










[ComfyUI]InvSR:低显存4K图像超分辨率!
🌹大家好!感谢大家的支持与鼓励。在AIGC探索道路上,我将与你一路同行。
InvSR简介
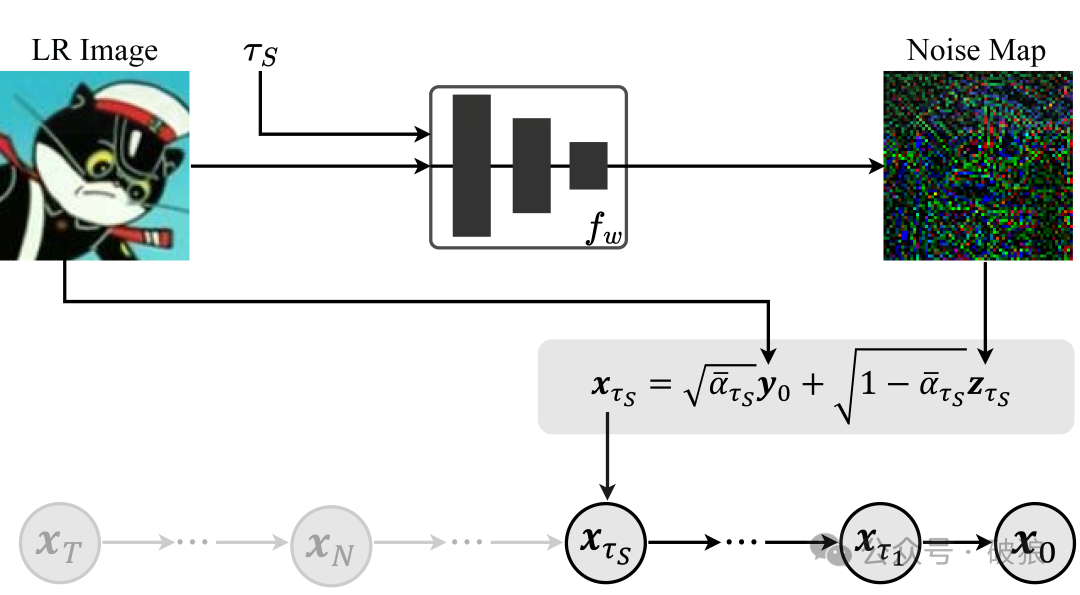
今天文章主题介绍一款基于扩散反演的新型图像超分辨率技术模型:InvSR。InvSR提出了一种基于扩散反演的新型图像超分辨率(SR)技术,旨在利用大型预训练扩散模型中丰富的图像先验知识来提升超分辨率性能。研究人员设计了一种“部分噪声预测”策略,用于构建扩散模型的中间状态,这一状态将作为起始采样点。该技术的核心是一个深度噪声预测器,用于估计正向扩散过程中的最优噪声图。一旦训练完成,这个噪声预测器可用于沿扩散轨迹部分初始化采样过程,从而生成所需的高分辨率结果。
- • Github:https://github.com/zsyOAOA/InvSR
- • 在线体验:https://huggingface.co/spaces/OAOA/InvSR
性能评估
与现有方法相比,InvSR 提供了一种灵活且高效的采样机制,支持任意数量的采样步数,从一步到五步不等。即使仅使用单个采样步骤,该模型具有先进的性能。



InvSR ComfyUI体验
当前社区已有ComfyUI插件ComfyUI_InvSR支持,可以通过ComfyUI_InvSR 的搜索安装插件。模型文末网盘获取!
- • ComfyUI_InvSR插件:https://github.com/yuvraj108c/ComfyUI_InvSR
- • Diffusers 模型:stabilityai/sd-turbo模型首次运行将自动下载到ComfyUI/models/diffusers 目录。下载地址:https://huggingface.co/stabilityai/sd-turbo/tree/main
- • InvSR 模型:noise_predictor_sd_turbo_v5.pth 模型将自动下载到ComfyUI/models/invsr 目录。下载地址:https://huggingface.co/OAOA/InvSR/blob/28e96115e767c699f2e40a85d04a8f5ebf0a685e/noise_predictor_sd_turbo_v5.pth
- • 建议使用环境:Python 3.10, Pytorch 2.4.0, xformers 0.0.27.post2

Flux文生图&混元视频工作流
最新LIBLIBAI平台已支持Flux文生图和混元视频ComfyUI工作流在线体验:
- • F.1-绮梦流光-水湄凝香:https://www.liblib.art/modelinfo/134c6dd95aef48e98a22b24e003e026b
- • 文生图-Flux文生图(PuLID|LORA|Joy|SUPIR)工作流:https://www.liblib.art/modelinfo/782aacd70f604da39e83368c696a02a8?versionUuid=9c5eceb01fb94d4d93d60fe2c0bd7468
- • 文生视频-腾迅混元最强开源视频(LORA)工作流:https://www.liblib.art/modelinfo/35ee21d5f6a94204abb767ad194ab9cd?versionUuid=be674032ffa14e5597a08922556f4da0
InvSR超分辨率ComfyUI工作流体验
InvSR超分辨率ComfyUI工作流已上传LIBLIBAI平台可体验:https://www.liblib.art/modelinfo/fcbcf0817ede4729ae8d69f4811d7856?versionUuid=bd2a344114f943e3b0b207475c428307
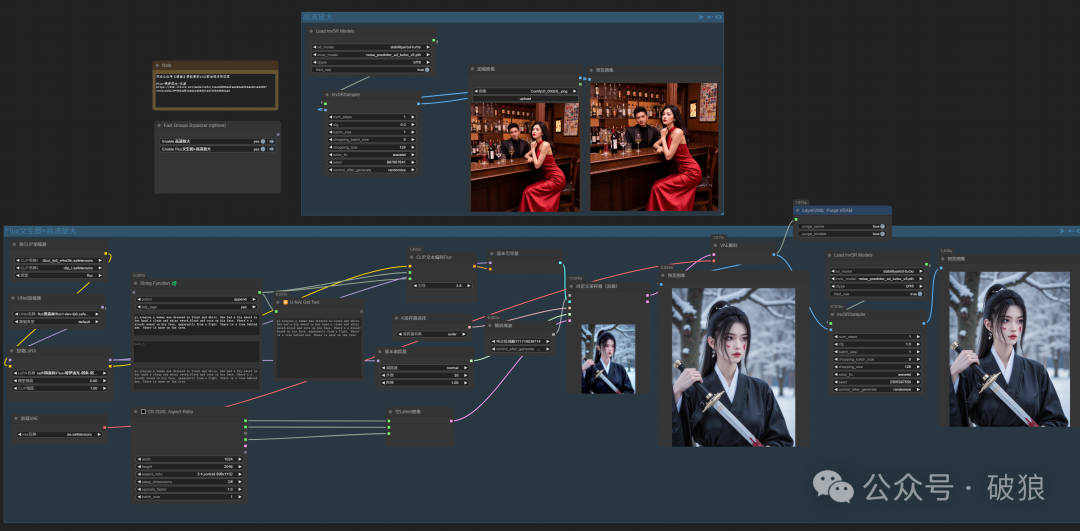
节点参数
- • chopping_size:在分割大图像时,控制图像块的大小。对于大图像如:对于大图像(例如,从 1k 到 4k),建议将 chopping_size 设置为 256。
- • chopping_batch_size:控制从同一图像中同时处理的图像块数量。如果 GPU 内存有限,建议将 chopping_batch_size 设置为 1。
- • batch_size:控制同时处理的完整图像数量。
- • color_fix:用于修复处理后图像中的色彩偏移的方法。
注意:
- • 对于大图像放大,建议参数:chopping_size 设置为 256,GPU 内存有限,建议将 chopping_batch_size 设置为 1。
- • 单图4K大约耗时仅21秒,最低仅需8G显存可运行。
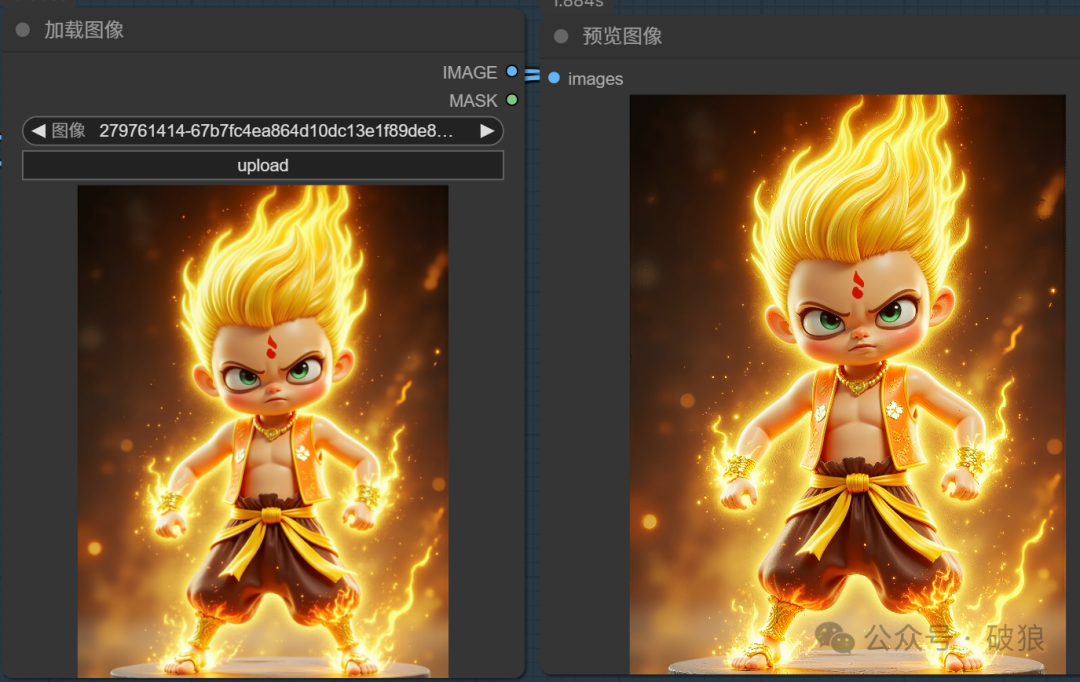
01.4K高清放大
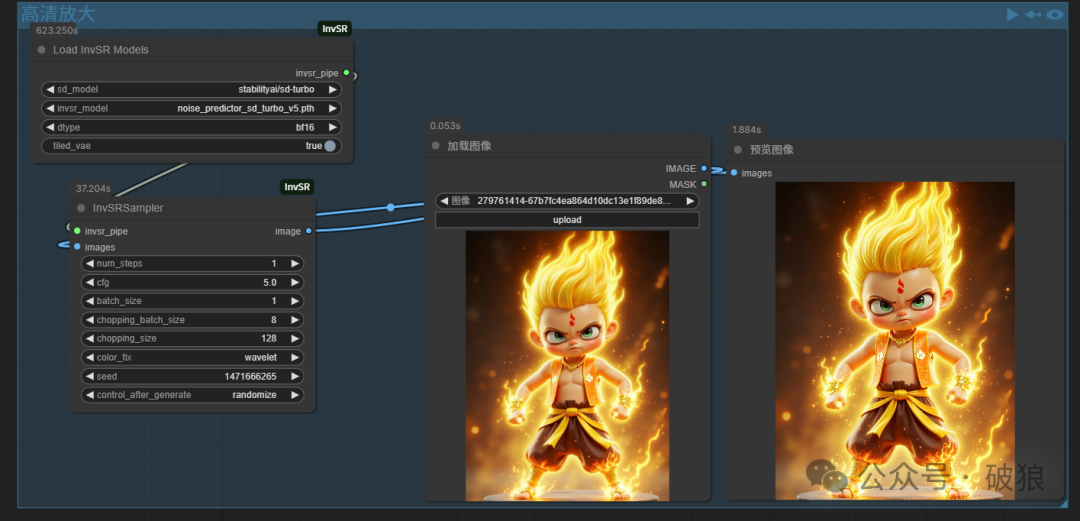
由于平台仅能上传不超过10MB图像,4K高清超过45MB。故本文采用仅截图展示。
 |
|---|
 |
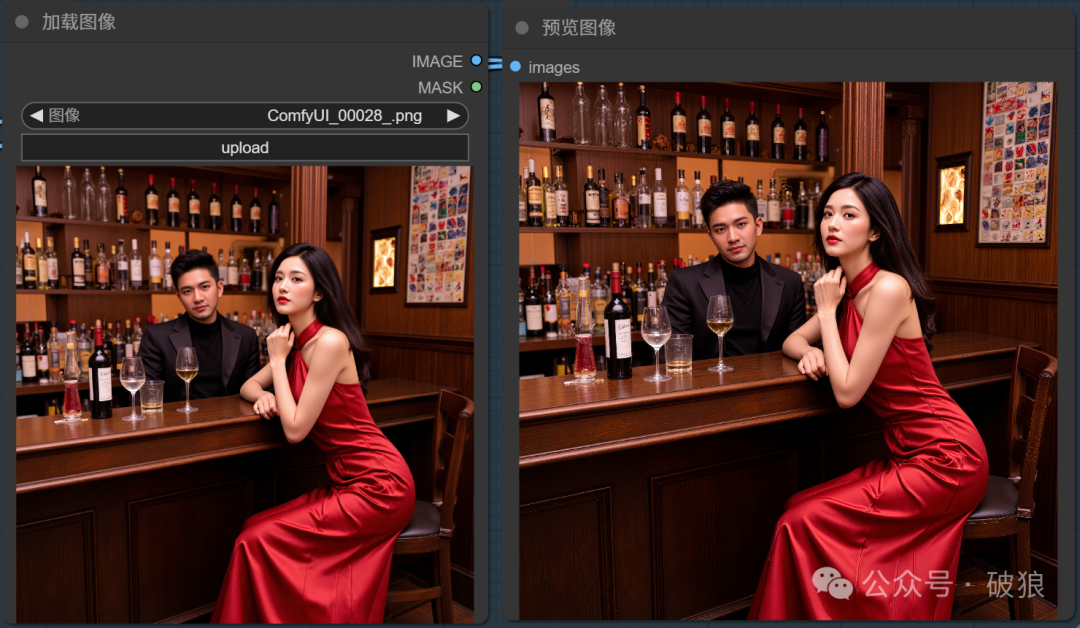 |
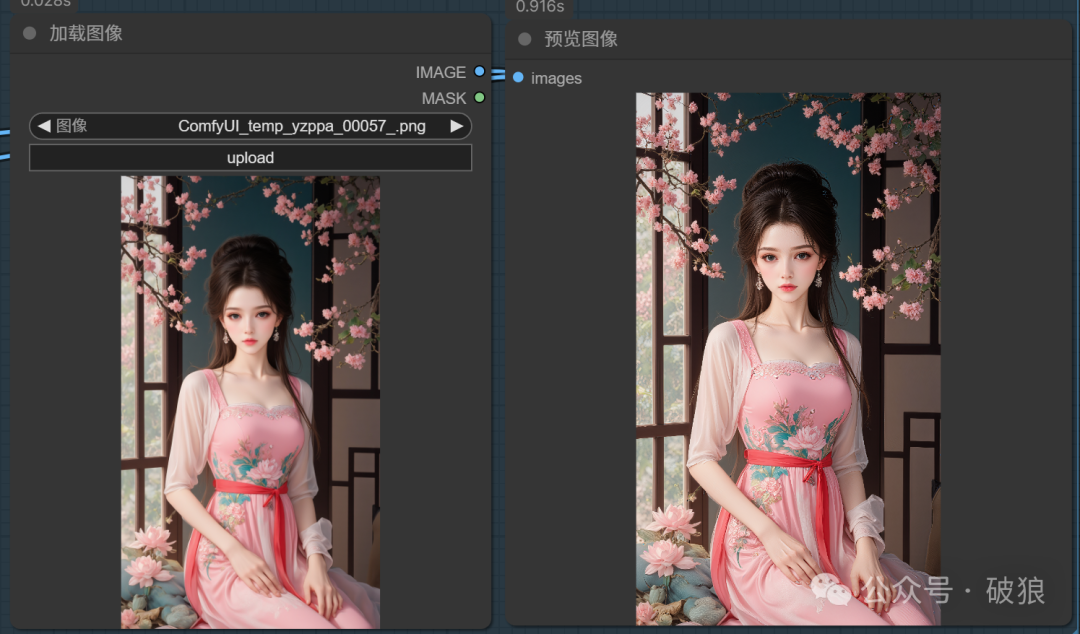
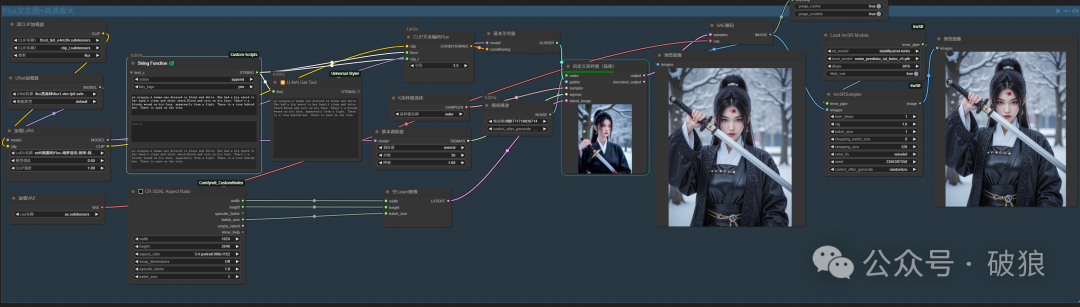
02.剑仙-宁姚
本案例使用Flux-绮梦流光-剑来-剑仙宁姚_国漫女神LORA模型:https://www.liblib.art/modelinfo/88bc3384e5854a97a522d35c4f94ffb6?versionUuid=5e80f31b1f2b4a4bb6261b39e8760930
pl,ningyao,A woman was dressed in black and white. She had a big sword in her hand.A clean and shiny sword.Blood and cuts on his face. There's a bloody wound on his face, apparently from a fight. There is a tree behind her. There is snow on the tree.
 |  |
|---|---|
InvSR模型文末可获取
为了帮助大家更好地掌握 ComfyUI,我花了几个月的时间,撰写并录制了一套ComfyUI的基础教程,共六篇。这套教程详细介绍了选择ComfyUI的理由、其优缺点、下载安装方法、模型与插件的安装、工作流节点和底层逻辑详解、遮罩修改重绘/Inpenting模块以及SDXL工作流手把手搭建。
由于篇幅原因,本文精选几个章节,详细版点击下方卡片免费领取
一、ComfyUI配置指南
- 报错指南
- 环境配置
- 脚本更新
- 后记
- …
二、ComfyUI基础入门
- 软件安装篇
- 插件安装篇
- …
三、 ComfyUI工作流节点/底层逻辑详解
- ComfyUI 基础概念理解
- Stable diffusion 工作原理
- 工作流底层逻辑
- 必备插件补全
- …
四、ComfyUI节点技巧进阶/多模型串联
- 节点进阶详解
- 提词技巧精通
- 多模型节点串联
- …
五、ComfyUI遮罩修改重绘/Inpenting模块详解
- 图像分辨率
- 姿势
- …

六、ComfyUI超实用SDXL工作流手把手搭建
- Refined模型
- SDXL风格化提示词
- SDXL工作流搭建
- …

由于篇幅原因,本文精选几个章节,详细版点击下方卡片免费领取


















 967
967

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









