






目 录
1.查看Scipy官网SciPy,找到优化有关的模块(Optimize)
问题重述
在二维平面有n个点,如何画一条直线,使得所有点到该直线距离之和最短
如果能找到,请给出其损失函数
附加问题
1.使用Scipy优化上述问题
2.主代码中不得出现任何循环语法,出现一个扣10分
步骤实施
1.查看Scipy官网SciPy,找到优化有关的模块(Optimize)

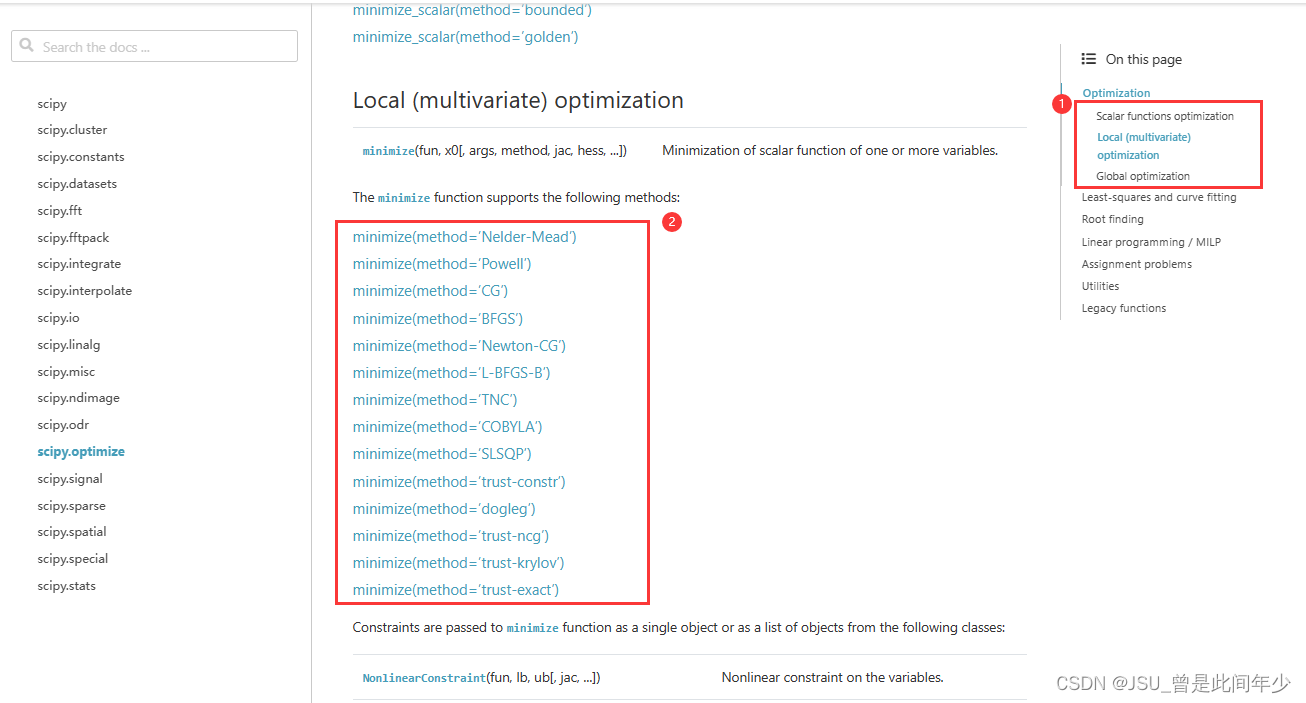
2.研究多种优化策略,选择最符合代码的方案进行优化
| 名称 | 特点 | 应用场景 |
| Scalar Functions Optimization | 用于最小化或最大化单个标量函数的,通常用于解决一维问题 | 目标函数只返回一个标量(单个值) |
| Local (Multivariate) Optimization | 适用于多变量问题,需要梯度函数,不过会自动寻找梯度更新目标值 | 在参数空间中找到局部最小值或最大值 |
| Global Optimization | 寻找函数的全局最小值或最大值,包含多个局部最值 | 在计算条件允许的条件下可以得到全局最优解 |
| 序号 | 名称 | 使用方法 | 适用条件 |
| 1 | Nelder-Mead | Nelder-Mead单纯形法 | 适用于一般的非线性问题 |
| 2 | Powell | Powell方法 | 适合多维非约束优化的方法 |
| 3 | CG | 共轭梯度法(Conjugate Gradient) | 适用于二次优化问题或大规模问题 |
| 4 | BFGS | 拟牛顿BFGS算法 | 适用于大多数非线性优化问题的常用方法,尤其是当梯度信息可用时 |
| 5 | Newton-CG | 牛顿共轭梯度法 | 适用于大多数非线性优化问题,但相对于BFGS需要更多的内存 |
| 6 | L-BFGS-B | 限制内存BFGS算法 | 适用于大规模问题,因为它限制了内存使用 |
| 7 | TNC | 截断牛顿法 | 适用于大多数非线性优化问题,并且能够处理约束条件 |
| 8 | COBYLA | 约束优化 | 适用于具有约束条件的问题 |
| 9 | SLSQP | 顺序最小二乘法 | 适用于具有约束条件的问题,并且能够处理线性和非线性约束 |
| 10 | trust-constr | 信任区域约束优化方法 | 适用于有约束条件的问题,并且可以处理线性和非线性约束 |
| 11 | dogleg | 信任域Dogleg方法 | 适用于具有约束条件的问题 |
| 12 | trust-ncg | 信任区域牛顿共轭梯度法 | 适用于约束优化问题 |
| 13 | trust-krylov | 信任区域Krylov子空间法 | 适用于约束优化问题 |
| 14 | trust-exact | 精确信任区域方法 | 适用于约束优化问题 |
此问题我们需要求最小值,所以我们采用minimize函数,并选择常用的BFGS策略
3.minimize函数参数及其返回值
原型如下:
scipy.optimize.minimize(fun, x0, args=(), method=None, jac=None, hess=None, hessp=None, bounds=None, constraints=(), tol=None, callback=None, options=None)
挑五个主要的参数讲
1.fun:需要最小化的目标函数
这个函数应该接受一个输入向量,返回一个标量(单个值),表示损失函数的值。
2.x0:起始参数的初始猜测值
通常是一个数组或列表,表示参数的初始估计。
3.args:传递给目标函数的额外参数的元组
如果目标函数需要额外的参数,可以将它们作为元组传递给args参数。
4.method:选择优化方法的字符串
这是一个可选参数,如果未指定,默认使用'Nelder-Mead'方法。可以选择其他方法,
5.jac:表示目标函数的梯度(导数)的函数
如果提供了梯度函数,通常可以加速优化过程。如果不提供,优化算法会尝试数值估计梯度。
所以我们在优化代码的时候,
可以将 calcLoseFunction函数作为fun,
而k,b两个参数打成列表作为x0,
将XData,YData组成元组传递给arg
method选择BFGS
最后jac选择不写,便于对比两者速度差异
其返回值说明如下
1.x:优化的参数值。这是一个数组,包含找到的最优参数。
2.fun:最小化目标函数的最小值(损失函数的最小值)。
3.success:一个布尔值,表示优化是否成功收敛到最小值。
4.message:一个字符串,描述优化的终止消息。
5.nit:迭代次数,表示优化算法运行的迭代次数。
6.nfev:函数调用次数,表示评估目标函数的次数。
7.njev:梯度计算次数,表示计算目标函数梯度的次数(如果提供了梯度函数)。
8.hess_inv:Hessian矩阵的逆矩阵(如果提供了Hessian信息)。
9.jac:目标函数的梯度值。
4.代码展示
import numpy #发现直接用List就行了
import random
import matplotlib.pyplot as plt
from scipy.optimize import minimize
from commonTools import *
# random.random()
# random.randint(start,stop)
#################全局数据定义区
# 数组大小
listSize=10
# 定义学习率 取尽量小0.001
learningRate=0.0001
#定义初始直线的 斜率k 和 截距b 45° 1单位距离
# 现在设置 k=0.5 检验程序
k,b=0.5,1
initialParams=[k,b]
#定义迭代次数
bfsNums=9999
#################全局数据定义区END
# 生成随机数
def generateRandomInteger(start, end):
# [1-100]
return random.randint(start, end)
# 打印本次随机生成的X,Y 便于快速粘贴复现
def printXYArray(XData,YData):
# 打印X
print("[", ",".join([str(i) for i in XData]), "]")
# 打印Y
print("[", ",".join([str(i) for i in YData]), "]")
#调用公共模块进行打印 便于快速查看粘贴
def printXYData(XData,YData):
loc=locals()
printArray(XData,loc)
printArray(YData,loc)
# 最小二乘法定义损失函数 并计算
#参考链接:https://blog.csdn.net/zy_505775013/article/details/88683460
# 求最小二乘法的最小值 最终结果应当是在learningRate一定情况下 这个最小的sum
def calcLoseFunction(params,XData,YData):
k, b = params
sum=0
for i in range(0,listSize):
# 使用偏离值的平方进行累和
sum+=(YData[i]-(k*XData[i]+b))**2
return sum
#梯度下降法
def calcGradientCorrection(b, k, XData, YData, learningRate, bfsNums):
for i in range(0, bfsNums):
sumk, sumb = 0, 0
for j in range(0, listSize):
# 定义预测值Y'
normalNum = k * XData[j] + b
# 计算逆梯度累和
sumk += -(2 / listSize) * (normalNum - YData[j]) * XData[j]
sumb += -(2 / listSize) * (normalNum - YData[j])
# 在逆梯度的方向上进行下一步搜索
k += learningRate * sumk
b += learningRate * sumb
return k, b
# 随机生成横坐标
XData=[generateRandomInteger(1,100) for i in range(listSize) ]
# 随机生成纵坐标
YData=[XData[i]+generateRandomInteger(-10,10) for i in range(listSize) ]
# 纯随机生成 但是可视化效果不直观
# YData=[generateRandomInteger(1,100) for i in range(listSize) ]
# 死值替换区
# XData=testArrayX
# YData=testArrayY
print("初始选取k={},b={}的情况下的损失函数值为sum={}".format(k,b,calcLoseFunction(initialParams,XData,YData)))
# 对k,b进行梯度修正
# k,b=calcGradientCorrection(b,k,XData,YData,learningRate,bfsNums)
#使用Scipy进行求解
result = minimize(calcLoseFunction, initialParams, args=(XData, YData), method='BFGS')
resultk,resultb=result.x
print("修正后:k={},b={},最小损失sum={},最小二乘法损失sums={}".format(resultk,resultb,result.fun,calcLoseFunction([resultk,resultb],XData,YData)))
print("调试数组")
printXYArray(XData,YData)
#画图
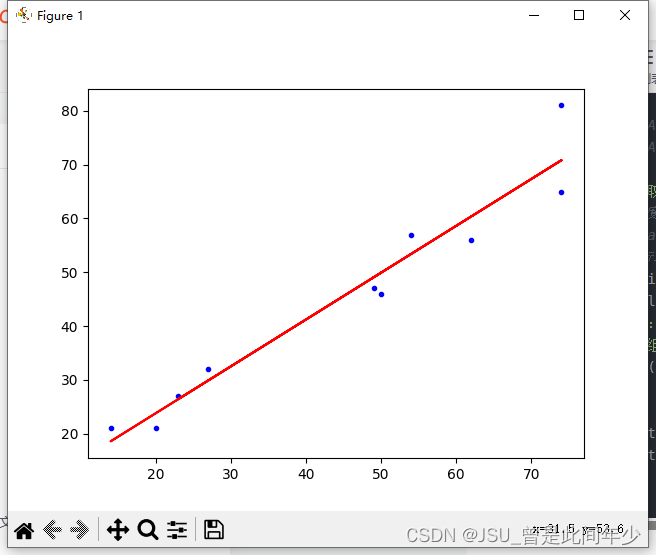
plt.plot(XData, YData, 'b.')
plt.plot(XData, resultk*numpy.array(XData)+resultb, 'r')
plt.show()
print("END")5.结果展示

6.进一步优化
两个目标
1.优化损失函数中的for循环
2.对使用Scipy优化前后的代码进行基准测试,比较运行速度
6.1对如下函数方法进行优化
def calcLoseFunction(params,XData,YData):
k, b = params
sum=0
for i in range(0,listSize):
# 使用偏离值的平方进行累和
sum+=(YData[i]-(k*XData[i]+b))**2
return sum使用numpy,优化后如下:
def calcLoseFunction(params,XData,YData):
XData,YData=np.array(XData),np.array(YData)
k, b = params
sum=np.sum((YData - (k * XData + b))**2)
return sum无for优化后代码如下:
import numpy as np
import random
import matplotlib.pyplot as plt
from scipy.optimize import minimize
from commonTools import *
#################全局数据定义区
# 数组大小
listSize=10
#定义初始直线的 斜率k 和 截距b 45° 1单位距离
# 现在设置 k=0.5 检验程序
k,b=0.5,1
initialParams=[k,b]
#################全局数据定义区END
# 生成随机数
def generateRandomInteger(start, end):
return random.randint(start, end)
#调用公共模块进行打印 便于快速查看粘贴
def printXYData(XData,YData):
loc=locals()
printArray(XData,loc)
printArray(YData,loc)
# 最小二乘法定义损失函数 并计算
def calcLoseFunction(params,XData,YData):
XData,YData=np.array(XData),np.array(YData)
k, b = params
sum=np.sum((YData - (k * XData + b))**2)
return sum
# 随机生成横坐标
XData=[generateRandomInteger(1,100) for i in range(listSize) ]
# 随机生成纵坐标
YData=[XData[i]+generateRandomInteger(-10,10) for i in range(listSize) ]
# 纯随机生成 但是可视化效果不直观
# YData=[generateRandomInteger(1,100) for i in range(listSize) ]
# 死值替换区
# XData=[ 49,74,62,54,20,14,27,74,23,50 ]
# YData=[ 47,65,56,57,21,21,32,81,27,46 ]
print("初始选取k={},b={}的情况下的损失函数值为sum={}".format(k,b,calcLoseFunction(initialParams,XData,YData)))
#使用Scipy进行求解
result = minimize(calcLoseFunction, initialParams, args=(XData, YData), method='BFGS')
resultk,resultb=result.x
print("修正后:k={},b={},最小损失sum={},最小二乘法损失sums={}".format(resultk,resultb,result.fun,calcLoseFunction([resultk,resultb],XData,YData)))
print("调试数组")
printXYData(XData,YData)
#画图
plt.plot(XData, YData, 'b.')
plt.plot(XData, resultk*np.array(XData)+resultb, 'r')
plt.show()
print("END")其中公共模块commonTools.py 代码如下:
#########导包区
#########说明
#1.想要在公共模块区域使用变量列表 必须传进来 因为彼此的变量作用域不同
#########公共变量定义区
#这个locals应该是被引入的界面传进来,而不是从这拿
# loc=locals()
#########函数书写区
#1.获取变量名称
def getVariableName(variable,loc):
for k,v in loc.items():
if loc[k] is variable:
return k
#附带的打印变量名
def printValue(object,loc):
print("变量{}的值是{}".format(getVariableName(object,loc),object))
# 2.组装列表为字符串
def mergeInSign(dataList,sign):
# print(str(sign).join([str(i) for i in dataList]))
return str(sign).join([str(i) for i in dataList])
# 3.打印一个列表
def printArray(dataArray,loc):
print("列表{}的内容是:".format(getVariableName(dataArray,loc)),\
"[", ",".join([str(i) for i in dataArray]), "]"\
)
原先的代码如下:
import numpy #发现直接用List就行了
import random
import matplotlib.pyplot as plt
# random.random()
# random.randint(start,stop)
#################全局数据定义区
# 数组大小
listSize=10
# 定义学习率 取尽量小0.001
learningRate=0.0001
#定义初始直线的 斜率k 和 截距b 45° 1单位距离
# 现在设置 k=0.5 检验程序
k,b=0.5,1
#定义迭代次数
bfsNums=9999
#################全局数据定义区END
# 生成随机数
def generateRandomInteger(start, end):
# [1-100]
return random.randint(start, end)
# 打印本次随机生成的X,Y 便于快速粘贴复现
def printXYArray(XData,YData):
# 打印X
print("[", ",".join([str(i) for i in XData]), "]")
# 打印Y
print("[", ",".join([str(i) for i in YData]), "]")
# 最小二乘法定义损失函数 并计算
#参考链接:https://blog.csdn.net/zy_505775013/article/details/88683460
# 求最小二乘法的最小值 最终结果应当是在learningRate一定情况下 这个最小的sum
def calcLoseFunction(k,b,XData,YData):
sum=0
for i in range(0,listSize):
# 使用偏离值的平方进行累和
sum+=(YData[i]-(k*XData[i]+b))**2
return sum
#梯度下降法
def calcGradientCorrection(b, k, XData, YData, learningRate, bfsNums):
for i in range(0, bfsNums):
sumk, sumb = 0, 0
for j in range(0, listSize):
# 定义预测值Y'
normalNum = k * XData[j] + b
# 计算逆梯度累和 注意这里求偏导应当是两倍 不知道为什么写成1了
# 求MSE的偏导
sumk += -(2 / listSize) * (normalNum - YData[j]) * XData[j]
sumb += -(2 / listSize) * (normalNum - YData[j])
# 在逆梯度的方向上进行下一步搜索
k += learningRate * sumk
b += learningRate * sumb
return k, b
# 随机生成横坐标
XData=[generateRandomInteger(1,100) for i in range(listSize) ]
# 随机生成纵坐标
YData=[XData[i]+generateRandomInteger(-10,10) for i in range(listSize) ]
# 纯随机生成 但是可视化效果不直观
# YData=[generateRandomInteger(1,100) for i in range(listSize) ]
# 死值替换区
# XData=testArrayX
# YData=testArrayY
print("初始选取k={},b={}的情况下的损失函数值为sum={}".format(k,b,calcLoseFunction(k,b,XData,YData)))
# 对k,b进行梯度修正
k,b=calcGradientCorrection(b,k,XData,YData,learningRate,bfsNums)
print("修正后:k={},b={},最小损失sum={}".format(k,b,calcLoseFunction(k,b, XData, YData)))
print("调试数组")
printXYArray(XData,YData)
#画图
plt.plot(XData, YData, 'b.')
plt.plot(XData, k*numpy.array(XData)+b, 'r')
plt.show()
print("END")到此,使用scipy并对for循环进行优化已经完成,下面我们使用程序对比优化后时间效率上有没有改进。
6.2基准测试
我们将先后代码的画图部分都注释
目录结构如下:
test.py代码如下:
import os #执行调用
import time #记录时间
DEBUG=False
execFileName="old.py" if DEBUG else "new.py"
if __name__=="__main__":
startTime = time.time()
os.system("python {}".format(execFileName))
endTime = time.time()
print("文件:{}执行耗时:{}ms".format(execFileName,endTime-startTime))DEBUG为False
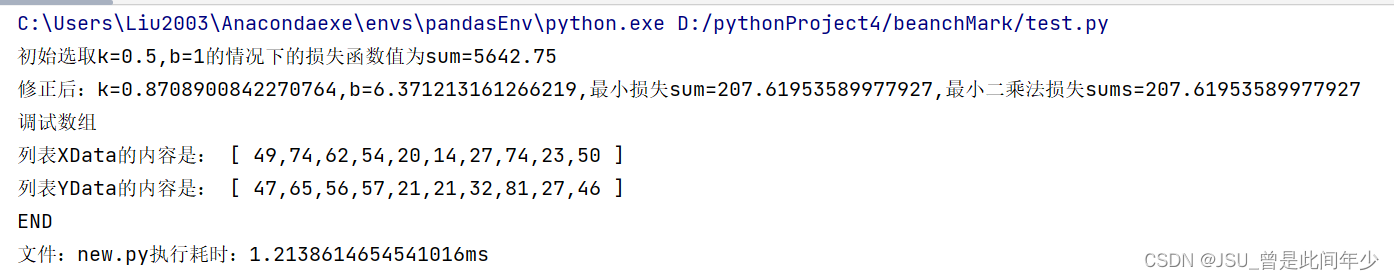
DEBUG为True

额,调用minimize函数在时间上不如自己写的梯度下降。。。。。
多次随机测试后发现结果依旧如此,可能是因为scipy引入了其他策略,导致了执行时间变长
6.3 发现
使用scipy在某种程度上可能能优化执行效率,但是在部分情况下可能耗时会略长于基本实现
测试文件附录
commonTools.py
#########导包区
#########说明
#1.想要在公共模块区域使用变量列表 必须传进来 因为彼此的变量作用域不同
#########公共变量定义区
#这个locals应该是被引入的界面传进来,而不是从这拿
# loc=locals()
#########函数书写区
#1.获取变量名称
def getVariableName(variable,loc):
for k,v in loc.items():
if loc[k] is variable:
return k
#附带的打印变量名
def printValue(object,loc):
print("变量{}的值是{}".format(getVariableName(object,loc),object))
# 2.组装列表为字符串
def mergeInSign(dataList,sign):
# print(str(sign).join([str(i) for i in dataList]))
return str(sign).join([str(i) for i in dataList])
# 3.打印一个列表
def printArray(dataArray,loc):
print("列表{}的内容是:".format(getVariableName(dataArray,loc)),\
"[", ",".join([str(i) for i in dataArray]), "]"\
)
test.py
import os #执行调用
import time #记录时间
DEBUG=True
execFileName="old.py" if DEBUG else "new.py"
if __name__=="__main__":
startTime = time.time()
os.system("python {}".format(execFileName))
endTime = time.time()
print("文件:{}执行耗时:{}ms".format(execFileName,endTime-startTime))new.py
import numpy as np
import random
import matplotlib.pyplot as plt
from scipy.optimize import minimize
from commonTools import *
#################全局数据定义区
# 数组大小
listSize=10
#定义初始直线的 斜率k 和 截距b 45° 1单位距离
# 现在设置 k=0.5 检验程序
k,b=0.5,1
initialParams=[k,b]
#################全局数据定义区END
# 生成随机数
def generateRandomInteger(start, end):
return random.randint(start, end)
#调用公共模块进行打印 便于快速查看粘贴
def printXYData(XData,YData):
loc=locals()
printArray(XData,loc)
printArray(YData,loc)
# 最小二乘法定义损失函数 并计算
def calcLoseFunction(params,XData,YData):
XData,YData=np.array(XData),np.array(YData)
k, b = params
sum=np.sum((YData - (k * XData + b))**2)
return sum
# # 随机生成横坐标
# XData=[generateRandomInteger(1,100) for i in range(listSize) ]
# # 随机生成纵坐标
# YData=[XData[i]+generateRandomInteger(-10,10) for i in range(listSize) ]
# 纯随机生成 但是可视化效果不直观
# YData=[generateRandomInteger(1,100) for i in range(listSize) ]
# 死值替换区
XData=[ 49,74,62,54,20,14,27,74,23,50 ]
YData=[ 47,65,56,57,21,21,32,81,27,46 ]
print("初始选取k={},b={}的情况下的损失函数值为sum={}".format(k,b,calcLoseFunction(initialParams,XData,YData)))
#使用Scipy进行求解
result = minimize(calcLoseFunction, initialParams, args=(XData, YData), method='BFGS')
resultk,resultb=result.x
print("修正后:k={},b={},最小损失sum={},最小二乘法损失sums={}".format(resultk,resultb,result.fun,calcLoseFunction([resultk,resultb],XData,YData)))
print("调试数组")
printXYData(XData,YData)
#画图
# plt.plot(XData, YData, 'b.')
# plt.plot(XData, resultk*np.array(XData)+resultb, 'r')
# plt.show()
print("END")old.py
import numpy # 发现直接用List就行了
import random
import matplotlib.pyplot as plt
from commonTools import *
# random.random()
# random.randint(start,stop)
#################全局数据定义区
# 数组大小
listSize = 10
# 定义学习率 取尽量小0.001
learningRate = 0.0001
# 定义初始直线的 斜率k 和 截距b 45° 1单位距离
# 现在设置 k=0.5 检验程序
k, b = 0.5, 1
# 定义迭代次数
bfsNums = 9999
#################全局数据定义区END
# 生成随机数
def generateRandomInteger(start, end):
# [1-100]
return random.randint(start, end)
# 打印本次随机生成的X,Y 便于快速粘贴复现
def printXYArray(XData, YData):
# 打印X
print("[", ",".join([str(i) for i in XData]), "]")
# 打印Y
print("[", ",".join([str(i) for i in YData]), "]")
# 最小二乘法定义损失函数 并计算
# 参考链接:https://blog.csdn.net/zy_505775013/article/details/88683460
# 求最小二乘法的最小值 最终结果应当是在learningRate一定情况下 这个最小的sum
def calcLoseFunction(k, b, XData, YData):
sum = 0
for i in range(0, listSize):
# 使用偏离值的平方进行累和
sum += (YData[i] - (k * XData[i] + b)) ** 2
return sum
# 梯度下降法
def calcGradientCorrection(b, k, XData, YData, learningRate, bfsNums):
for i in range(0, bfsNums):
sumk, sumb = 0, 0
for j in range(0, listSize):
# 定义预测值Y'
normalNum = k * XData[j] + b
# 计算逆梯度累和 注意这里求偏导应当是两倍 不知道为什么写成1了
# 求MSE的偏导
sumk += -(2 / listSize) * (normalNum - YData[j]) * XData[j]
sumb += -(2 / listSize) * (normalNum - YData[j])
# 在逆梯度的方向上进行下一步搜索
k += learningRate * sumk
b += learningRate * sumb
return k, b
# 随机生成横坐标
XData = [generateRandomInteger(1, 100) for i in range(listSize)]
# 随机生成纵坐标
YData = [XData[i] + generateRandomInteger(-10, 10) for i in range(listSize)]
# 纯随机生成 但是可视化效果不直观
# YData=[generateRandomInteger(1,100) for i in range(listSize) ]
# 死值替换区
# XData=[ 49,74,62,54,20,14,27,74,23,50 ]
# YData=[ 47,65,56,57,21,21,32,81,27,46 ]
print("初始选取k={},b={}的情况下的损失函数值为sum={}".format(k, b, calcLoseFunction(k, b, XData, YData)))
# 对k,b进行梯度修正
k, b = calcGradientCorrection(b, k, XData, YData, learningRate, bfsNums)
print("修正后:k={},b={},最小损失sum={}".format(k, b, calcLoseFunction(k, b, XData, YData)))
print("调试数组")
printXYArray(XData, YData)
# 画图
# plt.plot(XData, YData, 'b.')
# plt.plot(XData, k * numpy.array(XData) + b, 'r')
# plt.show()
print("END")任务清单
1.算法程序不使用任何for循环(已完成)
2.使用scipy对原先的代码进行优化(已完成)
3.对优化前后代码进行基准测试(已完成)
















 1927
1927











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











