







文章目录
什么是协同过滤?
通常协同过滤中用得最多的就是userCF,和itemCF。
userCF
基于用户协同:本质就是找到与自己相同的用户,将相似用户有过行为的物品而我没有过行为的物品推荐给我。
itemCF
基于物品协同:本质是找到物品的相似物品,将我有过行为的物品的相似物品推荐给我。
所以本质上说,协同就是相似,是一个不断的在找相似的一个过程,既然是寻找相似,那自然要有一个标准来度量相似情况,通常有以下的集中相似描述的机制
在介绍相似的描述标准的时,要介绍以下用户物品打分矩阵。因为协同过滤是基于用户的评分矩阵计算相似度的。通常一个网站如果有打分机制的话,可以直接得到打分矩阵,但是一般情况下,这种显示的打分是不存在,
所以为了得到打分矩阵,通常会利用隐性的行为,比如:收藏、评论、分享、观看时长等等,通过这些行为,制定一个规则来间接得到打分矩阵。
有了用户的打分矩阵以后:
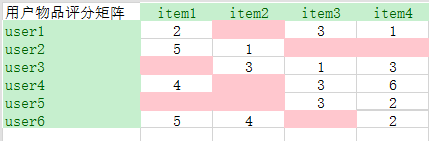
介绍衡量相似的衡量标准
1.欧几里得距离
闵可夫斯基距离公式
d
m
k
(
x
i
,
x
j
)
=
(
∑
u
=
1
n
∣
x
i
u
−
x
j
u
∣
p
)
1
p
d_{mk}(x_{i},x_{j})=\left ( \sum_{u=1}^{n} \left | x_{iu} -x_{ju} \right | ^{p} \right ) ^{\frac{1}{p} }
dmk(xi,xj)=(u=1∑n∣xiu−xju∣p)p1
欧几里得距离就是当闵可夫斯基距离中的p=2时。当p=1是曼哈顿距离
这种是直接计算出一个值来,缺点在于,计算出的值,并无一个范围限制,所以没法得出影响程度到底有多深,第二个是对于高维的向量,并不是很好用。
2.Jaccard系数
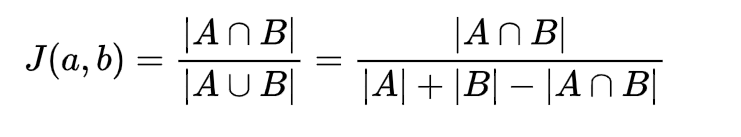
缺点,将所有打分看作是1,未打分的看作是0,完全忽略了打分大小的影响。
3.余弦相似度
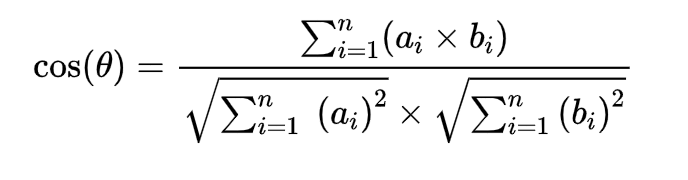
缺点:未考虑到数据分布不均的情况,比如5分制的打分,有些用户习惯打低分,比如就习惯打2分左右,但这也表示他对做的极大认可。有点习惯打高分的
不一定就是对作品的认可。
4.皮尔逊相关系数
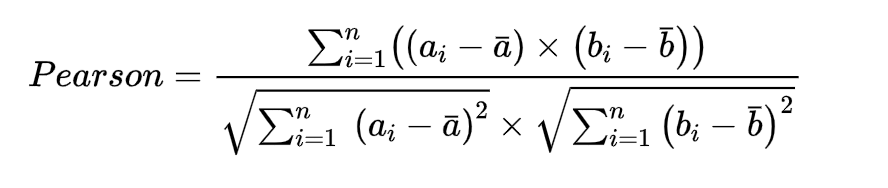
在余弦相似度的基础上,考虑到了数据分布不均的情况。更科学合理
综上,在计算协同的时候,可以根据业务选择不同的相似标准计算公式。
扩展:可以思考一下,以上的指标都是在描述两个用户之间的相似度或者是物品之间的相似度,是利用用户的行为矩阵中的行为向量进行计算的,那么其实以上的指标我认为一定程度上也可以作为数据挖掘或者是特征筛选过程中的指标,描述两个特征之间的相似度。
物品评分预测
有了相似度之后,就可以计算一个用户对 其他物品可能的打分情况,如下
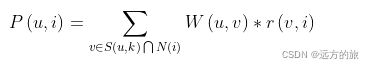
其中:
- P(u,i)表示用户u对第i个物品的可能性打分;
- W(u,u)表示两个用户之间的相似度,可以通过上一小结中的任何一种标准计算出来;
- r表示用户u的相似用户对物品i的打分情况;
- 上面公式还有一个S(u,K),表示的是在计算出用户的相似度后,最终只取其中的TopK,所有都取的话太大。
通过以上的公式就可以计算出用户u对之前没发生过打分行为的物品的预估打分,然后取TopK召回就可以了。
userCF、itemCF缺点
userCF
如果一个平台上,用户较少,产品比较多的情况下,这会导致用户的打分矩阵很稀疏,这种情况下,很难找到相似用户,自然很难推出东西。同时不能解决长尾问题,冷门的产品也很难推出来。
itemCF
这种无所谓物品的的多少,因为是推荐物品的相似物品,但是缺点在于会导致兴趣单一,容易信息茧房。
最重要的问题在于:
1.他们只利用到了用户的评分信息或者是行为信息,没有利用到用户的固有特征和物品的固有特征以及场景特征
2.很难处理稀疏问题
3.对于稀疏矩阵很难存储
针对以上的几个问题,在实际的工程中也尽量去解决。
实际工程应用中的问题
在实际的工程应用中,总是需要在理论的基础上进行改进
问题1:用户评分矩阵过大问题
类比于像头条这样的平台,每天日活量是亿级别,整体的用户量更是惊人,所以用户评分矩阵自然是大得离谱,自然会有两问题产生:一个是存储问题,一个是计算问题。
在存储问题上
可以采用稀疏存储,比如只存储用户打过分的物品的分数和坐标,没有发生过行为的不存储。
在计算问题上
-
从整体考虑,计算上可以实现先聚类,将相似的聚到一起,然后再在这一个小簇里面进行协同过滤,减小整体的计算量。
-
在进行协同过滤时,一般不取全量的用户,而是取前n天的活跃用户的行为矩阵进行计算,其实际的意义有3:
意义1:减少计算量
意义2:可以兼顾到新用户,如果取全量,新用户很难推出东西
意义3:一个平台的所有用户不一定全是活的,有些用户可能注册之后,并再没有使用,所以利用前n天的行为矩阵计算,可以避免掉僵尸用户。 -
应该去掉比较热门的物品,如果不去掉,其会导致所有用户都协同,进而出现马太效应。永远只推热门物品出来。















 3719
3719











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









