






系统:ubuntu20.04
一、
进入到/dify2/dify/docker中,右击docker-compose.yaml,用文编辑器打开,加入
# Frontend web application.
web:
image: langgenius/dify-web:0.14.1
restart: always
# 添加以下 ports 配置
ports:
- "3001:3000" # 将外部端口改为 3001,注意缩进格式
environment:
CONSOLE_API_URL: ${CONSOLE_API_URL:-}
APP_API_URL: ${APP_API_URL:-}
SENTRY_DSN: ${WEB_SENTRY_DSN:-}
NEXT_TELEMETRY_DISABLED: ${NEXT_TELEMETRY_DISABLED:-0}
TEXT_GENERATION_TIMEOUT_MS: ${TEXT_GENERATION_TIMEOUT_MS:-60000}
CSP_WHITELIST: ${CSP_WHITELIST:-}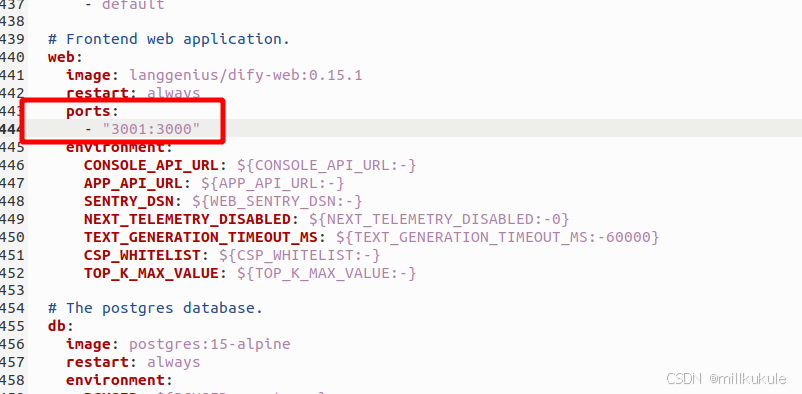
保存文件,重启服务
docker compose down
docker compose up -d二、切换dify版本
打开对应版本的源码,进入到docker,打开终端,执行
docker compose down
docker compose up -d

















 546
546

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









