






本文详细说明文件读取时,read()中参数的解释,可直接滑到文尾看总结.
f.read()读取文件的整个内容,返回的是字符串
如果一次性读取比如10G的文件,内存就直接爆了,所以需要限制单次读取的大小.
read()可接收size参数,在官方文档提示中

size参数是整数型,如果不设置.默认f,read()默认读取字节数-1
也就是说在文件管理器中,显示为字节数量为x,那么默认size的值为x-1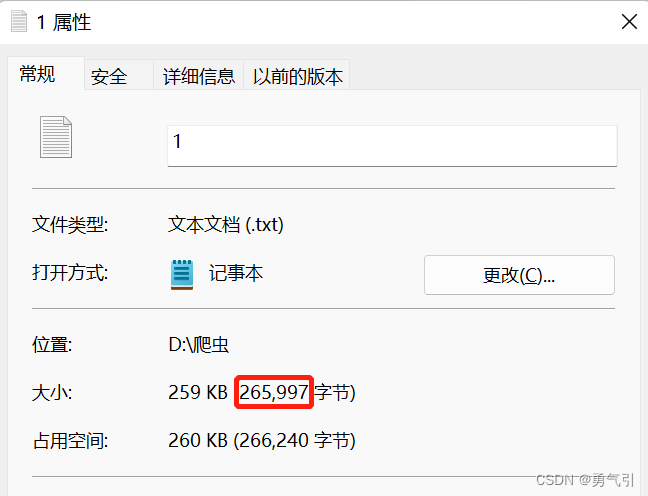
文件管理器中红框中的值-1就是size的值
-----------------------
案例一:
读取下面这个文件的内容
import os
def main():
path = 'd:/爬虫/'
os.chdir(path)
k = os.path.getsize('1.txt') #查看1.txt文件一共多少字节
print(k)
with open("d:/爬虫/1.txt", encoding='utf-8', errors='ignore') as f:
print(f.read(k)) #设定一次读取内容的大小为 统计到的字节数
if __name__ == '__main__':
main()
print(os.path.getsize('1.txt')) 结果:
265997字节全部读取并输出了
-----------------------
案例二:
依旧是读取上面那个265 997 字节大小的文件
代码及其运行结果如下:
import os
def main():
path = 'd:/爬虫/'
os.chdir(path)
k = os.path.getsize('1.txt') 查看1.txt文件一共多少字节
print(k)
size = 1024 * 87 + 100
设定读取内容大小的参数为 1024字节*82 + 100字节,也就是读取87K多一丢丢内容
with open("d:/爬虫/1.txt", encoding='utf-8', errors='ignore') as f:
print(f.read(size))
if __name__ == '__main__':
main()
print(os.path.getsize('1.txt'))
从图中可以看到:
实际是265,997 字节(约为259k)大小的文件,
只读取1024 * 87 + 100字节(约87k)就输出了所有的内容 !
不是说好的size值多大就读取多少文件内容吗?怎么设置比size小的多的值也读取了全部的文件内容?且看案例三:
案例三:代码及其运行结果
-----------------------
import os
def main():
with open("d:/爬虫/1.txt", encoding='utf-8', errors='ignore') as f:
content = f.read()
with open("d:/爬虫/1.txt", encoding='utf-8', errors='ignore') as f1:
cnt = len(content)
设定读取的大小为 整个内容的字符串长度值
print(f1.read(cnt -4))
print(f"1.txt文件有{cnt}个字")
if __name__ == '__main__':
path = 'd:/爬虫/'
os.chdir(path)
main()
print("1.txt文件有",os.path.getsize('1.txt'),"字节")运行结果
这次读取的内容的大小为 整个内容的字符串长度,依旧成功输出了几乎(少4个字)全部的内容.
到这应该能明白了,
在utf-8的编码的文本中,一个汉字占三个字节,一个英文字母占一个字节.
又由于在文本文件读取模式,size的计数是以Unicode字符的个数计数的,
也就是说列举的三个案例size的计数不是字节,而是字符.
-----------------------
绕了这么多弯子,总结.
读取文件限制最大读取大小时,要注意
在文本文件读取模式,size的计数是以Unicode字符的个数计数的,
在二进制文件读取模式下,size计数是以字节为单位计数。















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









