






目录
一、主成分分析概述
1.概念
主成分分析(Principal Component Analysis, 简称PCA)是一种常见的统计方法,用于数据降维和特征提取。它通过线性变换将原始数据投影到一个由各主成分组成的新坐标系中,这些主成分是原始数据中方差最大的方向。这样做可以减少数据的维度,去除数据中的噪声和冗余信息,帮助发现数据中的模式和结构。主成分分析的目标是找到一组正交的新变量(主成分),使得数据在这些新变量上的方差最大。通过对数据的协方差矩阵进行特征值分解,可以得到主成分的方向和相对重要性,并根据这些主成分对数据进行投影和降维。主成分分析常用于数据可视化、数据压缩、特征选择和模式识别等领域,是一种常见的无监督学习方法。通过主成分分析,我们可以更好地理解数据的分布和结构,发现数据中的潜在模式和规律。
2.基本原理
主成分分析是一种常用的降维方法,它通过线性变换将原始数据映射到一个新的坐标系中,使得映射后的数据在新坐标系下具有最大的方差,从而找到数据中最重要的主成分。主成分分析的基本原理如下:
(1) 数据中心化:首先对原始数据进行中心化处理,即将数据减去各自的均值,使数据的均值为0。
(2)计算协方差矩阵:计算中心化后的数据的协方差矩阵,该矩阵反映了数据之间的线性关系。(3)特征值分解:对协方差矩阵进行特征值分解,得到特征值和特征向量。
(4)选择主成分:根据特征值的大小选择最重要的前n个特征向量作为主成分,这些特征向量对应的特征值表示了数据中的方差。
(5)映射数据:将原始数据投影到主成分上,得到降维后的数据,这些数据在主成分方向上的方差最大。
通过主成分分析,可以得到数据的主要结构信息,降低数据维度同时保留较高的信息量,便于后续的数据分析和可视化。
3.优缺点
主成分分析(PCA)是一种常用的数据降维技术,其优点和缺点如下:
优点:
(1)PCA可以帮助发现数据中的隐藏模式和结构,减少数据的维度,提高数据的可解释性。
(2)PCA能够提高数据的处理效率,减少计算和存储的时间和空间成本。
(3)PCA可以减少数据中的噪声和冗余信息,提高模型的泛化能力和预测精度。
缺点:
(1)PCA假设数据是线性可分的,对于非线性数据表达能力有限。
(2)PCA需要对数据进行中心化处理,对数据的分布和尺度敏感,可能会改变数据的原始含义。
(3)PCA降维后可能丢失一些重要信息,导致模型性能下降。
(4)PCA对数据的特征之间的相关性敏感,如果特征之间相关性较低,可能会影响降维效果。
二、主成分分析相关概念介绍
1.协方差、方差和协方差矩阵
主成分分析是一种常用的数据降维技术,通过将原始数据投影到新的特征空间来实现数据压缩。在主成分分析中,我们通常会涉及到协方差、方差和协方差矩阵等概念。
(1)协方差:在统计学中,协方差描述了两个随机变量之间的关系。如果两个变量的协方差为正值,表示它们具有正相关性;如果为负值,则表示它们之间存在负相关性。在主成分分析中,通过计算原始数据的协方差矩阵来确定数据之间的相关性,从而找到数据中的主成分。
(2)方差:方差表示一个随机变量与其均值之间的差异程度,是协方差的一种特殊形式,即两个变量相同时的协方差即为它们自身的方差。在主成分分析中,方差也被用来衡量数据中的变异性,方差越大,表示数据的变化范围越广。
(3)协方差矩阵:协方差矩阵是一个对称矩阵,其中对角线上的元素是各个变量的方差,非对角线上的元素是相应变量之间的协方差。在主成分分析中,协方差矩阵是一个重要的概念,通过对协方差矩阵进行特征分解,我们可以找到数据中的主成分方向,并且可以通过主成分的重要性(即方差)来选择最重要的主成分。
2.特征向量和特征值
特征向量和特征值是主成分分析中非常重要的概念,用来描述数据集中的主要变化方向和变化强度。
(1)特征向量:在主成分分析中,特征向量是一个方向向量,它描述了数据集中的变化方向。对于一个给定的协方差矩阵,特征向量是一个满足以下条件的非零向量:当这个向量与原始矩阵相乘时,它的方向不变,只是乘以一个标量。换句话说,特征向量指示了数据集中的一个新的坐标系,使得在这个坐标系中数据的变化方向最为明显。
(2)特征值:特征值是与特征向量相关联的一个数值,它描述了特征向量代表的变化方向的重要程度。对于一个给定的协方差矩阵,特征值是一个标量,它表示在特征向量方向上数据的变化强度。特征值越大,说明数据在这个特征向量方向上的变化越显著。
在主成分分析中,通过计算协方差矩阵的特征值和特征向量,我们可以找到数据集中最重要的主要变化方向,从而进行数据降维和可视化分析。
3.数据降维
数据降维是指将原始数据中的特征进行转换,使得转换后的数据具有更少的维度,但依然能够尽可能地保留原始数据的信息。
数据降维是一种十分重要的数据处理手段,可以帮助我们更好地发现数据的内在结构和特性,为后续的数据分析和建模提供更好的基础。 主成分分析通过寻找数据中的主要模式和结构,在保留尽可能多的信息的同时,将数据从原始的高维空间降维到一个更低维的空间。这样可以减少数据的复杂度,同时也可以更好地展现数据的内在特性。数据降维可以更好地发现数据中的模式和结构,使得数据更易于解释和理解。另外,降维后的数据可以更方便地进行可视化和分析,同时也可以节省存储空间和计算资源。
4.主成分分析算法描述
输入:样本集 D ={x1,x2,...,xm};低维空间维数 d'.
过程:
(1)对所有样本进行中心化:
(2)计算样本的协方差矩阵;
(3)对协方差矩阵做特征值分解;
(4)取最大的 d'个特征值所对应的特征向量w1,w2,...,wd'.
输出:投影矩阵 W =(w1,w2,...,wd').
三、主成分分析具体实现
1.过程分析
我们主要通过PCA实现对手写数字数据集的降维可视化和分类准确率的分析。具体步骤如下:
(1)载入手写数字数据集,特征数据存储在X中,目标标签存储在y中。
def load_dataset():
# 载入手写数字数据集
digits = datasets.load_digits()
X = digits.data # 特征数据
y = digits.target # 目标标签
return X, y
(2)定义了一个函数`pca_visualization`来进行PCA降维和分类准确率的计算。
def pca_visualization(X, y, n_components_list):
accuracies = []
(3)对于给定的不同降维后保留的成分数量列表`n_components_list = [2, 5, 10, 20, 30, 40, 50, 64]`,依次进行如下操作:
①使用PCA进行降维,将原始特征数据X降至指定的成分数量。
②将数据集分割为训练集和测试集(80%训练集,20%测试集)。
③使用支持向量机(SVM)进行分类。
④计算分类准确率,并将准确率结果存储在`accuracies`列表中。
for n_components in n_components_list:
# 使用PCA进行降维
pca = PCA(n_components=n_components)
X_pca = pca.fit_transform(X)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_pca, y, test_size=0.2, random_state=42)
# 使用支持向量机进行分类
clf = SVC()
clf.fit(X_train, y_train)
# 计算分类准确率
accuracy = clf.score(X_test, y_test)
accuracies.append(accuracy)n_components_list = [2, 5, 10, 20, 30, 40, 50, 64] # 根据需求调整降维后保留的成分数量列表
X, y = load_dataset()
pca_visualization(X, y, n_components_list)
(4)最后,通过绘制保留的成分数量与分类准确率的曲线图,来展示降维后准确率的变化情况。
plt.plot(n_components_list, accuracies)
plt.xlabel('保留的成分数量')
plt.ylabel('准确率')
plt.title('PCA可视化')
plt.show()我们可以通过分析不同PCA降维后保留的成分数量对分类准确率的影响,观察曲线来找到合适的降维成分数量,以平衡维度的减少和分类准确率的保持。
2.具体代码实现
import numpy as np
from sklearn.decomposition import PCA
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
import matplotlib.pyplot as plt
from sklearn import datasets
def vectorize_image(image):
# 将图像展平为一维数组
return image.flatten()
def load_dataset():
# 载入手写数字数据集
digits = datasets.load_digits()
X = digits.data # 特征数据
y = digits.target # 目标标签
return X, y
def pca_visualization(X, y, n_components_list):
accuracies = []
for n_components in n_components_list:
# 使用PCA进行降维
pca = PCA(n_components=n_components)
X_pca = pca.fit_transform(X)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_pca, y, test_size=0.2, random_state=42)
# 使用支持向量机进行分类
clf = SVC()
clf.fit(X_train, y_train)
# 计算分类准确率
accuracy = clf.score(X_test, y_test)
accuracies.append(accuracy)
# 绘制准确率随降维后保留的成分数量变化的曲线
plt.plot(n_components_list, accuracies)
plt.xlabel('保留的成分数量')
plt.ylabel('准确率')
plt.title('PCA可视化')
plt.show()
if __name__ == '__main__':
n_components_list = [2, 5, 10, 20, 30, 40, 50, 64] # 根据需求调整降维后保留的成分数量列表
X, y = load_dataset()
pca_visualization(X, y, n_components_list)3.运行结果分析
主成分分析的结果准确率与降维次数的关系如下所示:
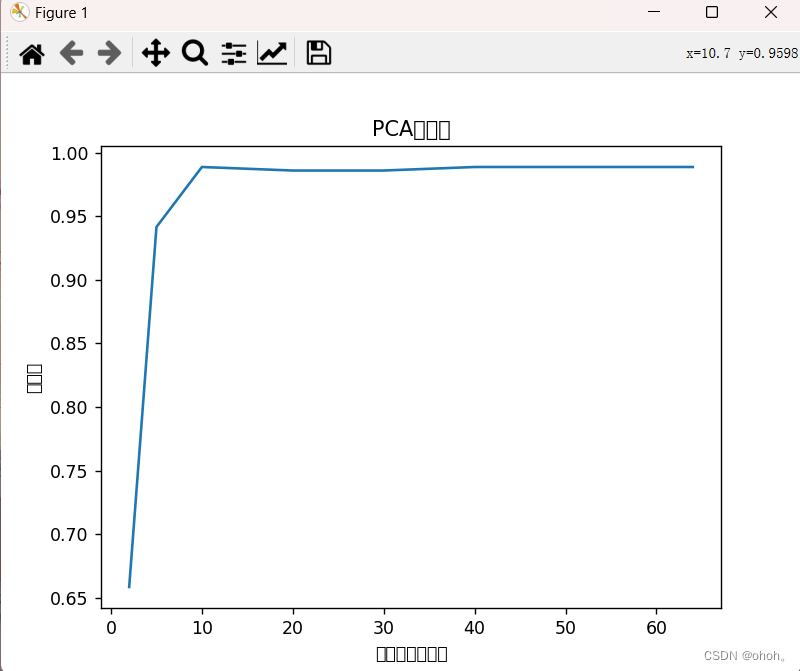
我们主要实现了使用PCA(主成分分析)进行降维,并结合支持向量机(SVM)进行手写数字数据集的分类任务。在给定不同的降维后保留的成分数量(n_components)列表后,代码会循环遍历每个成分数量,将数据集进行PCA降维,然后将降维后的数据集拆分为训练集和测试集,在训练集上训练SVM分类器,最后评估分类器在测试集上的准确率。
曲线的横坐标表示保留的成分数量,纵坐标表示对应的准确率。通过绘制这条曲线,我们可以观察不同成分数量下分类器的准确率变化趋势。通常来说,随着成分数量的增加,准确率会先增加后达到稳定,然后可能会出现下降的情况,这是因为增加成分数量可以保留更多的信息,但也可能包含噪声,导致模型泛化能力降低。因此,可以通过曲线来选择一个合适的成分数量,即在准确率较高且不至于过拟合的情况下找到一个平衡点。这种关系可以帮助我们选择合适的降维成分数量,以在保持数据信息的同时提高分类准确率。
四、实验总结
主成分分析(PCA)是一种常用的数据降维方法,用于发现数据中的主要模式和结构。主成分分析主要用于减少数据集中的维度,同时保留大部分数据的变异性。主成分分析的主要步骤包括数据标准化、计算协方差矩阵、计算特征值和特征向量、选择主成分和计算得分等。通过主成分分析,我们可以减少数据的维度,减少冗余信息,同时保留尽可能多的数据变异性。主成分分析可用于数据预处理、数据压缩、特征提取等领域。在实际应用中,主成分分析可以帮助我们更好地理解数据结构,发现隐藏的模式和规律。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











