






目录
15.join (rightOuterJoin leftOuterJoin fullOuterJoin)
一、从内存中读取数据创建RDD
1.parallelize()
parallelize有两个参数:
(1).需要转化的集合:须是seq集合,seq代表序列,指的是一类具有一定长度的可迭代访问的对象,其中每个数据元素均有一个从0开始的、固定的索引
(2).分区数,若不设分区数则rdd的分区数默认为该程序分配到的资源的cpu核心
演示:
val data = Array(1,2,3,4) //定义数组
val p_data = sc.parallelize(data) //使用parallelize()方法创建rdd
p_data.partitions.size // 查看rdd默认的分区数
val p_data = sc.parallelize(data,4) //设置分区数为4后创建rdd
p_data.partitions.size //查看rdd的分区数2.makeRDD()
makeRDD的使用方式有两个,一种是和parallelize一样,另外一种是根据数据大小思考分区
val seq = Seq((1,Seq("hello.com","scala.com")),
(3,Seq("hello.com","scala2.com")),(2,Seq("hello.com","scala3.com")))
//定义一个序列
val mrdd = sc.makeRDD(seq)
//使用makeRDD进行分区
mrdd.collect
//查看mrdd的值
mrdd.partitioner
mrdd.partitions.size
//查看分区数
mrdd.perferredLocations(mrdd.partitions(0))
mrdd.perferredLocations(mrdd.partitions(1))
mrdd.perferredLocations(mrdd.partitions(2))
//根据位置信息查看每一个分区的值二、从外部中读取数据创建RDD
1.hdfs文件
val test = sc.textFile("/data/test.txt")2.通过linux的本地文件创建
val test = sc.textFile("file:///data/test.txt")三、基本方法
1.map()
使用map方法转换数据
val data = sc.parallelize(List(1,2,5,6,8))
//创建rdd
val data1 = data.map(x => x*x)
//map方法算平方值2.sortBy()
对标准rdd进行排序
val data = sc.parallelize(List((1,2),(5,6),(8,4)))
val sortdata = data.sortBy(x => x._2,false,1)
//x._2是对第二个值进行排序,false是降序,1是指分区
//若要升序把false改为true3.collect()
查询数据
val data = sc.parallelize(List(1,2,5,6,8))
data.collect4.flatMap()
转换数据,分割合成1维
val data = sc.parallelize(List("Hello world"),("I am Fine"),("LET STUDY"))
data.flatMap(x => x.split(" ")).collect
结果
Array("Hello,world,I,am,Fine,LET,STUDY")5.take()
查询值
val data = sc.parallelize(List(1,2,5,6,8))
data.take(5)6.union
合并数据
val data = sc.parallelize(List((1,2),(5,6),(8,4)))
val data2 = sc.parallelize(List((1,3),(5,4),(8,5)))
data.union(data2)
结果:
Array((1,2),(5,6),(8,4),(1,3),(5,4),(8,5))7.filter
过滤数据
val data = sc.parallelize(List(('a',2),('b',6),('c',4)))
data.filter(_._2 >4).collect
data.filter(x=> x._2>4).collect
//过滤第二个数据小于等于4的数据,以上是两种写法,可以更具自己喜好挑选
8.distinct()
数据去重
val data = sc.makeRDD(List(('a',2),('b',6),('c',4),('a',2)))
data.distinct()9.intersection()
求出rdd的共同元素
val data = sc.parallelize(List((1,2),(5,6),(8,4)))
val data2 = sc.parallelize(List((1,2),(5,4),(8,5)))
data.intersection(data2)
10.subtract()
将原rdd里和参数rdd相同元素去掉
val data = sc.parallelize(List((1,2),(5,6),(8,4)))
val data2 = sc.parallelize(List((1,2),(5,4),(8,5)))
data.subtract(data2)
11.cartesian()
求两个edd的笛卡尔积
val data1 = sc.makeRDD(List(1,2,5,6))
val data2 = sc.makeRDD(List(8,3,4,6))
data1.cartesian(data2).collect12.reduceByKey()
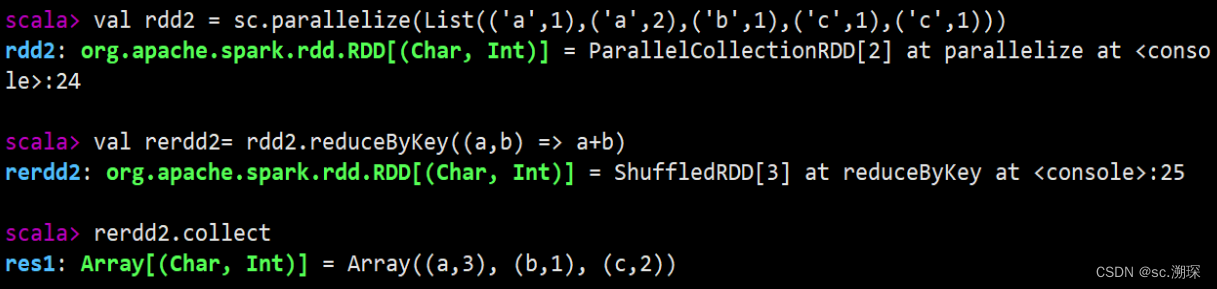
13.groupByKey
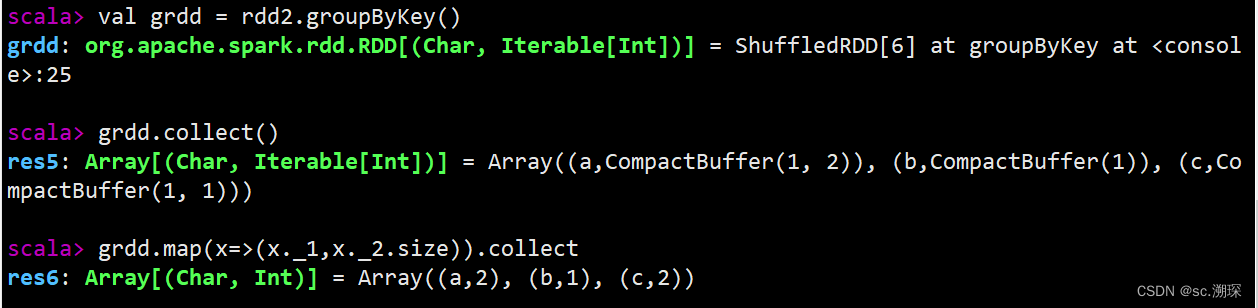
14.mapValues
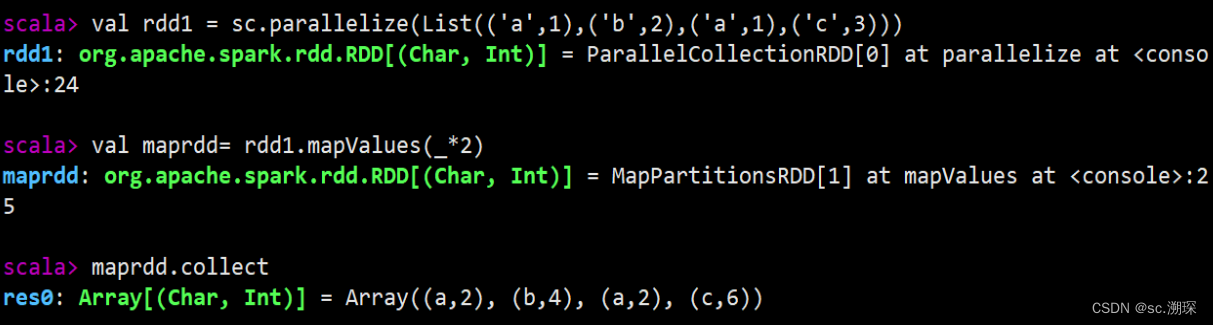
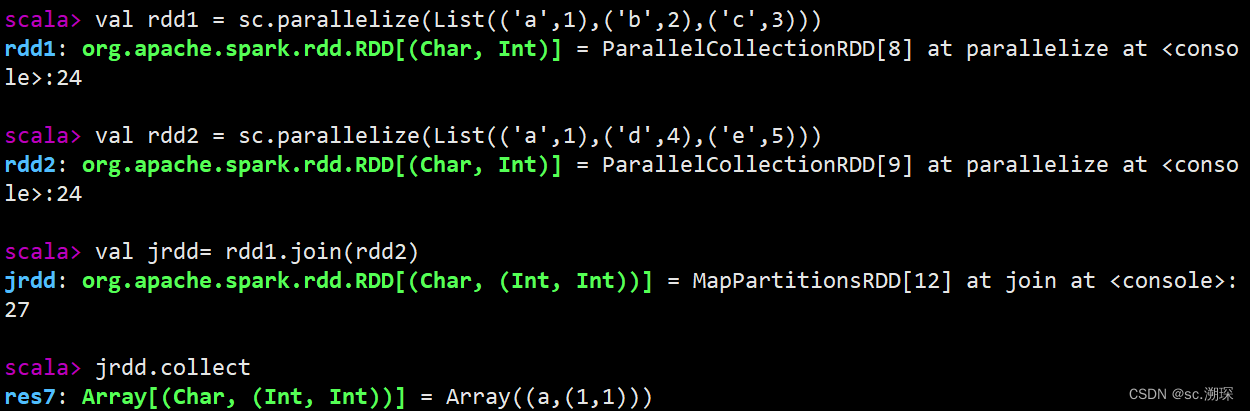
15.join (rightOuterJoin leftOuterJoin fullOuterJoin)
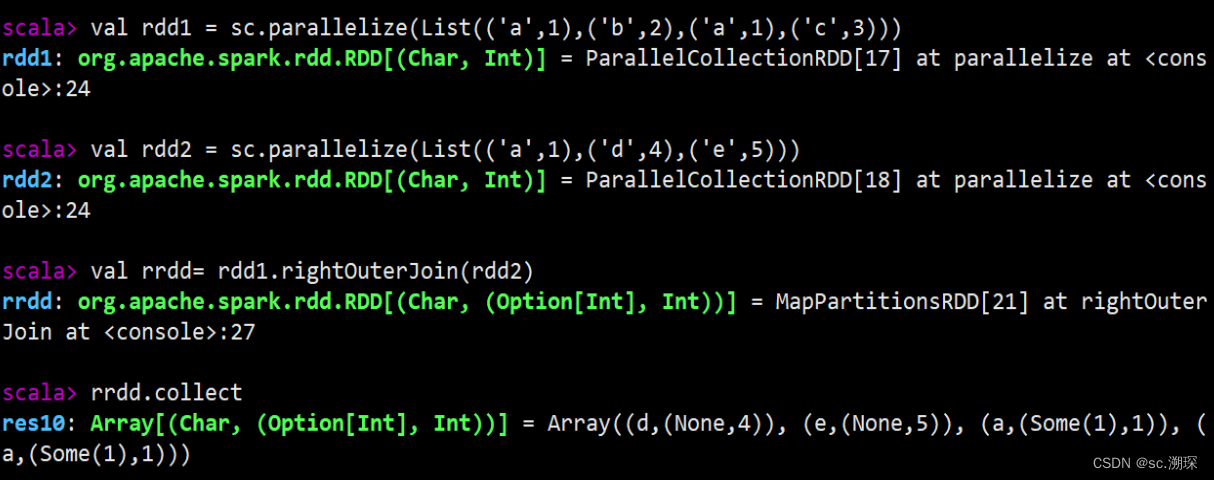
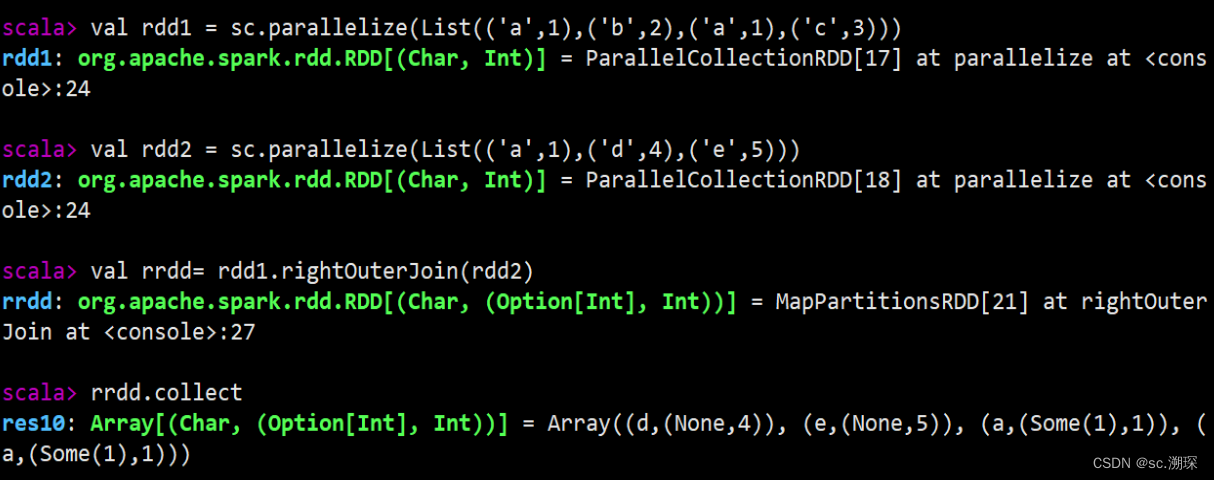
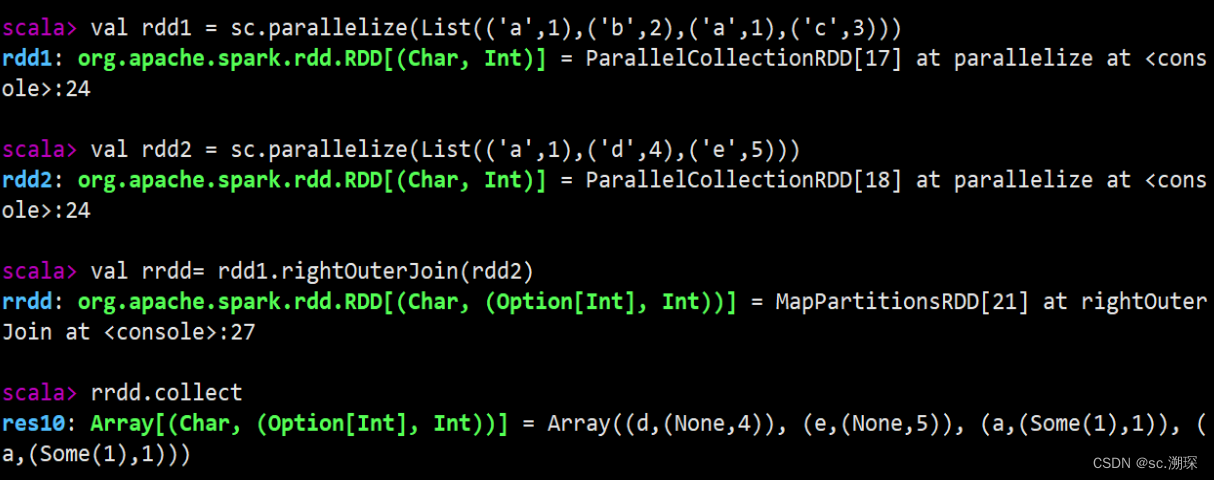
16. zip
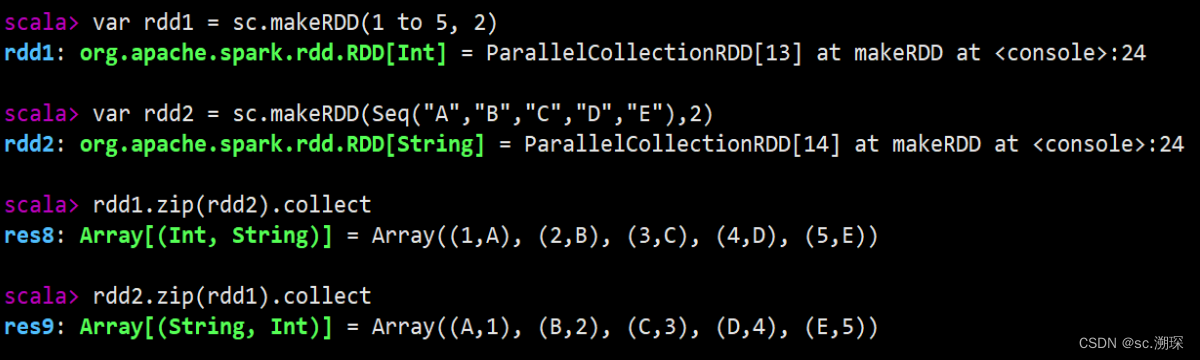
17.lookup

















 1082
1082











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









