




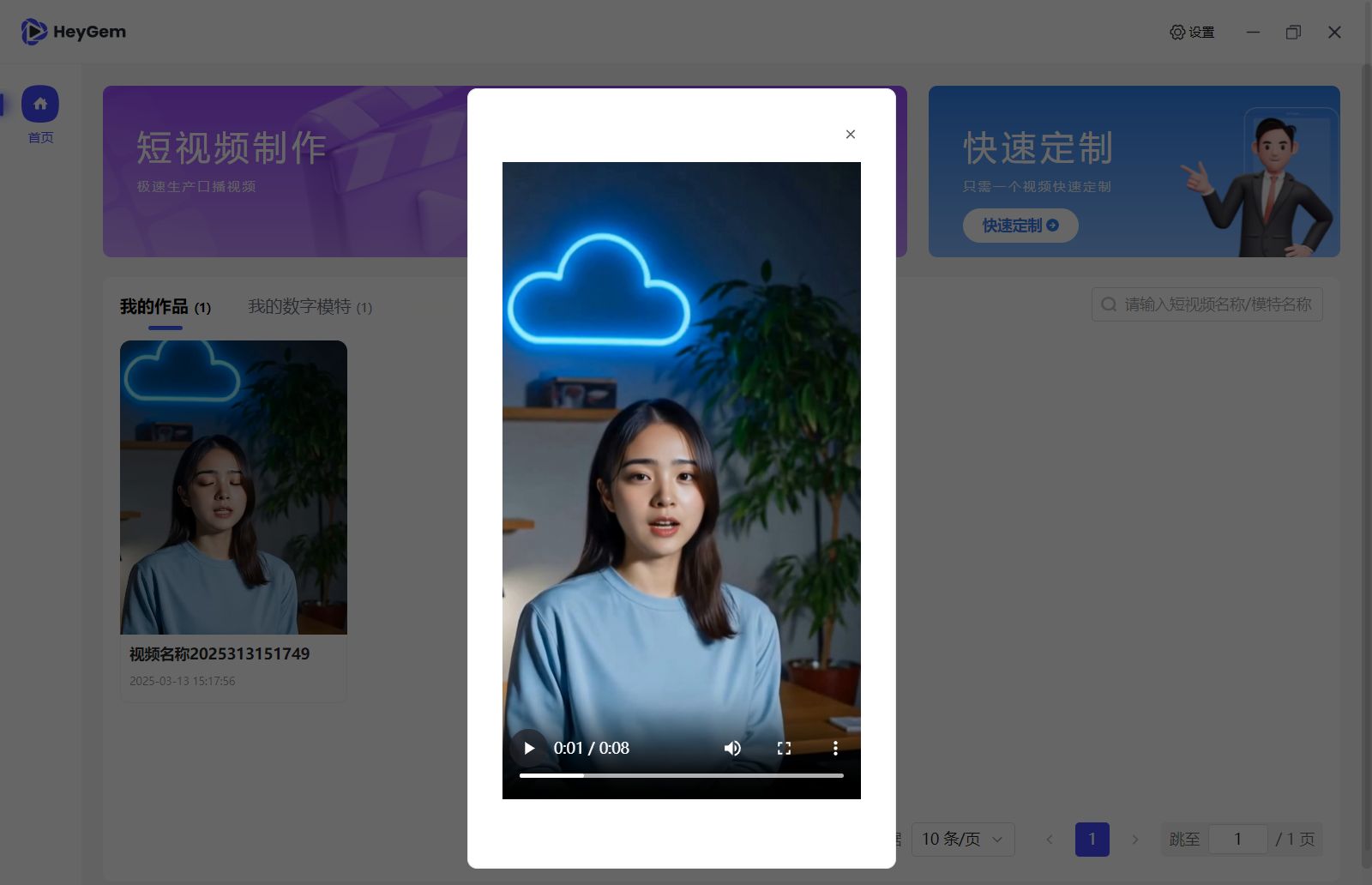
Heygem:开源前端界面的老六玩家
好消息!Heygem 在 GitHub 上开源了!不过,嘻嘻,只是前端界面开源,感觉更像是来 GitHub 刷一波知名度。不过这依然是个值得关注的工具。让我们先来看看它的官方介绍:
Heygem 是一款专为 Windows 系统打造的完全离线视频合成工具。它能精确克隆你的外貌和声音,将你的形象数字化。通过文字或语音驱动虚拟化身,你可以轻松制作视频。无需网络连接,在保护隐私的同时,享受高效便捷的数字体验。
核心功能
- 精准外貌与语音克隆
借助先进的 AI 算法,Heygem 高精度捕捉五官、轮廓等特征,构建逼真的虚拟模型。同时,它还能克隆语音,捕捉人声的细微特征,支持多种语音参数设置,打造高度相似的音色效果。 - 文字及语音驱动的虚拟化身
通过自然语言处理技术,Heygem 能将文本转化为流畅自然的语音,驱动虚拟化身开口“说话”。你也可以直接输入语音,虚拟化身会根据语音的节奏和语调,同步做出相应的动作和表情,表现更加生动。 - 高效视频合成
数字人视频画面与声音高度同步,口型匹配自然流畅,智能优化音视频效果,带来极佳的视听体验。 - 多语言支持
支持八种语言脚本:英语、日语、韩语、中文、法语、德语、阿拉伯语和西班牙语,满足全球化需求。
主要优势
- 完全离线操作:无需联网,保护用户隐私,避免数据泄露风险。
- 用户友好:界面简洁直观,即使是技术小白也能快速上手。
- 多模型支持:支持导入多种模型,并通过一键启动包管理,灵活适配不同创作场景。
技术支撑
- 语音克隆技术:基于 AI 生成与样本高度相似的语音,涵盖语调、语速等细节。
- 自动语音识别:将语音转化为文本,让计算机“听懂”你的指令。
- 计算机视觉技术:用于面部识别和唇部运动分析,确保唇形与语音完美匹配。
更棒的是,Heygem 还支持通过 Docker 进行本地部署,部署后甚至可以批量生成视频!下面我来详细讲讲如何在 Windows 上实现本地部署。
Windows 本地部署 Heygem 教程
步骤 1:安装 WSL
- 打开 PowerShell(在任务栏搜索“PowerShell”即可找到)。
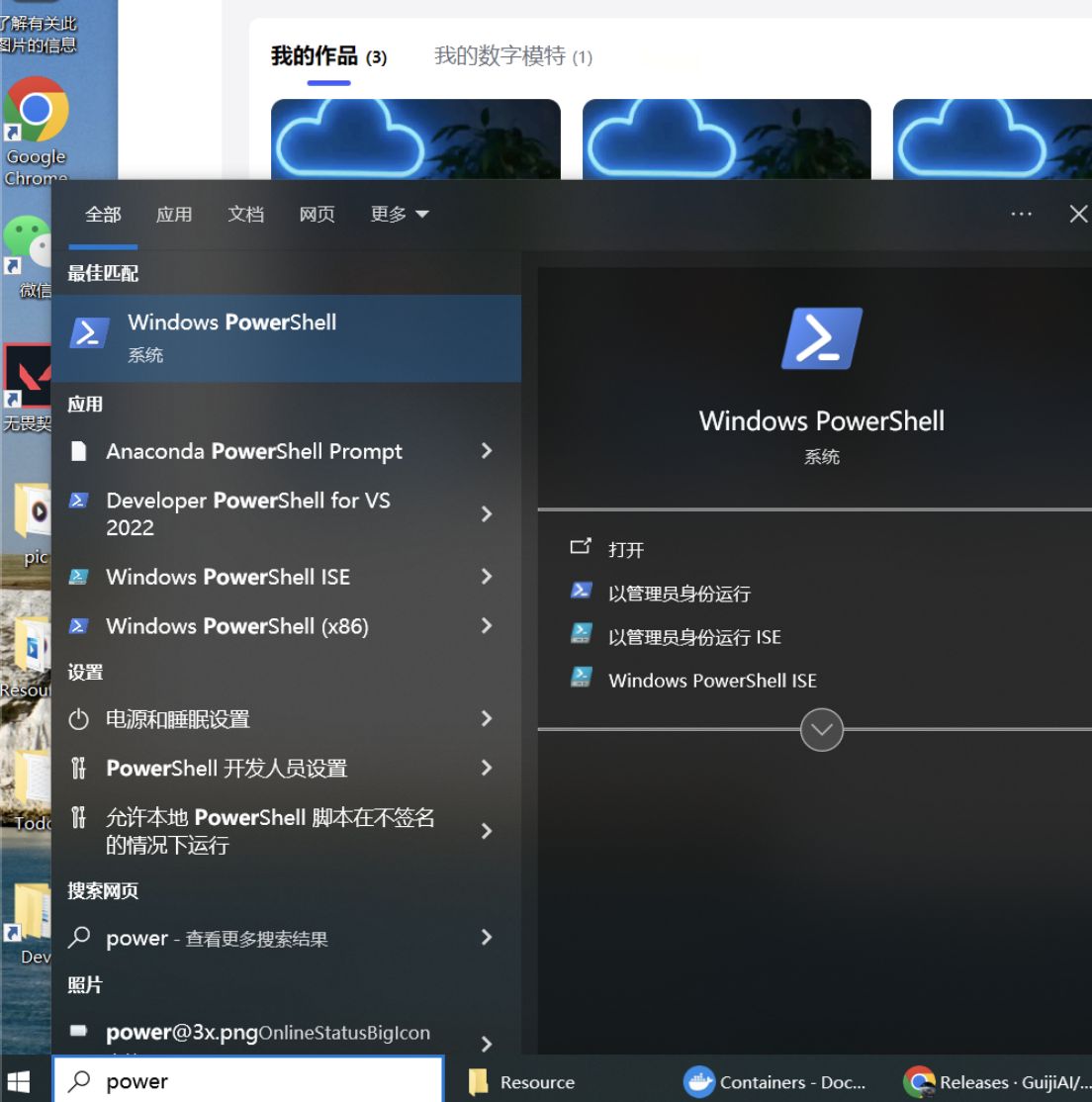
- 输入以下指令并回车:wsl --install
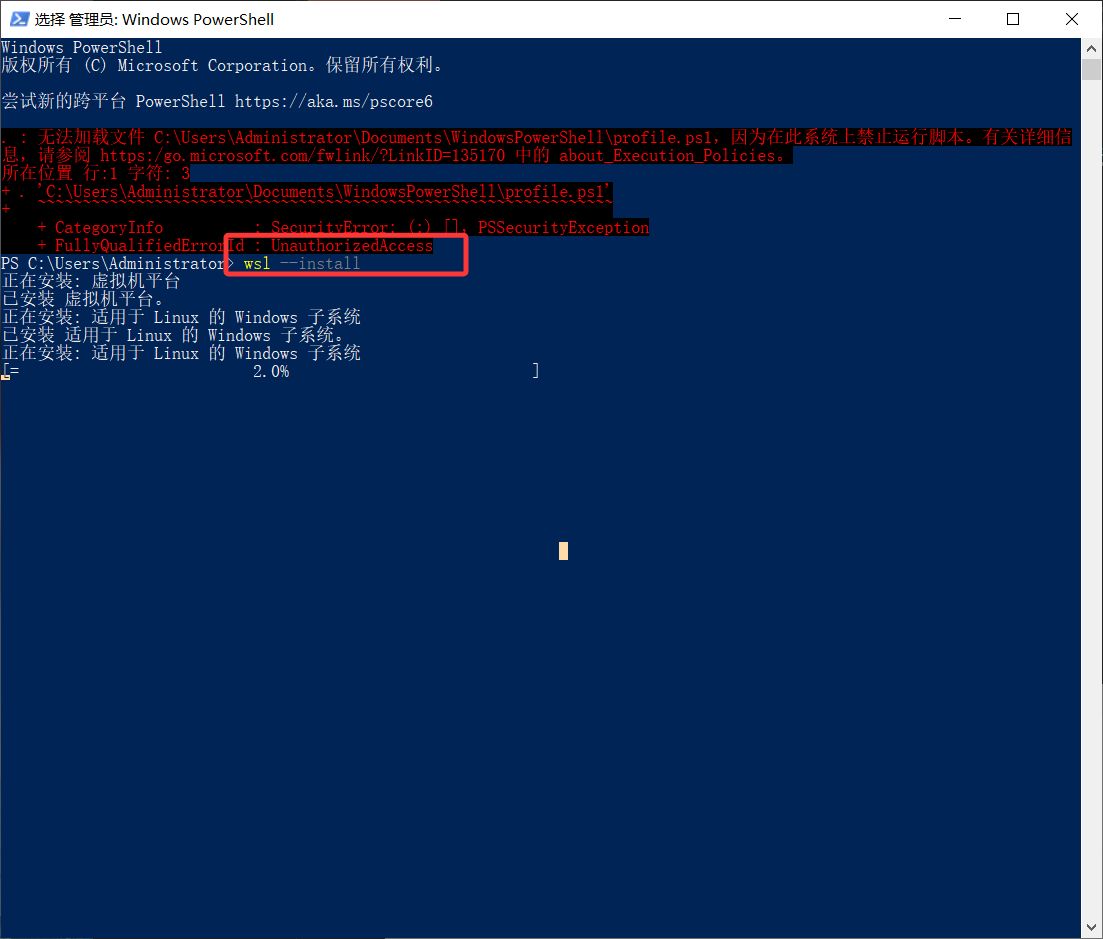
- 安装完成后,重启系统。
- 重启后再次打开 PowerShell,输入以下指令 WSL: wsl --update 检查是否安装成功,如下图则成功安装
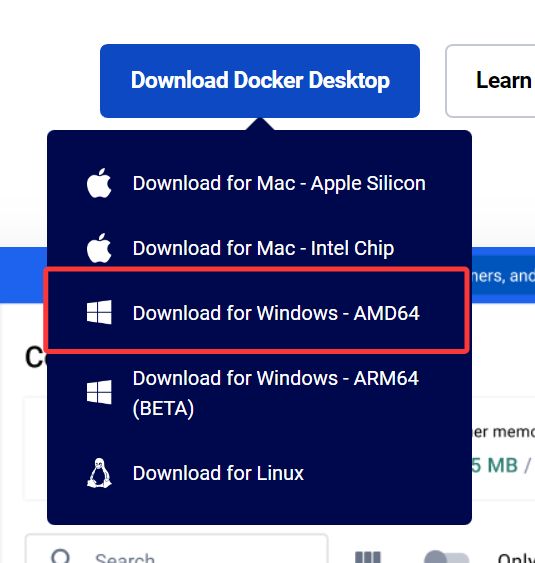
步骤 2:安装 Docker
- 前往 Docker 官网下载适用于 Windows 的版本(通常为 Windows AMD64)。
- 下载完成后安装,接受协议,首次运行时可跳过登录。
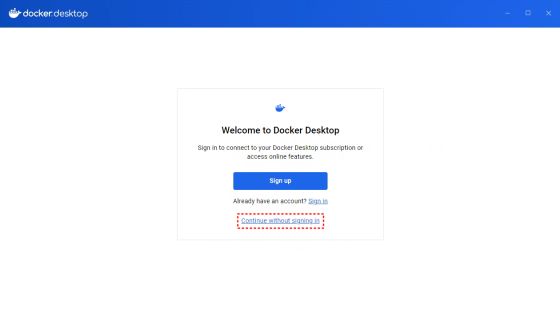
- 打开设置,调整镜像存储位置,镜像文件比较大70~80G,选择合适的盘,设置完成后点击“Apply & Restart”。
步骤 3:部署 Heygem
- 前往 Heygem github官网 https://github.com/GuijiAI/HeyGem.ai/tree/main/deploy,下载 Docker 部署文件。
你无需关心文件内容,只需使用 Docker 指令即可。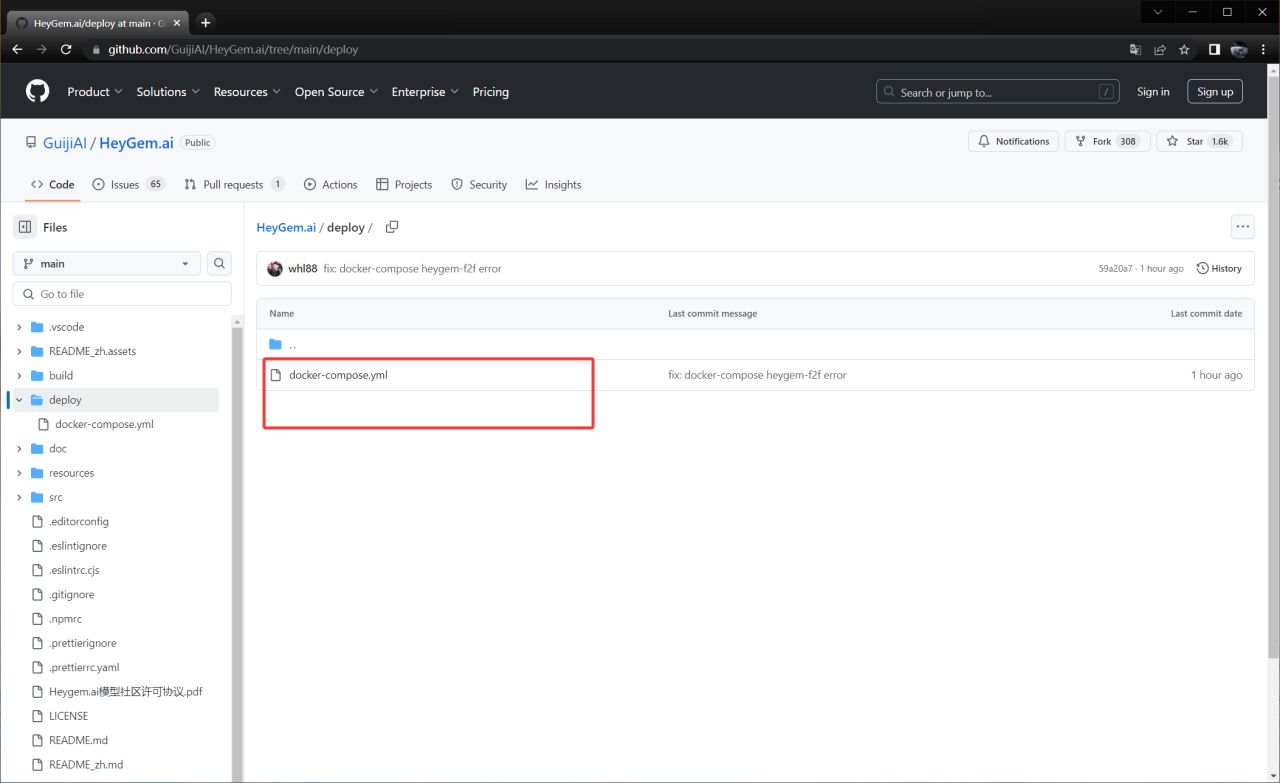
- 进入下载文件夹,在地址栏输入 cmd 并回车,打开命令行窗口。
- 在命令行输入以下指令: docker-compose up -d 这条指令会创建并启动容器,以后台模式运行。
根据网络情况好坏,下载镜像可能需要 1-2 小时(建议全程科学上网)。
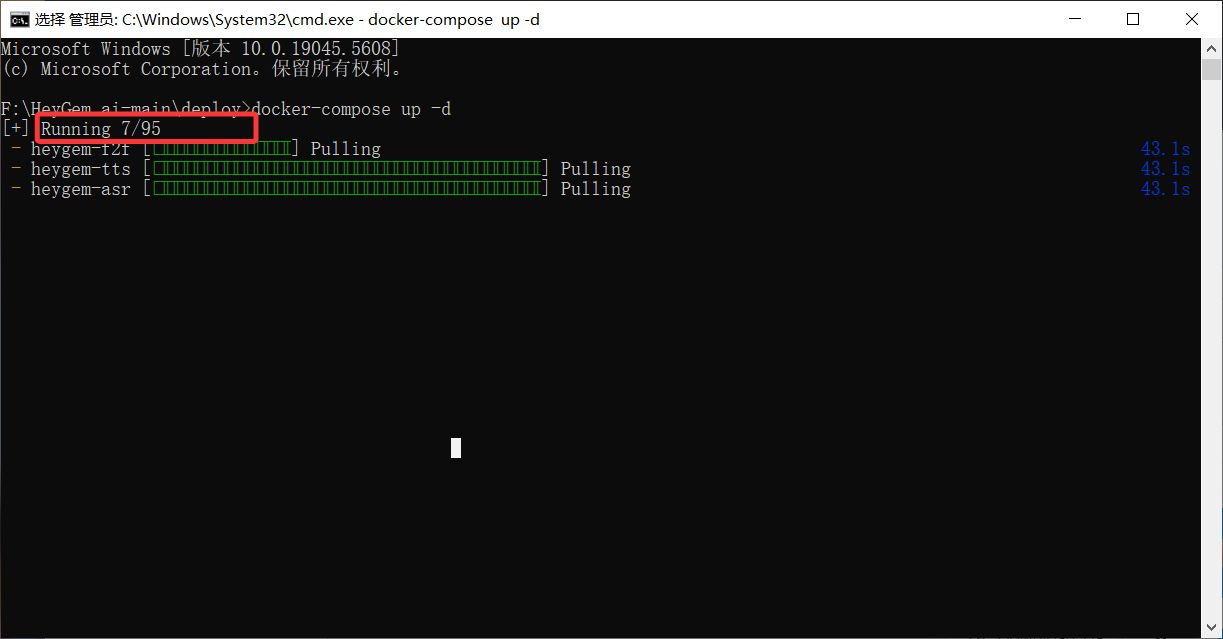
- 下载完成后,打开 Docker Desktop,在“Containers”中确认三个镜像正常运行(正确运行图标为正方形而非三角形)。
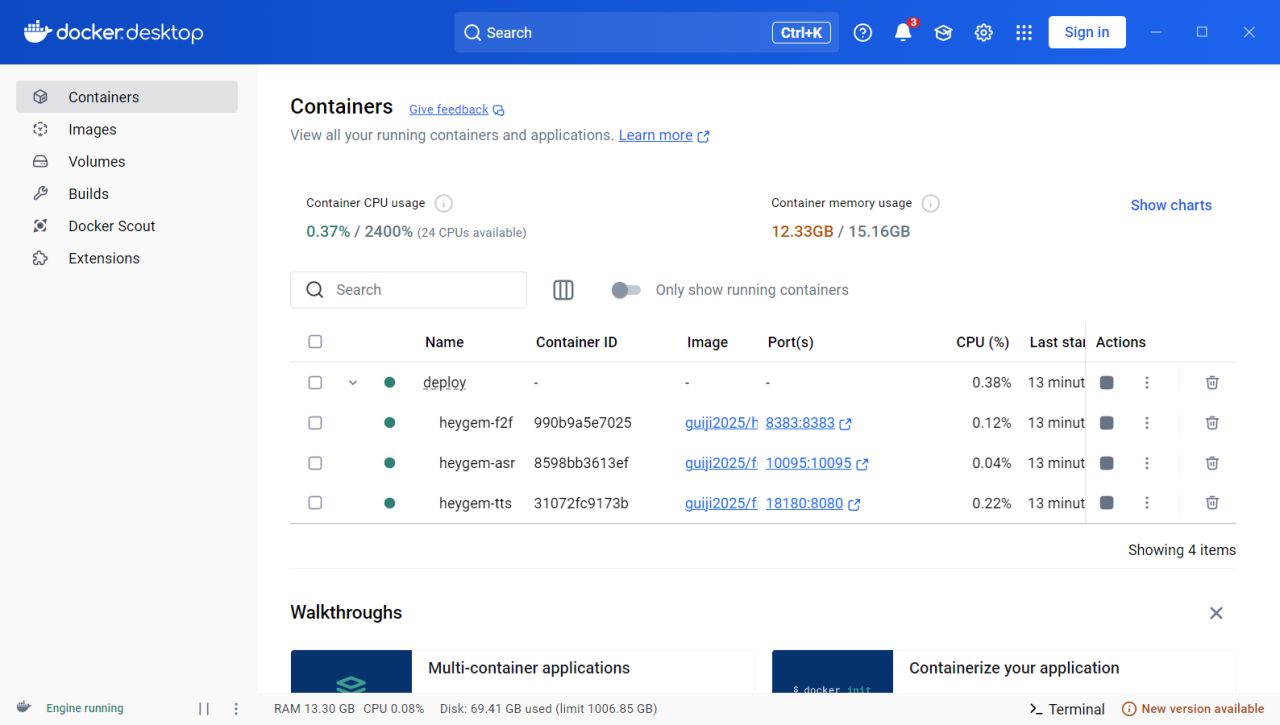
[Docker Desktop 中三个镜像运行状态截图]
至此,Heygem 的后端服务已部署完成。因为关键操作(如唇形同步模型)都集成在 Docker 。
步骤 4:安装前端界面
- 前往 GitHub 上的 Heygem 托管页面,下载运行界面 EXE 程序。
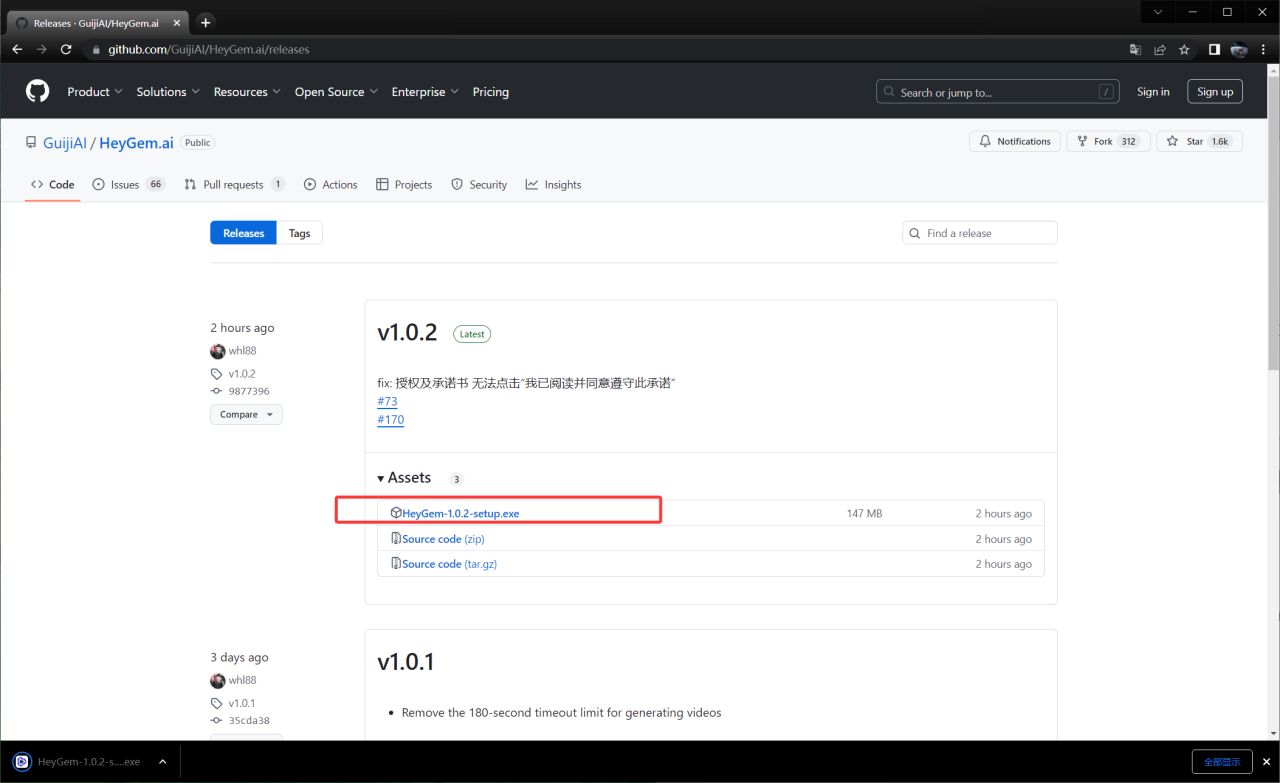
[GitHub 下载界面截图] https://github.com/GuijiAI/HeyGem.ai/releases - 下载并安装后即可使用。
使用 Heygem 打造数字人
- 快速定制数字模特
点击“快速定制”,输入模特名称,上传模特视频,点击提交。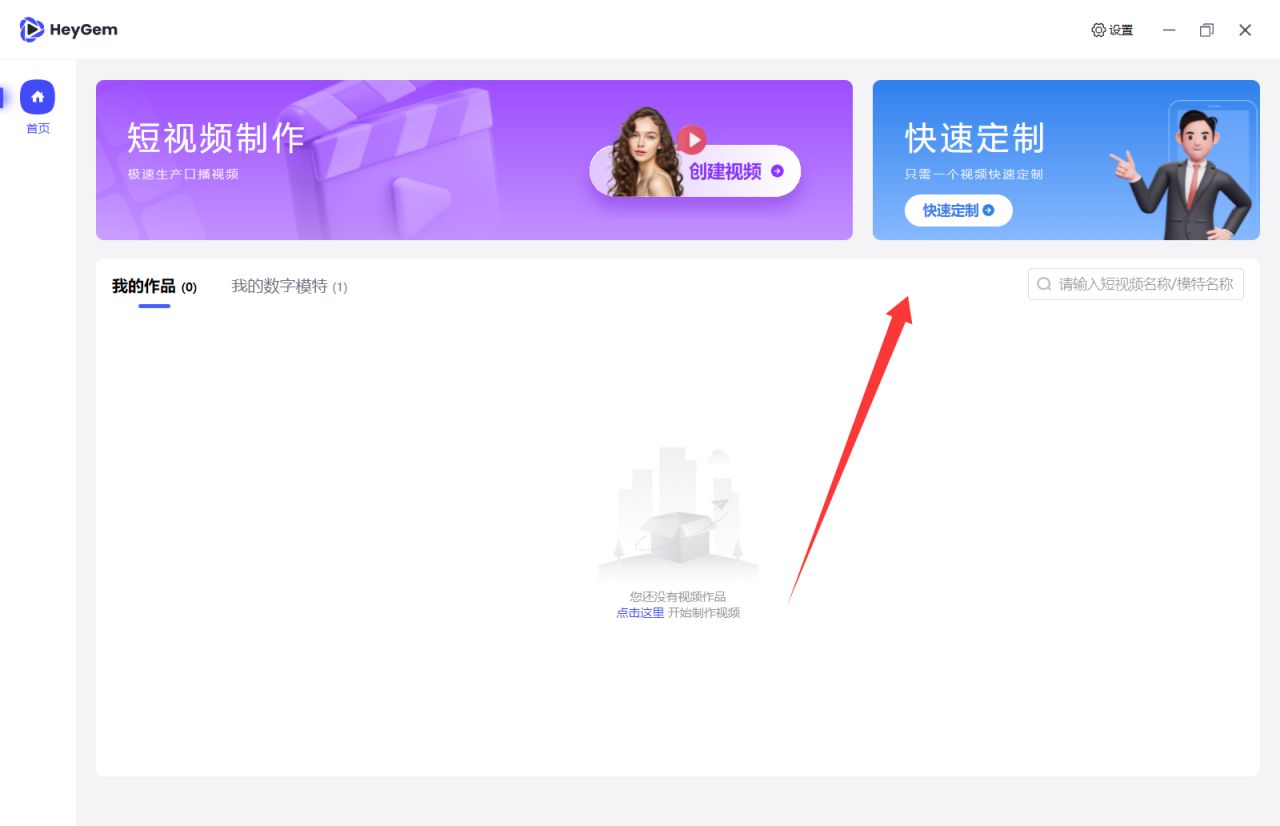
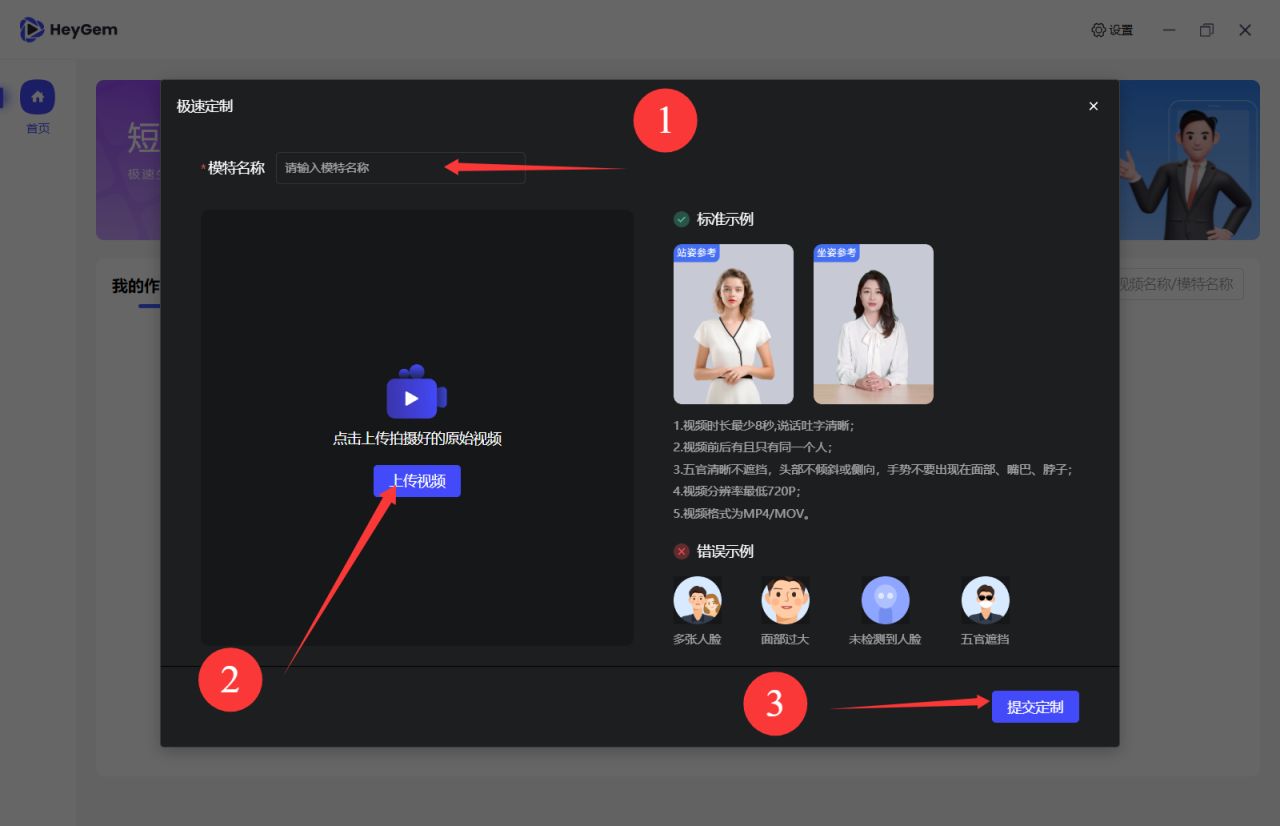
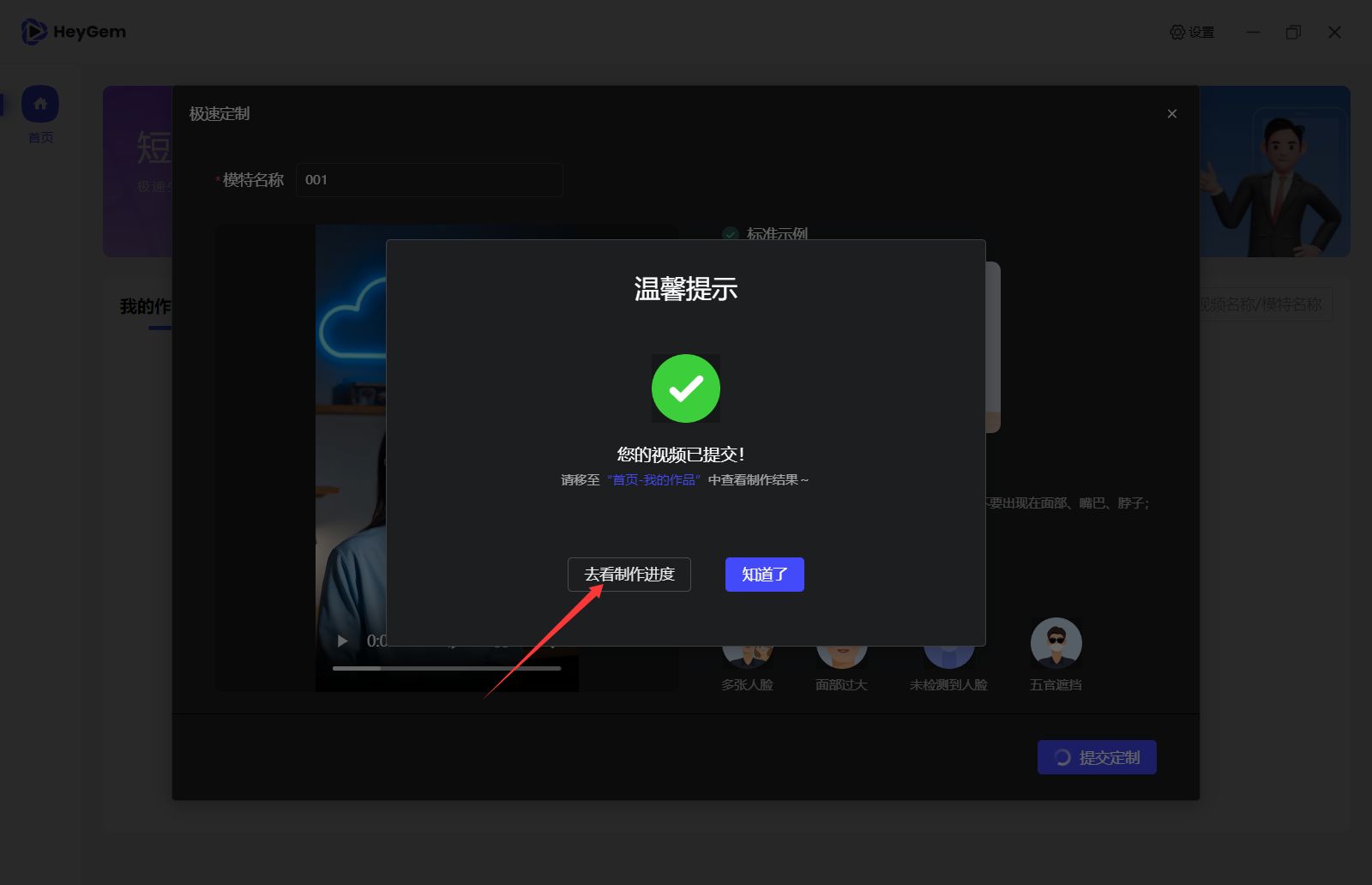 稍等片刻,回到主页即可在“我的数字模特”中看到结果。
稍等片刻,回到主页即可在“我的数字模特”中看到结果。 - 生成视频
鼠标移到数字模特上,点击“做视频”按钮,进入编辑界面。
 你可以输入文本或上传音频生成视频。
你可以输入文本或上传音频生成视频。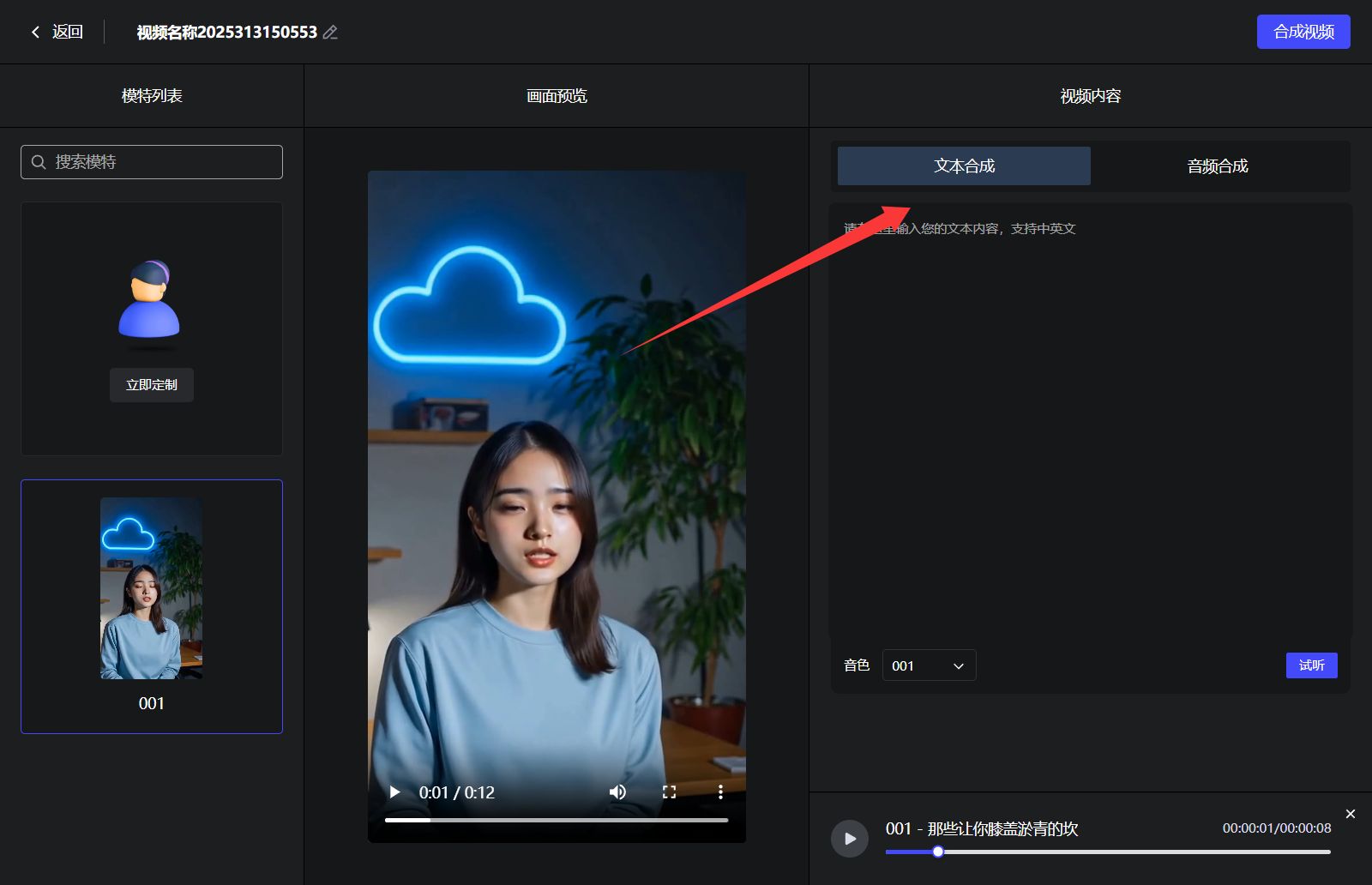
- 文本合成:仅提供一种音色,略显机械。
- 音频推荐:使用 CosyVoice 一键包克隆音色,上传音频后再合成,效果更自然。CosyVoice 一键包下载地址在以前的文章中有讲过,下载解压即可使用
- 批量生成与常见问题
Heygem 支持批量生成,但前一个视频未完成时,后续任务会排队。
- 如果长时间卡在 20%:
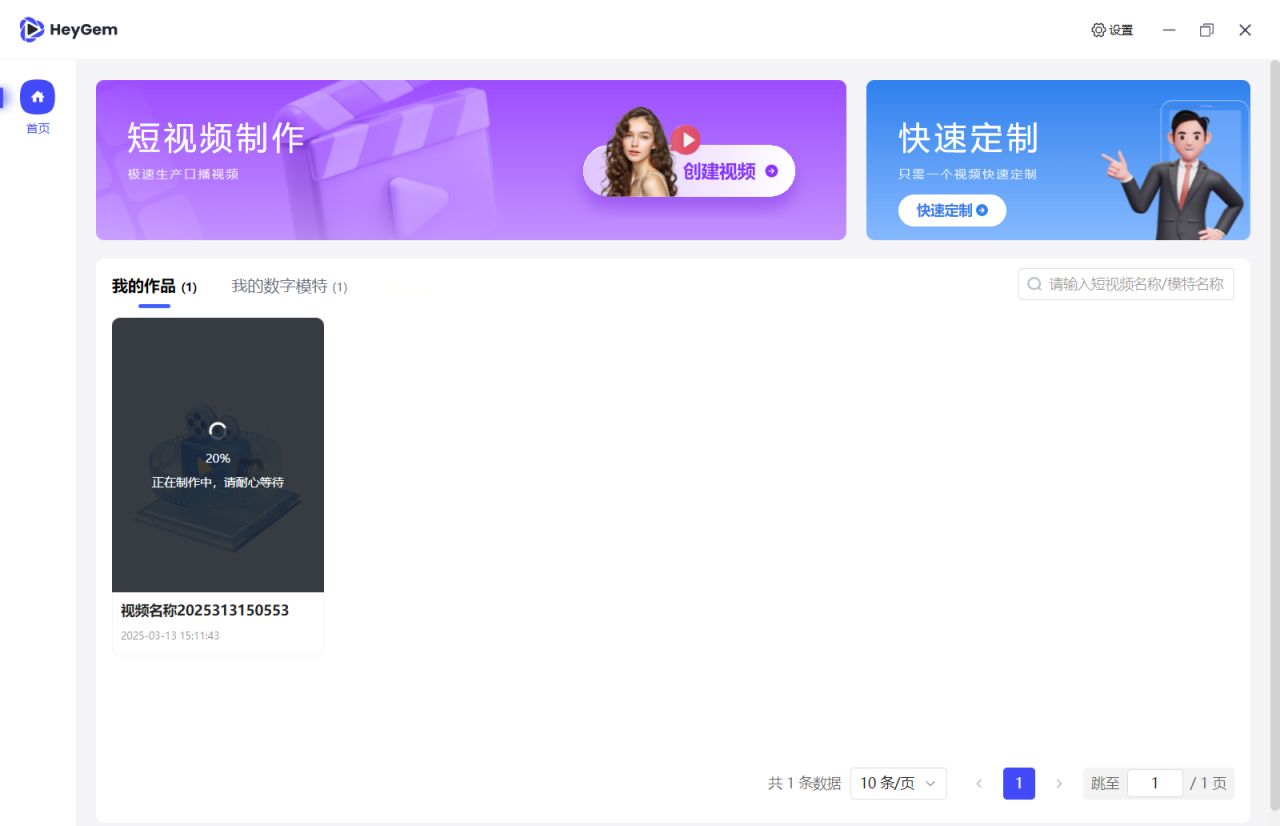
[生成进度卡在 20% 的截图] - 检查显卡占用,一般来说你的显卡比较好,是不需要太长时间。如果长时间卡在20%,注意是长时间。
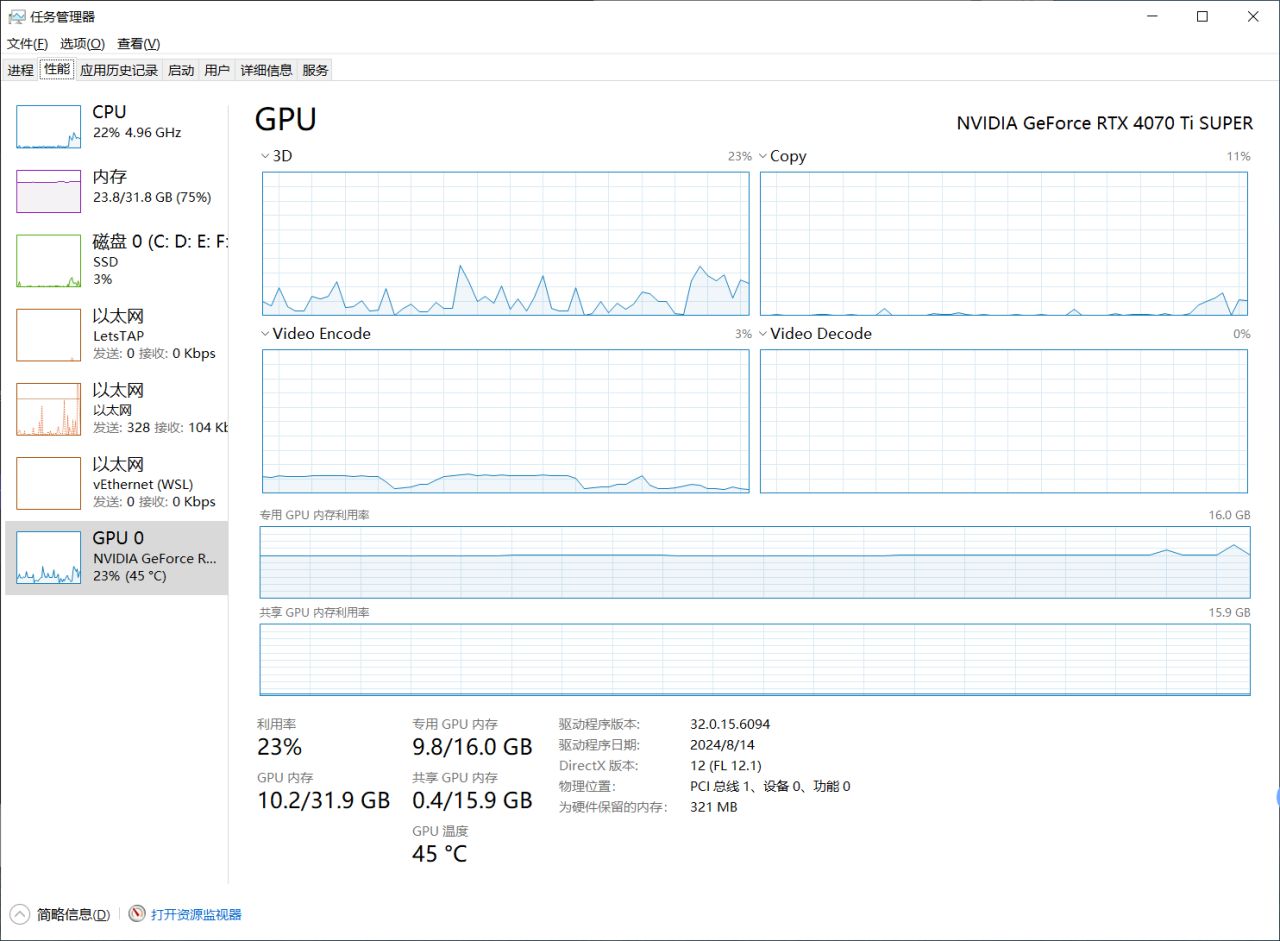
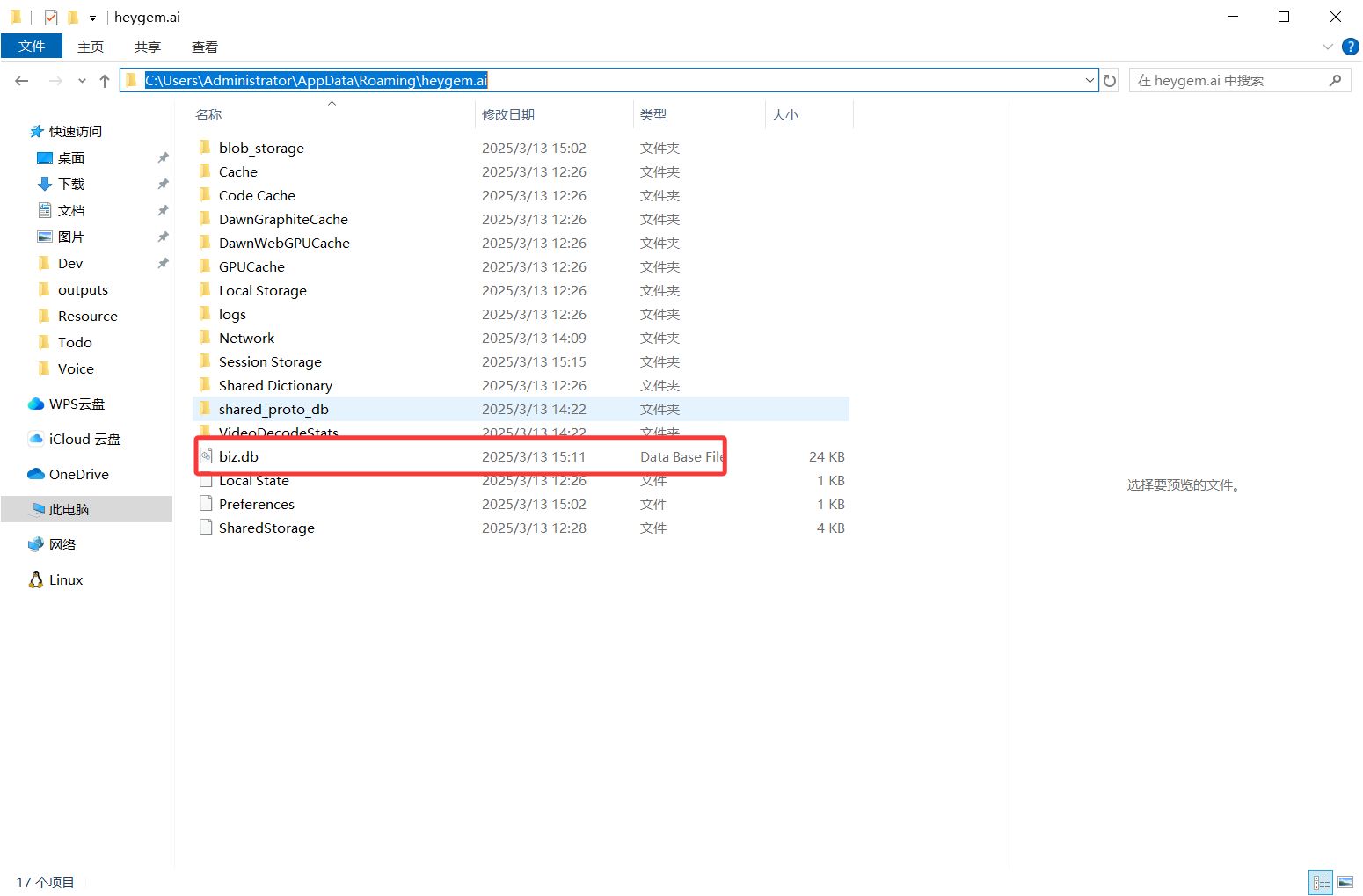
[显卡占用截图] - 若卡住,前往用户 AppData 目录删除软件数据库,重新上传模特和素材即可。
- 检查显卡占用,一般来说你的显卡比较好,是不需要太长时间。如果长时间卡在20%,注意是长时间。
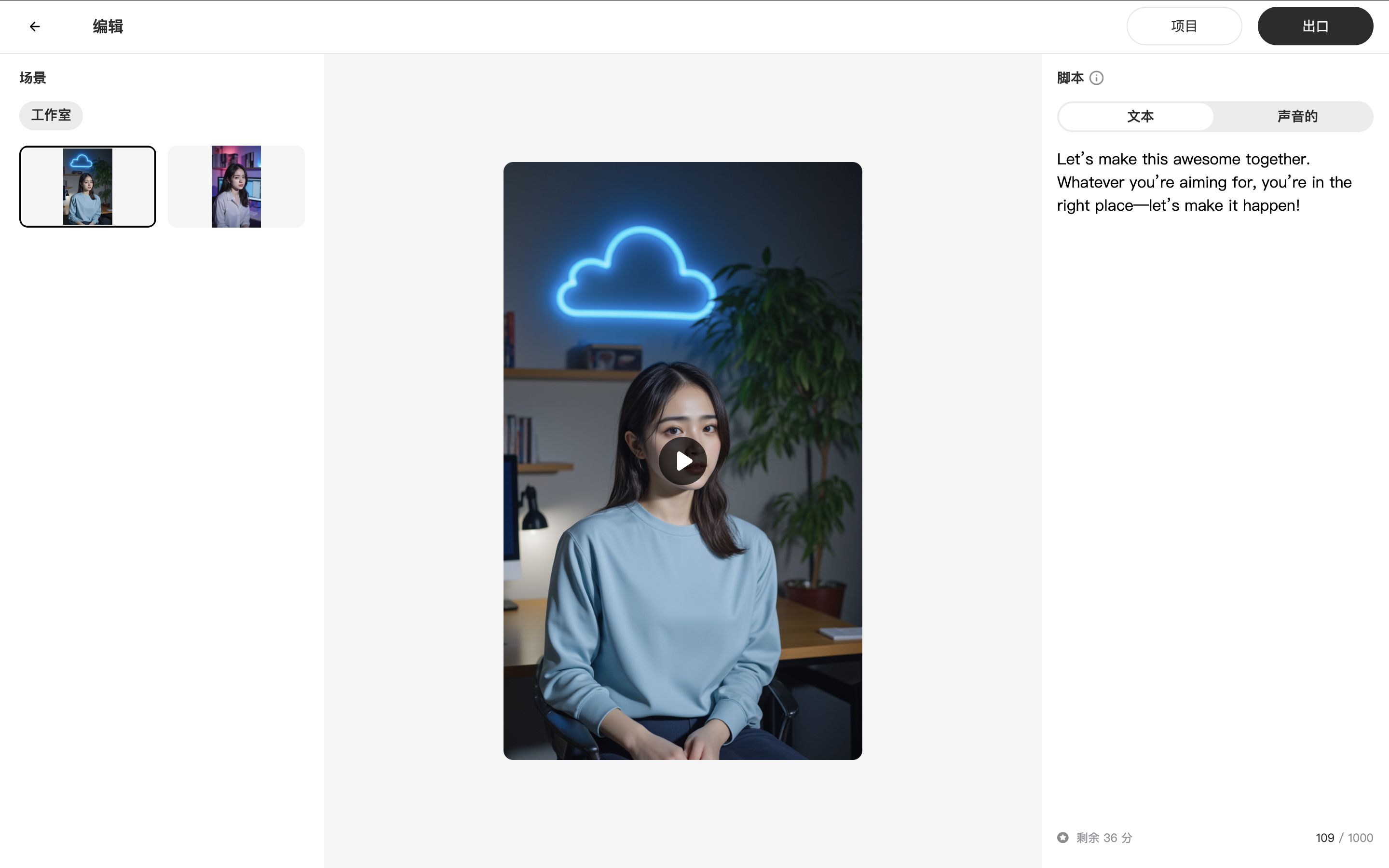
网页版 AI 数字人:Humva.com
除了 Heygem,还有一个网页工具——Humva.com。它能通过单张图片生成数字人,还支持更换场景和衣着!
使用方法
- 进入 Humva.com,点击“Create Avatar”。
- 上传一张头像,生成数字人模特。
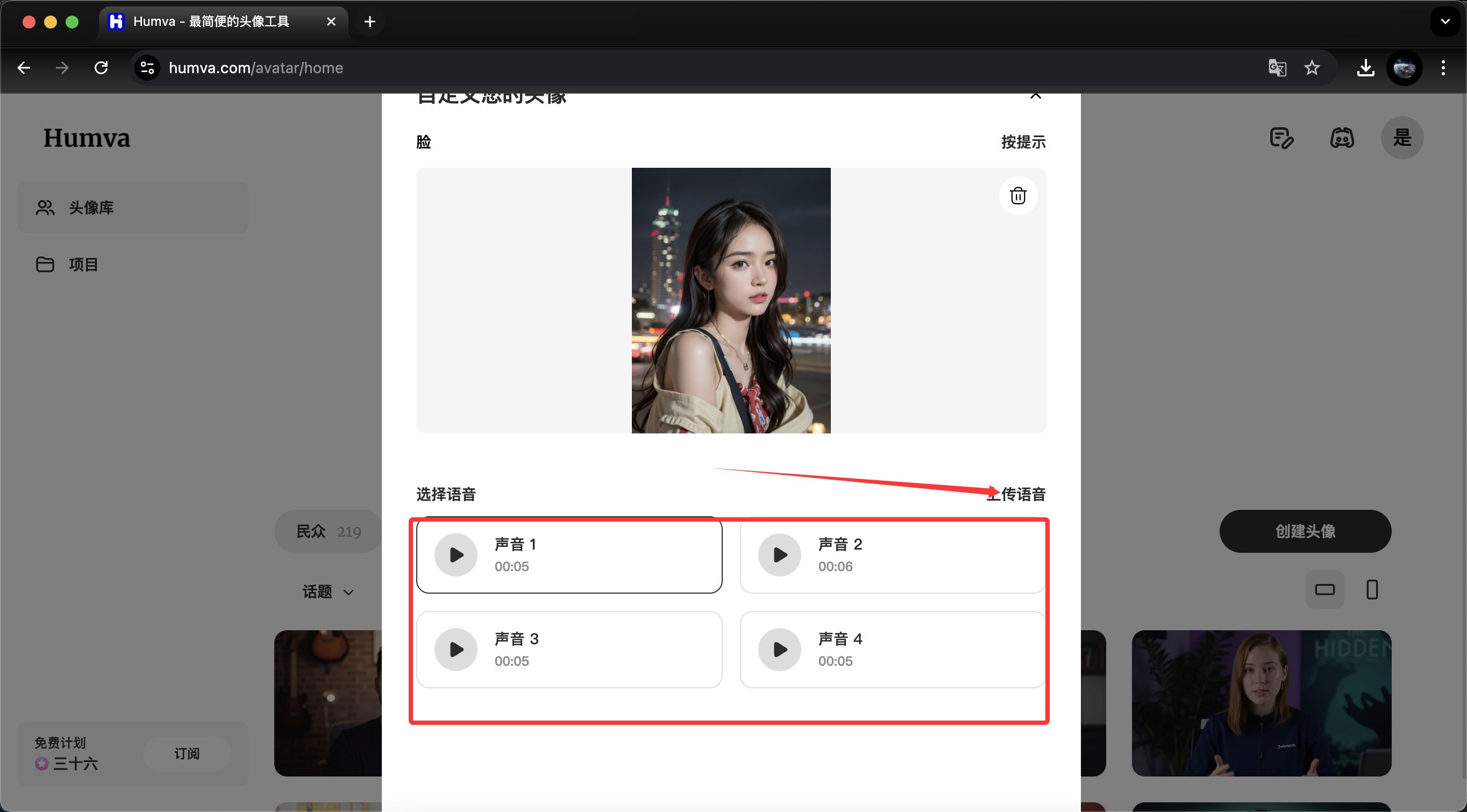
- 选择音色(默认提供几种,或上传音频),挑选主题场景(如工作室、户外、卡通等)和衣着风格。
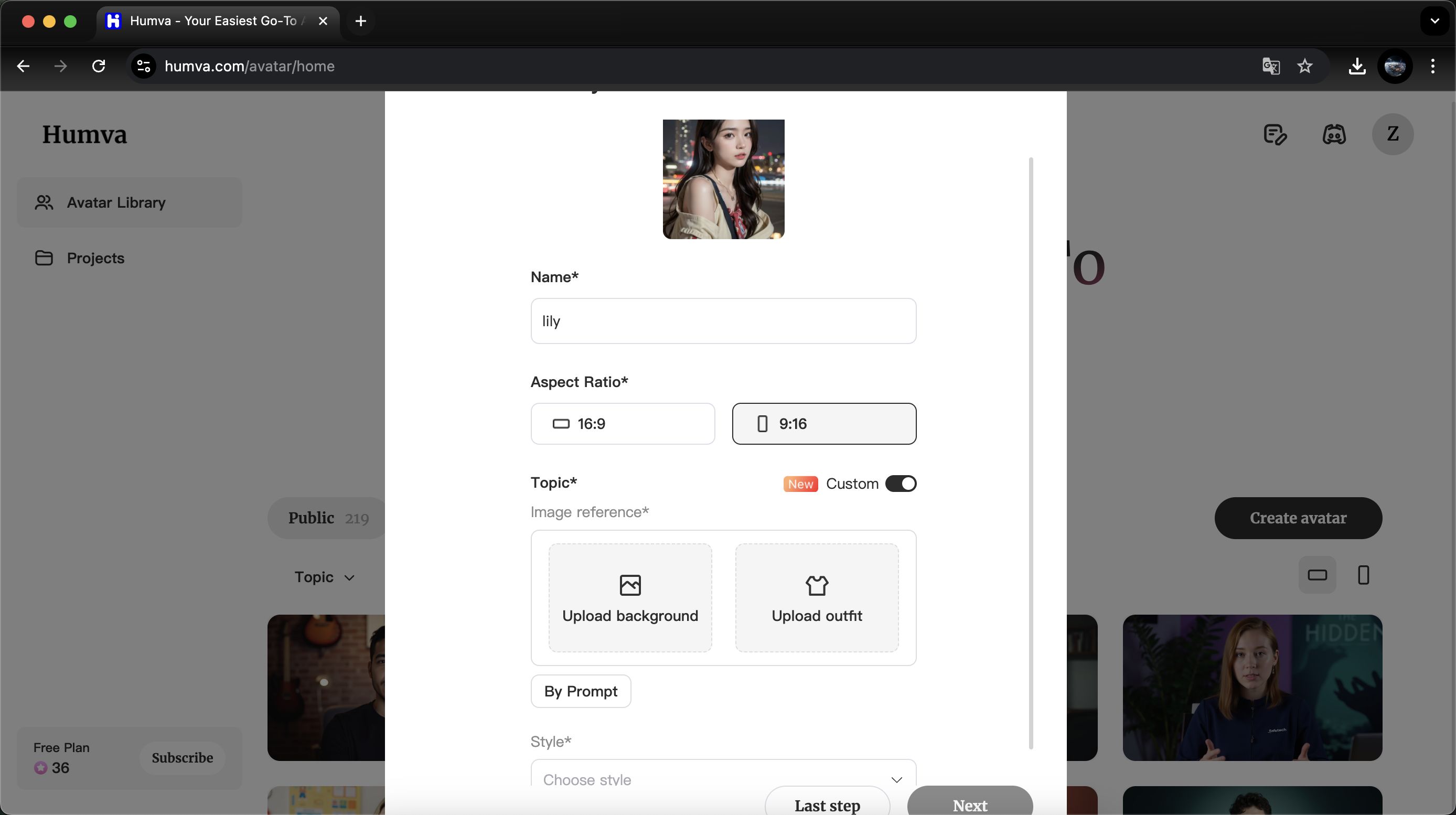
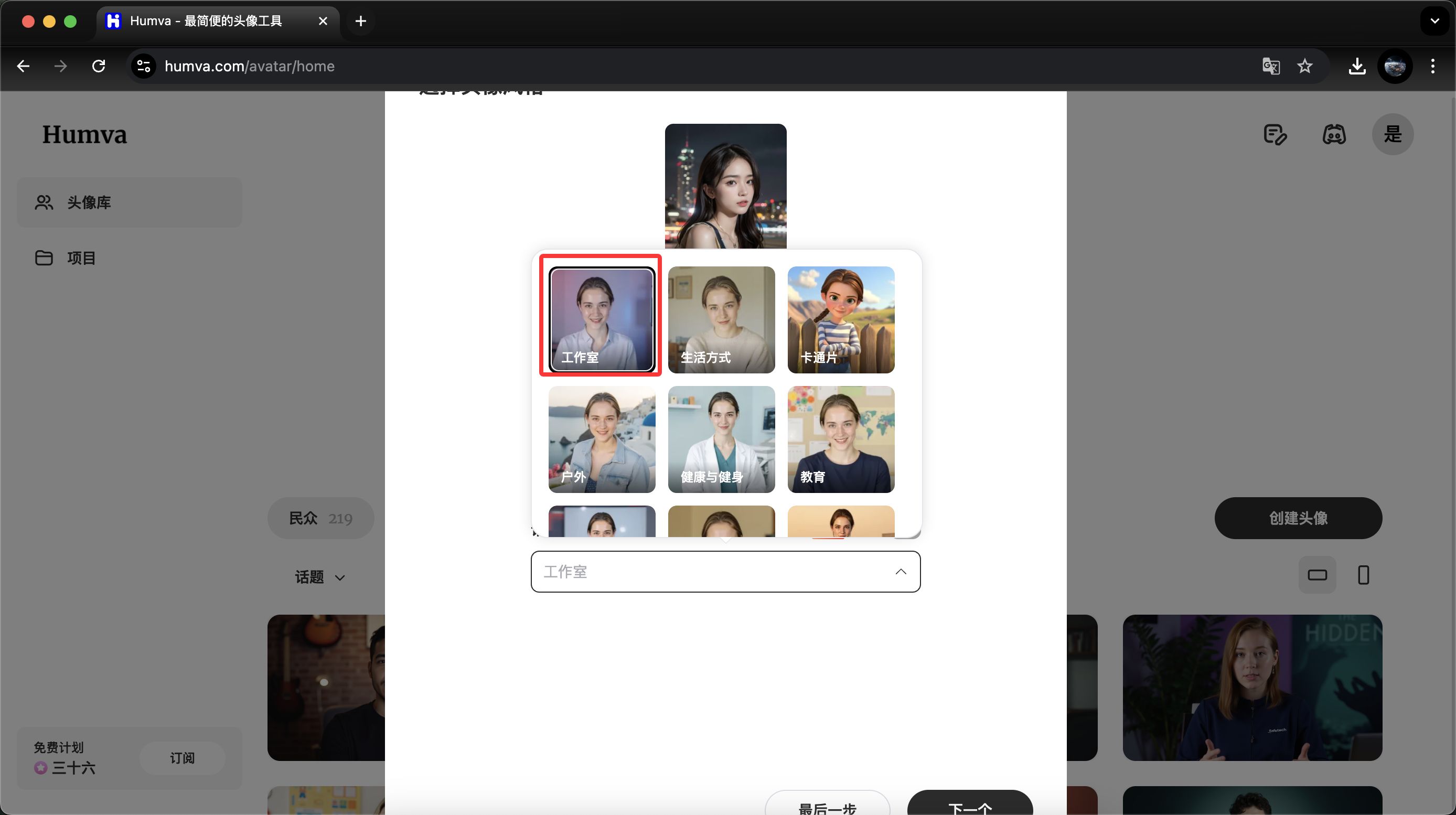
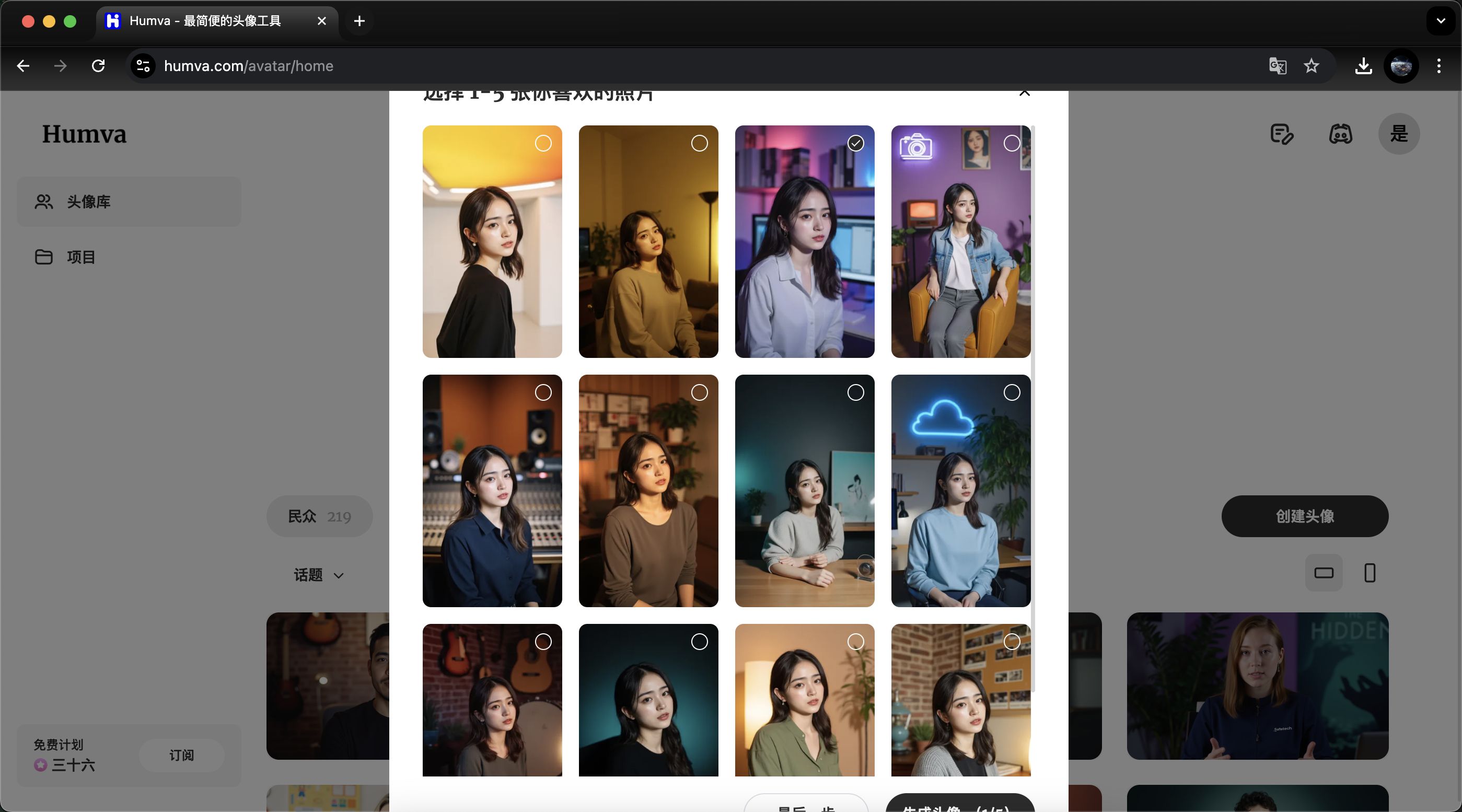
- 等待生成后,在“我的头像”中查看不同风格的数字人。
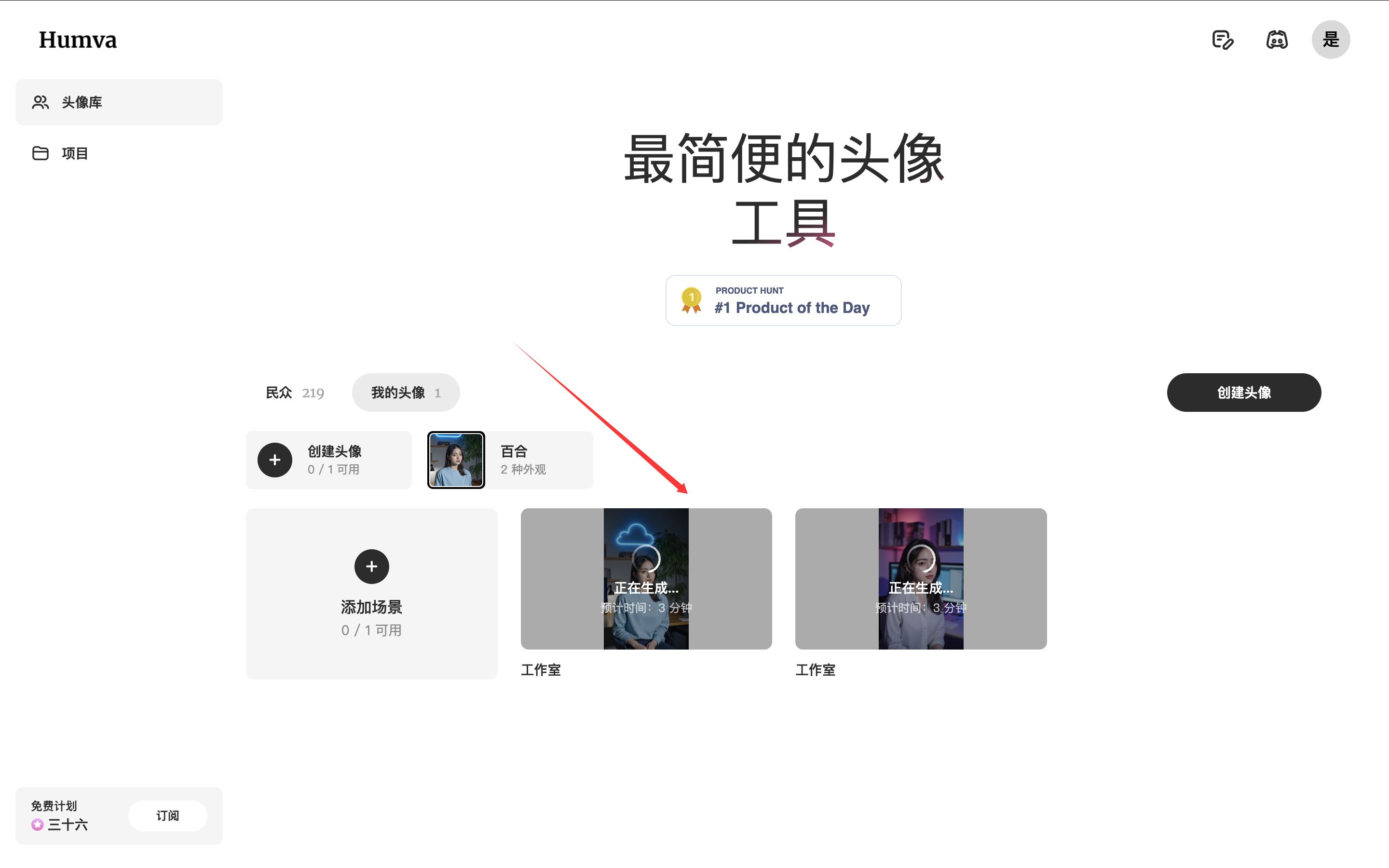
- 点击进入,使用文本或音频生成视频。
总结
Heygem 和 Humva 各有千秋:
- Heygem 适合需要离线操作和本地部署的用户,功能强大且隐私有保障。
- Humva 则更轻便,基于网页即可实现多样化数字人创作。
无论是口播视频还是唇形同步,AI 数字人正在改变我们的创作方式。

















 1574
1574

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









