







一、概念
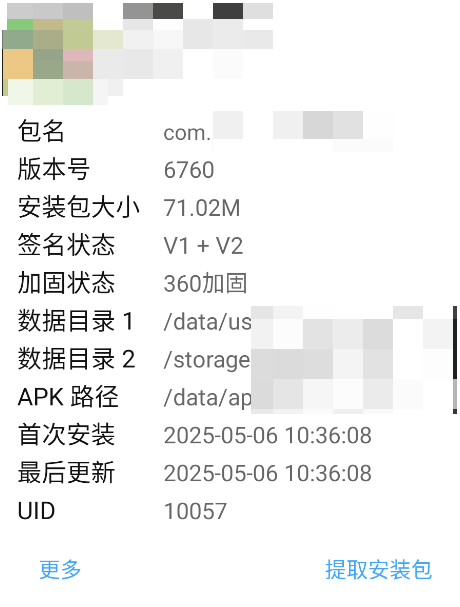
由于为了防⽌代码泄露等问题,以及篡改等问题,特意对APP进⾏加固加壳
例如:
未加固:
就如之前的抓包也能直接找到对应的数据

加固:
一般不能直接找到对应的数据,由于加固的原因要对其先进行脱壳
二、frida-dexdump脱壳
tool:
frida-dexdump:
https://github.com/hluwa/frida-dexdump
pip install frida-dexdump
use:
frida-dexdump
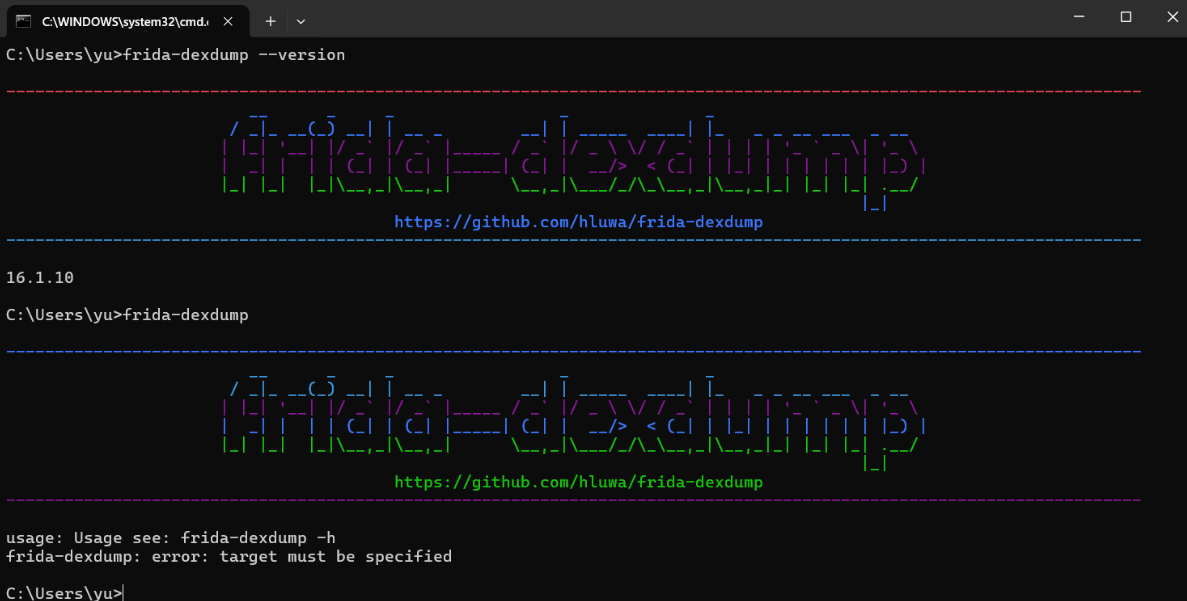
使⽤起来跟我们的frida⽤法是⼀样的,⾸先启动⼿机端的frida服务,然后直接使⽤frida-dexdump运⾏-
U -f <包名>即可。
随后将脱后的dex文件进行修复
三、LSP框架脱壳
tools:
FunDex2:https://github.com/Xposed-Modules-Repo/com.zhenxi.fundex2/releases
MT管理器:
⾯具:
ROOT权限:
LSP框架:https://mrzzoxo.lanzoue.com/i74DE1l482xa
use:
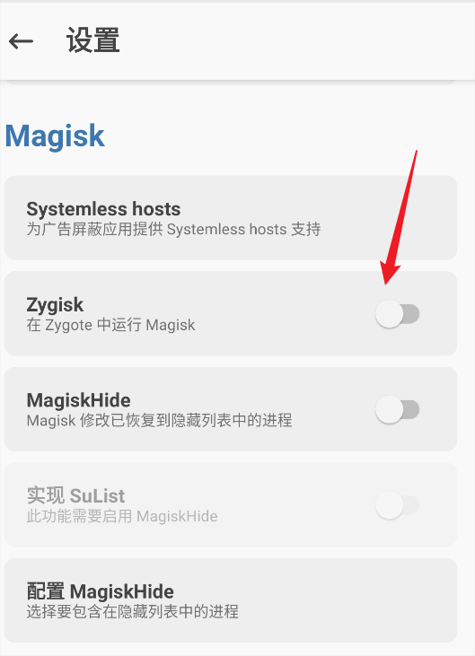
将FunDex和LSP安装后面具可能会对lsp进行报错如下:

只需在设置中打开即可:
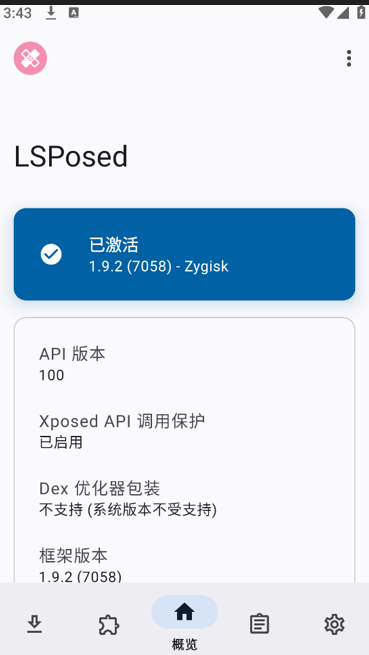
随后进行重启,在任务栏中显示以下信息即表示成功:

点击即可打开应用:
随后点击模块,点击启用以及勾选你想脱壳的app:
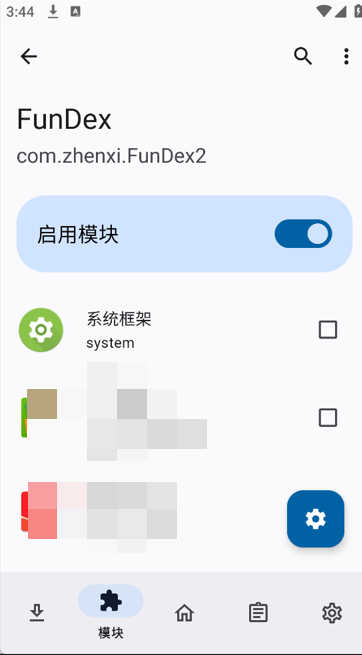
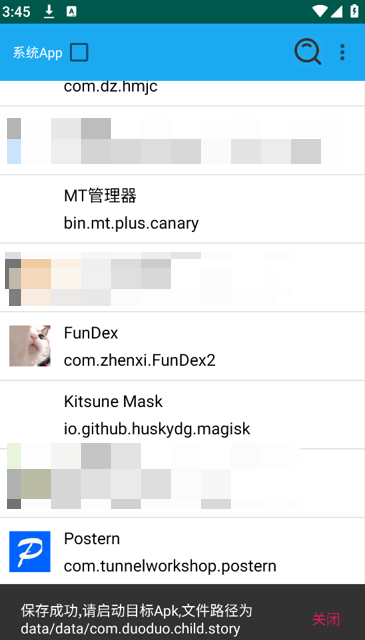
随后返回主页进行点击fundex apk,然后再点击想要脱壳的app:

















 607
607

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









