






一、适合自动化测试的产品
- 软件需求变动不频繁。
- 项目周期长,规划性强。
- 回归测试任务重。
- 项目进度压力不大。
二、Selenium
- 特点
- 开源工具
- 支持多浏览器:如Firefox、Chrome、IE系列、Opera 、Edge等
- 支持多平台:Windows、Linux、Mac
- 支持多语言:Java、Python、C#、PHP等
- 简单,灵活
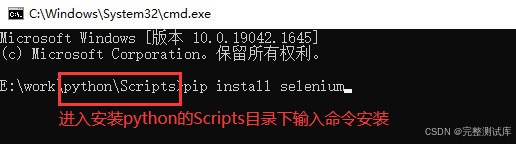
- 安装
使用命令安装:pip install selenium
Edge:
Microsoft Edge WebDriver | Microsoft Edge Developer
Safari:
WebDriver Support in Safari 10 | WebKit
Firefox:
Releases · mozilla/geckodriver · GitHub
IE:
http://selenium-release.storage.googleapis.com/index.html
Microsoft Edge WebDriver | Microsoft Edge Developer
http://selenium-release.storage.googleapis.com/index.html ( 仓 库 )
NuGet Gallery | Selenium.WebDriver.IEDriver 4.14.0
Chrome:
http://chromedriver.storage.googleapis.com/index.html
https://sites.google.com/a/chromium.org/chromedriver/
http://npm.taobao.org/mirrors/chromedriver/
http://chromedriver.chromium.org/downloads(ChromeDriver 官方网站)
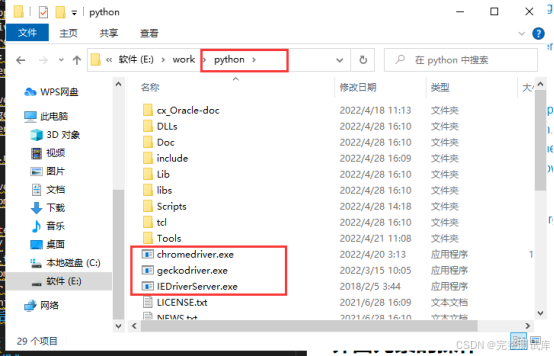
其他驱动:
下载之后将驱动放到Python的根目录
三、浏览器操作
- 打开浏览器:driver = webdriver.浏览器()
- 浏览器包括:Firefox,Chrome,Ie等
- driver = webdriver.Chrome()
- 打开网址:driver.get('网址')
- driver.get('https://www.baidu.com')
- 后退:driver.back()
- 前进:driver.forward()
- 最大化:driver.maximize_window()
- 最小化:driver.minimize_window()
- 刷新页面:driver.refresh()
- 关闭当前页面:driver.close()
- 关闭所有页面:driver.quit()
四、元素定位
1.通过id定位:find_element('id',' ')
2.通过name定位:find_element('name',' ')
3.通过class name定位:find_element('class name',' ')
4.通过link text定位(超链接载体的精确匹配,只有a标签才可以使用):find_element('link text',' ')
5.通过partial link text定位(超链接载体的模糊匹配,只有a标签才可以使用):find_element('partial link text',' ')
6.通过xpath定位(通过路径定位):
(1)使用绝对路径
find_element('xpath','/html/body/div/form/input')
(2)使用相对路径
find_element('xpath','//div/input') # 选取所有div下的input
(3)使用索引(find_elements定位一组元素,返回列表)
a.find_elements('xpath','//input[4]') # 全页面查找,查找这个页面上所有的第4个input
b.find_elements('xpath','//input')[3] # 全页面查找,查找这个页面上所有的第4个input
(4)xpath的常用语法
1)语法:xpath = '//标签名[@属性='属性值']'
find_element('xpath','//input[@id='kw']'); # 全文查找id = kw的这个input标签
2)部分属性值匹配:
a.find_elements('xpath','//[contains(@href, "news.baidu")]')匹配包含属性的值 #全文查找所有标签,href属性包含news.baidu的标签
b.find_elements_by_xpath('xpath','//[starts-with(@href,"https")]')匹配开始字段,ends-with方法不可用 #全文查找所有标签,href属性以https开头的标签
(5)xpath的缺点
a.由于xpath需要遍历页面,所以定位元素的性能要比其它的方式差
b.不够健壮,xpath会随着页面元素的改变而改变
c.兼容性不好,在不同的浏览器下对xpath的实现不一样
7.通过css selector定位(通过选择器定位):
(1).:class name(find_element('css selector','.s_ipt'))
(2)#:id
(3)*:所有元素
(4)标签1,标签2:所有的标签1和标签2
(5)标签1 标签2:标签1中的所有标签2
(6)标签1>标签2:所有父元素为标签1的标签2
(7)标签1+标签2:紧跟在标签1后面的标签2
(8)[属性名]:带有值为属性名的所有元素
(9)[属性='属性值']:属性等于属性值的所有元素
(10)[属性~='属性值']:所有包含属性为属性值的元素(属性值为单词)
(11)[属性|='属性值']:以属性为属性值开头的元素(属性值为单词)
(12)标签[属性^='属性值']:以属性为属性值开头的标签(属性值为字串)
(13)标签[属性$='属性值']:以属性为属性值结尾的标签(属性值为字串)
(14)标签[属性*='属性值']:以属性包含属性值的标签(属性值为字串)
(15)标签:first-child:标签为父元素的第一个子元素的所有标签
(16)标签:only-child:标签为父元素的唯一一个子标签的所有标签
(17)标签:nth-child(n):标签为父元素的第n个标签
(18)标签:last-child:标签为子元素的最后一个标签
8.通过tag name定位(通过标签名定位):find_element('tag name',' ')

















 1284
1284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









