






Pandas读取csv文件的格式: read_csv(filepath_or_buffer, sep=',', delimiter=None, header='infer', names=None, index_col=None, usecols=None, squeeze=False, ...)
一、pandas数据读取
1.1csv文件
df1 = pd.read_csv(‘文件路径文件名’)
#读取CSV文件到DataFrame中
df2 = pd.read_table(‘文件路径文件名’, sep = ‘,’)
#使用read_table,并指定分隔符
df3 = pd.read_csv(‘文件路径文件名’,names = [‘a’,’b’,---])
#文件不包含表头行,允许自动分配默认列名,也可以指定列名1.2excel文件
读取excel文件 Pandas读取excel文件的格式:
pandas.read_excel(io,sheet_name = 0,
header = 0,names = None,
index_col = None,
usecols = None,
squeeze = False,dtype = None, ...)
示例:
xlsx = pd.excelFile(‘example/ex1.xlsx’)
pd.read_excel(xlsx, ‘Sheet1’)
#也可以直接利用:
frame = pd.read_excel(‘example/ex1.xlsx’, ‘Sheet1’)1.3mysql文件
读取mysql数据 Pandas读取mysql文件的格式:
pandas.read_sql(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None, columns=None, chunksize=None)
读取mysql数据示例
import pymysql con =pymysql.connect( host=‘localhost’,user=‘root’,password=‘root’,database=‘test’,port=3306,charset=‘utf8’)
sql_select = ‘select * from a’
df = pd.read_sql(sql_select, con)1.4json文件
读取json数据
Json是一种常用的数据交换格式,在前后端的交互中经常用到,也会在存储的时候选择这种格式。
Pandas读取Json数据的格式:
pandas.read_json(path_or_buf=None,orient=None,type=’frame’,lines=False, ...)1.查询数据
在pandas中,可以使用以下方法查找数据:
(1)使用索引或标签选择行和列:
df.loc[row_indexer, column_indexer] # 使用标签选择数据
df.iloc[row_indexer, column_indexer] # 使用整数索引选择数据
(2)使用布尔索引进行筛选:
df[df['column_name'] == value] # 根据某一列的值进行筛选
df[(df['column_name1'] == value1) & (df['column_name2'] > value2)] # 复杂条件的筛选
(3)使用isin()方法进行多值筛选:
df[df['column_name'].isin([value1, value2, ...])]
(4)使用查询(query)方法进行高级筛选:
df.query('column_name1 == value1 and column_name2 > value2')
(5)使用比较运算符进行条件筛选:
df[df['column_name'] > value] # 大于某个值
df[df['column_name'].between(value1, value2)] # 在某个范围内
(6)使用字符串方法进行匹配:
df[df['column_name'].str.contains('substring')] # 包含某个字符串
df[df['column_name'].str.startswith('substring')] # 以某个字符串开头
df[df['column_name'].str.endswith('substring')] # 以某个字符串结尾
这些方法可以根据不同的需求选择和组合使用,以实现对数据框中特定数据的查找和筛选。
import numpy as np
import pandas as pd
d=[[2.0,1.4,5, 4], [1, 0, 2, 4], [5,2, 3.0,7],[3, 1,0,11]]
df = pd. DataFrame (d, index=['a', 'b', 'c', 'd'], columns=['A', 'B', 'C', 'D'])
print(df)
print(df['A']) #单列数据访问
print(df[['A','C']]) # 多列数据访问
print(df.head(4)) # 访问某几行数据
print(df.tail(1))
print(df.iloc[0, 0])# 按照行列顺序进行数据访问
print(df.iloc[0:3,0])
print(df.iloc[:,0])
print(df.iloc[0,:])
print(df.iloc[1:3,1:3])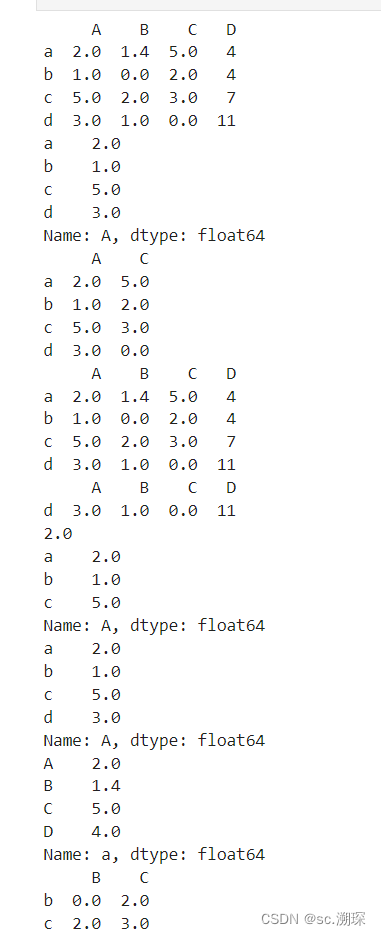
2.删除某列或某行
| 参数名称 | 说明 |
| labels | 代表删除行或列的标签。无默认值 |
| axis | 代表轴向。默认为0 |
| levels | 代表标签所在级别,默认为none |
| inplace | 代表是对对原数据生效,默认false |
在pandas中,可以使用以下方法删除某列或某行:
(1)删除某列:
df.drop('column_name', axis=1, inplace=True)
其中,'column_name'为要删除的列名,axis=1表示按列操作,inplace=True表示在原始数据上进行修改。
(2)删除某行:
df.drop(row_index, axis=0, inplace=True)
其中,row_index为要删除的行索引,axis=0表示按行操作,inplace=True表示在原始数据上进行修改。
注意:使用inplace=True会直接修改原始数据,若不想修改原始数据,可以将inplace参数设置为False,例如:
df_new = df.drop('column_name', axis=1, inplace=False)
这样会返回一个新的数据框df_new,而原始数据df不会被修改。
另外,还可以使用以下方法删除多列或多行:
(3)删除多列:
columns_to_drop = ['column_name1', 'column_name2', ...]
df.drop(columns_to_drop, axis=1, inplace=True)
(4)删除多行:
rows_to_drop = [row_index1, row_index2, ...]
df.drop(rows_to_drop, axis=0, inplace=True)
以上方法可以根据实际需求选择和组合使用,以达到删除某列或某行的目的。
3.数据描述性统计
| 函数名称 | 说明 |
| np.min | 最小值 |
| np.max | 最大值 |
| np.mean | 均值 |
| np.ptp | 极差 |
| np.median | 中位数 |
| np.std | 标准差 |
| np.var | 方差 |
| np.cov | 协方差 |
下面是一些使用numpy和pandas进行数据描述性统计的例子:
使用numpy计算数据描述性统计:
import numpy as np
# 创建一个示例数组
arr = np.array([1, 2, 3, 4, 5])
# 计算最小值
min_value = np.min(arr)
print("最小值:", min_value)
# 计算最大值
max_value = np.max(arr)
print("最大值:", max_value)
# 计算极差
ptp_value = np.ptp(arr)
print("极差:", ptp_value)
# 计算均值
mean_value = np.mean(arr)
print("均值:", mean_value)
# 计算中位数
median_value = np.median(arr)
print("中位数:", median_value)
# 计算标准差
std_value = np.std(arr)
print("标准差:", std_value)
# 计算方差
var_value = np.var(arr)
print("方差:", var_value)
使用pandas计算数据描述性统计:
import pandas as pd
# 创建一个示例数据框
df = pd.DataFrame({'A': [1, 2, 3, 4, 5],
'B': [6, 7, 8, 9, 10]})
# 计算列的最小值
min_values = df.min()
print("列的最小值:\n", min_values)
# 计算列的最大值
max_values = df.max()
print("列的最大值:\n", max_values)
# 计算列的均值
mean_values = df.mean()
print("列的均值:\n", mean_values)
# 计算列的中位数
median_values = df.median()
print("列的中位数:\n", median_values)
# 计算列的标准差
std_values = df.std()
print("列的标准差:\n", std_values)
# 计算列的方差
var_values = df.var()
print("列的方差:\n", var_values)
4.转换与处理时间序列数据
在时间序列数据处理中,timestamp类型是pandas库中用于表示日期和时间的对象。timestamp类型是pandas中的一种特殊数据类型,它具有日期和时间的精度,并提供了一些方便的方法和属性来处理日期和时间。
使用pandas库,可以将字符串、整数、浮点数等类型的数据转换为timestamp类型,可以使用to_datetime()函数来实现。以下是一些示例代码:
import pandas as pd
# 将字符串转换为timestamp类型
date_str = '2021-01-01'
timestamp = pd.to_datetime(date_str)
print(timestamp)
# 输出:2021-01-01 00:00:00
# 将整数/浮点数转换为timestamp类型
timestamp_int = pd.to_datetime(20210101, format='%Y%m%d')
timestamp_float = pd.to_datetime(2021.0101, format='%Y.%m%d')
print(timestamp_int)
print(timestamp_float)
# 输出:2021-01-01 00:00:00
# 输出:2021-01-01 00:00:00
一旦数据被转换为timestamp类型,就可以对其进行各种日期和时间操作。一些常见的timestamp对象的属性和方法包括:
.year: 获取年份.month: 获取月份.day: 获取天数.hour: 获取小时.minute: 获取分钟.second: 获取秒数.weekday(): 获取星期几(0-6,0代表星期一).date(): 获取日期部分.time(): 获取时间部分
例如,假设有一个timestamp对象ts,我们可以使用以下代码提取其年份和月份:
year = ts.year
month = ts.month
timestamp类型还可以进行比较、计算时间差等操作。例如,计算两个时间点之间的时间差:
diff = ts2 - ts1
DatetimeIndex和PeriodIndex是pandas库中用于处理时间序列数据的两种索引类型。它们能够以更加便捷的方式对时间序列数据进行索引、切片、过滤等操作。
DatetimeIndex适用于具有时间精度的时间序列数据,可以精确到年、月、日、小时、分、秒等级别。PeriodIndex适用于以固定时间间隔(例如月、季度、年等)为单位的时间序列数据。
下面分别介绍DatetimeIndex和PeriodIndex的主要特点和使用方法:
DatetimeIndex(日期时间索引)
- 可以通过
pd.to_datetime()函数将字符串或其他类型的数据转换为DatetimeIndex类型。 - 可以使用
pd.date_range()函数生成一系列连续的日期时间索引,可以指定起始日期、结束日期、日期频率等参数。 - 可以使用
DatetimeIndex对象的属性和方法对日期时间索引进行各种操作,如提取年、月、日、小时、分钟等。 - 可以根据日期时间索引对时间序列数据进行索引、切片、过滤等操作,例如通过
df.loc[start:end]进行日期范围内的数据选择。
示例代码:
import pandas as pd
# 将数据转换为DatetimeIndex类型
date_str = ['2021-01-01', '2021-01-02', '2021-01-03']
datetime_index = pd.to_datetime(date_str)
print(datetime_index)
# 输出: DatetimeIndex(['2021-01-01', '2021-01-02', '2021-01-03'], dtype='datetime64[ns]', freq=None)
# 生成一系列连续的日期时间索引
datetime_range = pd.date_range(start='2021-01-01', end='2021-01-10', freq='D')
print(datetime_range)
# 输出: DatetimeIndex(['2021-01-01', '2021-01-02', '2021-01-03', '2021-01-04', '2021-01-05', '2021-01-06', '2021-01-07', '2021-01-08', '2021-01-09', '2021-01-10'], dtype='datetime64[ns]', freq='D')
# 对日期时间索引进行操作
year = datetime_index.year
month = datetime_index.month
day = datetime_index.day
print(year)
print(month)
print(day)
# 输出: [2021 2021 2021]
# 输出: [1 1 1]
# 输出: [1 2 3]
# 对时间序列数据进行索引、切片
data = [1, 2, 3]
df = pd.DataFrame(data, index=datetime_range, columns=['value'])
print(df.loc['2021-01-02':'2021-01-05'])
# 输出:
# value
# 2021-01-02 2
# 2021-01-03 3
# 2021-01-04 4
# 2021-01-05 5
PeriodIndex(周期索引)
- 可以通过
pd.Period()函数将数据转换为PeriodIndex类型,可以指定时间间隔的频率。 - 可以使用
pd.period_range()函数生成一系列具有固定时间间隔的周期索引,可以指定起始周期、结束周期、周期频率等参数。 - 可以使用
PeriodIndex对象的属性和方法对周期索引进行各种操作,如提取年、季度、月等。 - 可以根据周期索引对时间序列数据进行索引、切片、过滤等操作,例如通过
df.loc[start:end]进行周期范围内的数据选择。
示例代码:
import pandas as pd
# 将数据转换为PeriodIndex类型
period_index = pd.Period('2021-01', freq='M')
print(period_index)
# 输出: Period('2021-01', 'M')
# 生成一系列具有固定时间间隔的周期索引
period_range = pd.period_range(start='2021-01', end='2021-12', freq='M')
print(period_range)
# 输出: PeriodIndex(['2021-01', '2021-02', '2021-03', '2021-04', '2021-05', '2021-06', '2021-07', '2021-08', '2021-09', '2021-10', '2021-11', '2021-12'], dtype='period[M]', freq='M')
# 对周期索引进行操作
year = period_index.year
month = period_index.month
print(year)
print(month)
# 输出: 2021
# 输出: 1
# 对时间序列数据进行索引、切片
data = [1, 2, 3]
df = pd.DataFrame(data, index=period_range, columns=['value'])
print(df.loc['2021-02':'2021-05'])
# 输出:
# value
# 2021-02 2
# 2021-03 3
# 2021-04 4
# 2021-05 5
以上是关于DatetimeIndex和PeriodIndex的简要说明和示例代码,它们是pandas库中常用的时间序列索引类型,可以方便地进行时间序列数据的处理和分析。
5.分组聚合进行计算
DataFrame.groupby(by=None,axis=0, level=None, as_index=True, sort=True, group_keys=True,squeeze=False,**kwargs)
下面是各个参数的解释:
by:指定数据的分组条件,可以是列名、列名列表、字典、函数或它们的组合。
axis:确定是沿着行(axis=0)还是列(axis=1)进行分组。
level:在处理多层次索引时使用,指定进行分组操作的级别。
as_index:确定分组后的列是否作为结果DataFrame的索引。默认为True,表示分组列变为索引的一部分。如果设置为False,则分组列将保留为普通列。
sort:确定分组后的结果是否按照分组列的值进行排序。默认为True。
group_keys:确定是否在结果DataFrame中包含分组键。如果设置为True,则包含键。如果设置为False,则不包含键。
squeeze:确定分组数据的格式。如果设置为True,则单个组在可能的情况下返回为Series而不是DataFrame。默认为False。
**kwargs:可以传递额外的关键字参数给groupby操作。这些参数可以用来指定特定聚合函数的额外选项或参数。
这些参数允许您自定义groupby操作的行为,控制数据如何分成组。
groupby方法的by参数可接受多种不同的值,用于指定根据哪些列或索引来分组数据。下面是一些常用的by参数的介绍:
- 单个列名:可以传递一个列名作为
by参数,表示按照该列的值对数据进行分组。
df.groupby(by='column_name')
- 多个列名:可以传递一个包含多个列名的列表作为
by参数,表示按照这些列的值对数据进行分组。数据将首先按照第一个列进行分组,然后再按照第二个列进行分组,以此类推。
df.groupby(by=['column_name1', 'column_name2'])
- 函数:可以传递一个函数作为
by参数,函数会应用到每个索引或列上,返回的结果将用于分组数据。
df.groupby(by=lambda x: x.year)
- 多个函数:可以传递一个包含多个函数的列表作为
by参数,每个函数会分别应用到每个索引或列上,返回的结果将用于分组数据。
df.groupby(by=[lambda x: x.year, lambda x: x.month])
- 字典:可以传递一个字典作为
by参数,字典的键表示要分组的列名或索引,字典的值表示该列或索引对应的分组名。
df.groupby(by={'column_name1': 'group_name1', 'column_name2': 'group_name2'})
除了上述常用的by参数之外,groupby方法还可以根据索引级别(多级索引)进行分组,使用level参数指定要分组的级别。
注意,在使用groupby方法时,可以与其他聚合函数(如agg、sum、mean等)结合使用,以对每个分组进行各种操作。
groupby方法用于按照指定的列或多列对数据进行分组。使用groupby方法之后,可以对每个分组进行各种操作,如求和、计数、平均值等。
下面是groupby方法的基本语法:
groupby对象常用的描述统计方法有:
count():计算每个分组中的非缺失值的数量。
sum():计算每个分组中的数值之和。
mean():计算每个分组中数值的平均值。
median():计算每个分组中数值的中位数。
min():计算每个分组中数值的最小值。
max():计算每个分组中数值的最大值。
std():计算每个分组中数值的标准差。
var():计算每个分组中数值的方差。
quantile():计算每个分组中数值的分位数。
first():返回每个分组中的第一个非缺失值。
last():返回每个分组中的最后一个非缺失值。
这些方法可以应用于groupby对象来计算每个分组的统计数据。您可以根据需求选择适合的方法进行分析和计算。
grouped = df.groupby(by=[列1, 列2, ...])
其中,df是DataFrame数据,by参数是用于分组的列名或列名的列表。
例如,如果我们有一个名为df的DataFrame,它包含了以下数据:
A B C
0 a 1 0
1 a 2 1
2 b 3 2
3 b 4 3
4 c 5 4
5 c 6 5
我们可以按列A进行分组,并对列B进行求和和列C进行计数:
grouped = df.groupby(by='A')
result = grouped.agg({'B': 'sum', 'C': 'count'}).rename(columns={'B': 'Sum_B', 'C': 'Count_C'})
结果如下:
Sum_B Count_C
A
a 3 2
b 7 2
c 11 2
在上面的例子中,我们首先使用groupby方法按列A进行分组,然后使用agg方法对每个分组进行聚合操作。agg方法接受一个字典,其中键表示要聚合的列,值表示要应用的聚合函数。最后,我们使用rename方法为聚合结果的列重新命名。
注意,groupby方法返回一个GroupBy对象,我们可以在该对象上使用各种聚合函数进行操作。最后,通过使用agg方法进行聚合,并使用rename方法为结果列重命名。
import pandas as pd
# 创建一个DataFrame
data = {
'Group': ['A', 'A', 'B', 'B', 'A', 'B'],
'Value': [10, 20, 30, 40, 50, 60]
}
df = pd.DataFrame(data)
# 使用groupby进行分组
grouped = df.groupby('Group')
# 计算每个分组中的数值之和
sum_values = grouped['Value'].sum()
print(sum_values)
# 输出:
# Group
# A 80
# B 130
# Name: Value, dtype: int64
# 计算每个分组中数值的平均值
avg_values = grouped['Value'].mean()
print(avg_values)
# 输出:
# Group
# A 26.666667
# B 43.333333
# Name: Value, dtype: float64
# 计算每个分组中的最小值和最大值
min_values = grouped['Value'].min()
max_values = grouped['Value'].max()
print(min_values)
print(max_values)
# 输出:
# Group
# A 10
# B 30
# Name: Value, dtype: int64
# Group
# A 50
# B 60
# Name: Value, dtype: int64
在上面的例子中,我们首先创建一个包含分组列和数值列的DataFrame。然后使用groupby方法根据分组列进行分组。然后,我们使用groupby对象的描述统计方法,如sum()、mean()、min()、max()等,对每个分组的数值列进行计算。最后,我们打印出计算结果。
6.agg方法聚合数据
agg方法可以用于聚合数据,即根据特定的条件对数据进行汇总和计算。agg方法常用于Pandas库中的DataFrame对象上,具体用法如下:
DataFrame.agg(func, axis=0, *args, **kwargs)
参数说明:
- func:要应用于数据的聚合函数或函数列表。可以是内置的聚合函数(如'mean'、'sum'、'max'等),也可以是自定义的聚合函数。如果是函数列表,则会将每个函数应用于数据。
- axis:指定要应用聚合函数的轴。默认为0,表示按列进行聚合;1表示按行进行聚合。
- args和kwargs:传递给聚合函数的其他参数。
示例代码:
import pandas as pd
data = {'A': [1, 2, 3, 4, 5], 'B': [6, 7, 8, 9, 10], 'C': [11, 12, 13, 14, 15]}
df = pd.DataFrame(data)
result = df.agg(['mean', 'max'])
print(result)
# A B C
# mean 3.0 8.0 13.0
# max 5.0 10.0 15.0上述示例中,对DataFrame对象df使用agg方法,计算了每一列的平均值和最大值。agg方法返回一个新的DataFrame对象,其中每一行代表一个聚合函数,每一列代表原始DataFrame中的一个列。
7.合并数据
在Pandas中,可以使用merge、concat和join等方法来合并数据。下面是这些方法的用法示例:
- 使用merge方法合并数据:
import pandas as pd
# 创建两个DataFrame对象
data1 = {'A': [1, 2, 3],
'B': ['a', 'b', 'c']}
df1 = pd.DataFrame(data1)
data2 = {'A': [4, 5, 6],
'B': ['d', 'e', 'f']}
df2 = pd.DataFrame(data2)
# 使用merge方法合并两个DataFrame
merged_df = pd.merge(df1, df2, on='A')
print(merged_df)
上述示例中,我们创建了两个DataFrame对象df1和df2,然后使用merge方法在列'A'上合并这两个DataFrame。合并后的结果将根据列'A'中的相同值进行匹配。
- 使用concat方法按行或列合并数据:
import pandas as pd
# 创建两个DataFrame对象
data1 = {'A': [1, 2, 3],
'B': ['a', 'b', 'c']}
df1 = pd.DataFrame(data1)
data2 = {'A': [4, 5, 6],
'B': ['d', 'e', 'f']}
df2 = pd.DataFrame(data2)
# 按行合并两个DataFrame
concatenated_df = pd.concat([df1, df2])
print(concatenated_df)
# 按列合并两个DataFrame
concatenated_df = pd.concat([df1, df2], axis=1)
print(concatenated_df)
上述示例中,我们创建了两个DataFrame对象df1和df2,并使用concat方法按行合并这两个DataFrame(将它们堆叠在一起)。另外还展示了如何按列合并DataFrame。
- 使用join方法根据索引合并数据:
import pandas as pd
# 创建两个DataFrame对象
data1 = {'A': [1, 2, 3],
'B': ['a', 'b', 'c']}
df1 = pd.DataFrame(data1, index=['x', 'y', 'z'])
data2 = {'C': ['d', 'e'],
'D': [4, 5]}
df2 = pd.DataFrame(data2, index=['y', 'z'])
# 根据索引合并两个DataFrame
joined_df = df1.join(df2)
print(joined_df)
上述示例中,我们创建了两个DataFrame对象df1和df2,并使用join方法根据索引合并这两个DataFrame。合并后的结果将基于索引值进行匹配。
以上是常用的合并数据的方法示例,具体选择哪种方法取决于数据的结构和合并需求。
8.清洗数据
在Pandas中,清洗数据是指对数据进行预处理和转换,以便更好地进行分析和建模。下面是一些常用的数据清洗方法:
- 去除重复值:使用drop_duplicates()方法去除DataFrame中的重复行。可以指定某些列来判断重复值。
df.drop_duplicates(subset=['col1', 'col2'], keep='first', inplace=True)
- 处理缺失值:使用fillna()方法填充缺失值,可以选择使用某个常数值、前一个值或后一个值来填充。
df.fillna(value=0) # 使用常数值填充缺失值
df.fillna(method='ffill') # 使用前一个值填充缺失值
df.fillna(method='bfill') # 使用后一个值填充缺失值
- 删除缺失值:使用dropna()方法删除包含缺失值的行或列。
df.dropna() # 删除包含缺失值的行
df.dropna(axis=1) # 删除包含缺失值的列
- 处理异常值:可以使用条件判断和过滤方法来处理异常值。
df = df[df['col'] > 0] # 过滤出大于0的值
df = df[(df['col'] > lower_bound) & (df['col'] < upper_bound)] # 过滤出位于范围内的值
- 数据类型转换:使用astype()方法将数据类型转换为其他类型。
df['col'] = df['col'].astype(int) # 将某列的数据类型转换为整数
- 重命名列名:使用rename()方法重命名DataFrame的列名。
df.rename(columns={'old_col': 'new_col'}, inplace=True) # 将某列的列名更改为新的列名
- 数据归一化或标准化:使用MinMaxScaler或StandardScaler来对数据进行归一化或标准化。
from sklearn.preprocessing import MinMaxScaler, StandardScaler
scaler = MinMaxScaler()
normalized_data = scaler.fit_transform(df)
scaler = StandardScaler()
standardized_data = scaler.fit_transform(df)
以上是一些常用的数据清洗方法,具体选择哪种方法取决于数据的特征和清洗要求。
9.监测与清洗异常值
在Pandas中,可以使用以下方法检查和清洗异常值:
- 查找异常值:使用describe()方法查看数据的统计摘要,包括均值、标准差、最小值、最大值等。根据这些摘要统计信息,可以初步识别出潜在的异常值。
df.describe()
- 绘制箱线图:使用boxplot()方法绘制箱线图,可以直观地显示数据的分布情况和异常值。
import matplotlib.pyplot as plt
df.boxplot(column='col')
plt.show()
- 使用条件判断和过滤方法:可以使用条件判断和过滤方法来识别和过滤掉异常值。
df = df[df['col'] > lower_bound] # 过滤掉小于下界的值
df = df[df['col'] < upper_bound] # 过滤掉大于上界的值
1.在Pandas中,isnull()和notnull()是两个常用的方法,用于检查数据中的缺失值。
- isnull()方法会返回一个布尔型的DataFrame或Series,其中缺失值位置为True,非缺失值位置为False。
df.isnull() # 返回一个布尔型的DataFrame,显示每个元素是否为缺失值
- notnull()方法会返回一个布尔型的DataFrame或Series,其中缺失值位置为False,非缺失值位置为True。
df.notnull() # 返回一个布尔型的DataFrame,显示每个元素是否为非缺失值
这两个方法可以用于各种数据类型,包括DataFrame和Series。
示例:
# 创建一个含有缺失值的DataFrame
import pandas as pd
import numpy as np
data = {'A': [1, np.nan, 3, 4],
'B': [5, 6, np.nan, 8],
'C': [9, 10, 11, 12]}
df = pd.DataFrame(data)
# 检查DataFrame中的缺失值
print(df.isnull())
print(df.notnull())
A B C
0 False False False
1 True False False
2 False True False
3 False False False
A B C
0 True True True
1 False True True
2 True False True
3 False True True
可以根据返回的布尔值DataFrame进行进一步的处理,例如删除含有缺失值的行或列,或者使用fillna()方法填充缺失值。
- 替换异常值:可以使用fillna()方法将异常值替换为指定的值。
df['col'] = df['col'].fillna(value=replace_value) # 将某列的异常值替换为指定的值
- 删除异常值:可以使用drop()方法删除包含异常值的行。
df.drop(df[df['col'] < lower_bound].index, inplace=True) # 删除小于下界的行
df.drop(df[df['col'] > upper_bound].index, inplace=True) # 删除大于上界的行
- 使用统计方法:可以使用z-score或IQR方法来检测和处理异常值。
from scipy import stats
z_scores = stats.zscore(df['col'])
df = df[(z_scores < threshold) & (z_scores > -threshold)] # 过滤掉z-score超过阈值的值
Q1 = df['col'].quantile(0.25)
Q3 = df['col'].quantile(0.75)
IQR = Q3 - Q1
df = df[(df['col'] >= Q1 - 1.5 * IQR) & (df['col'] <= Q3 + 1.5 * IQR)] # 过滤掉位于IQR范围之外的值
总结:
- 查找异常值:
- 使用describe()方法查看数值型数据的统计信息,包括均值、标准差、最小值、最大值等。
- 使用boxplot()方法绘制箱线图,查看数据的分布情况和异常值。
- 使用quantile()方法计算分位数,检测是否存在超出上下四分位距1.5倍的异常值。
# 查看数值型数据的统计信息
df.describe()
# 绘制箱线图
df.boxplot()
# 计算分位数
q1 = df['col'].quantile(0.25)
q3 = df['col'].quantile(0.75)
iqr = q3 - q1
lower_bound = q1 - 1.5 * iqr
upper_bound = q3 + 1.5 * iqr
- 处理异常值:
- 使用条件判断和过滤方法来筛选出异常值所在的行。
- 使用fillna()方法将异常值替换为其他值,如中位数或均值。
- 使用drop()方法删除包含异常值的行。
# 筛选出异常值所在的行
df_outliers = df[(df['col'] < lower_bound) | (df['col'] > upper_bound)]
# 将异常值替换为中位数
df['col'] = df['col'].apply(lambda x: df['col'].median() if x < lower_bound or x > upper_bound else x)
# 删除包含异常值的行
df = df[(df['col'] >= lower_bound) & (df['col'] <= upper_bound)]
10.离散值
import pandas as pd
# 创建一个包含连续数据的Series
data = pd.Series([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
categories = pd.cut(data, 5)
# 查看离散化后的数据
print(categories)
# 0 (0.991, 2.8]
# 1 (0.991, 2.8]
# 2 (2.8, 4.6]
# 3 (2.8, 4.6]
# 4 (4.6, 6.4]
# 5 (4.6, 6.4]
# 6 (6.4, 8.2]
# 7 (6.4, 8.2]
# 8 (8.2, 10.0]
# 9 (8.2, 10.0]
# dtype: category
# Categories (5, interval[float64, right]): [(0.991, 2.8] < (2.8, 4.6] < (4.6, 6.4] < (6.4, 8.2] < (8.2, 10.0]]import pandas as pd
# 创建一个包含连续数据的Series
data = pd.Series([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
# 将数据离散化为3个区间
bins = [0, 5, 8, 10]
labels = ['Low', 'Medium', 'High']
categories = pd.cut(data, bins=bins, labels=labels)
# 查看离散化后的数据
print(categories)
# 0 Low
# 1 Low
# 2 Low
# 3 Low
# 4 Low
# 5 Medium
# 6 Medium
# 7 Medium
# 8 High
# 9 High
# dtype: category
# Categories (3, object): ['Low' < 'Medium' < 'High']














 1760
1760

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









