











HiDream-I1简介
在之前的文章已经多次介绍最新的17B文生图模型:HiDream-I1 。最新社区进展已经出现了一批基于HiDream-I1文生图 底膜的LORA模型,同时也得到了ComfyUI官方的原来支持。今天将在继续深入探索ComfyUI原生支持下的文生图和图生图工作流体验。
• GitHub:https://github.com/HiDream-ai/HiDream-I1
HiDream-I1文生图ComfyUI体验
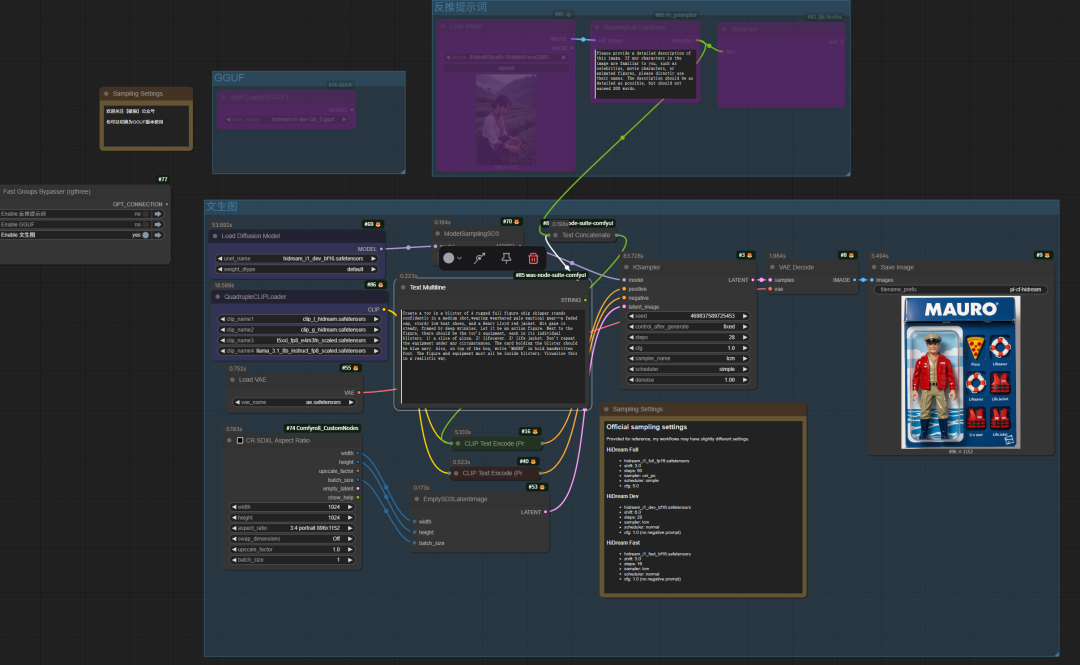
本文将使用ComfyUI本体工作流体验。文末网盘模型下载
• 更新ComfyUI本体即可,无需下载其他插件安装
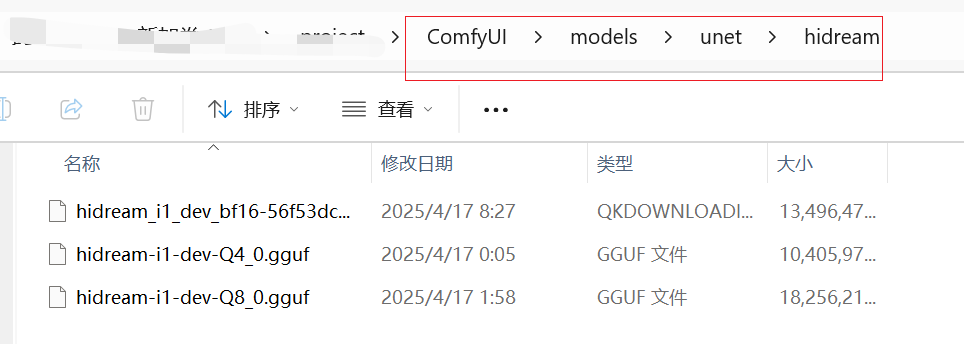
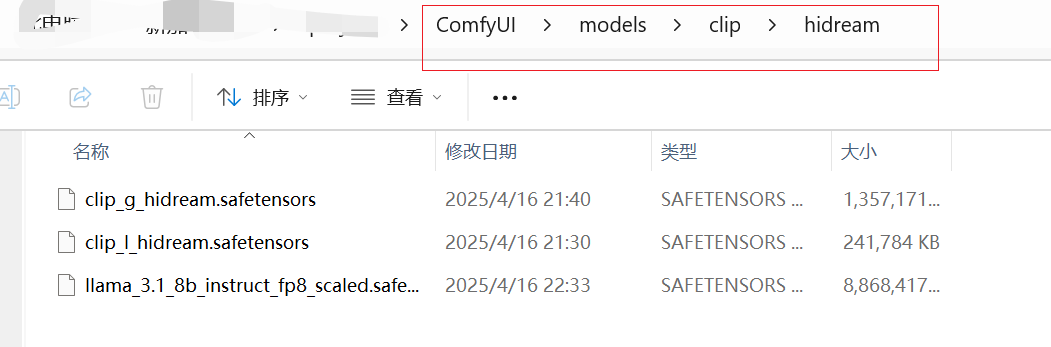
• 模型下载地址:https://huggingface.co/Comfy-Org/HiDream-I1_ComfyUI/tree/main 、 https://huggingface.co/city96/HiDream-I1-Dev-gguf/tree/main
HiDream-I1文生图ComfyUI体验
HiDream-I1文生图ComfyUI体验工作流下载:
- RunningHUB文生图在线体验:https://www.runninghub.cn/post/1912548267165712385/?inviteCode=kol01-rh059
- RunningHUB图生图在线体验:https://www.runninghub.cn/post/1915248465113452546/?inviteCode=kol01-rh059
注意:
• 具有dev、full、fast3个版本,对应的采样步骤、CFG设置不一样。官方推荐设置:HiDream Full:hidream_i1_full_fp16.safetensors:shift: 3.0;steps: 50;sampler: uni_pc;scheduler: simple;cfg: 5.0。HiDream Dev:hidream_i1_dev_bf16.safetensors: shift: 6.0;steps: 28;sampler: lcm;scheduler: normal;cfg: 1.0 (no negative prompt)。HiDream Fast:hidream_i1_fast_bf16.safetensors:shift: 3.0;steps: 16;sampler: lcm;scheduler: normal;cfg: 1.0 (no negative prompt)
• 对于低显存也可以使用GGUF版本或NF4 fast版本,大约15G左右
• 更多图文和视频ComfyUI工作流参见个人主页:https://www.runninghub.cn/user-center/1890418187312222210?utm_source=kol01-RH059
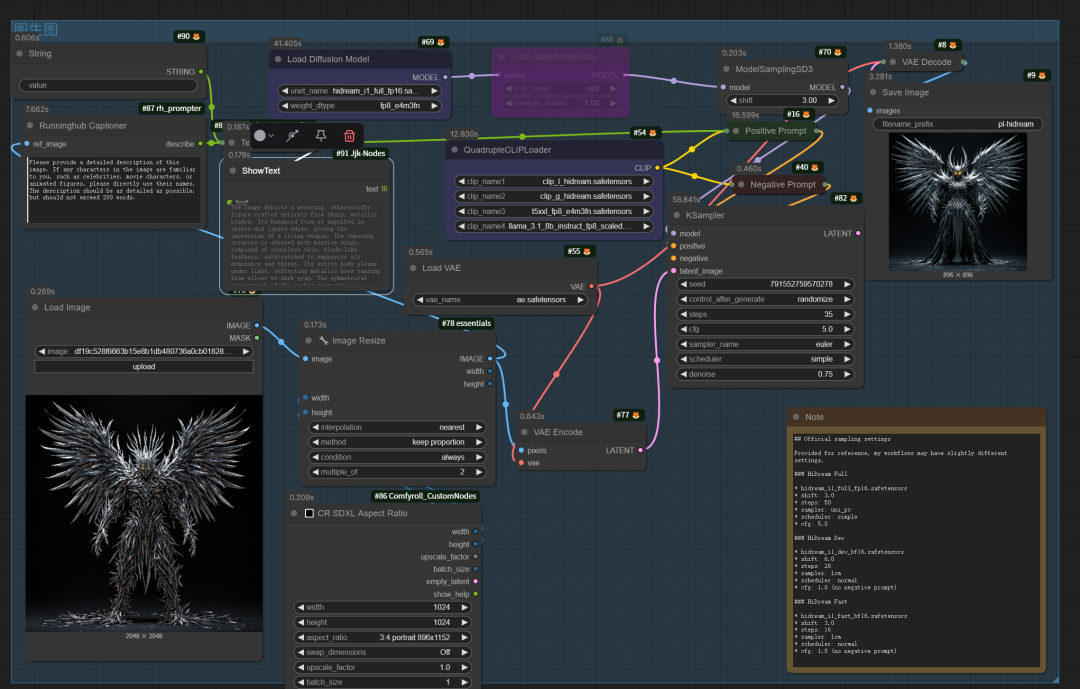
01.文生图-玩偶展示
Create a toy in a blister of A rugged full figure ship skipper stands confidently in a medium shot,wearing weathered pale nautical gear—a faded cap, sturdy low boat shoes, and a Henry Lloyd red jacket. His gaze is steady, framed by deep wrinkles. Let it be an action figure. Next to the figure, there should be the toy's equipment, each in its individual blisters. 1) a slice of pizza. 2) lifesaver. 3) life jacket. Don't repeat the equipment under any circumstances. The card holding the blister should be blue navy. Also, on top of the box, write 'MAURO' in bold handwritten font. The figure and equipment must all be inside blisters. Visualize this in a realistic way.

02.文生图-儿童画
Create a comical pencil drawn stick figure of a man on a blank sheet of white plain paper with a smile on its comical face.

03. 图生图-街机游戏
1 chinese women, The image depicts an arcade environment, showcasing classic gaming machines with brightly lit displays. Prominent among the machines are two "Street Fighter" arcade cabinets, which indicate the retro gaming theme of the location. The subject in focus is a woman standing confidently near the arcade machines, dressed in an eye-catching outfit that includes a fitted white crop top, a black leather mini skirt, long black gloves, and knee-high black boots with red soles. Her sleek, long black hair cascades down, contributing to an edgy yet stylish appearance. Of note, she is positioned with one leg raised onto the arcade console, adding a dynamic, confident pose. The overall setting suggests a nostalgic yet modern vibe, combining retro gaming with contemporary style.In the background, several other arcade players can be seen seated, engaged with the machines, contributing to the lively atmosphere. The lighting of the arcade, complete with glowing screens and signage, enhances the vibrant ambiance of the space. The arrangement of the arcade machines, stools, and players immerses the viewer into the setting, hinting at a fondness for retro gaming culture.

04.图生图-金属人
The image depicts a menacing, otherworldly figure crafted entirely from sharp, metallic blades. Its humanoid form is engulfed in spikes and jagged edges, giving the impression of a living weapon. The imposing creature is adorned with massive wings, composed of countless thin, blade-like feathers, outstretched to emphasize its dominance and threat. Its entire body gleams under light, reflecting metallic hues ranging from silver to dark gray. The symmetrical arrangement of the spikes suggests an intentional design rather than chaotic randomness. Its glowing golden eyes pierce through the darkness, providing an eerie contrast to the cold, steel-like texture of its body. The eyes convey an ominous presence, hinting at intelligence or a supernatural essence. The backdrop is entirely black, emphasizing the figure’s layered sharpness and isolating it as the focal point of the composition.This figure resembles an abstract fusion of a dark angel and a biomechanical entity, evoking imagery similar to characters from dark fantasy or science fiction genres. Its design could align with creatures found in works such as *Final Fantasy*, *Warhammer 40,000*, or a villain from a futuristic dystopia. The scene conveys themes of danger, power, and cold, metallic beauty.

为了帮助大家更好地掌握 ComfyUI,我花了几个月的时间,撰写并录制了一套ComfyUI的基础教程,共六篇。这套教程详细介绍了选择ComfyUI的理由、其优缺点、下载安装方法、模型与插件的安装、工作流节点和底层逻辑详解、遮罩修改重绘/Inpenting模块以及SDXL工作流手把手搭建。
由于篇幅原因,本文精选几个章节,详细版点击下方卡片免费领取
一、ComfyUI配置指南
- 报错指南
- 环境配置
- 脚本更新
- 后记
- …
二、ComfyUI基础入门
- 软件安装篇
- 插件安装篇
- …
三、 ComfyUI工作流节点/底层逻辑详解
- ComfyUI 基础概念理解
- Stable diffusion 工作原理
- 工作流底层逻辑
- 必备插件补全
- …
四、ComfyUI节点技巧进阶/多模型串联
- 节点进阶详解
- 提词技巧精通
- 多模型节点串联
- …
五、ComfyUI遮罩修改重绘/Inpenting模块详解
- 图像分辨率
- 姿势
- …

六、ComfyUI超实用SDXL工作流手把手搭建
- Refined模型
- SDXL风格化提示词
- SDXL工作流搭建
- …

由于篇幅原因,本文精选几个章节,详细版点击下方卡片免费领取


















 5198
5198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









