






集合进阶(一)
ArrayList集合是一种容器,用来装数据的,类似于数组,但集合的大小可变,开发中也非常有用,为了满足不同的业务场景需求,Java还提供了许多不同的特点的集合
目录
-
集合体系:单列集合(Collection)、双列集合(Map)
-
Collection集合体系
-
Collection
-
Collection的常用方法
-
Collection的遍历方式
-
-
List集合
- 特点,特有方法
- 遍历方式
- ArrayList集合的特点及底层原理
- LinkedList集合的底层原理和常用方法
-
Set集
- 特点
- HashSet集合的特点及底层原理
- LinkedHashSet集合的特点及底层原理
- TreeSet的特点及底层原理
-
Collection集合的使用总结,集合的并发修改异常问题
-
Collection的其他相关知识
- 前置知识:可变参数
- Collections
- 综合案例
-
Stream流
- 获取Stream流
- Stream提供的中间终结方法
- Stream提供的常用终结方法
集合体系
1. Collection 单列集合
2. Map 双列集合

Collection代表单列集合:每个元素(数据)只包含一个值
Map代表双列集合,每个元素包含两个值(键值对)
Collection集合体系
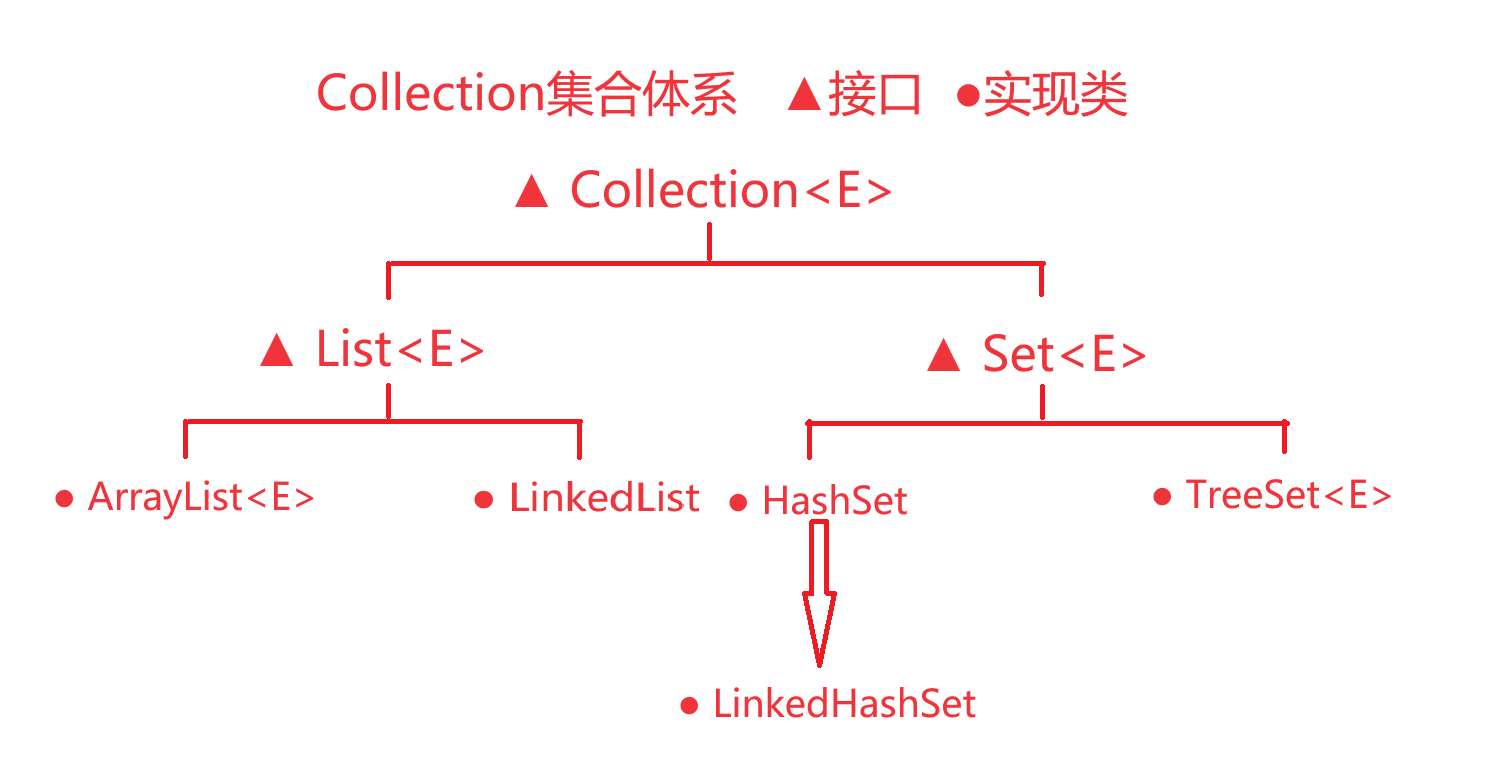
Collection
- List系列集合:添加的元素是有序,可重复、有索引
- ArrayList、LinkedList:有序、可重复、有索引
- Set系列集合:添加的元素是无序、不重复、无索引
- HashSet:无序、不重复、无索引
- LinkedHashSet:有序、不重复、无索引
- TreeSet:按照大小默认升序排序,不重复、无索引
Collection的常用方法
| 方法名 | 说明 |
|---|---|
| Public boolean add(E e) | 把给定的对象添加到当前集合中 |
| Public void clear() | 清空集合中的所有元素 |
| Public boolean remove(E e) | 把给定的对象在当前集合中删除 |
| Public boolean contains(Object obj) | 判断当前集合中是否包含给定的对象 |
| Public boolean isEmpty() | 判断当前集合是否为空 |
| Public int size() | 返回集合中元素的个数 |
| Public Object[] toArray() | 把集合中的元素,存储到数组中 |
public class CollectionTest1 {
public static void main(String[] args) {
Collection<String> c = new ArrayList<>(); //多态写法
// 1、public boolean add<E e>,添加元素,添加成功返回true
c.add("A");
c.add("B");
c.add("A");
c.add("B");
System.out.println(c); // [A, B, A, B]
// 2、public void clear(),清空集合的元素
// c.clear();
System.out.println(c);
// 3、public bpplean isEmpty(),判断集合是否为空,是空返回true,反之
System.out.println(c.isEmpty()); // false
// 4、public int size(),获取集合的大小
System.out.println(c.size()); // 4
// 5、public boolean contains(object obj),判断集合中是否包含某个元素
System.out.println(c.contains("A")); // true
System.out.println(c.contains("a")); // false
// 6、public boolean remove(E e),删除某个元素:如果有多个重复元素删除前面的第一个!
System.out.println(c.remove("B")); // true
System.out.println(c); // [A, A, B]
// 7、public Object[] toArray(),把集合转换成数组
Object[] arr = c.toArray();
System.out.println(Arrays.toString(arr)); // [A, A, B]
String[] arr2 = c.toArray(new String[c.size()]);
System.out.println(Arrays.toString(arr2)); // [A, A, B]
// 8、把一个集合中的全班数据倒入到另一个集合中去
Collection<String> c1 = new ArrayList<>();
c1.add("java1");
c1.add("java2");
Collection<String> c2 = new ArrayList();
c2.add("java3");
c2.add("java4");
c1.addAll(c2); // 就是把c2集合中的全部数据倒入到c1集合中去(拷贝一份)
System.out.println(c1); // [java1, java2, java3, java4]
System.out.println(c2); // [java3, java4]
}
}
Collection的遍历方式
- 迭代器
- 增强for
- lambda表达式
迭代器
- 迭代器是用来遍历集合的专用方式(数组没有迭代器,在Java中迭代器的代表是Iterator)
Collection集合获取迭代器的方法
| 方法名 | 说明 |
|---|---|
| Iterator iterator | 返回集合中的迭代器对象,该迭代器默认指向当前集合的第一个元素 |
Iterator迭代器的常见方法
| 方法名 | 说明 |
|---|---|
| boolean hasNext() | 询问当前位置是否有元素存在,存在返回true,不存在返回false |
| E next() | 获取当前位置的元素,并同时将迭代器对象指向下一个元素处 |
public class CollectionTest2 {
public static void main(String[] args) {
Collection<String> c = new ArrayList<String>();
c.add("张三");
c.add("李四");
c.add("王五");
c.add("赵六");
System.out.println(c); // [张三, 李四, 王五, 赵六]
// it
// 使用迭代器遍历集合
// 1、从集合对象中获取迭代器对象
Iterator<String> it = c.iterator();
// System.out.println(it.next());
// System.out.println(it.next());
// System.out.println(it.next());
// System.out.println(it.next());
// System.out.println(it.next()); // 出现异常
// 2、应该使用循环结合迭代器遍历集合
while (it.hasNext()) { // 问当前位置有没有数组
String ele = it.next(); // 取出当前数据,并移到下一个位置
System.out.println(ele);
}
}
}
增强for循环
格式
for(元素的数据类型 变量名:数组或集合) {
...
}
- 增强for可以用来遍历集合或数组
- 增强for遍历集合,本质就是迭代器遍历集合的简化写法
public class CollectionTest3 {
public static void main(String[] args) {
Collection<String> c = new ArrayList<String>();
c.add("张三");
c.add("李四");
c.add("王五");
c.add("赵六");
System.out.println(c);
// c = [张三, 李四, 王五, 赵六]
// ele
// 1、使用增强for循环遍历集合
for(String ele : c) {
System.out.println(ele);
}
// 2、使用增强for循环遍历数组
String[] names = {"张三","李四","王五"};
for(String name : names) {
System.out.println(name);
}
}
}
lambda表达式遍历集合
- 得益于JDK 8,开始的新技术lambda表达式,提供了一种更简单更直接的方式来遍历集合
需要使用Collection的如下方法完成
| 方法名 | 说明 |
|---|---|
| default void forEach(Consumer <? super T> action) | 结合lamdba遍历集合 |
public class CollectionTest4 {
public static void main(String[] args) {
Collection<String> c = new ArrayList<String>();
c.add("张三");
c.add("李四");
c.add("王五");
c.add("赵六");
System.out.println(c);
// c = [张三, 李四, 王五, 赵六]
// s
// default void forEach(Consumer<? super T> action): 结合lambda表达式遍历集合
// c.forEach(new Consumer<String>() {
// @Override
// public void accept(String s) {
// System.out.println(s);
// }
// });
// c.forEach((String s) -> {
// System.out.println(s);
// });
// lambda表达式简化
c.forEach(s -> System.out.println(s));
// 方法引用 out对象 println方法
c.forEach(System.out::println);
}
}
案例:遍历集合中的自定义对象
需求:展示多部电影
分析:
- 每部电影都是一个对象,多部电影要用集合装起来
- 遍历集合中的3个电影对象,输出每部电影的详情信息
/**
* 目标:完成电影信息的展示
* new Movie("《肖申克的救赎》",9.7,"罗宾斯")
* new Movie("《霸王别姬》",9.6,"张国荣")
* new Movie("《阿甘正传》",9.5,"汤姆·汉克斯")
*/
public class CollectionTets5 {
public static void main(String[] args) {
// 1、创建一个集合容器负责存储多部电影对象
Collection<Movie> movies = new ArrayList<Movie>();
movies.add(new Movie("《肖申克的救赎》",9.7,"罗宾斯"));
movies.add(new Movie("《霸王别姬》",9.6,"张国荣"));
movies.add(new Movie("《阿甘正传》",9.5,"汤姆·汉克斯"));
System.out.println(movies);
for (Movie movie : movies) {
System.out.println("电影名:" + movie.getName());
System.out.println("评分" + movie.getScore());
System.out.println("主演" + movie.getActor());
System.out.println("------------------------------------");
}
}
}
----------------------------------------------------------------------------------------------
public class Movie {
private String name;
private double score;
private String actor;
public Movie() {
}
public Movie(String name, double score, String actor) {
this.name = name;
this.score = score;
this.actor = actor;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getScore() {
return score;
}
public void setScore(double score) {
this.score = score;
}
public String getActor() {
return actor;
}
public void setActor(String actor) {
this.actor = actor;
}
@Override
public String toString() {
return "Movie{" +
"name='" + name + '\'' +
", score=" + score +
", actor='" + actor + '\'' +
'}';
}
}
List集合
- 特点、特有方法
- 遍历方式
- ArrayList集合的底层原理
- LinkedList集合的底层原理
·List系列集合特点:有序、可重复、有索引
List集合的特有方法
List集合因为支持索引,所以多了许多与索引相关的方法,当然,Collection的功能List也继承了
| 方法名 | 说明 |
|---|---|
| void add(int index,E element) | 在此集合中的指定位置插入指定的元素 |
| E remove(int index) | 删除指定索引处的元素,返回被删除的元素 |
| E set(int index,E element) | 修改指定索引处的元素,返回被修改的元素 |
| E get(int index) | 返回指定索引处的元素 |
public class ListTest1 {
/**
* 目标:掌握List系列集合的特点,以及其提供的特有方法
*/
public static void main(String[] args) {
// 1、创建一个ArrayList集合对象(有序、可重复、有索引)
List<String> list = new ArrayList<String>(); // 一行经典代码(多态)
list.add("张三");
list.add("李四");
list.add("王五");
list.add("赵六");
System.out.println(list); // [张三, 李四, 王五, 赵六]
// 2、public void add(int index,E element):在某个索引位置插入元素
list.add(2,"波妞");
System.out.println(list); // [张三, 李四, 波妞, 王五, 赵六]
// 3、public E remove(int index):根据索引删除元素,返回被删除的元素
System.out.println(list.remove(2)); // 波妞
System.out.println(list); // [张三, 李四, 王五, 赵六]
// 4、public E get(int index):返回集合中指定位置的元素
System.out.println(list.get(3)); // 赵六
// 5、public E set(int index,E element):修改索引位置处的元素,修改成功后,会返回原来的数据
System.out.println(list.set(3, "宗介")); // 赵六
System.out.println(list); // [张三, 李四, 王五, 宗介]
}
}
List集合支持的遍历方式
- for循环(因为List集合有索引)
- 迭代器
- 增强for循环
- lamdba表达式
public class listTest2 {
public static void main(String[] args) {
List<String> list = new ArrayList();
list.add("张三");
list.add("李四");
list.add("王五");
// 1、for循环
for (int i = 0; i < list.size(); i++) {
// i = 0 1 2
String s = list.get(i);
System.out.println(s);
}
// 2、迭代器
Iterator<String> it = list.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
// 3、增强for循环(foreach)
for (String s : list) {
System.out.println(s);
}
// 4、JDK 1.8开始之后的lambda表达式
list.forEach(System.out::println);
}
}
ArrayList集合的底层原理
- 基于数组实现的(查询快,增删慢)
- 数组的特点
- 删除效率低:可能需要把后面很多的数据进行前移
- 添加效率极低:可能需要把后面很多的数据后移,在添加元素,或者也可能需要进行数组的扩容
- ArrayList集合底层存数据的原理
- 利用无参构造器创建的集合,会在底层创建一个默认长度为0的数组
- 添加第一个元素时,底层会创建一个新的长度为10的数组
- 存满时,会扩容1.5倍
- 如果一次添加多个元素,1.5倍还放不下,则新创建的数组的长度以实际为准
- ArrayList集合适合的应用场景
- ArrayList适合:根据索引查询数据,比如根据随机索引取数据(高效),或者数据量不是很大时!
- ArrayList不适合:数据量大的同时,又要频繁的进行增删操作!
LinkedList集合的底层原理
- 基于双链表实现的
- 什么是链表?有啥特点
- 链表中的结点是独立的对象,在内存中是不连续的,每个结点包含数据值和下一个结点的地址
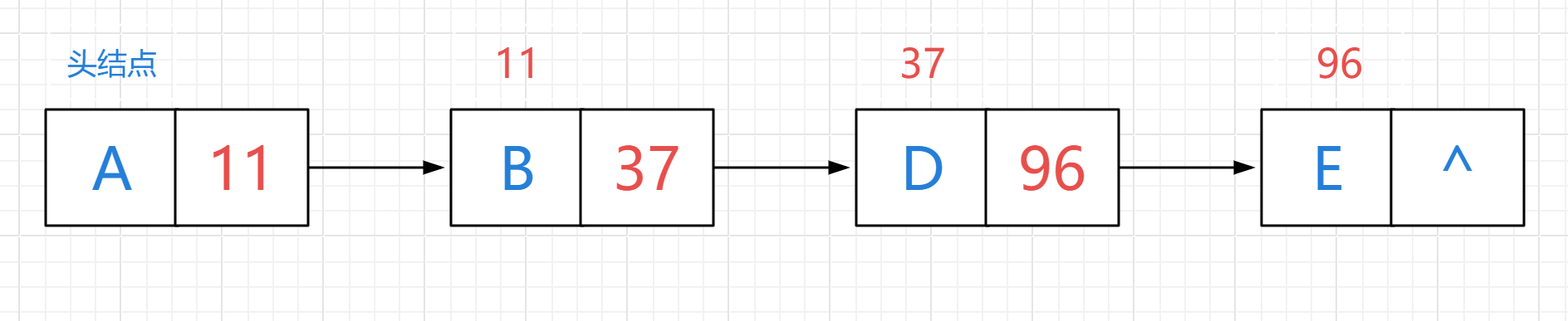
链表的特点:
- 查询慢,无论查询哪个数据都要从头开始
- 链表增删相对(数组)快
单向链表

双向链表

因为LinkedList是基于双链表,特点:查询慢,增删相对较快,对首尾元素进行增删改查是极快的
LinkedList新增了许多首尾操作的特有方法
| 方法名称 | 说明 |
|---|---|
| Public void addFirst(E e) | 在该列表开头插入指定的元素 |
| Public void addLast(E e) | 将指定的元素追加到此列表的末尾 |
| Public E getFirst() | 返回此列表的第一个元素 |
| Public E getLast() | 返回此列表的最后一个元素 |
| Public E removeFirst() | 从此列表中删除并返回第一个元素 |
| Public E removeLast() | 从此列表中删除并返回最后一个元素 |
LinkedList的应用场景之一:可以用来设计队列(叫号系统、排队系统)
队列:先进先出,后进后出
只是在首尾增删元素,用LinkedList来实现很合适!
public class LinkedListDemo1 {
public static void main(String[] args) {
// 1、创建一个队列
LinkedList<String> queue = new LinkedList<>();
// 入队
queue.addLast("第1号人");
queue.addLast("第2号人");
queue.addLast("第3号人");
queue.addLast("第4号人");
System.out.println(queue); // [第1号人, 第2号人, 第3号人, 第4号人]
// 出队
System.out.println(queue.removeFirst()); // 第1号人
System.out.println(queue.removeFirst()); // 第2号人
System.out.println(queue.removeFirst()); // 第3号人
System.out.println(queue); // [第4号人]
}
LinkedList的应用场景之一:可以用来设计栈
栈:后进先出,先进后出
-
数据进入栈模型的过程称为:压/进栈(push)
-
数据离开栈模型的过程称为:弹/出栈(pop)
public class LinkedListDemo2 {
public static void main(String[] args) {
// 2、创建一个栈对象
LinkedList<String> stack = new LinkedList<>();
// 压栈(push)
// stack.addFirst("第1颗子弹");
// stack.addFirst("第2颗子弹");
// stack.addFirst("第3颗子弹");
// stack.addFirst("第4颗子弹");
stack.push("第1颗子弹");
stack.push("第2颗子弹");
stack.push("第3颗子弹");
stack.push("第4颗子弹");
System.out.println(stack); // [第4颗子弹, 第3颗子弹, 第2颗子弹, 第1颗子弹]
// 出栈(pop)
// System.out.println(stack.removeFirst()); // 第4颗子弹
// System.out.println(stack.removeFirst()); // 第3颗子弹
System.out.println(stack.pop());
System.out.println(stack.pop());
System.out.println(stack); // [第2颗子弹, 第1颗子弹]
}
}
Set集合
- 特点
- HashSet集合的底层原理
- LinkedHashSet集合的底层原理
- TreeSet集合
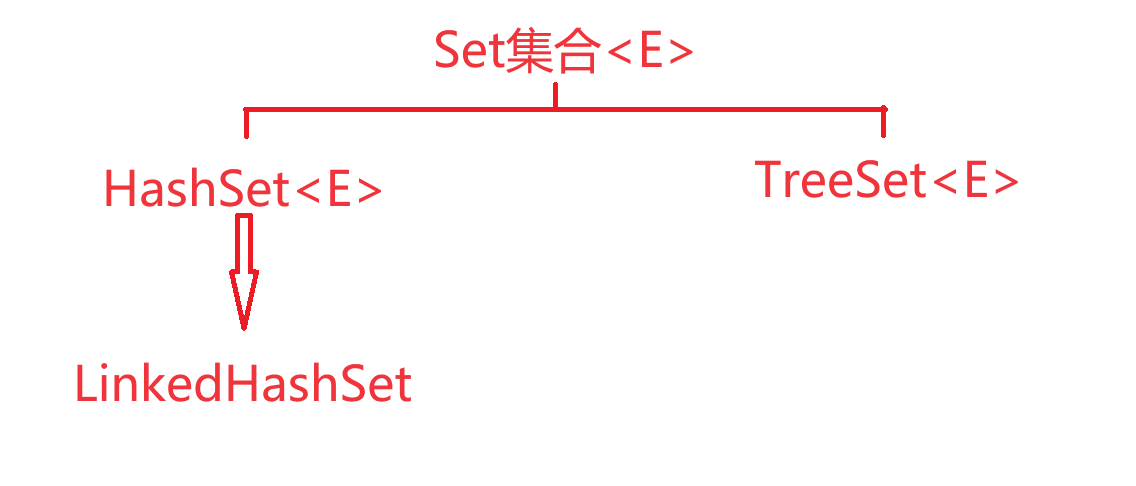
Set系列集合特点:无序:添加数据的顺序和获取数据顺序不一致,不重复;无索引
- HashSet:无序,不重复,无索引
- LinkedHashSet:有序,不重复,无索引
- TreeSet:排序,不重复,无索引
HashSet集合的底层原理
- 为什么添加的元素无序、不重复、无索引?
- 增删改查数据有什么特点,适合什么场景?
注意:在正式了解HashSet集合的底层原理前,先要搞清楚一个前置知识:哈希值!
哈希值:
- 就是一个int类型的数值,java中每个对象都有一个哈希值
- java中所有对象,都可以调用Object类提供的hashCode方法,返回该对象自己的哈希值
对象哈希值的特点:
- 同一个对象多次调用hashCode()方法,返回的哈希值是相同的
- 不同的对象,它们的哈希值一般不相同,但也有可能会相同(哈希碰撞),int(-21亿多 - 21亿多)
HashSet的底层原理:
- 基于哈希表实现
- 哈希表是一种增删改查数据,性能都较好的数据结构
哈希表:
- JDK8之前,哈希表 = 数组 + 链表
- JDK8开始,哈希表 = 数组 + 链表 + 红黑树
JDK8之前HashSet集合的底层原理,基于哈希表:数组 + 链表
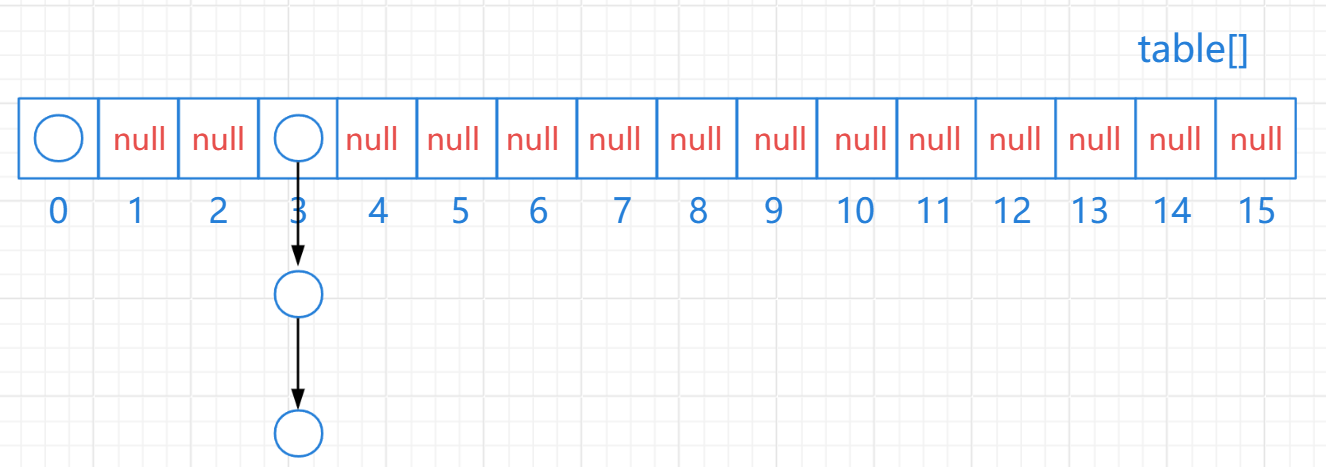
- 创建一个默认长度为16的数组,默认加载因子为0.75,数组名为table
- 使用元素的哈希值对数组的长度求余,计算出应存入的位置
- 判断当前位置是否为null,如果是null直接存入该数据
- 如果不为null,表示当前位置有元素,则调用equals方法比较,相等则不存,不相等,则存入数组
- JDK8之前,新元素存入数组,占老元素位置,老元素挂下面
- JDK8开始之后,新元素直接挂在老元素下面
JDK8开始之后,HashSet集合的底层原理,基于哈希表:数组 + 链表 + 红黑树
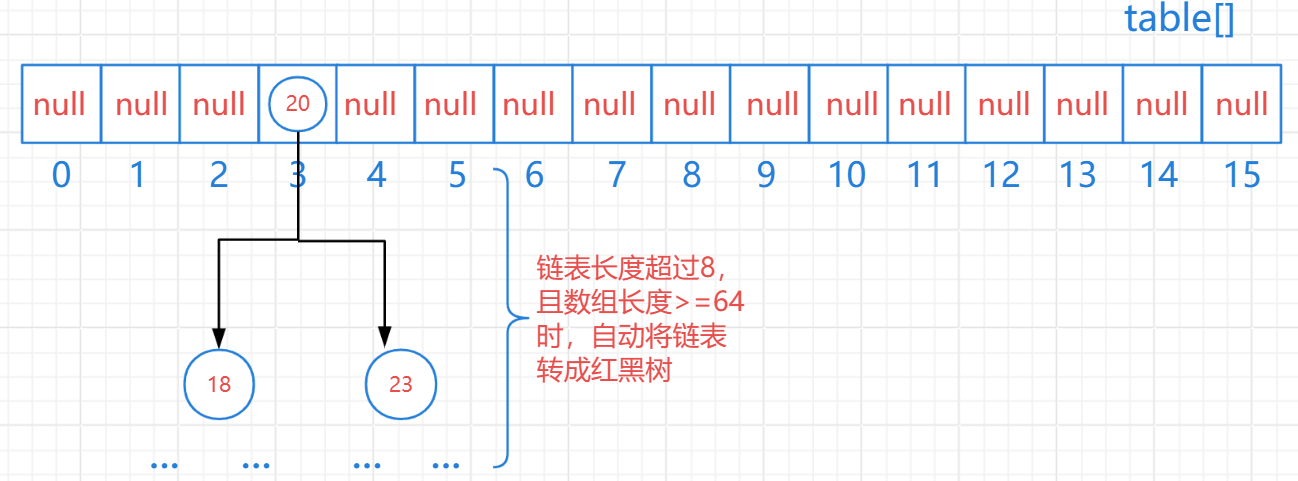
- JDK8开始,当链表长度超过8,且数组长度 >= 64时,自动将链表转成红黑数
- 小结:JDK8开始后,哈希表中引入了红黑树后,进一步提高了操作数据的性能
了解一下数据结构(树)
- 红黑树,就是可以自平衡的二叉树
- 红黑树是一种增删改查数据性能相对都较好的结构
深入理解HashSet集合去重复的机制
HashSet集合默认不能对内容一样的两个不同对象去重复
- 比如内容一样的两个学生对象存入到HashSet集合中去,HashSet集合是不能去重的
如何让HashSet集合能够实现对内容一样的两个不同对象也能去重复?
- 如果希望Set集合认为2个内容一样的不同对象是重复的,必须重写对象的hashCode() 和 equals()方法
/**
* 目标:自定义的类型的对象,比如两个内容一样的学生对象,如何让HashSet集合去重复!
* 重写hashCode()和equals()方法
*/
public class SetTest3 {
public static void main(String[] args) {
Set<Student> students = new HashSet<Student>();
Student s1 = new Student("张三",28,168.9);
Student s2 = new Student("李四",28,168.6);
Student s3 = new Student("李四",28,168.6);
System.out.println(s2.hashCode()); // -1550691888
System.out.println(s3.hashCode()); // -1550691888
Student s4 = new Student("王五",28,169.6);
students.add(s1);
students.add(s2);
students.add(s3);
students.add(s4);
System.out.println(students);
}
}
-----------------------------------------------------------------------------------------------
public class Student {
private String name;
private int age;
private double height;
public Student(String name, int age, double height) {
this.name = name;
this.age = age;
this.height = height;
}
// 只要两个对象内容一样,就返回ture
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age && Double.compare(height, student.height) == 0 && Objects.equals(name, student.name);
}
// 只要两个对象内容一样,返回的哈希值就是一样的
@Override
public int hashCode() {
// 根据对象的 姓名 年龄 身高来计算哈希值
return Objects.hash(name, age, height);
}
@Override
public String toString() {
return "{" +
"name='" + name + '\'' +
", age=" + age +
", height=" + height +
'}';
}
public Student() {
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public double getHeight() {
return height;
}
public void setHeight(double height) {
this.height = height;
}
}
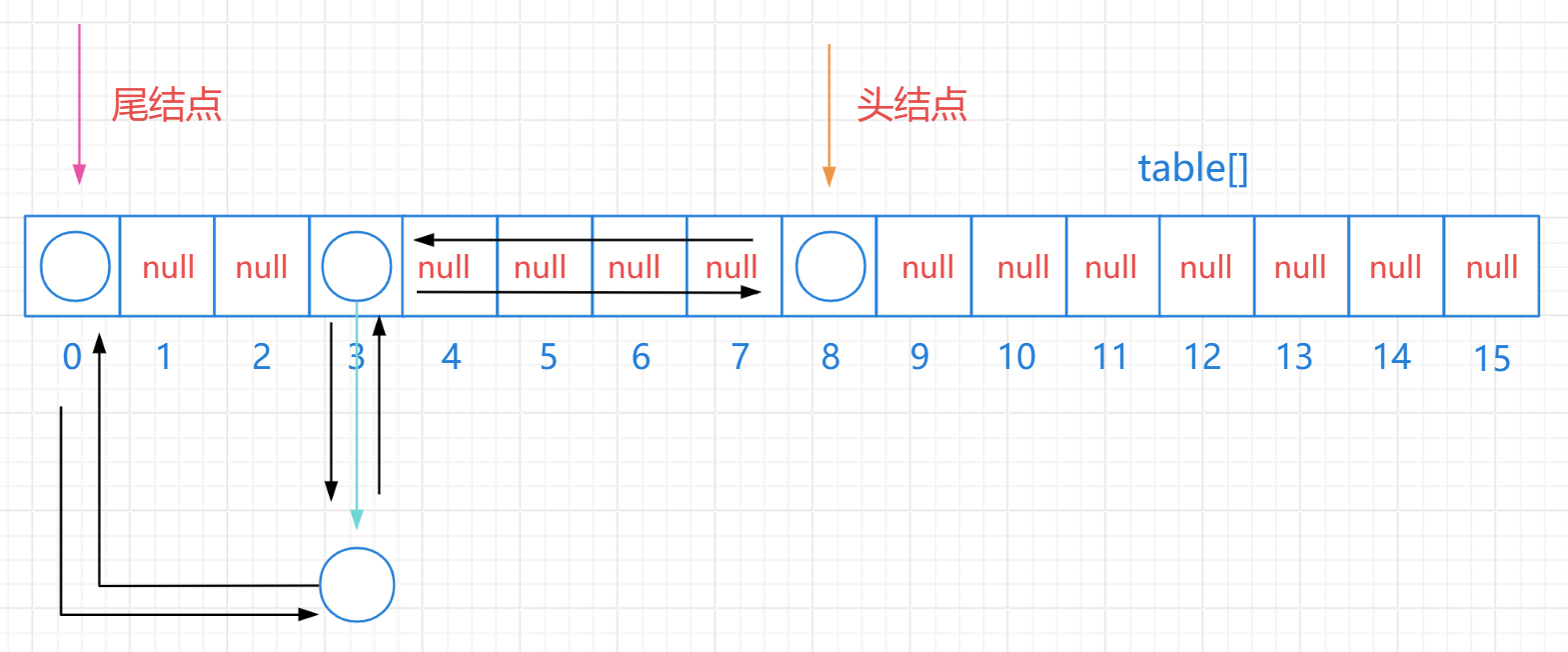
LinkedHashSet:有序、不重复、无索引
- 依然是基于哈希表(数组、链表、红黑树)实现的
- 但是,它的每个元素都额外的多了一个双链表的机制记录它前后的位置
TreeSet
- 特点:不重复,无索引,可排序(默认升序,按照元素的大小,由小到大排序)
- 底层是基于红黑数实现的排序
注意:
- 对于数值类型:Integer,Double,默认按照数值本身的大小进行升序
- 对于字符串类型:默认按照首字符的编号升序排序
- 对于自定义类型如:Student 对象,TreeSet默认是无法直接排序的
自定义排序规则
- TreeSet集合存储自定义类型的对象时,必须指定排序规则
方式一:
让自定义的类实现Comparable接口,重写里面的CompareTo方法,来指定比较规则
/**
* 目标:掌握如何给自定义类型的对象排序
*/
public class SetTest5 {
public static void main(String[] args) {
Set<Student> students = new TreeSet<>();
students.add(new Student("张三",22,167.8));
students.add(new Student("李四",23,166.8));
students.add(new Student("王五",25,165.8));
students.add(new Student("赵六",22,183.8));
System.out.println(students);
// [{name='张三', age=22, height=167.8}, {name='李四', age=23, height=166.8}, {name='王五', age=25, height=165.8}]
}
}
-----------------------------------------------------------------------------------------------
public class Student implements Comparable<Student>{
private String name;
private int age;
private double height;
// this 比较者
// o 被比较者
@Override
public int compareTo(Student o) {
// 如果认为左边对象 大于 右边对象返回正整数
// 如果认为左边对象 小于 右边对象返回负整数
// 如果认为左边对象 等于 右边对象返回 0
// 需求:按照年龄升序排序
return this.getAge() - o.getAge();
}
public Student(String name, int age, double height) {
this.name = name;
this.age = age;
this.height = height;
}
@Override
public String toString() {
return "{" +
"name='" + name + '\'' +
", age=" + age +
", height=" + height +
'}';
}
public Student() {
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public double getHeight() {
return height;
}
public void setHeight(double height) {
this.height = height;
}
}
方式二:
通过调用TreeSet集合的有参构造器,可以设置Comparator对象(比较器对象)
| 方法名 |
|---|
| Public TreeSet(Comparator < ? super E > comparator) |
/**
* 目标:掌握如何给自定义类型的对象排序
*/
public class SetTest6 {
public static void main(String[] args) {
// TreeSet就近选择自己自带的比较器对象进行排序
// Set<Student> students = new TreeSet<>(new Comparator<Student>() {
// @Override
// public int compare(Student o1, Student o2) {
// // 需求:按照升高升序
// return Double.compare(o1.getHeight(), o2.getHeight());
// }
// });
// 使用 lambda 表达式简化
Set<Student> students = new TreeSet<>(( o1, o2) -> Double.compare(o1.getHeight(), o2.getHeight()));
students.add(new Student("张三",22,167.8));
students.add(new Student("李四",23,166.8));
students.add(new Student("王五",22,165.8));
students.add(new Student("赵六",22,166.8));
System.out.println(students);
// [{name='王五', age=22, height=165.8}, {name='李四', age=23, height=166.8}, {name='张三', age=22, height=167.8}]
}
}
-----------------------------------------------------------------------------------------------
public class Student implements Comparable<Student>{
private String name;
private int age;
private double height;
public Student(String name, int age, double height) {
this.name = name;
this.age = age;
this.height = height;
}
@Override
public String toString() {
return "{" +
"name='" + name + '\'' +
", age=" + age +
", height=" + height +
'}';
}
public Student() {
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public double getHeight() {
return height;
}
public void setHeight(double height) {
this.height = height;
}
}
Collection集合的之一总结,集合的并发修改异常问题
- 如果希望记住元素的添加顺序,需要存储重复的元素,又要频繁的根据索引查询数据?
- 用ArrayList集合(有序、可重复、有索引),底层基于数组(常用)
- 如果希望记住元素的添加顺序,且增删首尾数据的情况较多?
- 用LinkedList集合(有序、可重复、有索引),底层基于双链表实现的
- 如果不在意元素顺序,也没有重复元素需要存储,只希望增删改查都快?
- 用HashSet集合,底层基于哈希表实现的(常用)
- 如果希望记住元素的添加顺序,也没有重复元素需要存储,且希望增删改查都快
- 用LinkedHashSet集合(有序、不重复、无索引),底层基于哈希表和双链表
- 如果要对元素进行排序,也没有重复元素需要存储,且希望增删改查都快
- 用TreeSet集合,基于红黑树实现
集合的并发修改异常
- 使用迭代器遍历集合,又同时在删除集合中的数据时,程序就会出现并发修改异常的错误
- 由于增强for循环遍历集合就是迭代器遍历集合的简化写法,因此,使用增强for循环遍历集合,又在同时删除集合中的数据时,程序也会出现并发修改异常。
public class CollectionTest1 {
public static void main(String[] args) {
List<String> list = new ArrayList();
list.add("李四");
list.add("小张子");
list.add("晓张");
list.add("王五");
list.add("张麻子");
list.add("张真");
System.out.println(list);
// [李四, 小张子, 晓张, 王五, 张麻子, 张真]
// 需求:找出集合中带“张”的名字,并从集合中删除
// 因为遍历集合中的元素,并且删除的时候会出现bug,所以迭代器会报一个集合的并发修改异常
Iterator<String> it = list.iterator();
while (it.hasNext()) {
String name = it.next();
if (name.contains("张")) {
list.remove(name);
}
}
System.out.println(list);
// ConcurrentModificationException:并发修改异常的错误
// 使用for循环遍历集合并删除集合中带张字的名字
// 普通for循环不会报并发修改异常的错误提示,只能自己打印出结果发现错误
for (int i = 0; i < list.size(); i++) {
String name = list.get(i);
if (name.contains("张")) {
list.remove(name);
}
}
System.out.println(list); // [李四, 晓张, 王五, 张真] 有的值略过了没有遍历到
}
怎么保证遍历集合时删除数据不出bug?
- 使用迭代器遍历集合,使用迭代器自己的删除方法删除数据即可
- 使用for循环遍历
- 从前往后遍历,但删除元素后做i–操作
- 倒着遍历集合并删除
/**
* 目标:理解集合的并发修改异常问题,并解决
*/
public class CollectionTest1 {
public static void main(String[] args) {
List<String> list = new ArrayList();
list.add("李四");
list.add("小张子");
list.add("晓张");
list.add("王五");
list.add("张麻子");
list.add("张真");
System.out.println(list);
// [李四, 小张子, 晓张, 王五, 张麻子, 张真]
// 集合的并发修改异常问题的解决方案
for (int i = 0; i < list.size(); i++) {
String name = list.get(i);
if (name.contains("张")) {
list.remove(name);
i--;
}
}
System.out.println(list); // [李四, 王五]
Iterator<String> it = list.iterator();
while (it.hasNext()) {
String name = it.next();
if (name.contains("张")) {
// list.remove(name); // 并发修改异常的错误
it.remove();
//使用迭代器自己的删除方法,删除迭代器当前遍历到的数据,每删除一个数据后,相当于也在底层做了 i--
}
}
System.out.println(list);
System.out.println("-------------------------------------");
// 使用增强for循环遍历集合并删除数据,没有办法解决并发修改异常的问题
// for (String name : list) {
// if (name.contains("张")) {
// list.remove(name);
// }
// }
// System.out.println(list);
// 使用增强forEach循环遍历集合并删除数据,没有办法解决并发修改异常的问题
// list.forEach(name -> {
// if (name.contains("张")) {
// list.remove(name);
// }
// });
// System.out.println(list);
}
}
Collection的其他相关知识
- 前置知识:可变参数
- Collections
- 综合案例
可变参数
- 就是一种特殊的形参,定义在方法、构造器的形参列表里,格式是:
数据类型...参数名称
可变参数的特点和好处
- 特点:可以不传数据给形参,可以传一个数据或者多个数据给形参,也可以传一个数组给形参
- 好处:常常用来灵活的接收数据
/**
* 目标:认识可变参数,掌握其作用
*/
public class ParamTest1 {
public static void main(String[] args) {
// 特点:
test();
test(10); // 传输一个数据给可变参数
test(10,20,30); // 传输多个数据给可变参数
test(new int[]{10,20,30,40}); // 传输一个数组给可变参数
}
// 注意事项1:一个形参列表中,只能有一个可变参数
// 注意事项2:可变参数必须放在形参列表的最后面
public static void test(int...numbers) {
// 可变参数在方法内部,本质就是一个数组
System.out.println(numbers.length);
System.out.println(Arrays.toString(numbers));
System.out.println("---------------------------------");
}
}
可变参数的注意事项
- 可变参数在方法内部就是一个数组
- 一个形参列表中可变参数只能有一个
- 可变参数必须放在形参列表的最后面
Collections
- 是一个用来操作集合的工具类
Collections提供的常用静态方法
| 方法名称 | 说明 |
|---|---|
| Public static boolean addAll(collection < ? super T > c,T … elements ) | 给集合批量添加数据 |
| Public static void shuffle(List<?> list) | 打乱List集合中的元素顺序 |
| Public static void sort(List list) | 对list集合中的元素进行升序排序 |
| Public static void sort(List list,Comparator< ? super T > c ) | 对list集合中元素,按照比较器对象指定的规则进行排序 |
案例:斗地主游戏
- 总共有54张牌
- 点数:“3”,“4”,“5”,“6”,“7”,“8”,“9”,“10”,“J”,“Q”,“K”,“A”,“2”
- 花色:“♠”,“♥”,“♣”,“♦”
- 大小王:“☺”,“☹”
- 斗地主:发出51张牌,剩下3张作为底牌
分析实现:
- 在启动游戏房间的时候,应该提前准备好54张牌
- 接着,需要完成洗牌,发牌,对牌排序,看牌
public class Card {
private String number;
private String color;
private int size; // 0 1 2 .....
public Card() {
}
public Card(String number, String color, int size) {
this.number = number;
this.color = color;
this.size = size;
}
public String getNumber() {
return number;
}
public void setNumber(String number) {
this.number = number;
}
public String getColor() {
return color;
}
public void setColor(String color) {
this.color = color;
}
public int getSize() {
return size;
}
public void setSize(int size) {
this.size = size;
}
@Override
public String toString() {
return color + number;
}
}
--------------------------------------------------------------------------------------------------
public class Room {
// 必须有一副牌
private List<Card> allCards = new ArrayList<Card>();
public Room() {
// 1、做出54张牌,存入到集合allCards
// 2、点数:个数确定,类型确定,可以用数组存储
String[] numbers = {"3","4","5","6","7","8","9","10","J","Q","K","A","2"};
// 3、花色:个数确定,类型确定
String[] colors = {"♠","♥","♣","♦"};
int size = 0; // 表示每张牌的大小
// 4、遍历点数,再遍历花色,组织牌
for (String number : numbers) {
// number = "3"
size++; // 1 ....
for (String color: colors) {
Card c = new Card(number, color, size);
allCards.add(c); // 存牌
}
}
// 单独存入小王和大王
Card c1 = new Card("","☹",++size);
Card c2 = new Card("","☺",++size);
Collections.addAll(this.allCards, c1, c2);
System.out.println("新牌" + allCards);
}
/**
* 游戏启动
*/
public void start() {
// 1、洗牌:allCards
Collections.shuffle(allCards);
System.out.println("洗牌后:" + allCards);
// 2、发牌:首先定义三个玩家(集合) ——> List(ArrayList)
List<Card> play1 = new ArrayList<>();
List<Card> play2 = new ArrayList<>();
List<Card> play3 = new ArrayList<>();
// 正式发牌给这三个玩家,依次发出51张牌,剩余3张作为底牌
// allCards = [♦10, ♣5, ♠2, ♣2, ♠5, ♠6, ♠4, ♦Q, .....]
// 0 1 2 3 4 5 6 7
for (int i = 0; i < allCards.size() - 3; i++) {
Card c = allCards.get(i);
// 判断给谁发牌
if(i%3 == 0) {
// 发给第一个玩家
play1.add(c);
} else if(i%3 == 1) {
// 发给第二个玩家
play2.add(c);
} else {
// 发给第三个玩家
play3.add(c);
}
}
// 3、对3个玩家的牌进行排序
sortCards(play1);
sortCards(play2);
sortCards(play3);
// 4、看牌
System.out.println("玩家1的牌:" + play1);
System.out.println("玩家2的牌:" + play2);
System.out.println("玩家3的牌:" + play3);
// 最后3张底牌放到一个集合中去
List<Card> lastThreeCards = allCards.subList(allCards.size() - 3, allCards.size()); // 包前不包后
System.out.println("底牌是:" + lastThreeCards);
play1.addAll(lastThreeCards); // 底牌加到地主的牌里面
sortCards(play1);
System.out.println("玩家1抢到地主后的牌:" + play1);
}
/**
* 集中进行排序
* @param cards
*/
private void sortCards(List<Card> cards) {
Collections.sort(cards, new Comparator<Card>() {
@Override
public int compare(Card o1, Card o2) {
return o1.getSize() - o2.getSize(); // 升序排序
}
});
}
}
--------------------------------------------------------------------------------------------------
public class GameDemo {
public static void main(String[] args) {
// 1、牌类
// 2、房间类
Room m = new Room();
// 3、启动游戏
m.start();
}
}
Map集合
- 概述
- 常用方法
- 遍历方式
- HashMap
- LinkedHashMap
- TreeMap
- 补充知识:集合的嵌套
1.认识Map集合
- Map集合称为双列集合,格式:{ key1 = value1 , key2 = value2,key3 = value3,…},一次需要存一对数据作为一个元素
- Map集合的每个元素"key = value " 称为一个键值对 | 一个键值对对象 | 一个Entry对象,Map集合也被叫做“键值对集合”
- Map集合的所有键是不允许重复的,但值可以重复,键和值是 一 一对应的,每一个键只能找到自己对应的值
Map集合在什么业务场景下使用
比如购物车里面的商品列表 { 商品1 = 2 , 商品2 = 3, 商品3 = 2},需要存储一 一对应的数据时,就可以考虑使用Map集合
Map集合体系
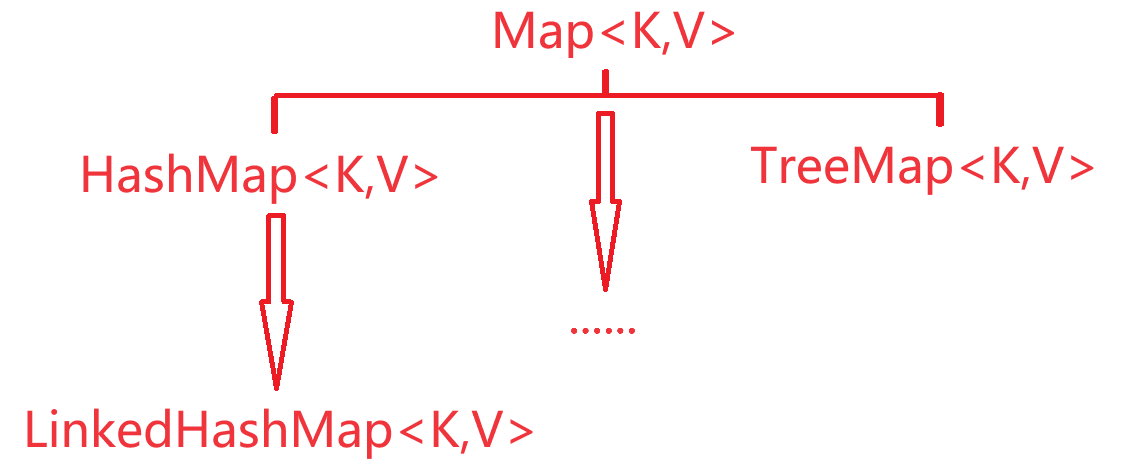
Map集合体系的特点
注意:Map系列集合的特点,都是由键决定的,值只是一个附属品,值是不做要求的
- HashMap(由键决定特点):无序、不重复、无索引;(用的最多)
public class MapTest1 {
public static void main(String[] args) {
Map<String,Integer> map = new HashMap<>(); // 按照键 ——> 无序、不重复、无索引
map.put("苹果",100);
map.put("苹果",200); // 后面重复的数据会覆盖前面的数据(键)
map.put("香蕉",20);
map.put("java书",2);
map.put(null,null);
System.out.println(map); // {null=null, 苹果=200, 香蕉=20, java书=2}
}
}
- LinkedHashMap(由键决定特点):有序,不重复,无索引
public class MapTest2 {
public static void main(String[] args) {
Map<String,Integer> map = new LinkedHashMap<>(); // 按照键 ——> 有序、不重复、无索引
map.put("苹果",100);
map.put("苹果",200); // 后面重复的数据会覆盖前面的数据(键)
map.put("香蕉",20);
map.put("java书",2);
map.put(null,null);
System.out.println(map); // {苹果=200, 香蕉=20, java书=2, null=null}
}
}
- TreeMap(由键决定特点):按照键的大小默认升序,不重复,无索引
public class MapTest3 {
public static void main(String[] args) {
Map<Integer, String> map = new TreeMap<>(); // 按照键排序(默认升序)、不重复、无索引
map.put(6,"Java");
map.put(29,"MySQL");
map.put(38,"python");
map.put(33,"C语言");
System.out.println(map); // {6=Java, 29=MySQL, 33=C语言, 38=python}
}
}
Map的常用方法
为什么要先学习Map的常用方法?
- Map是双列集合的祖宗,它的功能是全班双列集合都可以继承过来使用的
| Map的常用方法 | 说明 |
|---|---|
| Public V put (K key , V value) | 添加元素 |
| Public int size() | 获取集合的大小 |
| Public void clear() | 清空集合 |
| Public boolean isEmpty() | 判断集合是否为空,为空返回true,反之 |
| Public V get(Object key) | 根据键获取对应值 |
| Public V remove(Object key) | 根据键删除整个元素,并返回被删除的元素对应的值 |
| Public boolean containsValue(Object value) | 判断是否包含某个值 |
| Public Set keySet() | 获取全部键的Set集合 |
| Public Collection values() | 获取Map集合的全部值的Collection的集合 |
public class MapTest4 {
public static void main(String[] args) {
Map<String,Integer> map = new HashMap<>(); // 按照键 无序、不重复、无索引
map.put("苹果",100);
map.put("苹果",200); // 后面重复的数据会覆盖前面的数据(键)
map.put("香蕉",20);
map.put("Java书",2);
map.put(null,null);
System.out.println(map); // {null=null, 苹果=200, 香蕉=20, java书=2}
// 1、public int size(): 获取集合的大小
System.out.println(map.size()); // 4
// 2、public void clear: 清空集合
// map.clear();
// System.out.println(map); // {}
// 3、public boolean isEmpty(): 判断集合是否为空,为空返回true,反之返回false
System.out.println(map.isEmpty());
// 4、public V get(Object key): 根据键获取对应值
System.out.println(map.get("苹果")); // 存在返回键对应的值 200
System.out.println(map.get("Java")); // 不存在,返回null
// 5、public V remove(Object key): 根据键删除整个元素,并返回被删除的元素对应的值
System.out.println(map.remove("苹果")); // 200
System.out.println(map); // {null=null, 香蕉=20, java书=2}
// 6、public boolean containKey(Object key): 判断是否包含某个值,包含返回true,反之
System.out.println(map.containsKey("苹果")); // false
System.out.println(map.containsKey("Java书")); // true
// 7、public boolean containsValue(Object value): 判断是否包含某个值,包含返回true,反之
System.out.println(map.containsValue(2)); // true
System.out.println(map.containsValue("2")); // false
// 8、public Set<K> keySet(): 获取Map集合的全部键
Set<String> keys = map.keySet();
System.out.println(keys); // [null, 香蕉, Java书]
// 9、public Collection<V> value(); 获取Map集合的全部值
Collection<Integer> values = map.values();
System.out.println(values); // [null, 20, 2]
// 10、把其他Map集合的数据倒入到自己集合中来
Map<String,Integer> map1 = new HashMap<>();
map1.put("java1",10);
map1.put("java2",20);
Map<String,Integer> map2 = new HashMap<>();
map2.put("java3",30);
map2.put("java2",40);
map1.putAll(map2); // map2集合中的元素全部倒入一份到map1集合中去
System.out.println(map1); // {java3=30, java2=40, java1=10}
System.out.println(map2); // {java3=30, java2=40}
}
}
Map集合的遍历方式
- 键找值:先获取Map集合全部的键,在通过遍历键来找值
- 键值对:把"键值对"看成一个整体进行遍历(难度较大)
- lambda:JDK8开始之后的新技术(非常的简单)
Map集合的遍历方式一:键找值,需要用到Map的如下方法
| 方法名称 | 说明 |
|---|---|
| Public Set keySet() | 获取所有键的集合 |
| Public V get(Object key) | 根据键获取其对应的值 |
/**
* 目标:掌握Map集合的遍历方式1:键找值
*/
public class MapTest1 {
public static void main(String[] args) {
// 准备一个Map集合
Map<String,Double> map = new HashMap<>();
map.put("张三",155.6);
map.put("张三",162.8);
map.put("李四",165.8);
map.put("王五",169.5);
map.put("赵六",175.5);
System.out.println(map);
// map = {李四=165.8, 张三=162.8, 王五=169.5, 赵六=175.5}
// 1、获取Map集合的全部键
Set<String> keys = map.keySet();
System.out.println(keys); // [李四, 张三, 王五, 赵六]
// 2、遍历全部的键,根据键获取其对应的值
for (String key : keys) {
// 根据键获取对应的值
Double value = map.get(key);
System.out.println(key + ":" + value);
}
}
}
Map集合的遍历方式二:键值对
Map提供的方法
| 方法名 | 说明 |
|---|---|
| Set < Map.Entry<K,V> > entrySet() | 获取所有“键值对”的集合 |
Map.Enrty提供的方法
| 方法名 | 说明 |
|---|---|
| K getkey() | 获取键 |
| V getValue() | 获取值 |
/**
* 目标:掌握Map集合的第二种遍历方式:键值对
*/
public class Map_Test2 {
public static void main(String[] args) {
Map<String,Double> map = new HashMap<>();
map.put("张三",155.6);
map.put("张三",162.8);
map.put("李四",165.8);
map.put("王五",169.5);
map.put("赵六",175.5);
System.out.println(map);
// map = {李四=165.8, 张三=162.8, 王五=169.5, 赵六=175.5}
// 1、调用Map集合提供entrySet方法,把Map集合转换成键值对类型的Set集合
Set<Map.Entry<String, Double>> entries = map.entrySet();
// entries = [(李四=165.8), (张三=162.8), (王五=169.5), (赵六=175.5)]
// entry
for (Map.Entry<String, Double> entry : entries) {
String key = entry.getKey();
Double value = entry.getValue();
System.out.println(key+":"+value);
}
}
}
Map集合的遍历方式三:Lambda
需要用到Map的如下方法
| 方法名 | 说明 |
|---|---|
| default void forEach(BiConsumer< ? super K , ? super V > action ) | 结合Lambda遍历Map集合 |
public class Map_Test3 {
public static void main(String[] args) {
Map<String,Double> map = new HashMap<>();
map.put("张三",155.6);
map.put("张三",162.8);
map.put("李四",165.8);
map.put("王五",169.5);
map.put("赵六",175.5);
System.out.println(map);
// map = {李四=165.8, 张三=162.8, 王五=169.5, 赵六=175.5}
// map.forEach(new BiConsumer<String, Double>() {
// @Override
// public void accept(String k, Double v) {
// System.out.println(k + ":" + v);
// }
// });
// 用lamdba表达式简化
map.forEach(( k, v) -> System.out.println(k + ":" + v));
}
}
Map集合的案例:统计投票人数
需求:某个班级100名学生,现在需要组织秋游活动,班长提供了四个景点(A,B,C,D),每个学生只能选择一个景点,请统计出最终哪个景点想去的人数最多
分析:
- 将100个学生选择的数据拿到程序中去,[A,A,B,A,B,C,D…]
- 准备一个Map集合用于存储统计结果,Map<String,Integer>,键是景点,值是票数
- 遍历100个学生选择的景点,每遍历一个景点,就看Map集合中是否存在该景点,不存在在存入“ 景点 = 1 ”,存在则其对应的值 +1
/**
* 目标:完成Map集合的案例,统计投票人数
*/
public class Map_Demo4 {
public static void main(String[] args) {
// 1、把100个学生选择的景点数据拿到程序中来
List<String> data = new ArrayList<String>();
String[] selects = {"A","B","C","D"};
Random r = new Random();
for (int i = 1; i <= 100; i++) {
int index = r.nextInt(4);// 0 1 2 3
data.add(selects[index]);
}
System.out.println(data);
// 2、开始统计每个景点的投票人数
// 准备一个Map集合用于统计最终结果
Map<String,Integer> result = new HashMap<>();
// 3、开始变量100个景点数据
for (String s : data) {
// 看Map集合中是否存在该景点
if(result.containsKey(s)) {
// 说明这个景点之前统计过,其值+1,存入到Map集合中去
result.put(s,result.get(s)+1);
} else {
// 说明这个景点是第一次统计,存入"景点=1"
result.put(s,1);
}
}
}
}
HashMap集合的底层原理
- HashMap跟HashSet的底层原理是一模一样的,都是基于哈希表实现的
- 实际上Set系列的底层就是基于Map实现的,只是Set集合中的元素只要键数据,不要值数据而已
public HashSet {
map = new HashSet<>();
}
HashMap底层是基于哈希表实现的
- JDK8之前,哈希表 = 数组 + 链表
- JDK8开始之后,哈希表 = 数组 + 链表 + 红黑数
- 哈希表是一种增删改查数据,性能都较好的数据结构
- 无序、不重复、无索引(由键决定特点)
- HashMap的键依赖hashCode()方法和equals()方法保证键的唯一
- 如果键存储的是自定义类型的对象,可以通过重写hashCode()和equals()方法,这样可以保证多个对象内容一样时,HashMap集合就能认为是重复的
LinkedHashMap集合的底层原理
- 底层数据结构依然是基于哈希表实现的,只是每个键值对元素,又额外的多了一个双链表机制,记录元素顺序(保证有序)
- 实际上,原来学习的LinkedHashSet集合的底层原理就是LinkedHashMap
- 有序、不重复、无索引
TreeMap
- 特点“不重复、无索引、可排序(按照键的大小默认升序排序,只能对键排序)
- 原理:TreeMap跟TreeSet集合的底层原理是一样的,都是基于红黑数实现的排序
TreeMap集合同样也支持两种方式来指定排序规则
-
让类实现Comparable接口,重写比较规则
-
TreeMap集合有一个有参构造器,支持创建Comparator比较器对象,以便用来指定比较规则
补充知识:集合的嵌套
指的是集合中的元素又是一个集合
需求:要求在程序中记住如下省份和其对应的城市信息,记录成功后要求可以查询出湖北省的城市信息
分析:定义一个Map集合,键用来表示省份名称,值表示城市名称
注意:城市有多个,可以根据"湖北省"这个键获取对应的值展示即可
/**
* 目标:理解集合的嵌套
* 江苏省 = "南京市","扬州市","苏州市","无锡市","常州市"
* 湖北省 = "武汉市","咸宁市","孝感市","宜昌市","鄂州市"
* 河北省 = "石家庄市","唐山市","邢台市","保定市","张家口市"
*/
public class Test {
public static void main(String[] args) {
// 1、定义一个Map集合存储全部的省份信息,和其对应的城市信息
Map<String, List<String>> map = new HashMap<>();
// 定义一个ArrayList集合存储省份对应的城市信息
List<String> cities1 = new ArrayList<>();
Collections.addAll(cities1,"南京市","扬州市","苏州市","无锡市","常州市");
map.put("江苏省", cities1);
List<String> cities2 = new ArrayList<>();
Collections.addAll(cities2,"武汉市","咸宁市","孝感市","宜昌市","鄂州市");
map.put("湖北省", cities2);
List<String> cities3 = new ArrayList<>();
Collections.addAll(cities3,"石家庄市","唐山市","邢台市","保定市","张家口市");
map.put("河北省", cities3);
System.out.println(map);
List<String> cities = map.get("湖北省");
for (String city : cities) {
System.out.println(city);
}
}
}
Stream流
- 认识Stream
- Stream的常用方法
什么是Stream?
- 也叫Stream流,是JDK8开始新增的一套API(java.unit.Stream.*),可以用于操作集合或数组的数据
- 优势:Stream流大量的结合力Lambda的语法风格来编程,提供了一种更加强大,更加简单的方式操作集合或者数组中的数据,代码更简洁,可读性更好
体验Stream流
需求:把集合中所有以“张”开头,且是3个字的元素存储到一个新的集合中去
/**
* 目标:初步体验Stream流的方便与快捷
*/
public class StreamTest1 {
public static void main(String[] args) {
List<String> names = new ArrayList<>();
Collections.addAll(names,"张无忌","张三丰","张三","李四","王五");
System.out.println(names);
// names = [[张无忌, 张三丰, 张三, 李四, 王五]]
// 找出姓张,且 是3个字的名字,存入到一个新集合中去
List<String> list = new ArrayList<>();
for (String name : names) {
if (name.startsWith("张") && name.length() == 3) {
list.add(name);
}
}
System.out.println(list);
// 用Stream流解决这个需求
List<String> list2 = names.stream().filter(s -> s.startsWith("张"))
.filter(a -> a.length() == 3).collect(Collectors.toList());
System.out.println(list2);
}
}
Steram流的使用步骤
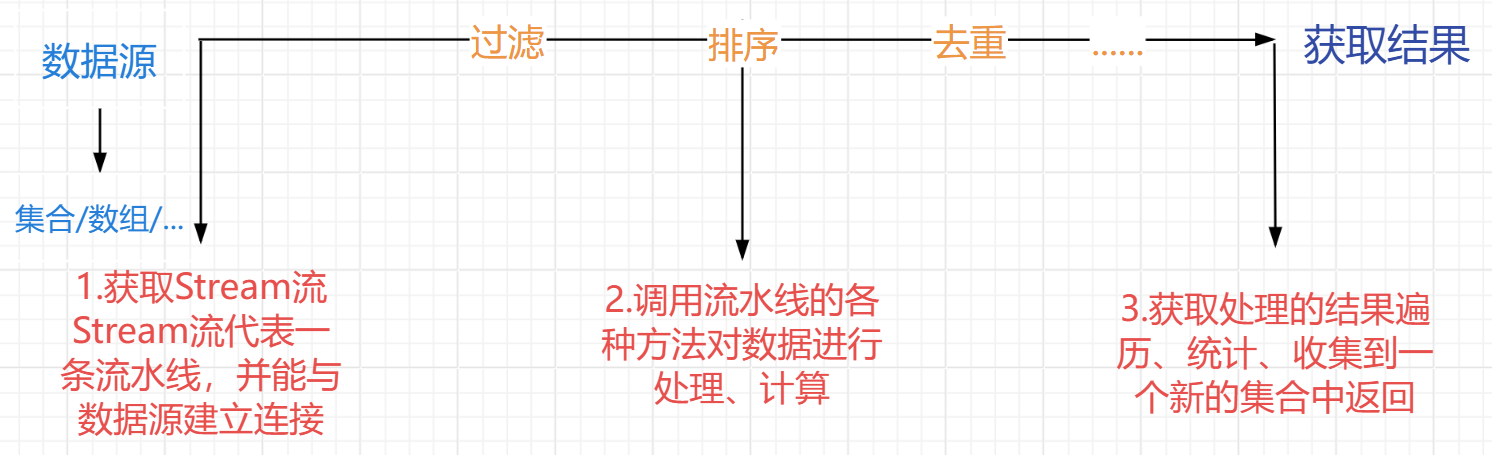
常用方法
- 获取Stream流
- 获取集合的Stream流
Collection提供的如下方法
| 方法名 | 说明 |
|---|---|
| default Stream stream() | 获取当前集合对象的Stream流 |
- 获取数组的Stream流
Arrays类提供的如下方法
| 方法名 | 说明 |
|---|---|
| Public static Stream Stream( T[] array ) | 获取当前数组的Stream |
Stream类提供的如下方法
| 方法名 | 说明 |
|---|---|
| Public static Stream of( T…values) | 获取当前接受数据的Stream流 |
public class Stream_Test2 {
public static void main(String[] args) {
// 1、如何获取List集合的Stream流?
List<String> names = new ArrayList<>();
Collections.addAll(names,"张无忌","张三丰","张三","李四","王五");
Stream<String> stream = names.stream();
// 2、如何获取Set集合的Stream流
Set<String> set = new HashSet<>();
Collections.addAll(set,"张无忌","张三丰","张三","李四","王五");
Stream<String> stream1 = set.stream();
// 输出名字里包含"张"的名字
stream1.filter(s -> s.contains("张")).forEach(s -> System.out.println(s));
// 3、如何获取Map集合的Stream流
Map<String,Double> map = new HashMap<>();
map.put("张无忌",166.4);
map.put("张三丰",169.5);
map.put("张三",176.8);
map.put("李四",163.4);
map.put("王五",163.4);
// 得到键的Stream流
Set<String> keys = map.keySet();
Stream<String> ks = keys.stream();
// 得到值的Stream流
Collection<Double> values = map.values();
Stream<Double> vs = values.stream();
// 得到键值对对象的Stream流
Set<Map.Entry<String, Double>> entries = map.entrySet();
Stream<Map.Entry<String, Double>> kvs = entries.stream();
// 输出名字里包含"三"的名字
kvs.filter(e -> e.getKey().contains("三"))
.forEach(e -> System.out.println(e.getKey() + ":" + e.getValue()));
// 4、如何获取数组的Stream流
String[] names2 = {"张无忌","张三丰","张三","李四","王五"};
Stream<String> s1 = Arrays.stream(names2);
Stream<String> s2 = Stream.of(names2);
}
}
- Stream流常见的中间方法
- 中间方法指的是调用完成后会返回新的Stream流,可以继续使用(链式编程)
| 方法名 | 说明 |
|---|---|
| Stream filter(Predicate< ? super T> predicate) | 用于对流中的数据进行过滤 |
| Stream sorted() | 对元素进行升序排序 |
| Stream sorted(Comparator <? super T> comparator) | 按照指定规则排序 |
| Stream limit(long maxSize) | 获取前几个元素 |
| Stream skip(long n) | 跳过前几个元素 |
| Stream distinct() | 去除流中重复的元素 |
| Stream map( Function < ? super T , ? extends R > mapper ) | 对元素进行加工,并返回对应的新流 |
| Static Stream concat(Stream a,stream b) | 合并a和b两个流为一个流 |
public class StreamTest3 {
public static void main(String[] args) {
List<Double> scores = new ArrayList<Double>();
Collections.addAll(scores, 88.5,100.0,60.0,99.0,48.5,49.5);
// 需求1:找出成绩大于等于60分的数据,并升序后,再输出
scores.stream().filter(s -> s >= 60).sorted().forEach(s -> System.out.println(s));
List<Student> students = new ArrayList<>();
Student s1 = new Student("张三",28,169.8);
Student s2 = new Student("张三",28,169.8);
Student s3 = new Student("李四",24,172.8);
Student s4 = new Student("王五",27,183.5);
Student s5 = new Student("赵六",22,166.8);
Collections.addAll(students, s1, s2, s3, s4, s5);
// 需求2:找出年龄大于等于23,且年龄小于等于30岁的学生,并按照年龄降序输出
students.stream().filter(s -> s.getAge() >= 23 && s.getAge() <= 30)
.sorted((o1,o2) -> o2.getAge() - o1.getAge())
.forEach(System.out::println);
System.out.println("----------------------------------------------------");
// 需求3:取出身高最高的前3名学生,并输出
students.stream().sorted((o1,o2) -> Double.compare(o2.getHeight(), o1.getHeight()))
.limit(3).forEach(System.out::println);
System.out.println("----------------------------------------------------");
// 需求4:取出身高倒数的2名学生,并输出
students.stream().sorted((o1,o2) -> Double.compare(o2.getHeight(), o1.getHeight()))
.skip(students.size() - 2).forEach(System.out::println);
System.out.println("----------------------------------------------------");
// 需求5:找出身高超过168的学生叫什么名字,要求去除重复的名字,再输出
// students.stream().filter(s -> s.getHeight() > 168).map(s -> s.getName())
// .distinct().forEach(System.out::println);
students.stream().filter(s -> s.getHeight() > 168).map(Student::getName)
.distinct().forEach(System.out::println);
// distinct去重复,自定义类型的对象(希望内容一样就认为重复,需要重写hashCode,equals方法)
students.stream().filter(s -> s.getHeight() > 168)
.distinct().forEach(System.out::println);
// 两个流合并成一个流
Stream<String> st1 = Stream.of("张三", "李四");
Stream<String> st2 = Stream.of("王五", "赵六");
Stream<String> allSt = Stream.concat(st1, st2);
allSt.forEach(System.out::println);
}
}
- Stream流常见的终结方法
- 终结方法指的是调用完成后,不会返回新的Sream流,没法继续使用流了
Stream提供的常见终结方法
| 方法名 | 说明 |
|---|---|
| void forEach(Consumer action) | 对此流运算后的元素执行变量 |
| long count() | 统计此流运算后的元素个数 |
| Optional max(Comparator < ? super T > comparator ) | 获取此流运算后的最大值元素 |
| Optional min(Comparator < ? super T > comparator ) | 获取此流运算后的最小值元素 |
- 收集Stream流:就是把Stream流操作后的结果转回到集合或数组中去返回
Stream流:方便操作集合 / 数组的手段;集合 / 数组:才是开发中的目的
Stream提供的常用终结方法
| 方法名 | 说明 |
|---|---|
| R collect( Collector collector) | 把流处理后的结果收集到一个指定的集合中去 |
| Object[] toArray() | 把流处理后的结果收集到一个数组中去 |
Collector工具类提供了具体的收集方式
| 方法名 | 说明 |
|---|---|
| Public static Collector toList() | 把元素收集到List集合中去 |
| Public static Collector toSet() | 把元素收集到Set集合中去 |
| Public static Collector toMap(Function KeyMapper,Function ValueMapper) | 把元素收集到Map集合中去 |
public class StreamTest4 {
public static void main(String[] args) {
List<Student> students = new ArrayList<>();
Student s1 = new Student("张三",28,169.8);
Student s2 = new Student("张三",28,169.8);
Student s3 = new Student("李四",24,172.8);
Student s4 = new Student("王五",27,183.5);
Student s5 = new Student("赵六",22,166.8);
Collections.addAll(students,s1,s2,s3,s4);
// 需求1:请计算出身高超过168的学生有几人
long count = students.stream().filter(s -> s.getHeight() > 168).count();
System.out.println(count);
// 需求2:请找出身高最高的学生对象,并输出
Student s = students.stream().max((o1,o2) -> Double.compare(o1.getHeight(),o2.getHeight())).get();
System.out.println(s);
// 需求3:请找出身高最矮的学生对象,并输出
Student ss = students.stream().min((o1,o2) -> Double.compare(o1.getHeight(),o2.getHeight())).get();
System.out.println(ss);
// 需求4:请找出身高超过170的学生对象,并放到一个新集合中去返回
// 流只能收集一次
List<Student> students1 = students.stream().filter(a -> a.getHeight() > 170 ).collect(Collectors.toList());
System.out.println(students1);
// 需求5:请找出身高超过170的学生对象,并把学生对象的名字和身高,存入到一个Map集合返回
Map<String,Double> map = students.stream().filter(a -> s.getHeight() >170)
.distinct().collect(Collectors.toMap(a -> a.getName(), a -> a.getHeight()));
System.out.println(map);
// 需求6:请找出身高超过170的学生对象,并存入到一个数组中
// Object[] arr = students.stream().filter(a -> a.getHeight() > 170).toArray();
Student[] arr = students.stream().filter(a -> a.getHeight() > 170).toArray( len -> new Student[len]);
System.out.println(Arrays.toString(arr));
}
}















 80
80

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









