







一、概要
目前,大多数的推荐系统还是由级联的排序策略组成,即召回-粗排-精排-重排/混排
生成式推荐以自回归的方式直接生成物品的语义id
transformer架构模型做生成式检索或推荐,主流还是基于encoder-decoder架构的模型,onerec是一个做生成式推荐的模型,以query或者用户特征、行为序列为输入,是做检索或者推荐的区别所在。
其核心如下:
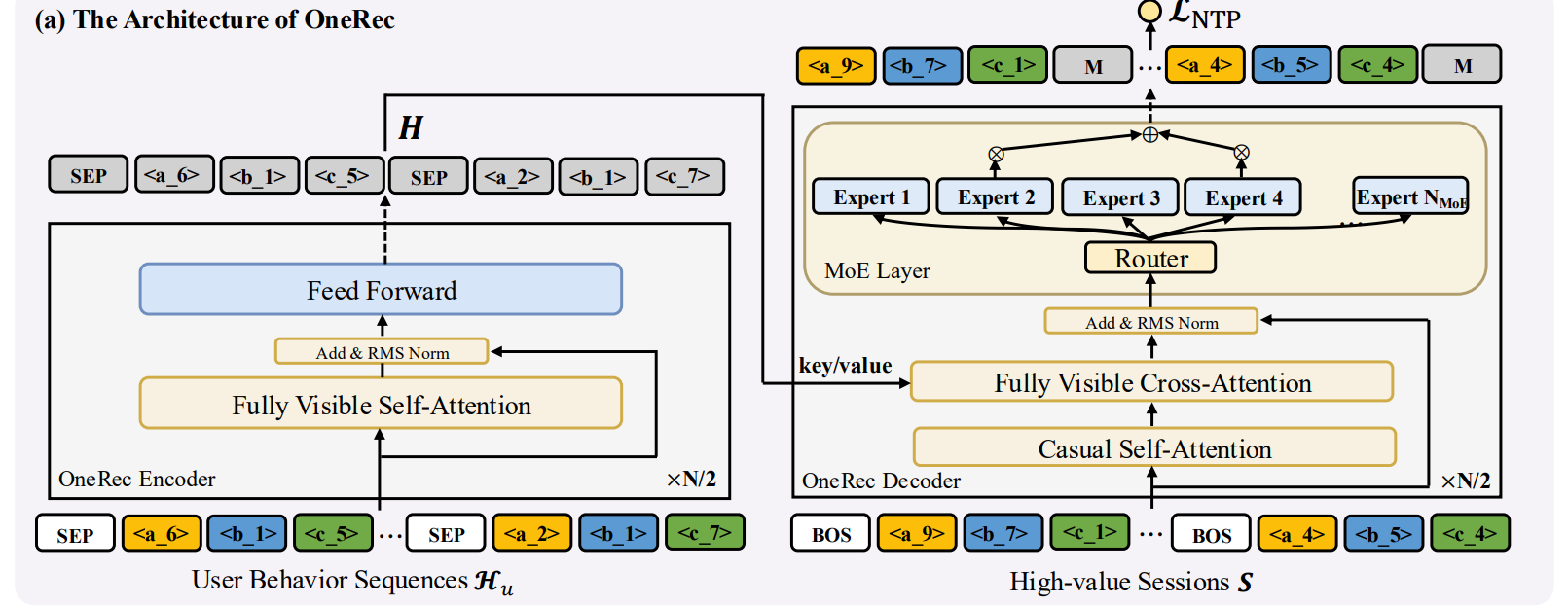
(1)架构为encoder-decoder,以用户历史行为序列为输入,逐渐解码为可能感兴趣的推荐视频,采用稀疏MOE的架构,在一定的资源限制下方便扩展模型能力
(2)将用户行为序列,作为一个分支以cross-attention的方式融入
(3)用预训练的奖励模型,构建偏好数据集,做DPO
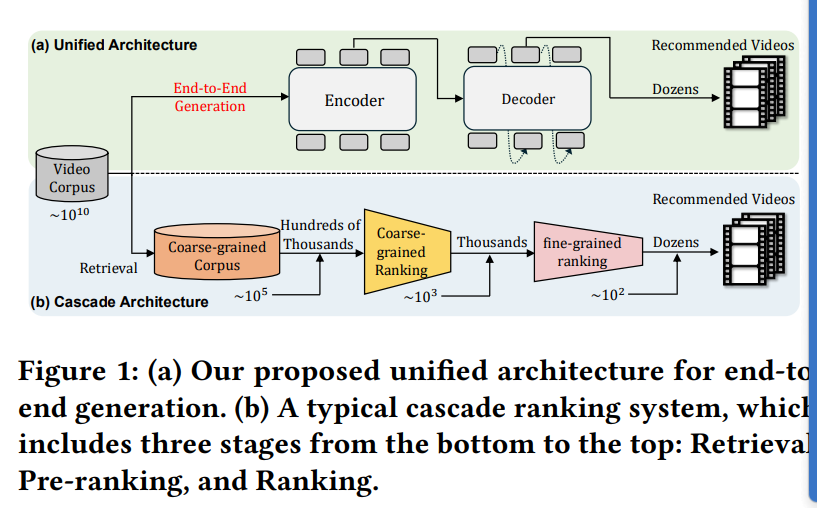
端到端,代替分阶段的推荐系统,在快手短视频推荐中应用,提升了1.6个百分点的总观看时长
二、方法
语义id产生
输入为:正相关历史行为序列,在此场景为点赞收藏转发的视频
输出是视频语义id构成的列表
视频用预训练的多模态模型产生embedding,用embedding根据平衡kmeans算法聚类产生:

codebook的第l层的质心先随机初始化,将候选物品(视频)的特征按照和质心的距离排列,取目标数量的候选加入这个质心中,用候选的均值更新质心,将加入的候选从候选集中去除。逐步等待分配收敛
在给item分配语义id时,先用embedding初始化表示,逐渐选择最近的codebook中的质心,并且更新表示,再递归到下一层
会话列表生成
训练数据标准:高质量会话的定义为推荐的一个会话中存在一定的交互,在训练集中作为用特殊token分隔的语义id
将decoder中的FFN层改为MOE架构,易于参数扩展的同时降低推理耗时。
带有RM的迭代偏好对齐
奖励模型的训练策略:

使用RM的中间特征接了几个预测用户交互行为的线性层,更具正式标签和交叉熵损失函数来使得RM产生的特征是否能根据会话的短视频embedding预测用户的交互特征,
作者称这种偏好学习方法是迭代偏好对齐,损失函数与DPO一致,以其上一次更新前的权重为参考模型,达到一定的DPO比例的数量时会进行迭代的训练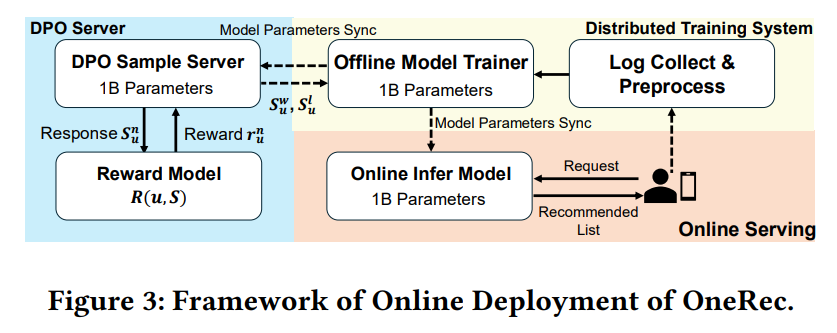
DPO的方式是通过beam search产生多个候选,用RM打分,最高的为正样本,最低得分为负样本
三、效果
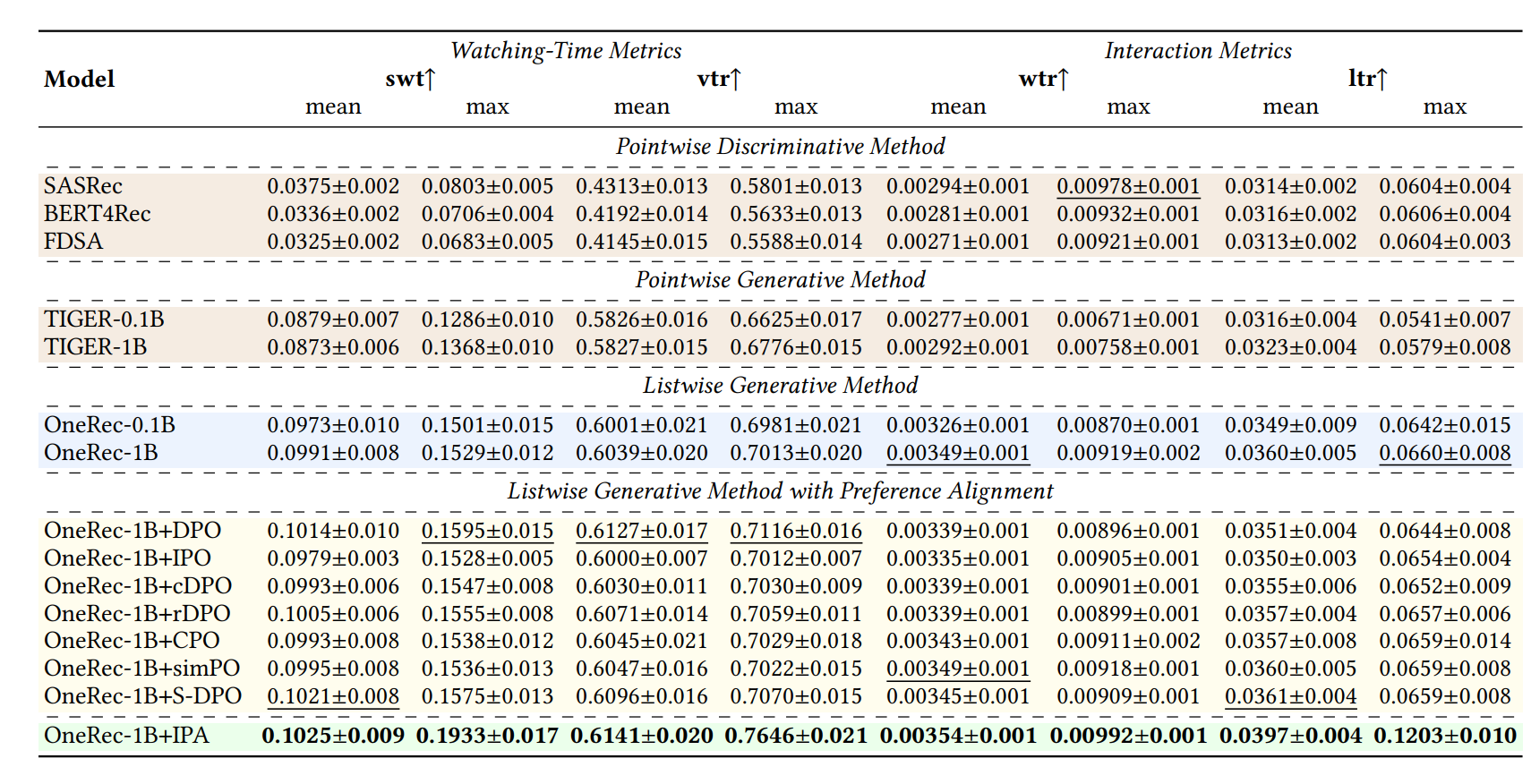
可见该方案经过了多个生成式召回的方案对比,和训练方法的选型,相对严谨
四、实验及上线
百分之一流量,1B模型,严格对比了参数扩展、DPO比例在推荐系统的观看时长、点赞比例等的影响
有些疑问,这个端到端的系统直接能完全代替多路召回吗,之后在精排中根据业务策略的扶持和用户特征为什么能被完全替代


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









