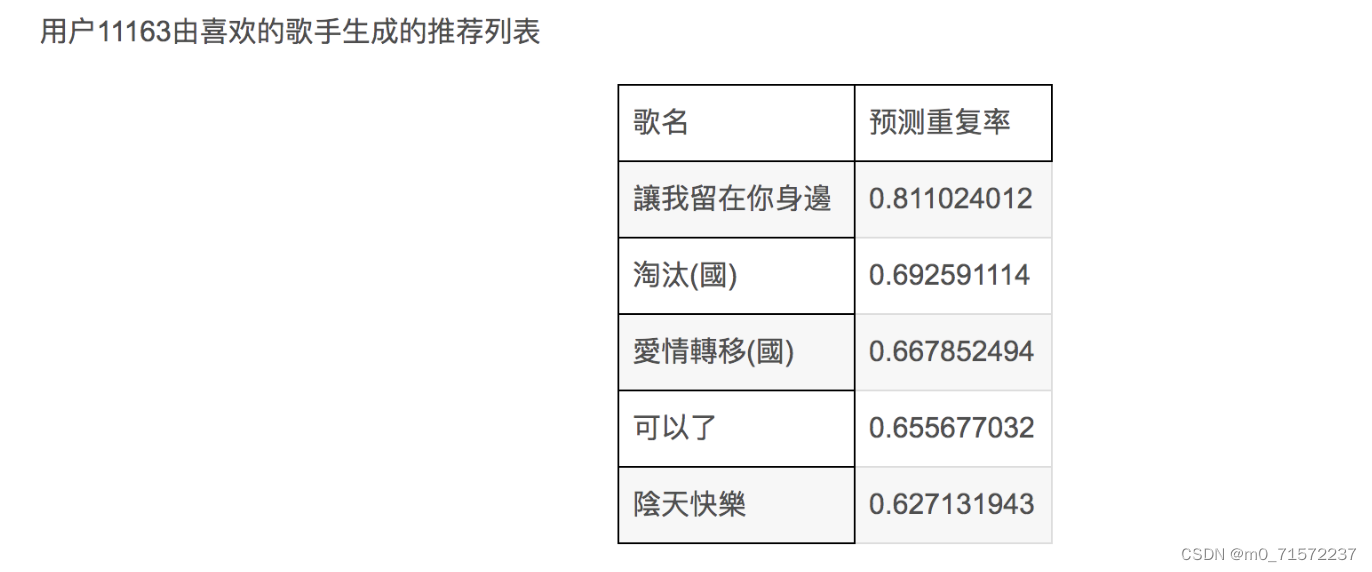
由图二可知,对于同一个用户,设置不同的候选集,可以有不同的推荐列表,支持音乐服务商使用多种推荐方式,也可以综合多个候选集,建立混合推荐的推荐列表。
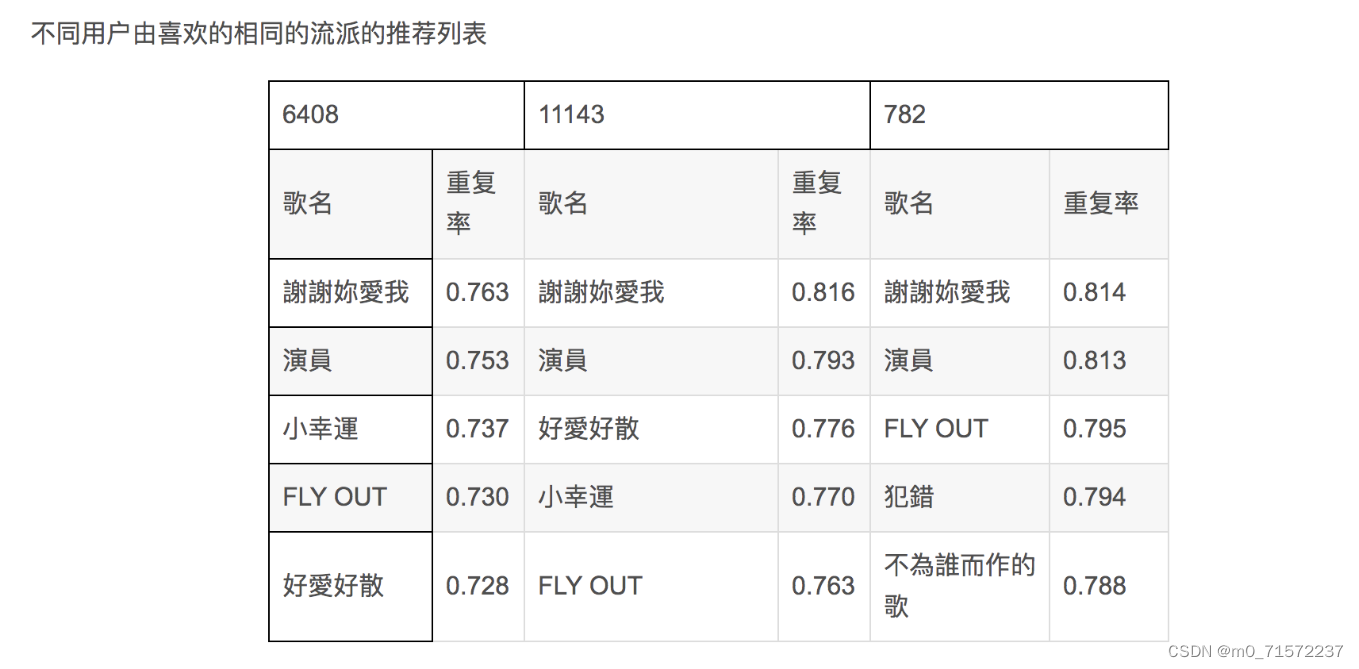
由图三可知,对于不同用户,因为其它用户特征的不同,对于相同的候选集,也可以生成不同的推荐列表,符合个性化推荐的要求。














 388
388











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









