






前言
无论是以极高新闻刷新频率闻名的今日头条,还是全民短视频软件抖音,它们的成功都离不开一个能让用户沉迷于其中的推荐算法。
一个好的推荐算法,能让平台生产的内容精准地发送到每个用户群体的手里,从而加强了平台用户的黏性,使用户的长期价值得以体现。
本篇所涉及到的算法UserCF,全名叫做基于用户的协同过滤(User-Based Collaborative Filtering),这是一个相当传统的推荐算法,可作为入门级推荐算法来学习。
UserCF流程
基于用户的协同过滤的核心思想是找出与目标用户兴趣相似的其他用户,然后根据这些相似用户的喜好,来推荐物品给目标用户。
以电商平台推荐算法为例,其大致步骤如下:
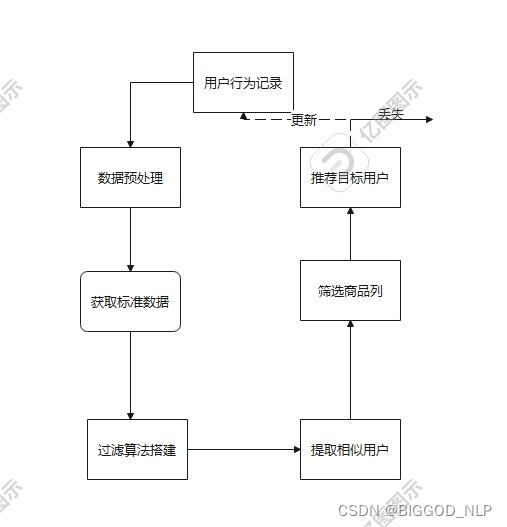
一、用户行为记录
电商平台用户的消费记录、商品页面停留时间、收藏店铺等数据,新闻平台用户观看不同主题的新闻在其用户画像的占比,短视频平台用户观看一个视频的完播率,都可算作是用户的行为记录。
用户行为记录是最原始的记录,它必须要有两个部分。
其一:用户的身份识别列,如 ID名,账号,登录IP地址等。
其二:能够对该用户兴趣内容做出识别的数据特征
二、数据预处理
所有从业务场景获取的数据都不是处理好的数据,我们需要对获取的数据进行一个预先处理。
除了数据格式转换、缺失值处理等传统流程,我们还需要根据我们采取的推荐算法类型,将业务数据转化成对应的数据范式。
三、标准数据
标准数据,就是上述数据预处理后得到的数据。
在大部分的推荐算法中,标准数据大多都是以下这种:
| 用户A | (商品1,得分1),(商品2,得分2),(商品3,得分3) |
| 用户B | (商品2,得分4),(商品5,商品5),(商品6,得分6) |
| 用户C | (商品1,得分7),(商品6,得分8) |
| ....... | (................................) |
第一列为用户ID。
第二类为一个又一个元组,每个元组的元素相同,前者为某个商品,后者为反应用户感兴趣程度的得分。
以A用户为例,如果得分1越大,那就说明A对商品的兴趣程度就越强,其购买欲望也就越大。
对同种商品,用户A和用户B可能会有两个不同得分,也就是说,用户A对该商品的兴趣程度不如或者强过用户B对改商品的兴趣程度。
其他同理。
要想将业务数据转化为如上图所示的标准数据,需要在数据处理上费一定功夫。
一般可以采用的方法有:
1、根据经验建模:
在电商分析环境中,我们常认为用户浏览商品时间久、下单到付款的时间短,加入了收藏等行为,是用户机器感兴趣的体现,那么,我们可以将每个行为量化,从1-10为该用户在各个行为上打分,如购买了该商品是强兴趣体现,则设为10,投诉了该商品则是弱兴趣体现,则设为1。最后,通过简单加总、加权加总等计算,获得每个商品的最终评分。
2、有监督的机器学习:
这一方法的本质,依然是根据经验建模,只不过前期的工作量将大大减小。一种较为可行的方法是,我们直接通过问卷调查的形式,让用户写下感兴趣的商品和不感兴趣的商品,并对自己的选择做出打分,获得如下结构的数据:
| 用户 | 商品1 | 商品2 | 商品3 | 商品4 |
| 用户1 | 2 | 3 | 4 | 5 |
| 用户2 | 3 | 5 | 1 | 0 |
这样取得的数据其优势在于能直接反应用户的喜好程度,而不取决于分析人员的主观判断。
将这些数据设为数据标签,应用有监督的机器学习法在每个用户每个商品的用户行为记录上进行训练,从而获得可以自动评分的机器学习模型。
训练集格式应大体如下:
| 序号 | 最长浏览时长min | 搜索次数 | 是否收藏 | 是否购买 | 回购次数 | ........ | 喜好程度 |
| 1 | 8 | 20 | False | True | 1 | ........ | 3 |
| 2 | 60 | 3 | True | False | 0 | ........ | 2 |
| 3 | 180 | 51 | True | True | 5 | ........ | 5 |
3、无监督的机器学习:
无监督的机器学习直接省去了对数据的人工标注,它不需要人为的告诉计算机要识别什么,而是让计算机自我学习、调整,挖掘数据本身内在的价值。
在电商领,尤其是618、双11等电商活动日,动辄每天上千万单商品交易成单量,如果通过数据标注+机器学习的方式来进行分析,工作量将十分地大。
但通过无监督的机器学习方式,却能极大地节省时间、物力、人力。
这里推荐一个2015年阿里推出的深度兴趣网络DIN,它是神经网络和自注意力机制的结合,实现了根据用户的不同行为对商品的喜好程度自适应调整权重。
相关链接: 深度兴趣网络![]() https://www.cnblogs.com/bonelee/p/18140982
https://www.cnblogs.com/bonelee/p/18140982
四、过滤算法与筛选商品列
过滤算法,顾名思义,是根据特定规则或条件对数据进行筛选和提取的过程。
把该用户没体验过,却可能存在潜在兴趣的商品从数据中提取出来,这就是过滤算法的意义。
常用算法通常有两种:
关联规则分析
聚类分析
都是些很基础的分类方法,这里不再赘述。
除此之外我们还可以通过一系列相似度计算公式作为辅助,粗略估计每个用户之间的相似性。
以用户-商品得分数据为例:
| 用户 | 商品1 | 商品2 | 商品3 | 商品4 |
| 用户1 | 2 | 3 | 4 | 5 |
| 用户2 | 3 | 5 | 1 | 0 |
对该数据集,可用的相似度计算公式有:
余弦相似度:将用户每个商品的得分映射到高维坐标系的每个坐标系上,所有坐标只确定一个点,这个点就是用户A在高位坐标系中的位置,将它和原点连接,则形成了一个高维向量。
这个高维向量有两个要素。
长度代表的是用户对所有商品的综合喜好程度,通俗来讲,就是你喜欢的所有商品都放在一起捆绑销售,你购买的欲望。
方向代表的是用户的个人喜好倾向,比方说,你既喜欢打篮球,又喜欢唱歌、跳舞,三者的共同结果是你越来越喜欢发展才艺,向量方向就是指代了这种偏好趋势。
余弦相似度即是求不同用户向量之间的方向是否一致,余弦相似度越接近于1,则表明两个用户喜好的趋势是越来越接近的。
下面是余弦相似度的计算图例:

cosθ=A*B/||A||*||B||
获得的数据格式应如下:
| 用户 | A | B | C | D | E | F |
| A | 1 | 0.376 | 0.754 | 0.434 | 0.155 | 0.248 |
| B | 0.376 | 1 | 0.331 | 0.823 | 0.765 | 0.442 |
| C | 0.754 | 0.311 | 1 | 0.654 | 0.452 | 0.901 |
| D | 0.434 | 0.823 | 0.654 | 1 | 0.345 | 0.248 |
| E | 0.155 | 0.765 | 0.452 | 0.345 | 1 | 0.743 |
| F | 0.248 | 0.442 | 0.901 | 0.248 | 0.743 | 1 |
杰卡德相似系数:把一个个用户对喜好商品的选择视作集合,杰卡德系数就等于两个集合交集的个数和并集个数的比值。
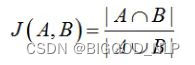
杰卡德系数的思想很简单,假设有两个集合,它们的交集个数为N,不交集个数为M,那么总集(并集)个数就为N+M,杰尔德相似系数就可以写成N/N+M。
为什么该式子能反映两个集合的相似度。
我们可以举个例子。
假设有两家饭店,我们想知道它们主打的菜品是否有相似性,可以每一家都点上一百次,每一次都是随机点餐一样菜品,然后看他们共同出现过菜品的次数。
在一定的取样次数下,共同菜品出现的次数越多,则说明两家店铺主打的菜品赛道则越趋于一致,消费者既可以选择在A家店吃,也可以在B家店吃,因为它们提供的菜品大致相同。
而随着取样次数趋近于无穷,共同菜品出现的频率P,就等于N/N+M。
所以,N/N+M越大,相同元素出现的概率也就越大,则意味着两个集合具有高度的相似性。
之所以不列举其他算法,是因为笔者认为,在UserCF算法的实现中,更关键的一步其实是量化用户之间的相关性,只要这一点做的足够好,上述两种算法就足以应对绝大部分的推荐场景。
这里给出一个改进的聚类分析算法。
我们知道,商品与商品本身就存在一定的关联,这种关联常常出现在一定的语境当中。
例如:今天我打了一场篮球赛,回家的路上买了一瓶可乐解渴。
篮球和可乐,在打篮球这个行为中就是强相关。
再比如一个爱打扮的女生,手里不可能只有一个化妆品,除了粉底液,还有口红、修眉刀等,它们之间的联系可以通过某种形式表示出来,即:在特定语境下的上下文关系。
因此,当我们获得商品-用户数据集的时候,可以做如下处理:
1、将商品序列视作词的序列,然后加入到bert模型中获取词向量表示,这种表示能很好地保留词在文本中的上下文关系,从而建立起商品与商品之间在特定场景下的相关度。
2、对获得的向量序列进行因子分析,提取出潜在的隐形特征,这种隐形特征能较好地反应出不同用户在不同消费场景下的需求。
3、对经过上述处理的数据进行聚类分析,对同一簇的商品列进行汇总,作为该群体推荐时的候选商品列
五、推荐目标用户与更新、丢失操作
将上述对应簇的商品列表进行提取,推荐给在该簇中的目标用户,从而获得新的用户行为记录。
新的用户记录可以直接加到用户行为记录数据当中,重新进入UserCF流程,以此循环直至找到最优解。
与此同时,我们也可以对该用户行为记录进行进一步分析,直接对商品列进行更新与丢失操作。
对于后者,我们常用的方法是强化学习。
强化学习通过智能体与环境的交互形成的反馈来调整自己的策略,以获得更高的累计奖励。
我们依然可以举一个简单的例子。
摆在你面前的是十台老虎机,每一个老虎机出奖概率、每次出奖金额都不一样,你事先不知道哪个老虎机能给你带来最大收益,但是你现在有10000块钱,你该怎么做?
最简单的方法,就是去试。
每一个老虎机都先投一遍,每次投的金额都是20,看看每个老虎机能带给你带来什么收益。
| 1号 | 2号 | 3号 | 4号 | 5号 | 6号 | 7号 | 8号 | 9号 | 10号 |
| 20 | 30 | 18 | 5 | 0 | 47 | 41 | 10 | 13 | 9 |
我们可以看到,1号、2号、6号、7号老虎机是赚钱的,3号、4号、5号、8号、9号、10号是不赚钱的。
根据环境反馈的结果,我们需要对自己的投钱策略做出相应的调整。
1、2、6、7号老虎机我们继续加大投钱金额,增加到100块,而3号、4号、5号、8号、9号、10号则减少投钱金额,减少到10块,尝试查看这次投钱策略能给你带来什么。
| 1号 | 2号 | 3号 | 4号 | 5号 | 6号 | 7号 | 8号 | 9号 | 10号 |
| 110 | 150 | 9 | 40 | 1 | 50 | 120 | 5 | 13 | 4 |
欸,这时赚钱的老虎机发生了变化,1、2、4、7、9是挣钱的,剩下的是不挣钱的。
与此同时,4号老虎机的收益虽然不多,但足足翻了四倍,我们可以重点关注4号老虎机的收益变化,给予它更多的测试机会。
通过上述的例子我们可以看到,强化学习的本质,就是预先设置一个策略,然后通过这个策略在环境中反馈得到的数据,进一步调整,从而获得新的策略。
如此循环,最后,我们将每次策略获得的奖励加总,使累计奖励最大化,这就是强化学习。
现在,我们回到UserCF。
我们已经得到了准备推荐的商品列,然后对每个对应簇的用户进行推送。
用户接收到商品的内容,并作出反馈。
通过用户的反馈数据,我们对具体的商品推荐进行一对一增加和删改,向同一簇具体的每个用户生成不同的候选商品列,从而形成个性化的推荐策略。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









