







1. 简介
网络交互过程中,两个节点需要进行交互,假设两个节点称为 A、B,A 节点需要获取到 B 节点产生的数据,需要怎么做呢?有两种方式:
-
推:B 在存在新消息时把新消息主动推动给 A 节点
-
拉:A 节点定期轮询 B 节点中有没有新消息
那么两种方式哪种更好呢?
-
推:推相较于拉不需要轮询,但是推具有不可靠性
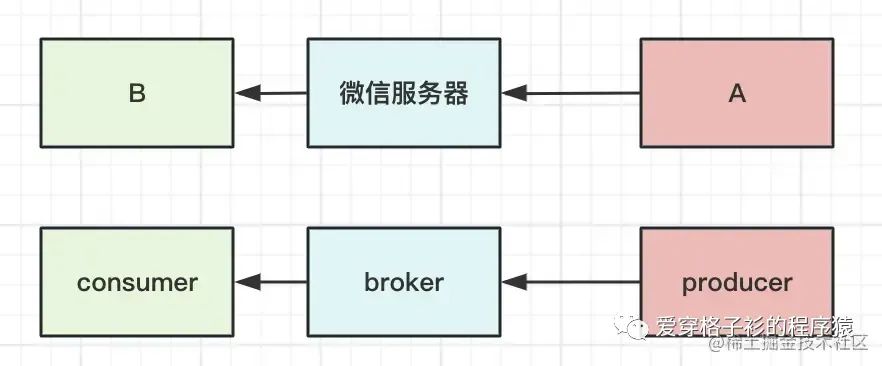
网络交互中,例如微信,用户 A 向用户 B 发送消息,需要先把消息发送给微信服务器再由微信服务器转发给用户 B。RocketMQ 也是如此,生产者需要先把消息发送给 broker ,broker 再把消息转发给 consumer。在这一过程中 broker 作为服务端,而生产者和消费者作为客户端,网络交互中服务端的端口号由启动服务器时指定,不会改变,而客户端的端口号是由操作系统去随机分配,如果客户端发生改变,例如重启、关闭进程、新增客户端等那服务端就会找不到客户端,导致不能推送消息
-
拉:可以保证消息拉取动作由消费者自己去发起,只要消费者能够正常工作就可以持续去 broker 拉取新消息,但是弊端是,需要消费者自己去轮询拉取,如果没有新消息时,会导致空轮询浪费 cpu 资源。
2. RokectMQ 中的推与拉
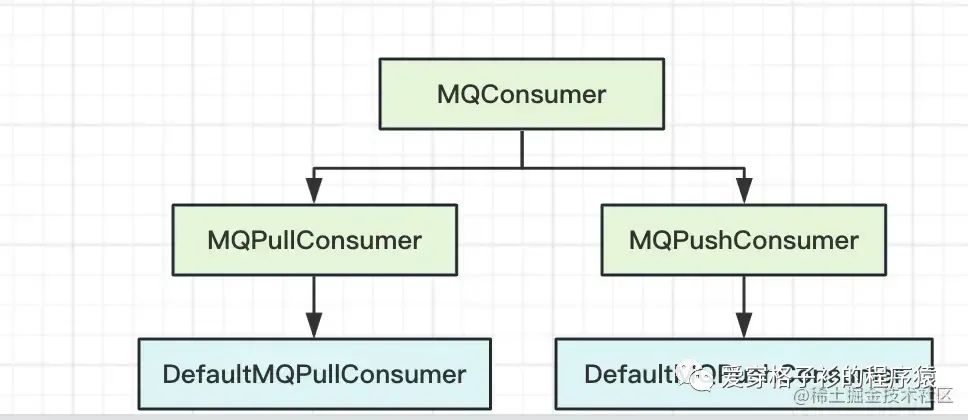
RocketMQ 提供了两种模式的消费者,下面让我们看下两种方式的区别。
2.1 拉取消费者-DefaultMQPullConsumer
java复制代码 // 新建拉取消费者,并指定消费者组
DefaultMQPullConsumer consumer = new DefaultMQPullConsumer("consume_group");
// 指定 namesrv 地址
consumer.setNamesrvAddr("127.0.0.1:9876");
// 启动消费者
consumer.start();
// 设置需要拉取的消息队列信息,topic 名字、broker 名字、队列id
MessageQueue messageQueue = new MessageQueue("topic_name", "broker-name", 0 /*队列id*/);
// 进行拉取操作
PullResult pullResult = consumer.pull(messageQueue, "*", 0 /*offset*/, 5 /*maxNums*/);
// 消费拉取的数据
for (MessageExt messageExt : pullResult.getMsgFoundList()) {
System.out.println(new String(messageExt.getBody(), StandardCharsets.UTF_8));
}
- 在启动消费者时,消费者会通过 namesrv 去找到 broker 的地址,并且与 broker 建立连接
- 获取消息由消费者自己进行控制,通过调用 consumer.pull 方法,传入 topic、队列id、拉取偏移量、拉取的消息数去进行主动拉取。
2.2 推送消费者-DefaultMQPushConsumer
java复制代码 // 新建拉取消费者,并指定消费者组
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("consume_group");
// 指定 namesrv 地址
consumer.setNamesrvAddr("127.0.0.1:9876");
// 设置消费者第一次启动时从哪拉取消息
consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_FIRST_OFFSET);
// 设置订阅的 topic 名字
consumer.subscribe("topic_name", "*");
// 注册消息监听器,即拉取消息后的消费逻辑
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs,
ConsumeConcurrentlyContext context) {
msgs.forEach(msg -> {
try {
System.out.printf("%s Receive New Messages: %s %n",
Thread.currentThread().getName(), new String(msg.getBody(), RemotingHelper.DEFAULT_CHARSET));
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
});
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
// 启动消费者
consumer.start();
与拉取消费者的区别
- 需要指定第一次启动时从哪个位置拉取消息,可以从 初始位置消费、指定时间点位置消费、队列的最后更新位置消费。不同于拉取消费者需要自己指定偏移量,推送消费者只需要指定第一次启动时需要消息的偏移量后续随着不断的消费新消息,推送消费者的消费偏移量也会随之更新,不断获取新消息
- 需要在启动前指定 topic 名字,方便 broker 将指定 topic 的信息推送给该消费者
- 需要注册消息监听器,拉取消费者自己按照制定的逻辑去消费拉取的消息,但是推送消费者会不断有新消息产生,因此需要制定逻辑在有新消息推送到消费者时去执行该逻辑
3. 消费者获取消息的原理
拉取消费者,拉取的过程比较简单,发送了一次网络请求去获取数据,可以类比为发起了一次 http 请求去向服务器获取数据,不做过多介绍。
推送消费者原理
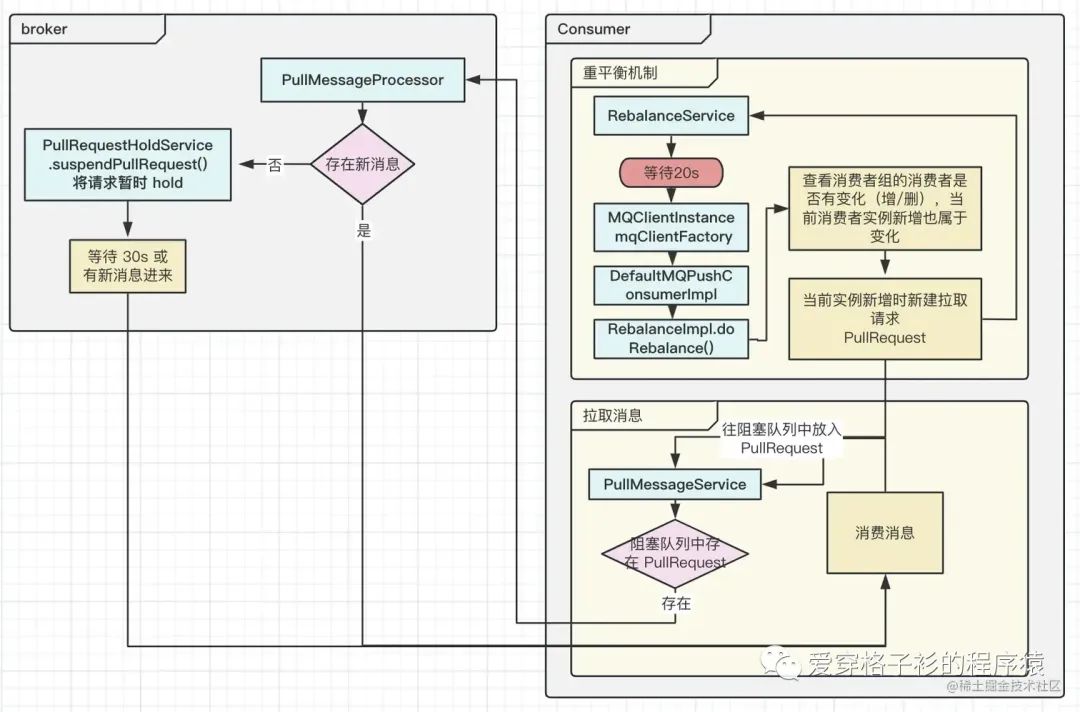
-
通过 PullMessageService 去轮询,查看阻塞队列
LinkedBlockingQueue<PullRequest> pullRequestQueue中是否有拉取请求,有的话从队列中弹出拉取请求进行拉取新消息,否则阻塞队列阻塞等待。拉取请求什么时候被放到阻塞队列中?-
RebalanceService 会定时 20s 轮询一次查看消费者组中的消费者是否有变化(增/减),例如新建消费者节点时就属于增行为,会重平衡为当前消费者节点分配 queueId ,包装 PullRequest 拉取请求放入到阻塞队列中。
-
在上一次拉取请求完成后并且消费者消费完成后将拉取请求再次放入到阻塞队列中。
-
-
请求到达 broker 的 PullMessageProcessor 后,如果有新消息立即返回,如果没有新消息,会将请求放入到 PullRequestHoldService 中进行等待,等待期间 PullRequestHoldService 会每 1s 轮训一次检查有没有新消息到达。等待有新消息到达或者等待 30s 后进行返回。
RocketMQ 的推送模式是通过包装拉取逻辑,同时在 broker 中增加空请求等待,有新数据或者等待一段时间后返回,降低空轮询。我们在实际开发中也可以借鉴,不使用单一的推/拉,可以推拉结合,既避免客户端的不可靠性又可以降低空轮询导致的cpu消耗。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









