







为了方便跟踪消息发送和消费的轨迹,RocketMQ 引入了轨迹消息,今天一起来学习一下。
1 开启轨迹消息
默认情况下,RocketMQ 是不开启轨迹消息的,需要我们手工开启。
1.1 Broker
Broker 端开启轨迹消息,需要增加下面的配置:
traceTopicEnable=true1.2 生产者
对于生产者端,要开启轨迹消息,需要在定义生产者时增加参数。定义消费者使用类 DefaultMQProducer,这个类支持开启轨迹消息的构造函数如下:
public DefaultMQProducer(final String producerGroup, RPCHook rpcHook, boolean enableMsgTrace, final String customizedTraceTopic)
public DefaultMQProducer(final String producerGroup, boolean enableMsgTrace)
public DefaultMQProducer(final String producerGroup, boolean enableMsgTrace, final String customizedTraceTopic)
public DefaultMQProducer(final String namespace, final String producerGroup, RPCHook rpcHook, boolean enableMsgTrace, final String customizedTraceTopic)
从上面的构造函数可以看出,自定义消费者时,不仅可以定义开启轨迹消息,还可以指定轨迹消息发送的 Topic。如果不指定轨迹消息的 Topic,默认发送的 Topic 是 RMQ_SYS_TRACE_TOPIC。
1.3 消费者
对于消费者,要开启轨迹消息,需要在定义消费者时增加参数。定义消费者使用类 DefaultMQPushConsumer,这个类支持开启轨迹消息的构造函数如下:
public DefaultMQPushConsumer(final String consumerGroup, boolean enableMsgTrace)
public DefaultMQPushConsumer(final String consumerGroup, boolean enableMsgTrace, final String customizedTraceTopic)
public DefaultMQPushConsumer(final String consumerGroup, RPCHook rpcHook,
AllocateMessageQueueStrategy allocateMessageQueueStrategy, boolean enableMsgTrace, final String customizedTraceTopic)
public DefaultMQPushConsumer(final String namespace, final String consumerGroup, RPCHook rpcHook,
AllocateMessageQueueStrategy allocateMessageQueueStrategy, boolean enableMsgTrace, final String customizedTraceTopic)
2 生产者处理
首先看一个支持轨迹消息的生产者示例:
DefaultMQProducer producer = new DefaultMQProducer(producerGroupTemp, true, "");
producer.setNamesrvAddr("127.0.0.1:9876");
producer.start();
下面是一张生产者端的 UML 类图:
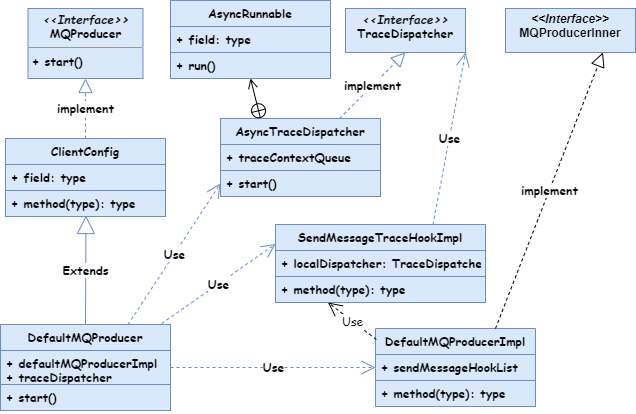
在 DefaultMQProducer 创建时,会初始化 defaultMQProducerImpl、traceDispatcher 和钩子函数 SendMessageHook。
2.1 生产者初始化
生产者初始化代码如下:
public DefaultMQProducer(final String namespace, final String producerGroup, RPCHook rpcHook,
boolean enableMsgTrace, final String customizedTraceTopic) {
this.namespace = namespace;
this.producerGroup = producerGroup;
defaultMQProducerImpl = new DefaultMQProducerImpl(this, rpcHook);
if (enableMsgTrace) {
try {
AsyncTraceDispatcher dispatcher = new AsyncTraceDispatcher(producerGroup, TraceDispatcher.Type.PRODUCE, customizedTraceTopic, rpcHook);
dispatcher.setHostProducer(this.defaultMQProducerImpl);
traceDispatcher = dispatcher;
//注册轨迹消息钩子函数
this.defaultMQProducerImpl.registerSendMessageHook(
new SendMessageTraceHookImpl(traceDispatcher));
//省略事务消息的钩子注册
} catch (Throwable e) {
}
}
}
初始化的代码中,传入了是否开启轨迹消息(enableMsgTrace)和自定义轨迹消息的 Topic(customizedTraceTopic),同时初始化了 traceDispatcher 并注册了钩子函数 SendMessageTraceHook。
生产者启动时 defaultMQProducerImpl 和 traceDispatcher 也会启动,代码如下:
public void start() throws MQClientException {
this.setProducerGroup(withNamespace(this.producerGroup));
this.defaultMQProducerImpl.start();
if (null != traceDispatcher) {
try {
traceDispatcher.start(this.getNamesrvAddr(), this.getAccessChannel());
} catch (MQClientException e) {
log.warn("trace dispatcher start failed ", e);
}
}
}
2.2 traceDispatcher 启动
生产者初始化的时候初始化了 traceDispatcher。traceDispatcher 是轨迹消息的处理器,AsyncTraceDispatcher 构造函数定义一个专门发送轨迹消息的生产者 traceProducer(DefaultMQProducer 类型)。
注意:traceProducer 发送消息的最大值 maxMessageSize 是 128k,虽然 maxMessageSize 初始值被定义为 4M,但是创建 traceProducer 时赋值 128k。
上面提到,生产者启动时 traceDispatcher 也会启动,看一下它的启动方法:
public void start(String nameSrvAddr, AccessChannel accessChannel) throws MQClientException {
if (isStarted.compareAndSet(false, true)) {
traceProducer.setNamesrvAddr(nameSrvAddr);
traceProducer.setInstanceName(TRACE_INSTANCE_NAME + "_" + nameSrvAddr);
traceProducer.start();
}
this.accessChannel = accessChannel;
this.worker = new Thread(new AsyncRunnable(), "MQ-AsyncTraceDispatcher-Thread-" + dispatcherId);
this.worker.setDaemon(true);
this.worker.start();
this.registerShutDownHook();
}
可以看到,traceDispatcher 的启动首先启动了 traceProducer,然后启动了一个异步线程 AsyncRunnable,下面看一下 run 方法:
public void run() {
while (!stopped) {
//batchSize=100
List<TraceContext> contexts = new ArrayList<TraceContext>(batchSize);
//traceContextQueue队列长度等于1024
synchronized (traceContextQueue) {
for (int i = 0; i < batchSize; i++) {
TraceContext context = null;
try {
//get trace data element from blocking Queue - traceContextQueue
context = traceContextQueue.poll(5, TimeUnit.MILLISECONDS);
} catch (InterruptedException e) {
}
if (context != null) {
contexts.add(context);
} else {
break;
}
}
if (contexts.size() > 0) {
AsyncAppenderRequest request = new AsyncAppenderRequest(contexts);
traceExecutor.submit(request);
} else if (AsyncTraceDispatcher.this.stopped) {
this.stopped = true;
}
}
}
}
从上面的代码可以看到,每次从 traceContextQueue 中拉取 100 条 TraceContext,然后通过 AsyncAppenderRequest 异步发送出去。
注意:
-
发送轨迹消息时需要组装消息进行批量发送,每次发送的消息大小不超过 128k;
-
如果保存轨迹消息的 Broker 有多个,则需要按照轮询的方式依次发送到不同的 Broker 上,具体代码见 AsyncTraceDispatcher 类中的 sendTraceDataByMQ 方法。
2.3 钩子函数
看到这里相信你一定会有一个疑问,traceContextQueue 中的消息是从哪儿来的呢?答案是生产者初始化时定义的 SendMessageTraceHook。
看一下发送消息的代码:
//DefaultMQProducerImpl 类
private SendResult sendKernelImpl(final Message msg,
final MessageQueue mq,
final CommunicationMode communicationMode,
final SendCallback sendCallback,
final TopicPublishInfo topicPublishInfo,
final long timeout) throws MQClientException, RemotingException, MQBrokerException, InterruptedException {
//省略部分代码
SendMessageContext context = null;
if (brokerAddr != null) {
try {
//省略部分代码
if (this.hasSendMessageHook()) {
context = new SendMessageContext();
//1.发送消息前执行钩子函数
this.executeSendMessageHookBefore(context);
}
SendMessageRequestHeader requestHeader = new SendMessageRequestHeader();
//省略requestHeader封装代码
SendResult sendResult = null;
//-------------2.这里发送消息-------------
if (this.hasSendMessageHook()) {
context.setSendResult(sendResult);
//3.发送消息后执行钩子函数
this.executeSendMessageHookAfter(context);
}
return sendResult;
}
//catch和finally省略
}
throw new MQClientException("The broker[" + mq.getBrokerName() + "] not exist", null);
}
由于 sendKernelImpl 代码比较多,我这里只贴了骨架代码。我在上面加了注释,可以看到在发送消息前后都会执行钩子函数。
在发送消息前,通过调用钩子函数封装一个轨迹消息。发送消息后,再通过钩子函数对轨迹消息进行完善,主要加入消息发送结果、发送消息花费时间等属性,然后把轨迹消息加到 traceContextQueue 上。轨迹消息包含的内容如下图:
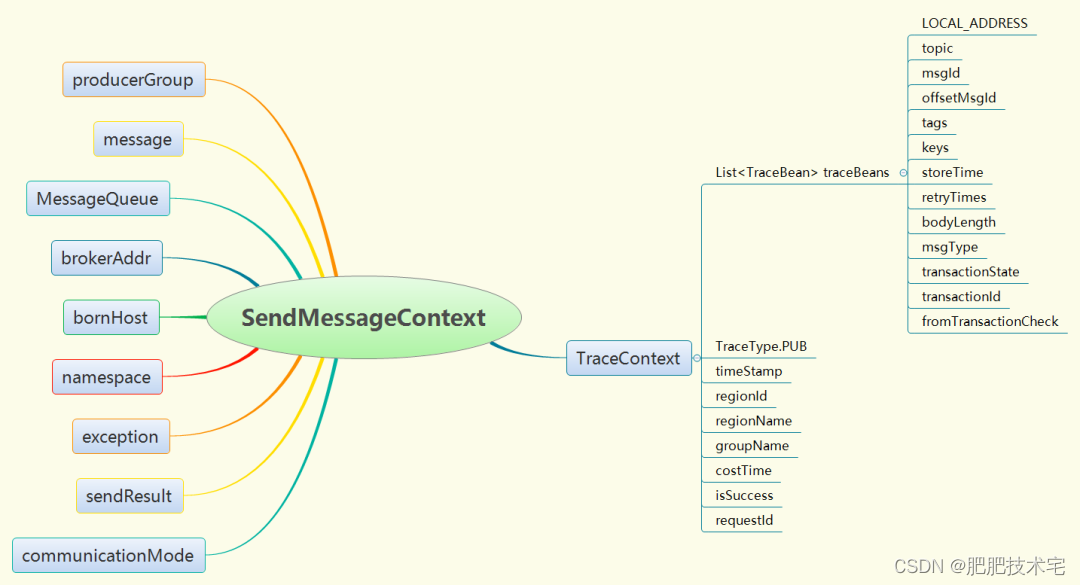
轨迹消息的内容比较多,包含了发送消息的详细信息,比如:Topic、Message、MessageQueue、Group、生产者地址(clientHost)、消息发送结果等。
3 Broker 处理
轨迹消息发送到 Broker 后,会保存到 Broker 上,默认保存的 Topic 是 RMQ_SYS_TRACE_TOPIC。Broker 启动时,会自动初始化默认 Topic 的路由配置,代码如下:
//TopicConfigManager 类
if (this.brokerController.getBrokerConfig().isTraceTopicEnable()) {
String topic = this.brokerController.getBrokerConfig().getMsgTraceTopicName();
TopicConfig topicConfig = new TopicConfig(topic);
TopicValidator.addSystemTopic(topic);
topicConfig.setReadQueueNums(1);
topicConfig.setWriteQueueNums(1);
this.topicConfigTable.put(topicConfig.getTopicName(), topicConfig);
}
前面提到过,生产者也可以自己定义轨迹消息 Topic,不过需要在 Broker 上提前创建好自定义的 Topic。
如果想要轨迹消息和业务消息隔离,可以专门用一个 Broker 来保存轨迹消息,这样需要单独在这个 Broker 上开启轨迹消息。
4 消费端处理
消费端对轨迹消息的处理跟生产端非常类似。首先我们看一下消费端处理的 UML 类图:

我们以推模式处理并发消息为例,ConsumeMessageConcurrentlyService 在消费消息前,通过 DefaultMQPushConsumerImpl 调用了钩子函数 executeHookBefore,消费消息后通过 DefaultMQPushConsumerImpl 调用了钩子函数 executeHookAfter。代码如下:
//ConsumeMessageConcurrentlyService 类
public void run() {
//省略部分逻辑
ConsumeMessageContext consumeMessageContext = null;
if (ConsumeMessageConcurrentlyService.this.defaultMQPushConsumerImpl.hasHook()) {
consumeMessageContext = new ConsumeMessageContext();
consumeMessageContext.setNamespace(defaultMQPushConsumer.getNamespace());
consumeMessageContext.setConsumerGroup(defaultMQPushConsumer.getConsumerGroup());
consumeMessageContext.setProps(new HashMap<String, String>());
consumeMessageContext.setMq(messageQueue);
consumeMessageContext.setMsgList(msgs);
consumeMessageContext.setSuccess(false);
//1.消费消息前执行钩子函数
ConsumeMessageConcurrentlyService.this.defaultMQPushConsumerImpl.executeHookBefore(consumeMessageContext);
}
//省略部分逻辑
try {
//2.消费消息
status = listener.consumeMessage(Collections.unmodifiableList(msgs), context);
} catch (Throwable e) {
}
//省略部分逻辑
if (ConsumeMessageConcurrentlyService.this.defaultMQPushConsumerImpl.hasHook()) {
consumeMessageContext.setStatus(status.toString());
consumeMessageContext.setSuccess(ConsumeConcurrentlyStatus.CONSUME_SUCCESS == status);
//3.消费消息前执行钩子函数
ConsumeMessageConcurrentlyService.this.defaultMQPushConsumerImpl.executeHookAfter(consumeMessageContext);
}
//省略部分逻辑
}
如果消费端开启轨迹消息,就会初始化 traceDispatcher 并且注册钩子函数。
if (enableMsgTrace) {
try {
AsyncTraceDispatcher dispatcher = new AsyncTraceDispatcher(consumerGroup, TraceDispatcher.Type.CONSUME, customizedTraceTopic, rpcHook);
dispatcher.setHostConsumer(this.getDefaultMQPushConsumerImpl());
traceDispatcher = dispatcher;
this.getDefaultMQPushConsumerImpl().registerConsumeMessageHook(
new ConsumeMessageTraceHookImpl(traceDispatcher));
} catch (Throwable e) {
log.error("system mqtrace hook init failed ,maybe can't send msg trace data");
}
}
可以看到,traceDispatcher 跟生产者使用的都是 AsyncTraceDispatcher,处理逻辑完全一样。
同样,钩子函数的使用跟生产者也类似,在消费消息之前调用钩子函数(executeHookBefore)封装轨迹消息,在消费消息之后再次调用钩子函数(executeHookAfter)完善轨迹消息。消费端轨迹消息的内容如下图:
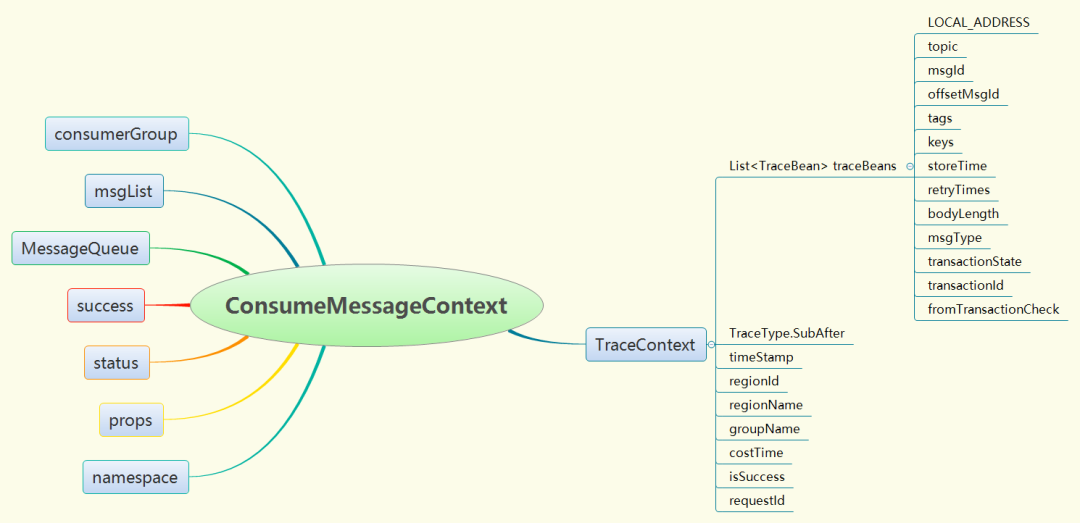
5 总结
本文主要讲解了 RocketMQ 的轨迹消息实现机制。轨迹消息分为生产端和消费端的轨迹消息,生产端和消费端 RocketMQ 都提供了构造函数来指定是否开启轨迹消息。通过钩子函数,把轨迹消息加入队列,也就是变量 traceContextQueue,而 traceDispatcher 则以 100 条为单位不停地从队列中拉取消息进行组装并发送到 Broker。如下图:
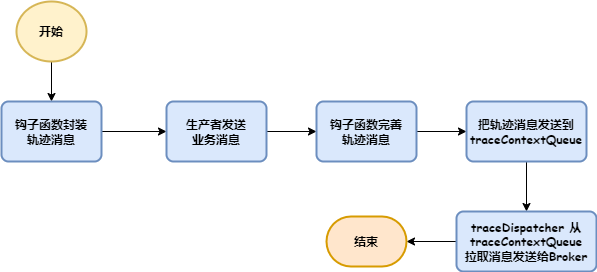
理解了 traceDispatcher 和钩子函数 ,就很容易理解 RocketMQ 轨迹消息的处理逻辑了。
在 Broker 端,则通过增加配置参数 traceTopicEnable 来指定是否存储轨迹消息。














 1075
1075











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









