






在开始本次教程之前,首先要确定你已经安装了anaconda,pycharm,以及git等必要的软件,或者已经完成了深度学习基本开发环境的搭建,如果还没有搭建好自己的深度学习环境的,这里请先移步我的第一篇博客。
(2条消息) 《关于我被车创④,转生到异世界以后什么都不会,于是从零开始搞深度学习这回事》之 yolov7保姆级教学_深度学习鲨我的博客-CSDN博客
基本的环境搭建完毕以后,就开始本次的教学,首先,我们要开始搭建关于paddledetection的环境,对于paddle paddle的版本选择,以及一些其他的相关的依赖包的安装与下载,请参考我的上一篇博客。
(2条消息) 《人均码农的世界对连c都不会写的辣鸡很不友好》之paddle系列 PP-humanseg保姆级入门教学(之后会更新paddle系列其他的教学)_深度学习鲨我的博客-CSDN博客
paddledetection也是百度的产品,所以环境是通用的,如果是看过我上一个博客的同学,这里可以不用换环境,就用之前做humanseg的环境,也可以做paddledetection。
首先,先把paddledetection克隆下来,这里建议大家重新新建一个文件夹,然后在文件夹里打开,这样免得找不到你的项目在哪里,克隆的代码我放在下面。
git clone https://github.com/PaddlePaddle/PaddleDetection.git如果网络实在不行的同学,也可以试试在码云上面下载,这里同样附上代码。
git clone https://gitee.com/paddlepaddle/PaddleDetection.git
下载完毕以后,用pycharm打开,大家会看到如下界面。
下载下来以后,首先需要安装相关的依赖包。这里就不一一解释了,总之,下面的代码一条一条执行,如果有问题的话,就多执行即便即可。
cd C:\Users\20105\Desktop\paddle\PaddleDetection #这一步主要是打开你的paddle detection的地址,我的地址是这个,把这个换成你自己的
pip install -r requirements.txt
python setup.py install执行完毕,如果没有报错的话,再执行下面的代码,如果结果输出“OK”,则说明你的环境搭建完毕。
python ppdet/modeling/tests/test_architectures.py需要注意的是,paddledetection里面的大部分模型都是需要多卡训练的,且模型巨大,如果你的环境搭建没什么问题,但是跑训练就是跑不出来的话,别怀疑,就是你的显存爆了。
上述如果都没什么问题的话,输入下面的代码,试着预测一张测试图片看看。
python tools/infer.py -c configs/ppyolo/ppyolo_r50vd_dcn_1x_coco.yml -o use_gpu=true weights=https://paddledet.bj.bcebos.com/models/ppyolo_r50vd_dcn_1x_coco.pdparams --infer_img=demo/000000014439.jpg

如果上面的指令运行没问题的话,在output里面会看到这张图片,demo跑通。
接下来是训练环节,这里比较麻烦的是,如果大家看的是我第一个教程学习打标签的话,大概率用的是labelimg,打出来的是txt文件,不能适用于其他模型,所以如果想要在其他模型上训练的话,需要自己再打一个coco的数据集。
下载一个新的打标签的包,labelme。
pip install labelme然后直接输入labelme即可打开。界面如下。
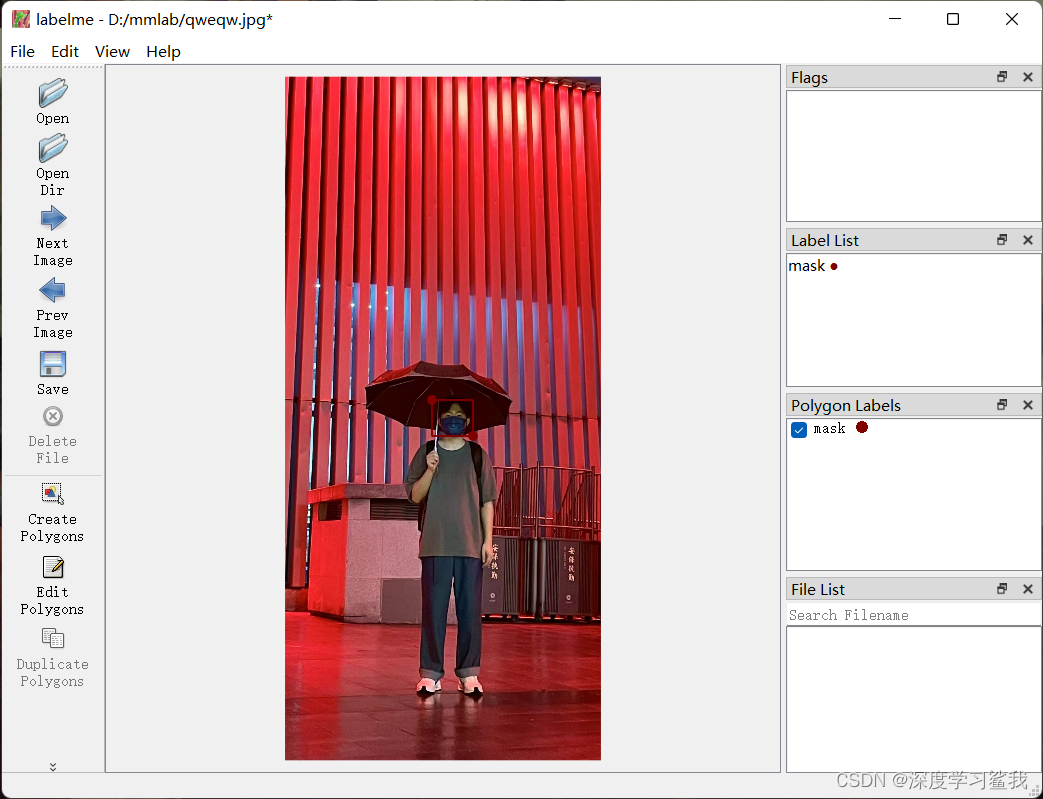
打开文档的流程大同小异,不同在于打标签的方式,这里选择create polygons,然后就正常打标签即可,这里我做的是口罩检测模型,所以我打了口罩的标签。

这里打出来的标签文件应该是JSON格式,不需要之前那样刻意的去分训练集,测试集,所有的标签文件放一起,所有的图片文件放一起。具体格式如下。

JEPGimages里面放图片,annotations里面放标签文件。具体如何区分训练集和数据集,代码我放在下面。
# coding: utf-8
import os
import random
trainval_percent = 1 # 训练集验证集总占比
train_percent = 0.95 # 训练集在trainval_percent里的train占比
xmlfilepath = 'C:/Users/20105/Desktop/paddle/PaddleDetection/data/VOCdevkit/Annotations'#这里放你标签文件的地址
txtsavepath = 'C:/Users/20105/Desktop/paddle/PaddleDetection/data/ImageSets/Main'#这里放你标签文件生成以后的保存地址
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('C:/Users/20105/Desktop/paddle/PaddleDetection/data/ImageSets/Main/trainval.txt', 'w')
ftest = open('C:/Users/20105/Desktop/paddle/PaddleDetection/data/ImageSets/Main/test.txt', 'w')
ftrain = open('C:/Users/20105/Desktop/paddle/PaddleDetection/data/ImageSets/Main/train.txt', 'w')
fval = open('C:/Users/20105/Desktop/paddle/PaddleDetection/data/ImageSets/Main/val.txt', 'w')
#以上四个都是你生成标签文件以后存放的地址以及名字,大家按照我的改成自己的地址即可。
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()这样自己的数据集就制作完成了。我们可以试一下较为简单的训练。打开C:\Users\20105\Desktop\paddle\PaddleDetection\configs\yolov3\yolov3_mobilenet_v1_roadsign.yml文件,该文件如下。
_BASE_: [
'../datasets/roadsign_voc.yml',
'../runtime.yml',
'_base_/optimizer_40e.yml',
'_base_/yolov3_mobilenet_v1.yml',
'_base_/yolov3_reader.yml',
]
pretrain_weights: https://paddledet.bj.bcebos.com/models/yolov3_mobilenet_v1_270e_coco.pdparams
weights: output/yolov3_mobilenet_v1_roadsign/model_final
YOLOv3Loss:
ignore_thresh: 0.7
label_smooth: true其中,base是运行该文件所需要的依赖文件,大家都可以在对应的地方找到,大家可以不必了解具体是什么,只需要将第一个依赖,即../datasets/roadsign_voc.yml'改为datasets\coco_detection.yml即可,这里最好改为绝对寻址。然后打开coco_detection.yml文件,如下。
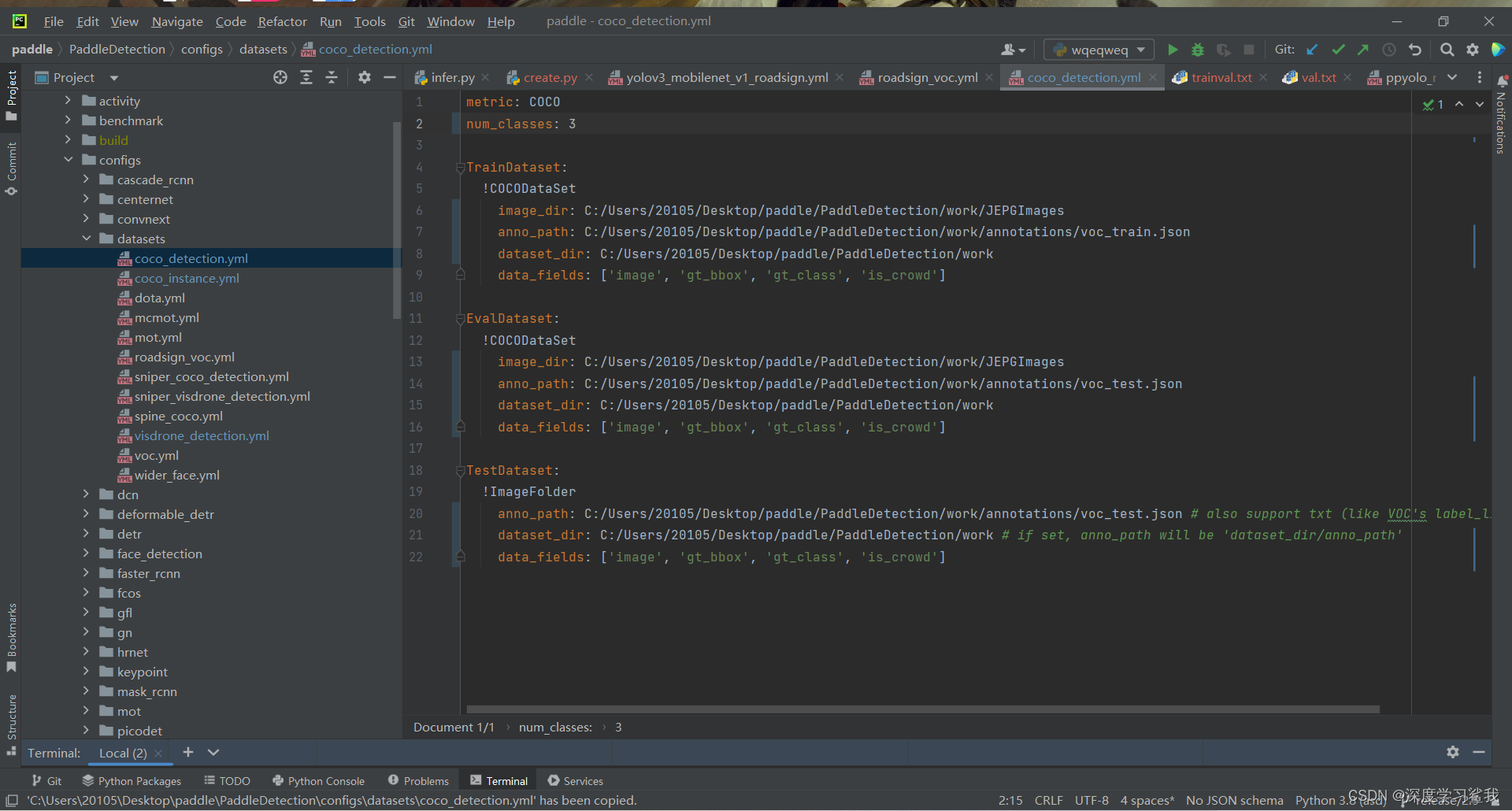
这里num_class指的是你的标签种类,需要注意的是,这里的标签数要比你实际的标签数要多一个。比如我只有mask,face俩个标签,但是我的标签数是3,下面的都是你的数据集的位置,大家按照我的格式改成自己的即可。比如,第一个,从上到下分别是你照片所在文件夹的地址,你训练集生成的标签文件地址,和你所有东西的根文件夹地址。下面的都大差不差。
如果上面的东西都调完了,直接运行该文件即可。
代码如下。
python tools\train.py -c
C:\Users\20105\Desktop\paddle\PaddleDetection\configs\yolov3\yolov3_mobilenet_v1_roadsign.yml#这是我该文件的绝对寻址地址,这里换成自己的。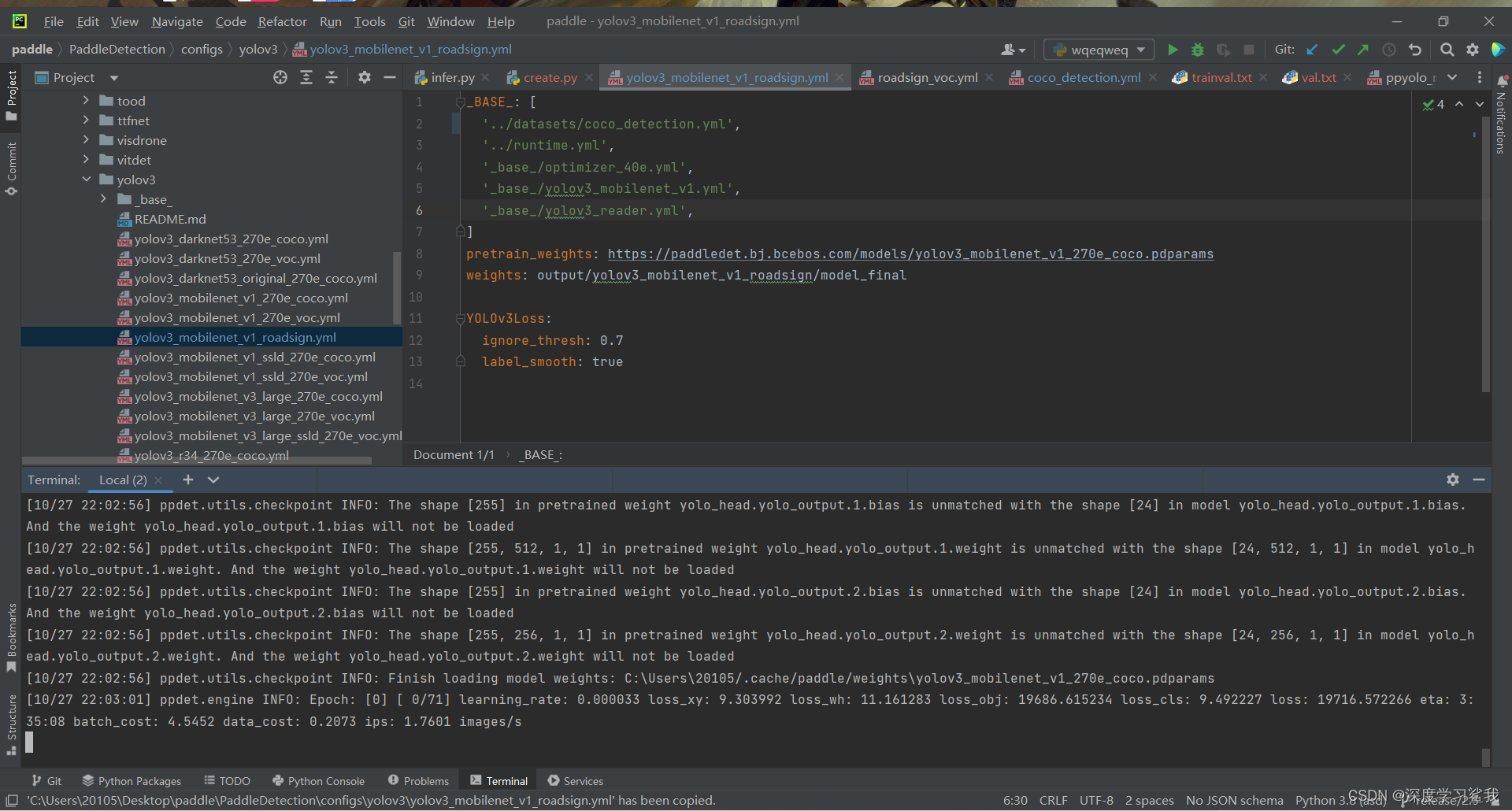
如果在terminal里看见上面的输出,则说明开始训练了,然后等他训练完毕即可。到此,paddledetection的教学就结束了。
mmdetection的安装与paddledetection的安装大同小异,毕竟都是企业开发的。这里我就直接放代码了,大家一条一条执行即可。首先还是新建一个文件夹,然后用pycharm打开。环境如果没换的话,就用上面那个环境即可,免得重新装pytorch了。
pip install openmim
mim install mmcv-full
git clone https://github.com/open-mmlab/mmdetection.git
cd mmdetection
pip install -r requirements/build.txt
pip install -v -e .上面每一条代码执行都会运行一段时间,还很有肯能报错,因为网络超时的问题,大家耐心安装,如果报错了,就多执行几遍。如果大家运行完毕,最后会告诉你,成功安装mmdet,如下。
得到上述结果以后,大家先到下面这个链接里下载权重文件,然后在根目录下新建一个checkpoints文件夹,放进去。
然后再新建一个python的脚本,注意,名字最好是乱打的,别带空格和中文,免得和其他文件重名。代码如下。
from mmdet.apis import init_detector, inference_detector
config_file = 'configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py'
# 从 model zoo 下载 checkpoint 并放在 `checkpoints/` 文件下
# 网址为: http://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth
checkpoint_file = 'checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth'
device = 'cuda:0'
img='D:/mmlab/mmdetection/projecttest.jpg'#这里放你要检测的照片的地址,改成自己的
# 初始化检测器
model = init_detector(config_file, checkpoint_file, device=device)
# 推理演示图像
result=inference_detector(model, img)
model.show_result(img, result, out_file='result2.jpg')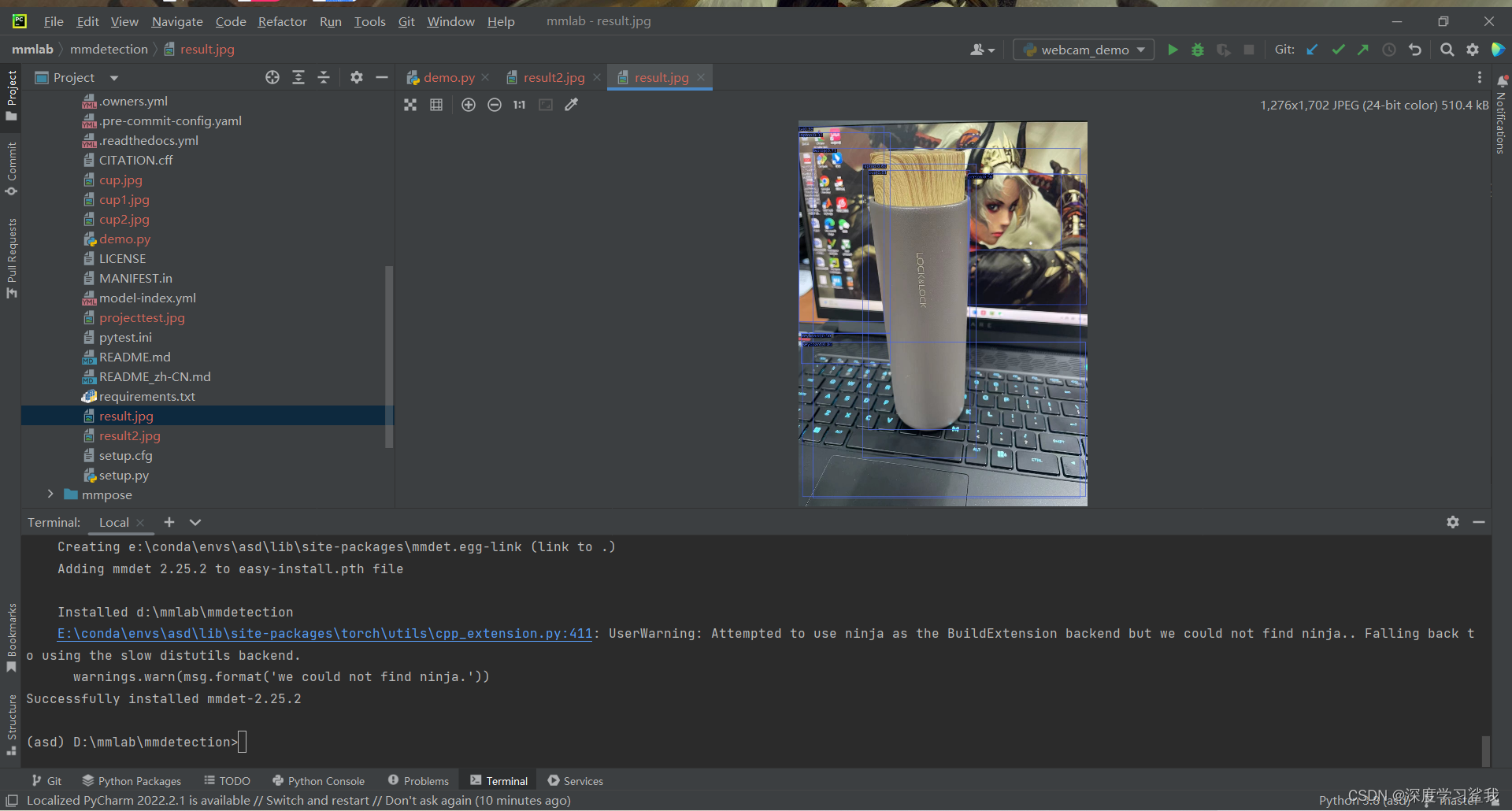
运行后大概是这样,因为大家所用的照片不同,所以结果也不尽相同,但是大概是这么个意思。
mmdetection的训练和paddle detection的训练差不多,如果大家已经完成了对于paddle detection的训练,那么大家一定已经有了自己的coco数据集了,这里我们的mmdetection的训练还是要使用之前制作好的coco数据集,我会以一个yolov3的训练作为本次的教程。首先,大家打开mmdetection/configs/yolo/yolov3_d53_mstrain-608_273e_coco.py,如下图。
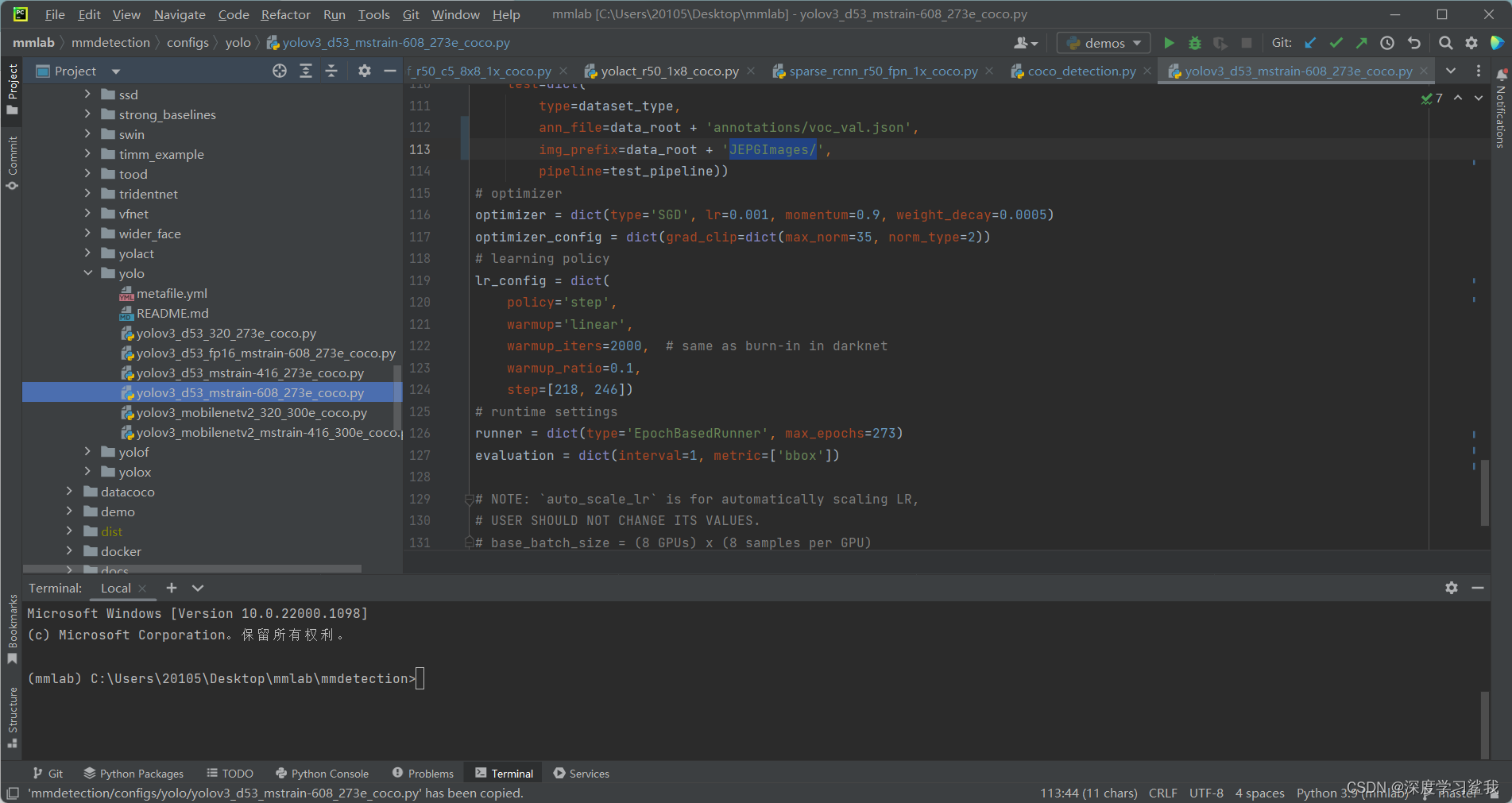
这里我就直接告诉大家需要修改的代码行,大家一一对照即可。
17 num_classes=2 这个是你的数据标签的种类,改为自己的即可
60 data_root = 'C:/Users/20105/Desktop/mmlab/mmdetection/datacoco/' 这个是你的数据集的根目录,大家按照我的格式修改为自己的即可
102-114 ann_file=data_root + 'annotations/voc_train.json',
img_prefix=data_root + 'JEPGImages/',
pipeline=train_pipeline),
val=dict(
type=dataset_type,
ann_file=data_root + 'annotations/voc_val.json',
img_prefix=data_root + 'JEPGImages/',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
ann_file=data_root + 'annotations/voc_val.json',
img_prefix=data_root + 'JEPGImages/',
pipeline=test_pipeline))
这几行都是在修改你的数据集的地址,包括标签地址,图片地址等,大家按照我的格式改为自己的地址即可这里我只做了coco的数据集的教程,所以后面我也只会修改coco 的数据集,如果大家有做voc的,都大差不差,可以参考一下。
还有两个大家需要修改的脚本文件,分别是
mmdetection/mmdet/core/evaluation/class_names.py和mmdetection/mmdet/datasets/coco.py
这里其实需要修改的地方是一样的,截图如下。
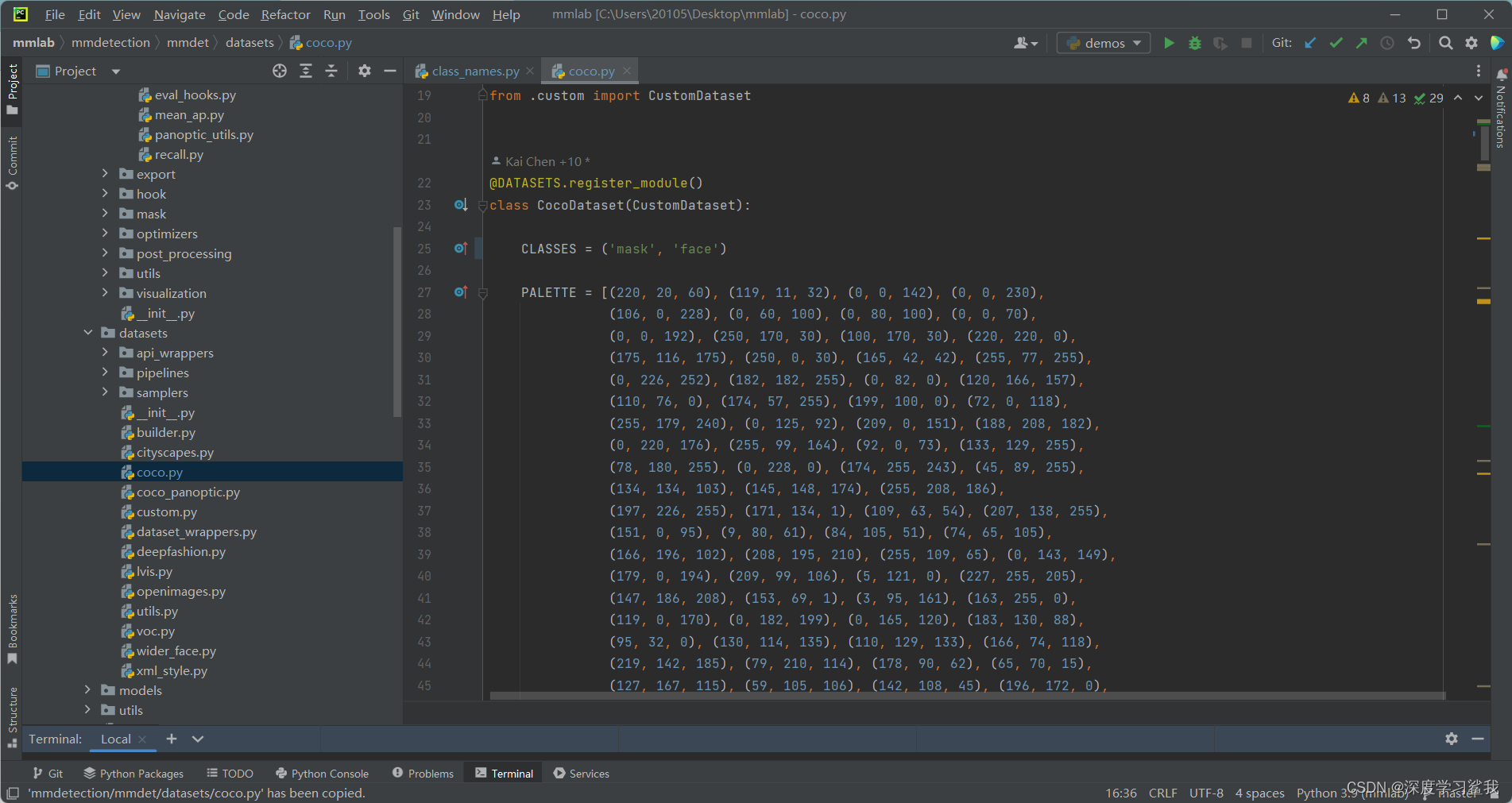
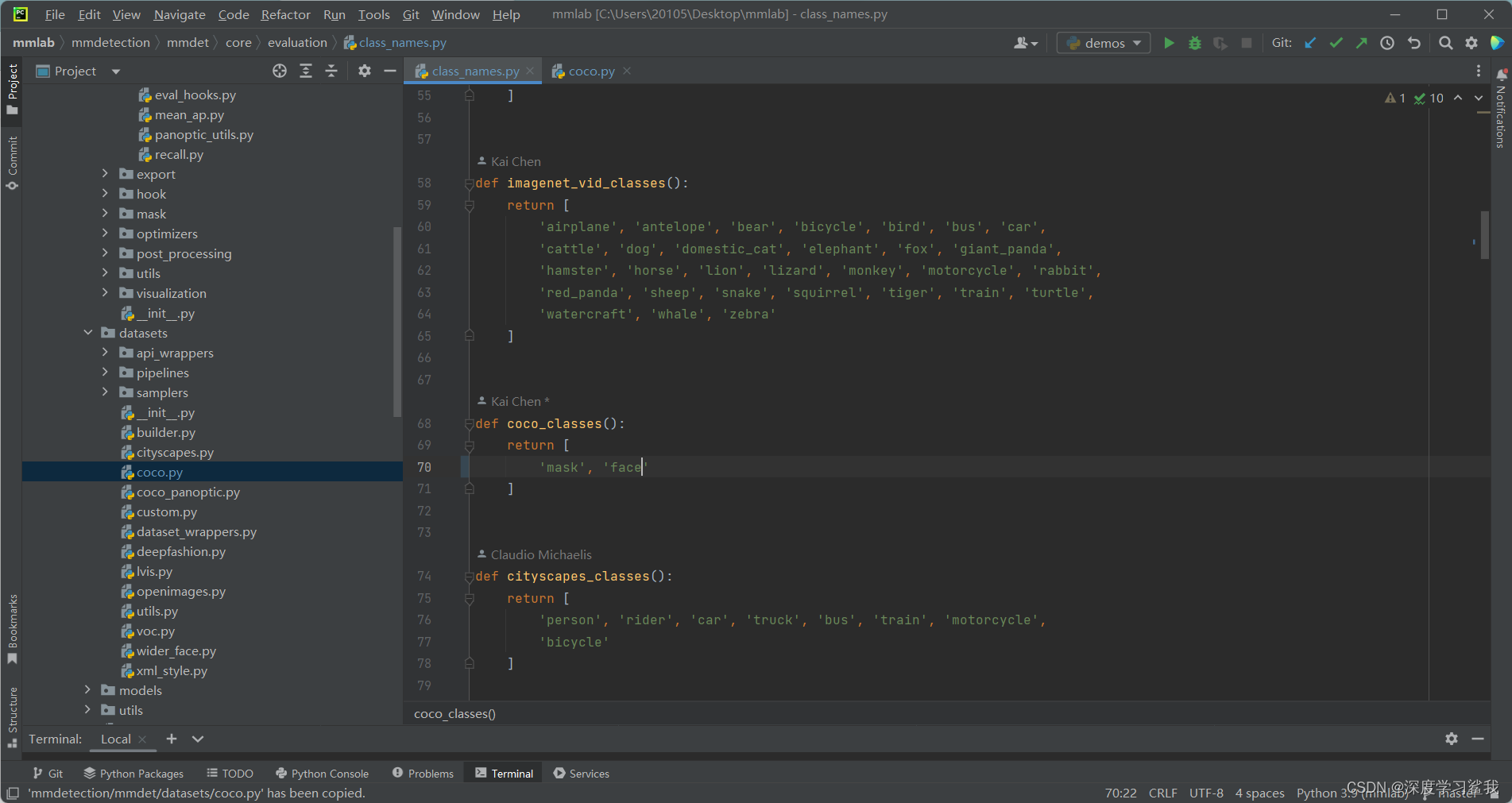
分别修改coco数据集的标签名称和返回值,改为自己的,这里需要注意的是,要按照自己的标签顺序来,不能乱写,如何查看自己的标签顺序呢,打开你的标签文件json查看即可,如下图。
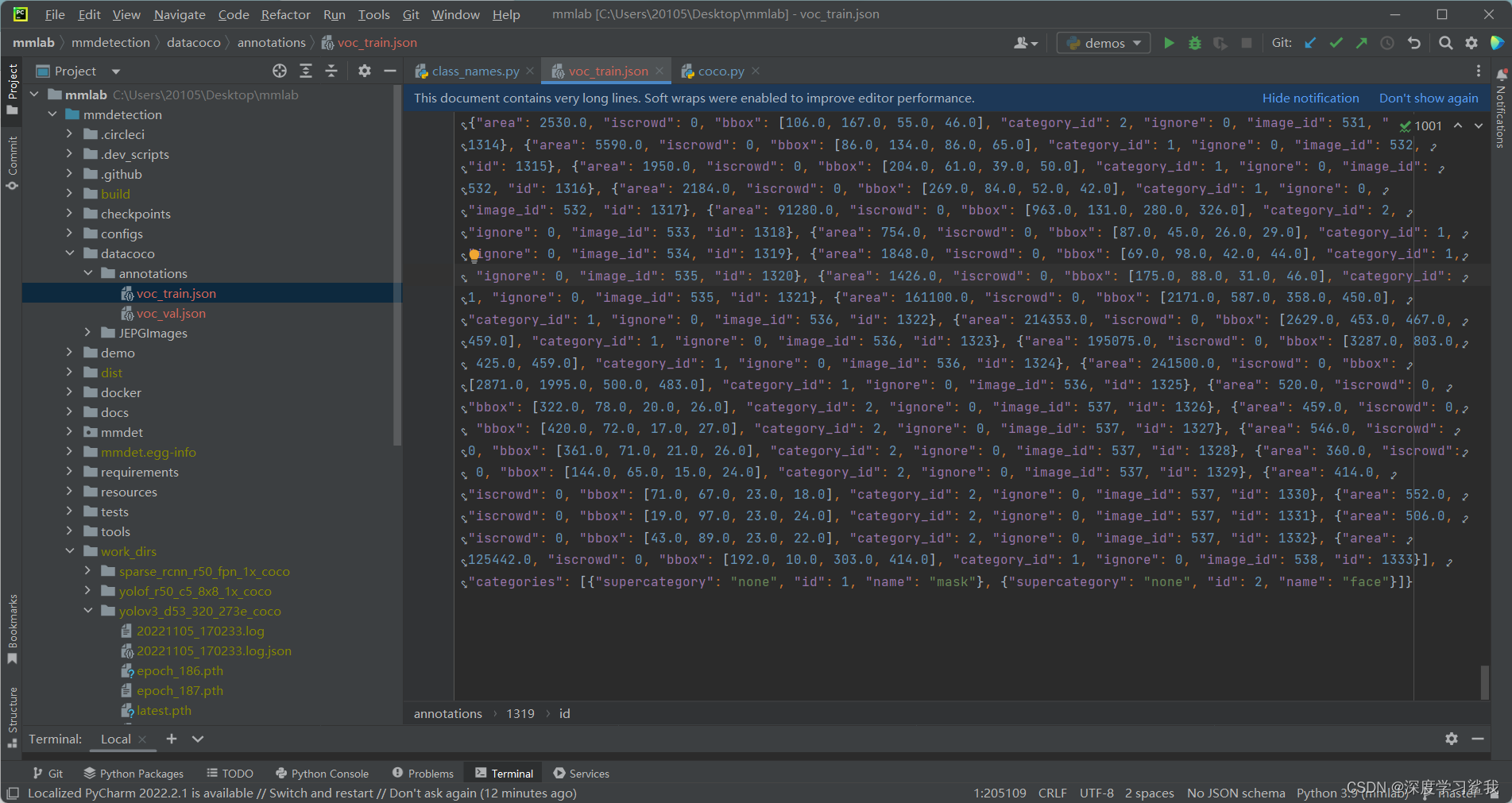
这里可以看到,我的第一个标签是mask,第二个是face,且我只有这两个,所以我在上面修改coco的标签时先写mask,再写的face,如果这里大家都已经修改完毕,那么执行下面的指令,即可开始训练了。
python tools\train.py
C:\Users\20105\Desktop\mmlab\mmdetection\configs\yolo\yolov3_d53_320_273e_coco.py
这里需要注意的是,在mmdetection/configs/yolo/yolov3_d53_mstrain-608_273e_coco.py这个脚本的126行这里,有他的训练的轮数,这个模型因为精度不是很高,所以每训练一次,都会保存,如果大家内存不够的话,分分钟爆炸,所以我建议大家,要么修改保存间隔,要么就一边训练一边删,只保留最后的结果即可。
126 runner = dict(type='EpochBasedRunner', max_epochs=273)














 2726
2726











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









