






dd基于python的案例实战
数据预处理
导入包
import pandas as pd
import numpy as np
import seaborn as sns
读取数据
income = pd.read_excel(r'F:\python数据挖掘\income.xlsx')#数据读取数据处理
#查看数据是否存在缺失值
income.apply(lambda x:np.sum(x.isnull()))#处理缺失值
income.fillna(value = {'workclass':income.workclass.mode()[0],
'occupation':income.occupation.mode()[0],
'native-country':income['native-country'].mode()[0]},inplace=True)#数值型变量的统计
income.describe()
#离散型数据的统计描述
income.describe(include=['object'])数据的分布情况(如偏度、峰度)可以通过可视化的方法进行展现,这里调查的是居民的年龄和每周工作小时数为例子,绘制各自的分布图像
import matplotlib.pyplot as plt
#设置绘图风格
plt.style.use('ggplot')
#设置多图形的组合
fig, axes = plt.subplots(2, 1)
#绘制不同收入水平下的年龄核密度图
income.age[income.income == ' <=50K'].plot(kind = 'kde',
label = '<=50K',
ax = axes[0],
legend = True,
linestyle = '-')
income.age[income.income == ' >50K'].plot(kind = 'kde',
label = '<50K',
ax = axes[0],
legend = True,
linestyle = '-')
#绘制不同水平下的周工作小时数核密图
income['hours-per-week'][income.income == ' <=50K'].plot(kind = 'kde',
label = '<=50K',
ax = axes[1],
legend = True,
linestyle = '-')
income['hours-per-week'][income.income == ' >50K'].plot(kind = 'kde',label = '>50K',ax = axes[1],
legend = True,
linestyle = '--')
#显示图像
plt.show()运行结果
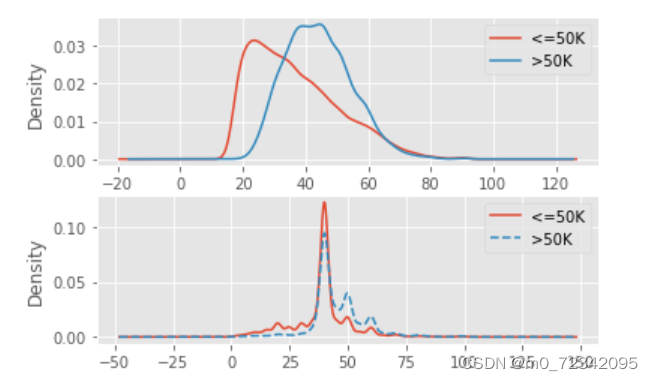
上半图展示的是不同收入情况下,年龄的核密图,对于年收入超过5万美元的居民来说,他们的年龄几乎成正太分布,而收入低于5万美元的则出现右偏特征,即年龄偏大的人数比年龄偏小的人数多
下半图展现的是不同收入水平下,周工作的小时的和密度,很明显两者的分布趋势非常相似,并且出现局部峰值。
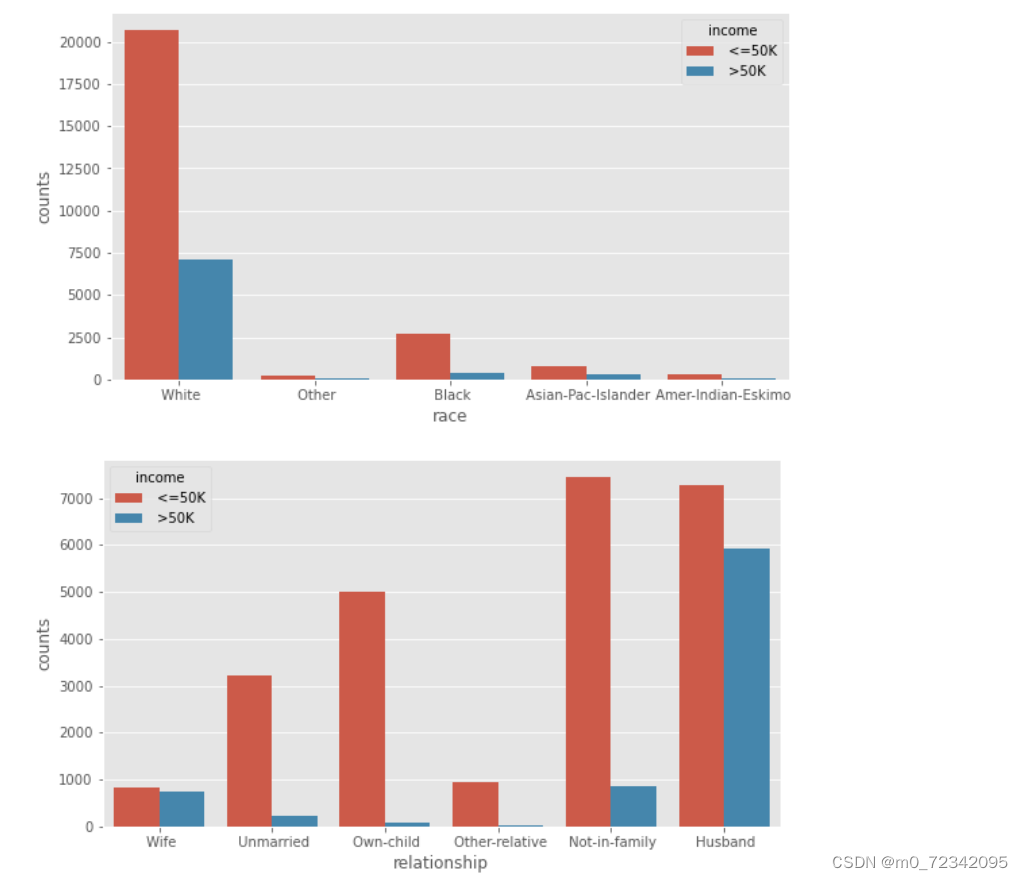
同理针对离散型数据,对比居民的收入水平在性别、种族状态、家庭关系等 方面的差异,进而可以发现这些离散型数据是否影响收=收入水平
#构造不同收入水平下各种族人群的数据
race = pd.DataFrame(income.groupby(by = ['race','income']).aggregate(np.size).loc[:,'age'])
#重新行索引
race = race.reset_index()
#变量重命名
race.rename(columns={'age':'counts'}, inplace=True)
#排序
race.sort_values(by = ['race','counts'],ascending=False , inplace=True)
#构造不同收入水平下各家庭关系人数的数据
relationship = pd.DataFrame(income.groupby(by=['relationship','income']).aggregate(np.size).loc[:,'age'])
relationship = relationship.reset_index()
relationship.rename(columns={'age':'counts'},inplace=True)
relationship.sort_values(by=['relationship','counts'],ascending=False,inplace=True)
#设置图例
plt.figure(figsize=(9,5))
sns.barplot(x="race",y="counts",hue='income',data=race)
plt.show()
plt.figure(figsize=(9,5))
sns.barplot(x="relationship",y="counts",hue='income',data=relationship)
plt.show()运行结果















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









