






页面整体前端
Streamlit
streamlit是什么
- Streamlit:一个能够迅速搭起web服务的Python框架,非常便捷地将本地的程序开发接口给别人调用。更多介绍官方文档写的很详细了点击跳转,安装也很简单,直接pip
install streamlit即可 - 再说下Streamlit Cloud,这是streamlit官方提供的云,可以部署自己公开的streamlit
app,会生成一个公网url,可以随时访问并分享给别人
全局信息配置
app的全局配置
主要用到的是st.set_page_config,可以修改页面标题、页面icon、侧边栏以及页面布局,其中可以用log作为页面的icon。如下是我的配置信息:
def main():
# 设置页面布局
global model
st.set_page_config(
page_title="Coding Learning Corner",
page_icon="log",
layout="wide",
initial_sidebar_state="collapsed"
)
# 设置主标题
st.title("水稻种植辅助系统")
# 侧边栏标题
st.sidebar.header("模型配置")
# 侧边栏-任务选择
task_type = st.sidebar.selectbox(
"选择要进行的任务",
["目标检测"]
)
model_type = None
# 侧边栏-模型选择
if task_type == "目标检测":
model_type = st.sidebar.selectbox(
"选取模型",
config.DETECTION_MODEL_LIST
)
else:
st.error("目前仅仅实现了目标检测任务")
# 侧边栏-置信度
confidence = float(st.sidebar.slider(
"选取最小置信度", 10, 100, 25)) / 100
model_path = ""
if model_type:
model_path = Path(config.DETECTION_MODEL_DIR, str(model_type))
else:
st.error("请在下拉框选择一个模型")
# 加载模型
try:
model = load_model(model_path)
except Exception as e:
st.error(f"无法加载模型. 请检查路径: {model_path}")
# 侧边栏-图像、视频、摄像头选择
predict_region, show_region = st.columns(2)
with predict_region:
# st.header("图片/视频配置")
source_selectbox = st.selectbox(
"选取文件类型",
config.SOURCES_LIST
)
程序内部的全局变量信息配置:
主要用到的是st.session_state,这里面定义的信息会在页面刷新时重置,因此可以利用它,可以非常巧妙地配置每次访问页面时的全局信息。如下是我的配置信息:
秘钥信息配置:
这个主要是针对用Streamlit Cloud分享app时所要配置的信息,会储存在st.secrets中,因为部署到Streamlit Cloud的app都是链接public github repository的,所以像database的账户密码、API key等信息是不能公开的,但程序中又需要用到这些信息,那么就需要配置了。详细的用法官方也已经给出点击跳转
if st.session_state.first_visit:
# 在这里可以定义任意多个全局变量,方便程序进行调用
st.session_state.date_time = datetime.datetime.now() + datetime.timedelta(
hours=0) # Streamlit Cloud的时区是UTC,加8小时即北京时间
st.session_state.random_chart_index = random.choice(range(len(charts_mapping)))
st.session_state.my_random = MyRandom(random.randint(1, 1000000))
st.session_state.city_mapping,_ = get_city_mapping()
st.session_state.static = load_static()
st.session_state.city_map, st.session_state.city_seq = load_map()
st.balloons()
st.snow()
d = st.sidebar.date_input('Date', st.session_state.date_time.date())
t = st.sidebar.time_input('Time', st.session_state.date_time.time())
t = f'{t}'.split('.')[0]
st.sidebar.write(f'The current date time is {d} {t}')
# with predict_region:
# chart = st.selectbox('选择你想查看的图表', charts_mapping.keys(),
# index=st.session_state.random_chart_index)
with show_region:
city_choose = sac.cascader(st.session_state.city_map,index=[2090,2106],return_index=True,search=True)
city_index = city_choose[0]
city = st.session_state.city_seq[city_index]
cat = st.selectbox("灾害类别:",config.categories_map,format_func=config.categories_map.get)
for p in st.session_state.city_map:
if p['label'] == st.session_state.city_seq[city_index]:
children_size = len(p['children'])
break
缓存机制
streamlit的缓存主要是用到装饰器@st.cache,可以优化性能,提升用户体验。主要是用在请求的数据量比较大时采用的一种应对策略,因为streamlit的一个特点是:用户每进行一次交互,程序都会重新自顶向下重新运行一遍。
被@st.cache装饰的函数,streamlit会对该函数的入参、出参、函数主体以及函数内部用到的其他函数主体进行跟踪,通过hash编码进行前后判断是否已经运行过一遍,快速返回结果。更多详细介绍官方也给出了点击跳转
同时,hash编码是可以自定义的,通过参数hash_funcs实现,如下是我自定义的hash编码:
class MyRandom:
def __init__(self,num):
self.random_num=num
def my_hash_func(my_random):
num = my_random.random_num
return num
@st.cache(hash_funcs={MyRandom: my_hash_func})
def get_pictures(my_random):
try:
cat_img=Image.open(BytesIO(requests.get(requests.get('https://aws.random.cat/meow').json()['file']).content))
dog_img=Image.open(BytesIO(requests.get(requests.get('https://random.dog/woof.json').json()['url']).content))
fox_img=Image.open(BytesIO(requests.get(requests.get('https://randomfox.ca/floof/').json()['image']).content))
except Exception as e:
if 'cannot identify image file' in str(e):
return get_pictures(my_random)
else:
st.error(str(e))
return cat_img,dog_img,fox_img
数据来源
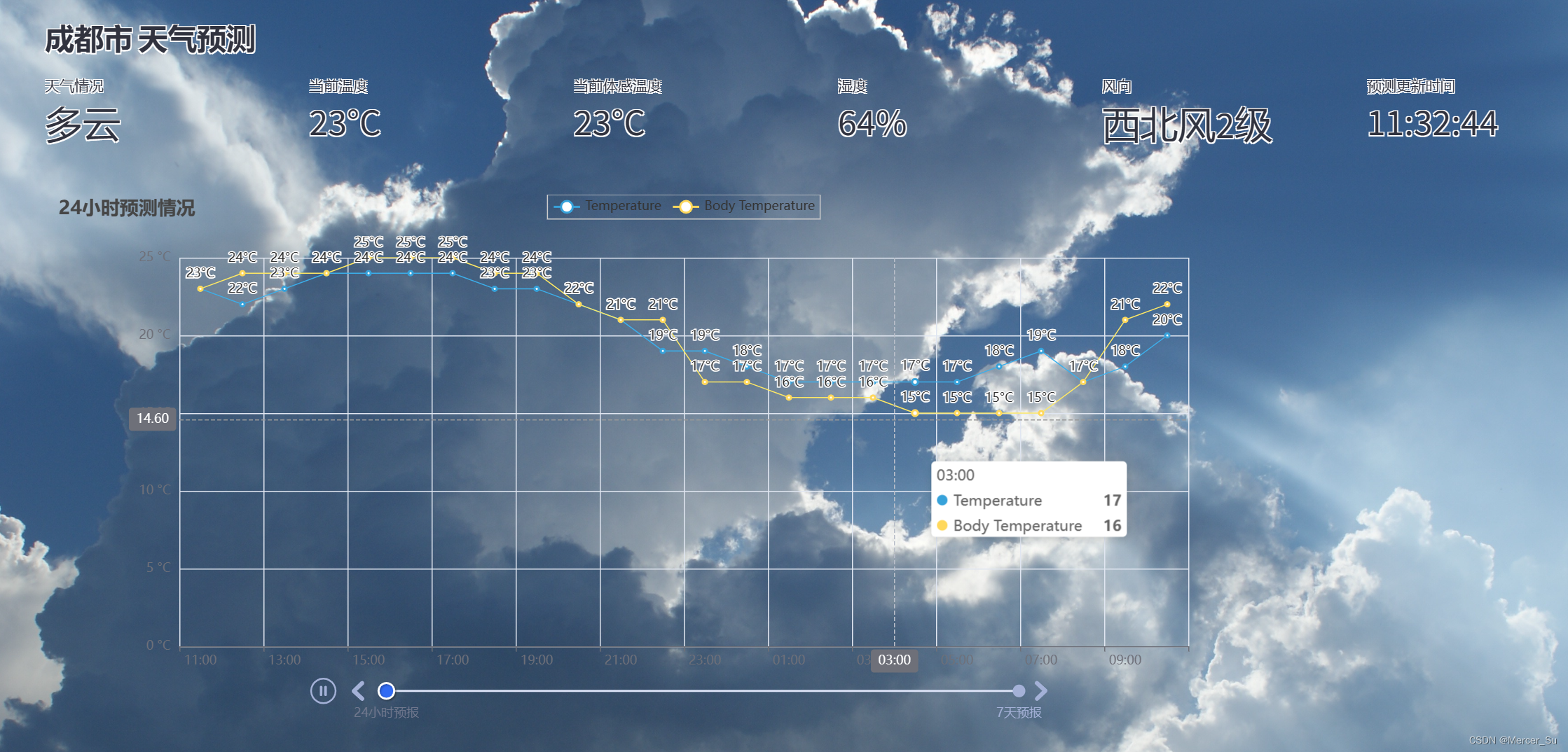
在我的项目中,用到了天气预报数据
天气预报:数据是来自墨迹天气
地图
使用是mapbox绘制底图,再根据收集的经纬度数据,填充单选框,使其能够匹配在地图上的位置
,对于收集到的经纬度数据剔除了误差过大的部分,调整了区县的设置
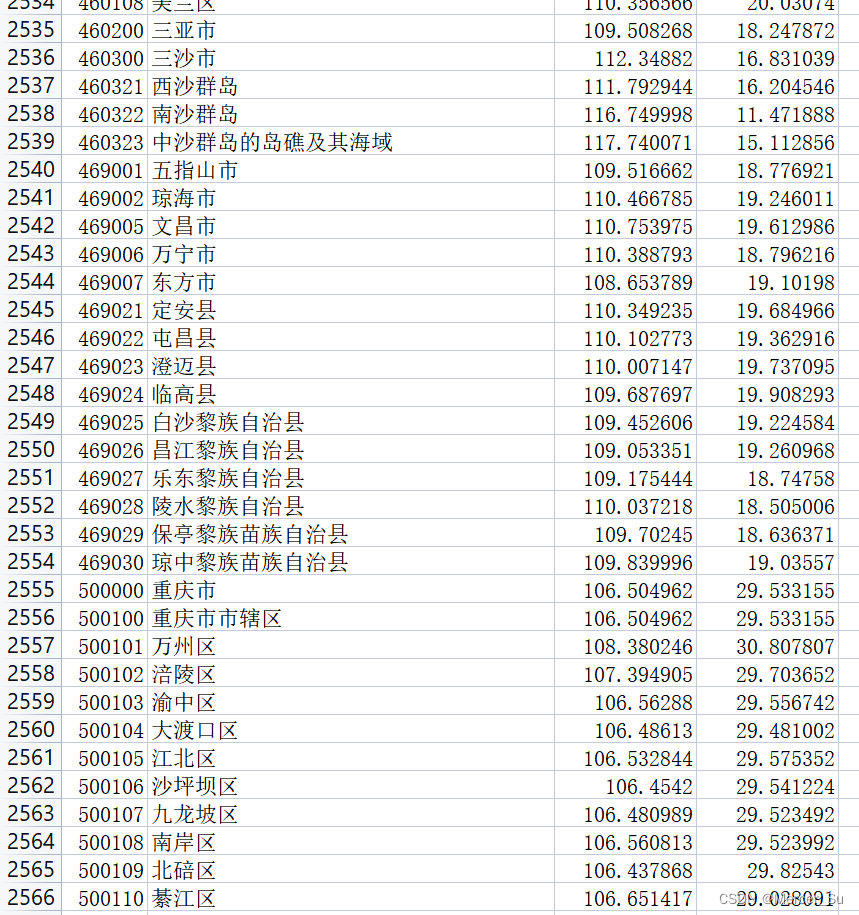
完整前端: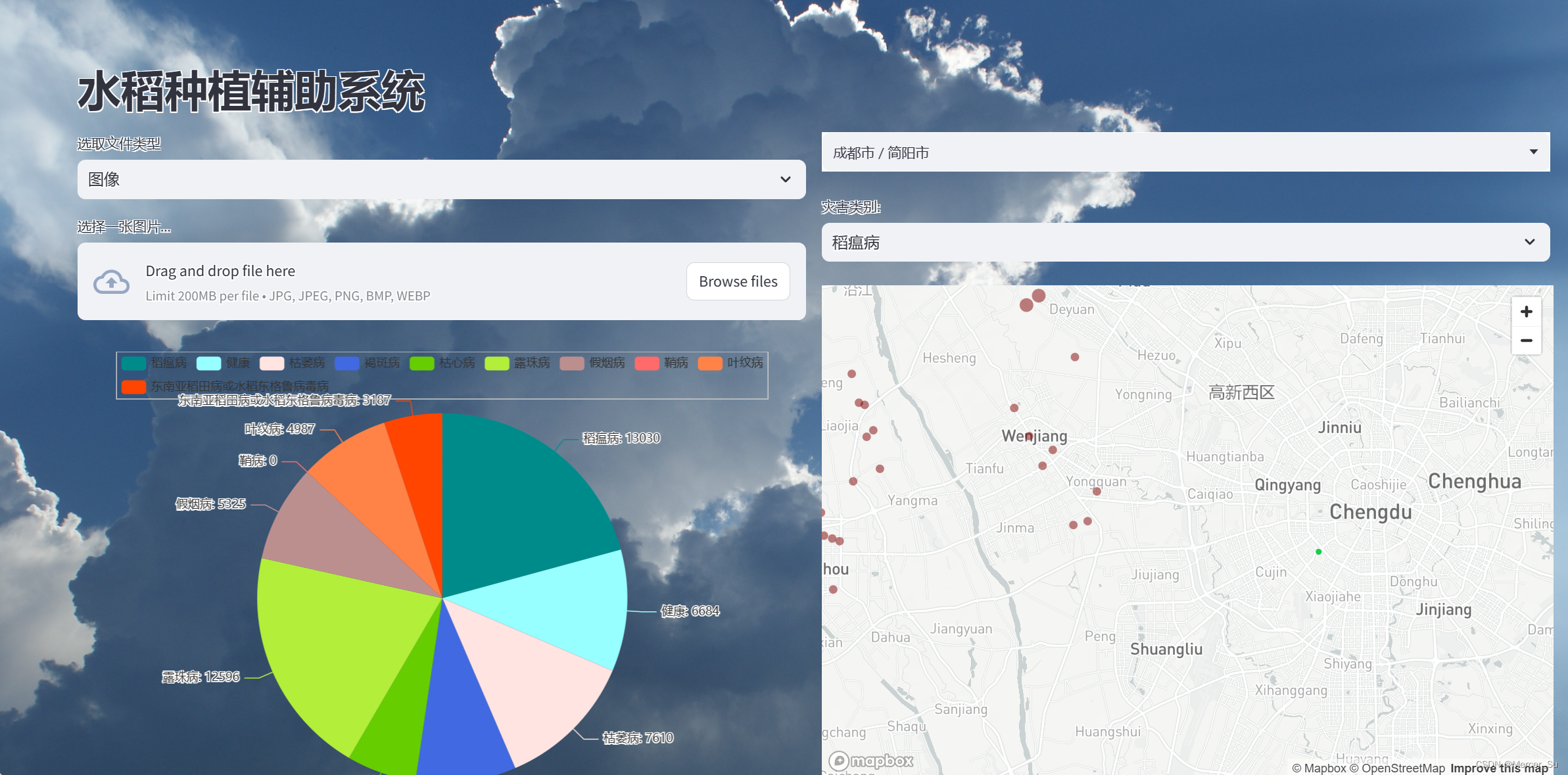
项目已部署:https://riceauxiliarysystem.streamlit.app/
















 7098
7098











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









