






Series
1、序列的创建
使用python列表和字典创建序列
(1)列表s=pd.Series([10,11,12,13,14])

(2)字典使用字典创建时,字典的key值就是序列的标签值

使用numpy函数创建
(1)pd.Series(np.arange(4,9))

(2)pd.Series(np.linspace(0,9,5) 该函数意为从0开始,到9结束,一共生成5个等距的数

(3)pd.Series(np.random.normal(size=5))从正态分布生成5个随机数

使用标量值创建
s=pd.Series(2)

2、确定Series中的项目数(长度)
使用len()函数

使用.shape属性
将返回一个二值元组,但仅指定元组中的第一个值并表示Series的长度

使用.size属性
3、如何在创建时指定索引
使用index参数

4、Series的取值
使用head、tail、take函数
(1)s.head(n) 返回前n行,若不赋予n具体值默认返回前5行
(2)s.tail(n) 返回末n行
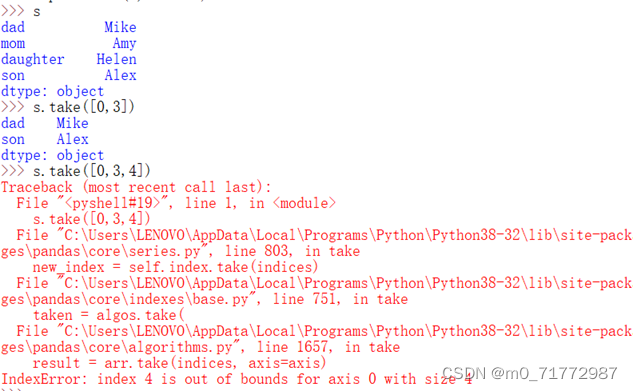
(3)s.take([]) 返回指定整数位置的行和列(注意是通过位置指定,而不是标签值)

注意该函数中的位置不能超过序列中的位置索引,否则会报错
通过标签或位置检索序列中的值
(1)使用[]运算符和.ix[]属性按标签查找(几乎已弃用,因为传整数值可能会造成混乱)s['a']:查找一个s[['a','b']]:查找多个注意:若索引未使用整数标签,[]内可传入单个数字或数字列表来对位置进行查找
(2)使用.iloc[]按位置显式查找不管索引值是否为整数,都会按位置查找;如果位置不存在,将引发异常

(3).loc[]通过标签进行显式查找,若没有该标签,则会引发keyError错误

5、将序列切成子集(切片)
语法如下:s[start:end:step]
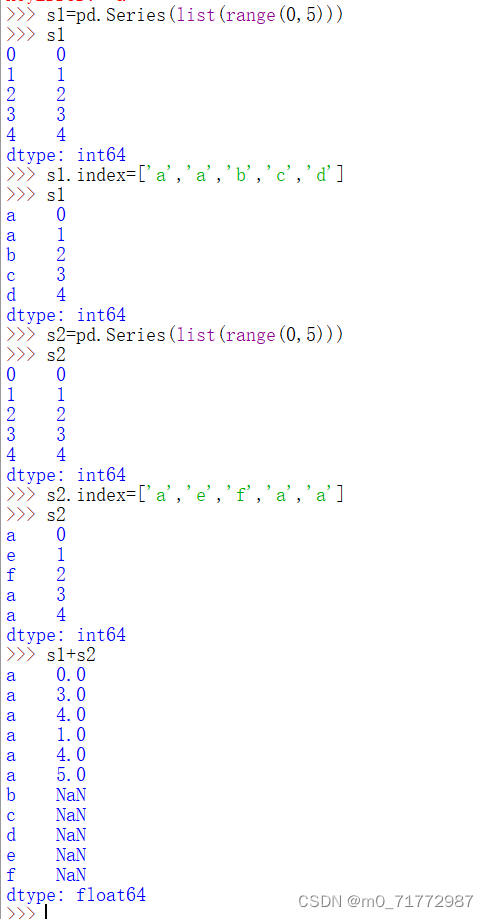
6、通过索引标签对齐
两个序列如果索引标签相同,可进行算术符号运算;如果索引标签未对齐,则未对齐的索引值返回NaN
如果索引中的标签值不唯一(有重复),如S1+S2,若S1中有两个‘a'标签,S2中有三个'a'标签,则S1+S2后,S1中的每个a标签要依次与S2中的三个a标签进行运算,结果中总共有6个a标签
7、执行布尔运算
通过比较运算符筛选在Series序列中符合条件的值
all、any、sum方法
all()方法可以确定Series中的所有值是否与给定表达式匹配
any()方法,只要序列中有一个值满足条件都会返回True
sum()方法可以确定序列中有多少项目满足表达式
8、重新索引序列
为Series的.index属性分配一个新索引,s.index=[] 属性列表中的元素必须与行数相匹配,否则将引发异常
使用.reindex()方法 方法中的fill_value参数可更改默认NaN值的显示
注意:reindex()方法是形成一个新的Series,如果.reindex()方法中指定的索引在原来的Series中存在,则复制过去;若不存在,则用NaN代替
当对有序数据执行重新索引时,可执行插值或值填充 s.reindex(np.arange(0,7),method="" method的取值为ffill或bfill
















 671
671











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









