







最近发现了一个让人眼前一亮的工具——FramePack,它能用一块普通的6GB显存笔记本GPU,生成60秒电影级的高清视频画面,效果堪称炸裂!那么我们就把他本地部署起来玩一玩、下载离线一键整合包,或者是用云算力快速上手。接下来,我带大家看看FramePack的硬核实力,以及如何用它让一张静态美女图片“舞动”起来!
实际效果怎么样?先来个小实验!
想生成一段高质量视频,起点自然是一张高质量图片。你可以先用Stable Diffusion 或者 Midjourney生成了一张精美的美女写实图片。接下来,用FramePack让这张静态图片“动起来”,变成一段优雅的舞蹈视频。
实验步骤:
-
生成静态图片:用Stable Diffusion或 Midjourney 生成一张高分辨率美女图片。

-
FramePack上场:将图片上传到本地部署/云算力的FramePack网页。
-
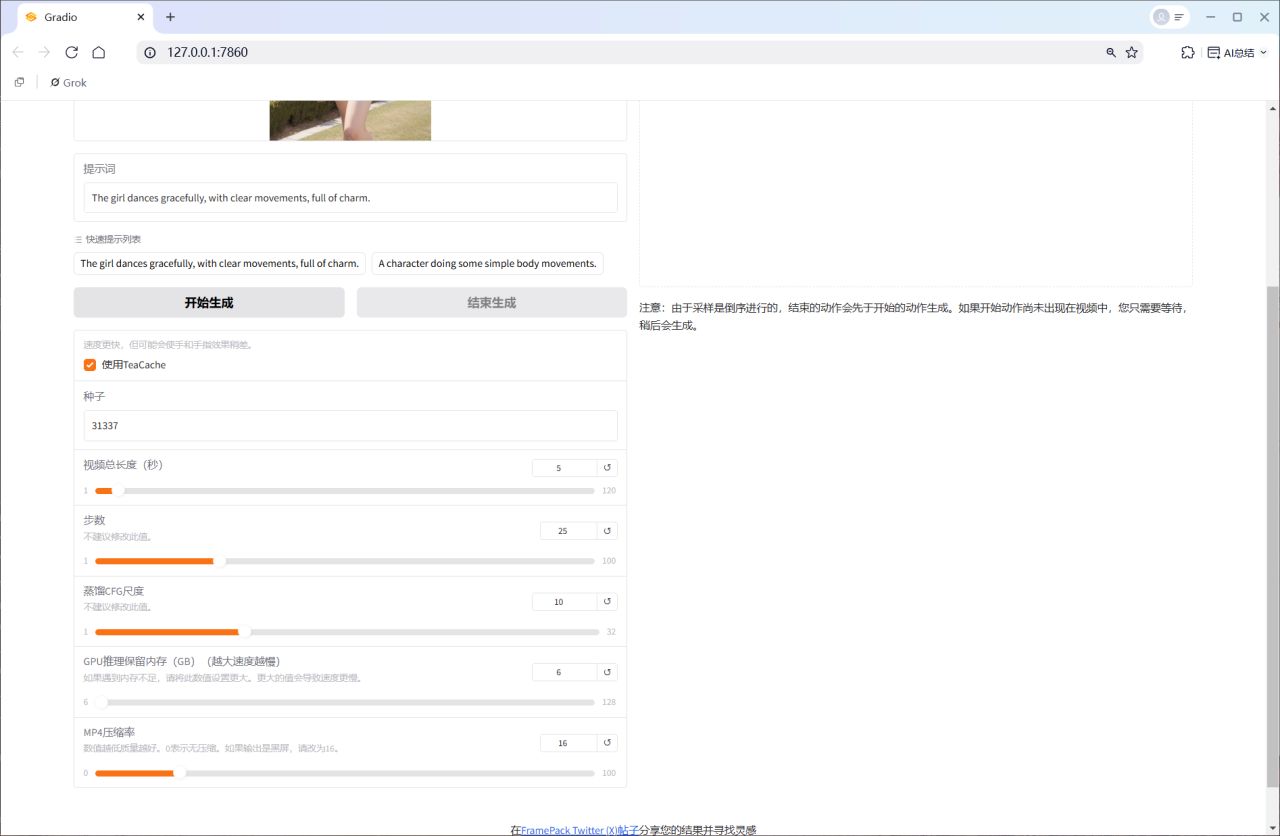
生成视频:运行后,FramePack逐帧预测,画面流畅,动作自然,宛如电影镜头!
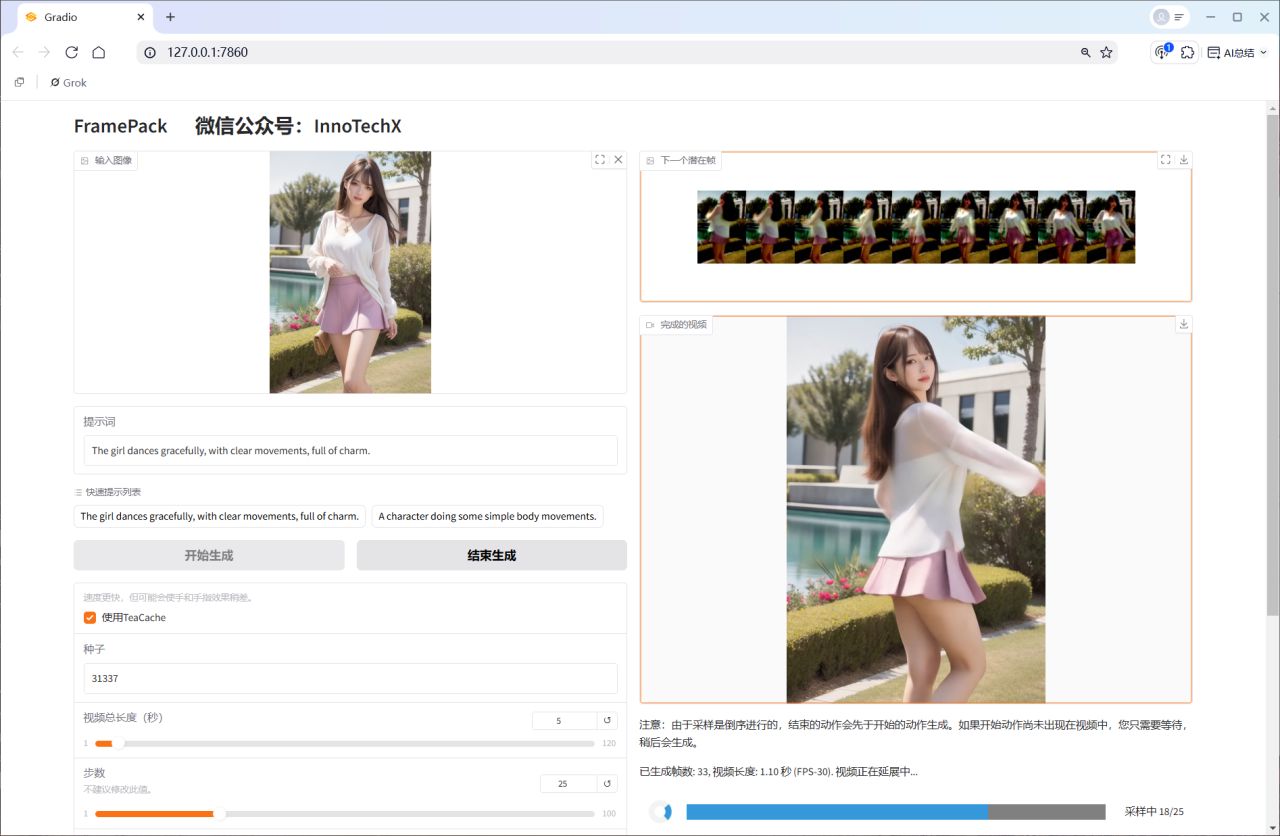
生成过程中,你可以实时看到每一帧的生成效果,这种即时反馈真的太友好!
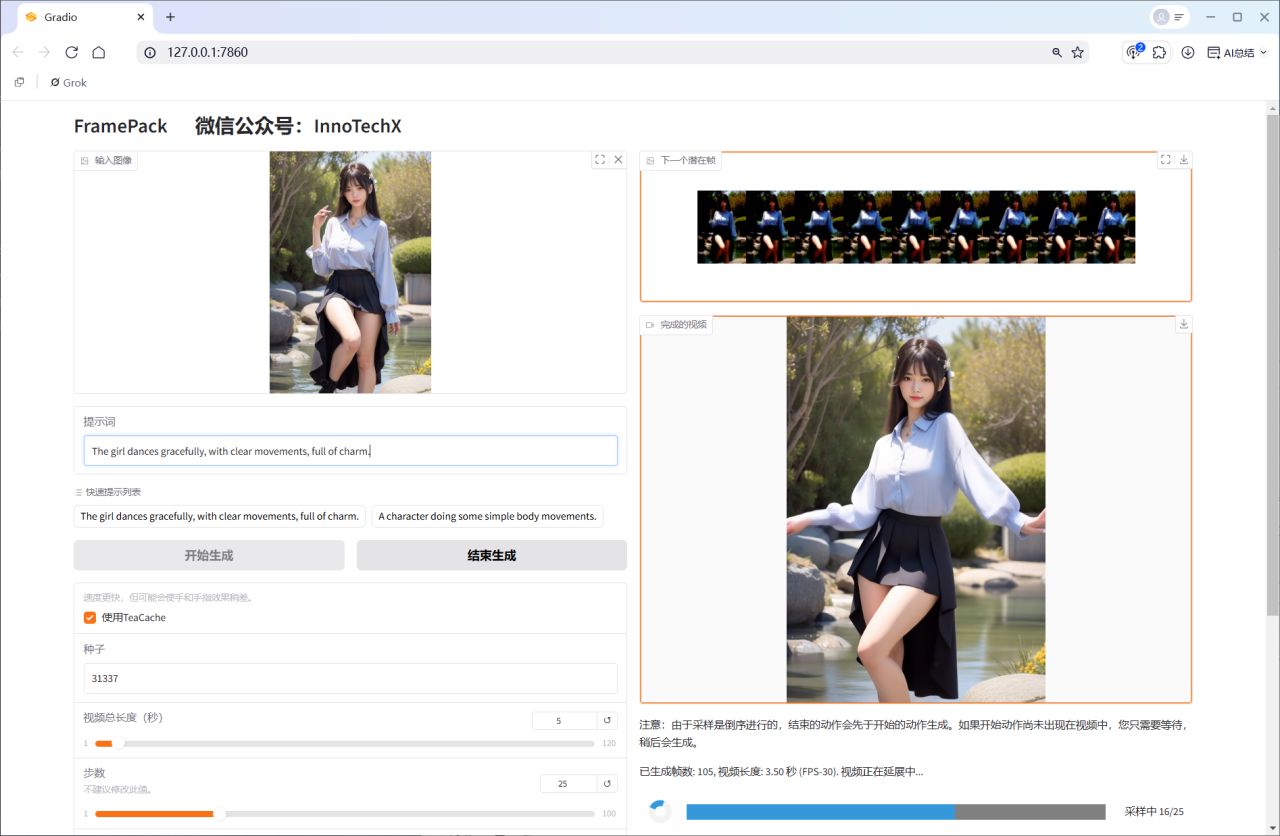
生成结果如下
FramePack是什么?为什么这么强?
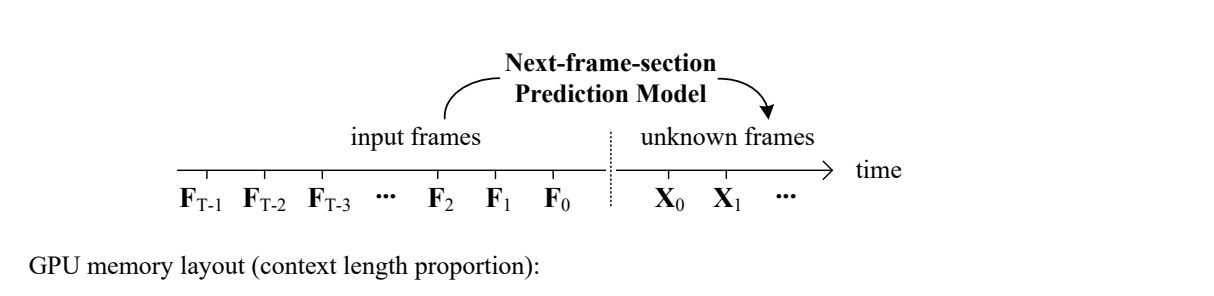
FramePack是由斯坦福大学张律敏和Maneesh Agrawala团队开发的一种神经网络结构,专门为视频生成优化。它通过预测“下一帧”或“下一帧段”,让视频生成变得高效又高质量。核心亮点有以下几点:

1. 高效的神经网络设计
FramePack通过一种独特的压缩技术,将输入帧的上下文长度固定为一个常数,完全不受视频长度的限制。这意味着:
-
它能轻松处理超多帧,计算开销跟图像扩散模型差不多。
-
训练时可以大幅增加视频批次大小,接近图像扩散模型的训练规模,效率直接拉满。
2. 反漂移采样,告别误差累积
FramePack提出了一种“倒序时间生成”的新方法,提前设定视频的起点和终点。这种反漂移采样技术可以:
-
有效减少生成过程中的误差累积,避免画面“跑偏”。
-
让视频的视觉质量更稳定,细节更清晰。
3. 对现有模型的“即插即用”改进
如果你已经在用其他视频扩散模型,FramePack可以无缝微调现有模型。它优化了扩散调度,减少了极端时间步的偏移,显著提升画面质量。
4. 笔记本GPU也能玩转
最让人震惊的是,FramePack只需要6GB显存就能生成60秒、30fps(共1800帧)的高清视频!这意味着你用一台普通的RTX 3060笔记本就能体验电影级视频生成,门槛低到飞起。
FramePack的硬件需求和运行速度
FramePack的硬件门槛低得让人感动,但也有一些基本要求:
硬件要求:
-
GPU:Nvidia RTX 30XX/40XX/50XX系列(支持fp16和bf16)。GTX 10XX/20XX未测试。
-
操作系统:Linux或Windows。
-
显存:最低6GB(是的,6GB也可以!)。
-
推荐配置:用13B模型生成60秒、30fps视频,6GB显存完全hold得住。
运行速度:
-
在RTX 4090台式机上,未优化时每帧约2.5秒,优化后(teacache)可达1.5秒。
-
在RTX 3070ti或3060笔记本上,速度大约是台式机的1/4到1/8,但依然流畅。
-
得益于“下一帧预测”设计,你能边生成边看到画面,体验感满分。
怎么上手FramePack?
提供了三种部署方式,满足不同需求:
1. 本地部署
适合喜欢自己动手的技术爱好者,步骤简单:
# 创建并激活conda环境
conda create -n FramePack python=3.10
conda activate FramePack
# 克隆仓库
git clone https://github.com/lllyasviel/FramePack.git
cd FramePack
# 安装依赖
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
pip install -r requirements.txt
# 运行Demo
python demo_gradio.py2. 离线一键整合包
不想折腾环境?直接用离线包!底部个人名片关注,回复“FramePack”,下载解压后即可开跑,省时省力。
3. 云算力部署
如果你本地部署,甚至是一键整合包都失败的情况,那么你只有使用云算力快速体验,这个是非常简单并且不会失败的方法。
-
镜像地址:https://www.xiangongyun.com/image/detail/85454460-f2d5-4146-91fe-a501096e747d
-
部署过程只需2-3分钟,简单到不行。
为什么FramePack这么值得一试?
FramePack不仅技术硬核,还非常接地气:
-
低门槛:6GB显存就能跑,普通笔记本也能玩。
-
高效率:上下文压缩和反漂移采样让生成又快又好。
-
更重要的是,FramePack让视频生成变得像图像生成一样简单高效,为长视频创作打开了新大门。无论是想做一部短片、动画,还是给静态图片加点动态魔法,FramePack都能帮你实现。
避免生成的效果达不到自己想要的,需要重复抽卡,所以修改了代码,支持批量生成。
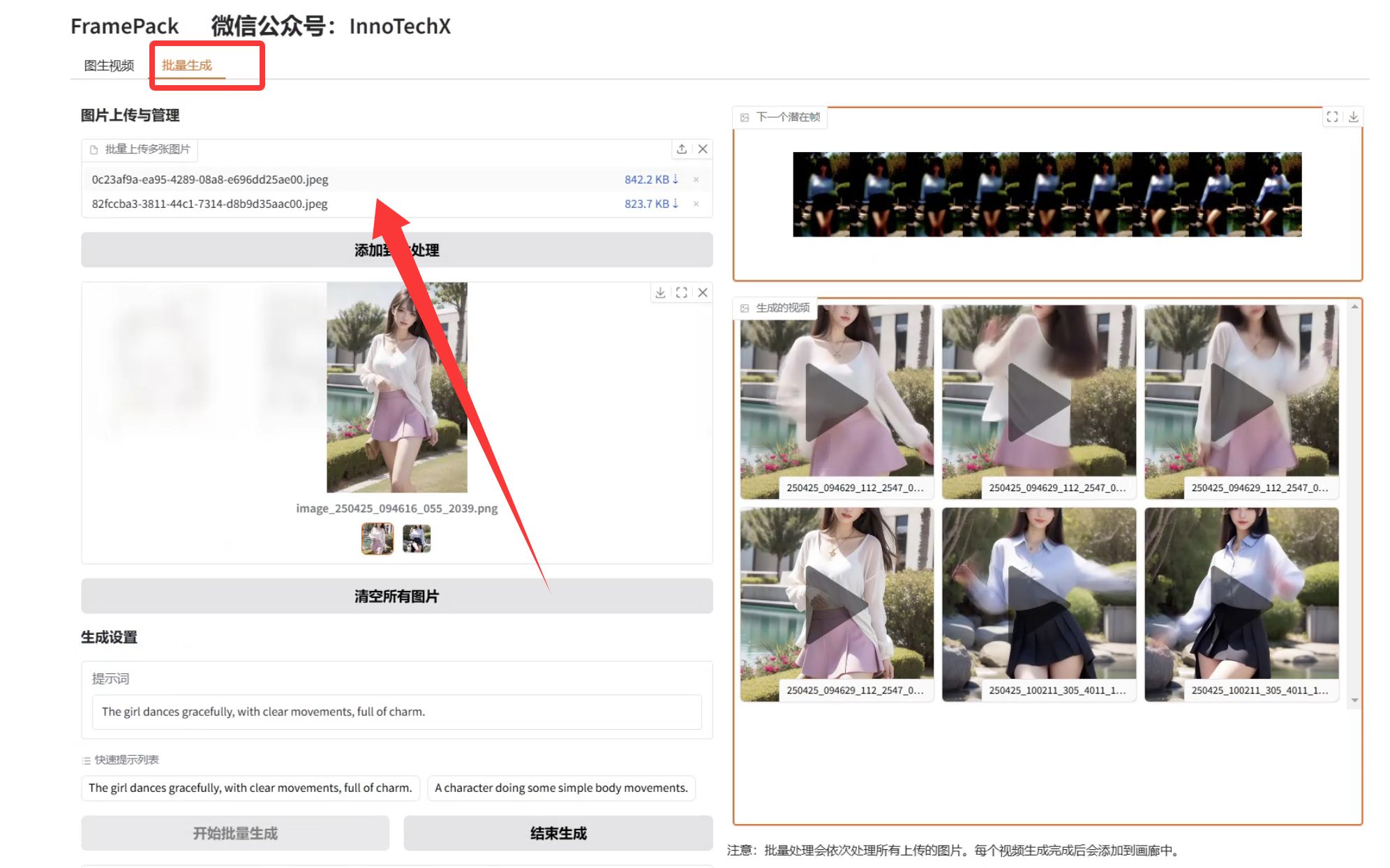
FramePack用6GB显存就能生成60秒电影级视频,这性价比简直无敌。它的神经网络设计高效又聪明,反漂移采样让画面质量更上一层楼。
快去试试吧!用一张美女图片,配合FramePack,生成一段属于你的电影级视频,绝对惊艳!效果媲美可灵大师版2.0,最重要的是免费!!!还要啥自行车!

















 2226
2226

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









