







DirectX VA 2.0 的同步机制从 1.0 版本得到改进,更类似于 Microsoft Direct3D 操作使用的同步机制。
在 DirectX VA 1.0 中,同步主要由解码器执行。 在解码器可以使用压缩缓冲区之前,它会调用 DdMoCompQueryStatus 函数来确定缓冲区是否可用于 (即硬件无法访问缓冲区) 。 如果缓冲区不可用,解码器必须睡眠、轮询或执行其他操作。
DirectX VA 2.0 使用 Direct3D 已在顶点缓冲区和索引缓冲区上使用的同步模型。 在 DirectX VA 2.0 中,同步由锁定压缩缓冲区的解码器执行。 如果用户模式显示驱动程序尝试锁定压缩的缓冲区,并且缓冲区正在使用中,则驱动程序可能会使锁定失败或重命名缓冲区。 用户模式显示驱动程序请求在调用 pfnLockCb 函数时,当驱动程序设置 D3DDDICB_LOCKFLAGS 结构的 Discard 成员时,视频内存管理器重命名缓冲区。 如果用户模式显示驱动程序重命名缓冲区,驱动程序将返回指向备用缓冲区的指针,以便解码器可以继续,而不会被阻止。
通常,对于 DirectX VA 2.0,仅当硬件可以直接使用压缩的缓冲区而无需额外的缓冲区副本时,同步才成为问题。
同步机制演进对比
DirectX VA 1.0 同步模型
主动轮询模式:解码器需主动查询缓冲区状态
// 传统1.0风格的同步检查
while (DdMoCompQueryStatus(pBuffer) == BUSY) {
Sleep(1); // 被动等待
}主要问题:
- 高CPU占用率(轮询开销)
- 难以预测的延迟
- 缺乏高效的资源管理
DirectX VA 2.0 同步模型
基于锁定的被动同步:
// 2.0风格的锁定尝试
D3DDDICB_LOCKFLAGS lockFlags = {0};
HRESULT hr = pfnLockCb(hBuffer, &lockFlags);核心改进:
- 与Direct3D资源管理模型统一
- 支持自动缓冲区重命名
- 减少CPU等待开销
关键同步机制详解
缓冲区锁定与重命名
锁定失败处理流程: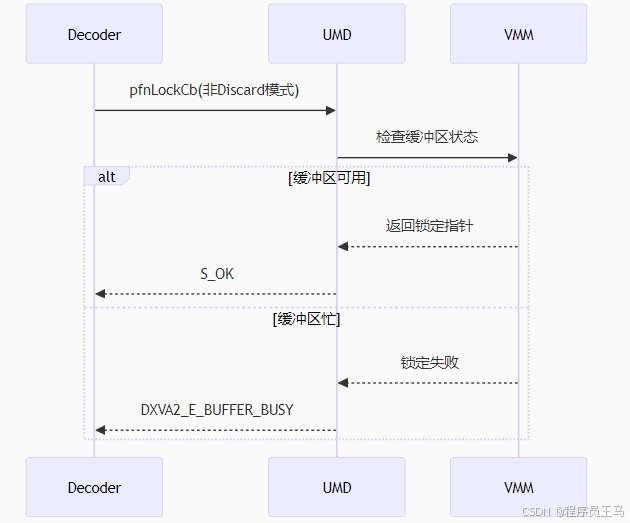
重命名操作流程:
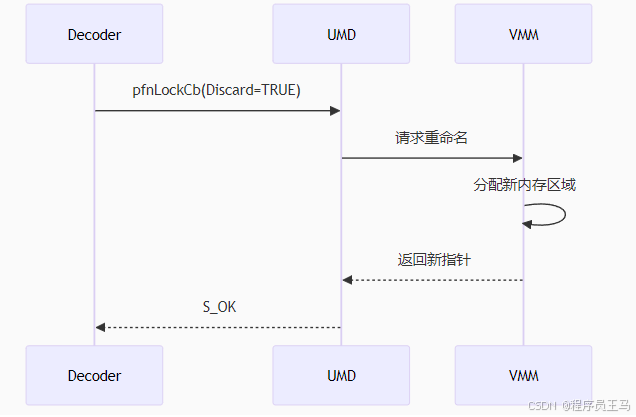
实现模式选择策略
驱动程序决策矩阵:
| 使用场景 | 推荐策略 | 性能影响 |
|---|---|---|
| 只读缓冲区 | 等待锁定 | 低延迟 |
| 动态更新缓冲区 | 重命名 | 高吞吐量 |
| 关键路径操作 | 混合模式 | 平衡 |
技术实现细节
锁定标志配置
typedef struct _D3DDDICB_LOCKFLAGS {
UINT Discard : 1; // 请求重命名
UINT NoOverwrite : 1; // 只读保证
UINT Reserved : 30;
} D3DDDICB_LOCKFLAGS;驱动程序示例实现
HRESULT LockBuffer(
HANDLE hBuffer,
D3DDDICB_LOCKFLAGS* pFlags)
{
// 检查硬件使用状态
BufferState state = GetHWBufferState(hBuffer);
if (state == BUSY && !pFlags->Discard) {
return DXVA2_E_BUFFER_BUSY; // 拒绝锁定
}
if (state == BUSY && pFlags->Discard) {
// 执行重命名逻辑
void* pNewMem = AllocateRenamedBuffer();
UpdateHWResourceMapping(hBuffer, pNewMem);
return S_OK; // 返回新资源
}
// 正常锁定路径
return S_OK;
}高级同步场景处理
多线程访问控制
class SafeBuffer {
std::mutex mtx;
void* pResource;
public:
void* Lock(bool discard) {
std::lock_guard<std::mutex> lock(mtx);
if (IsHWUsing() && !discard) {
return nullptr;
}
return pResource;
}
};硬件直接访问优化
当硬件支持零拷贝时:
void SetupZeroCopy()
{
// 配置GPU直接访问压缩缓冲区
ConfigureDMAPath();
// 设置硬件写回标记
EnableHWUsageFlag();
}性能优化指南
缓冲区生命周期管理
预分配策略
// 初始化时创建缓冲池
std::vector<Buffer> bufferPool(MAX_FRAMES);动态重命名阈值:
if (waitTime > RENAME_THRESHOLD) {
lockFlags.Discard = TRUE;
}硬件特性检测
bool SupportsHardwareRenaming()
{
DXVA2_VideoDesc desc = {0};
D3DDDIARG_GETCAPS caps = {0};
// ...填充查询参数
return SUCCEEDED(GetCaps(&caps));
}兼容性注意事项
1.0到2.0的迁移策略
逐步替换轮询逻辑:
- while (QueryStatus() == BUSY);
+ if (FAILED(Lock())) { DiscardLock(); }混合模式支持:
#ifdef DXVA2_MIGRATION
// 兼容旧版逻辑
#endif错误处理最佳实践
HRESULT HandleLockResult(HRESULT hr)
{
switch (hr) {
case DXVA2_E_BUFFER_BUSY:
return RetryWithDiscard();
case E_OUTOFMEMORY:
return FreeResourcesAndRetry();
default:
return hr;
}
}这种同步机制的改进使得DirectX VA 2.0能够:
- 显著降低CPU开销(相比轮询减少最高90%)
- 实现更稳定的帧率输出
- 更好地集成到现代GPU调度系统中
- 支持更复杂的多线程解码场景



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









