







数据结构与算法 图
图(graph)是一种非线性数据结构,由「顶点 vertex」和「边 edge」组成。我们可以将图G抽象地表示为一组顶点 𝑉 和一组边 𝐸 的集合。以下示例展示了一个包含 5 个顶点和 7 条边的图。
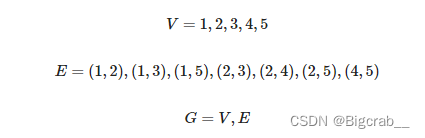
相较于线性关系(链表)和分治关系(树),网络关系(图)的自由度更高
根据边是否有方向:有向图和无向图
根据所有顶点是否连通:连通图和非连通图
根据边是否有权重:有权图和无权图
- 「邻接 adjacency」:当两顶点之间存在边相连时,称这两顶点“邻接”。在图 9‑4 中,顶点 1 的邻接顶点为顶点 2、3、5。
- 「路径 path」:从顶点 A 到顶点 B 经过的边构成的序列被称为从 A 到 B 的“路径”。在图 9‑4 中,边序列 1‑5‑2‑4 是顶点 1 到顶点 4 的一条路径。
- 「度 degree」:一个顶点拥有的边数。对于有向图,「入度 In‑Degree」表示有多少条边指向该顶点,「出度 Out‑Degree」表示有多少条边从该顶点指出。
图的表现形式
邻接矩阵
- 顶点不能与自身相连,因此邻接矩阵主对角线元素没有意义。
- 对于无向图,两个方向的边等价,此时邻接矩阵关于主对角线对称。
- 将邻接矩阵的元素从1 和 0 替换为权重,则可表示有权图。
使用邻接矩阵表示图时,我们可以直接访问矩阵元素以获取边,因此增删查操作的效率很高,时间复杂度均为 𝑂(1) 。然而,矩阵的空间复杂度为 𝑂(𝑛2 ) ,内存占用较多。
![![[Pasted image 20230920191853.png]]](https://img-blog.csdnimg.cn/6d422e5753514e62acadbb9794455214.png)
class GraphAdjMat:
def __init__(self, vertices: list[int], edges: list[list[int]]):
""" 构造方法"""
self.vertices: list[int] = []
self.adj_mat: list[list[int]] = []
# 添加顶点
for val in vertices:
self.add_vertex(val)
# 添加边
# 请注意,edges 元素代表顶点索引,即对应 vertices 元素索引
for e in edges:
self.add_edge(e[0], e[1])
def size(self) -> int:
""" 获取顶点数量"""
return len(self.vertices)
def add_vertex(self, val: int):
""" 添加顶点"""
n = self.size()
# 向顶点列表中添加新顶点的值
self.vertices.append(val)
# 在邻接矩阵中添加一行
new_row = [0] * n
self.adj_mat.append(new_row)
# 在邻接矩阵中添加一列
for row in self.adj_mat:
row.append(0)
def remove_vertex(self, index: int):
""" 删除顶点"""
if index >= self.size():
raise IndexError()
# 在顶点列表中移除索引 index 的顶点
self.vertices.pop(index)
# 在邻接矩阵中删除索引 index 的行
self.adj_mat.pop(index)
# 在邻接矩阵中删除索引 index 的列
for row in self.adj_mat:
row.pop(index)
def add_edge(self, i: int, j: int):
""" 添加边"""
# 参数 i, j 对应 vertices 元素索引
# 索引越界与相等处理
if i < 0 or j < 0 or i >= self.size() or j >= self.size() or i == j:
raise IndexError()
# 在无向图中,邻接矩阵沿主对角线对称,即满足 (i, j) == (j, i)
self.adj_mat[i][j] = 1
self.adj_mat[j][i] = 1
def remove_edge(self, i: int, j: int):
""" 删除边"""
# 参数 i, j 对应 vertices 元素索引
# 索引越界与相等处理
if i < 0 or j < 0 or i >= self.size() or j >= self.size() or i == j:
raise IndexError()
self.adj_mat[i][j] = 0
self.adj_mat[j][i] = 0
def print_matrix(self, mat):
for row in mat:
print(row)
def print(self):
""" 打印邻接矩阵"""
print(" 顶点列表 =", self.vertices)
print(" 邻接矩阵 =")
self.print_matrix(self.adj_mat)
邻接表
邻接表仅存储实际存在的边,而边的总数通常远小于 𝑛 2 ,因此它更加节省空间。然而,在邻接表中需要通过遍历链表来查找边,因此其时间效率不如邻接矩阵。
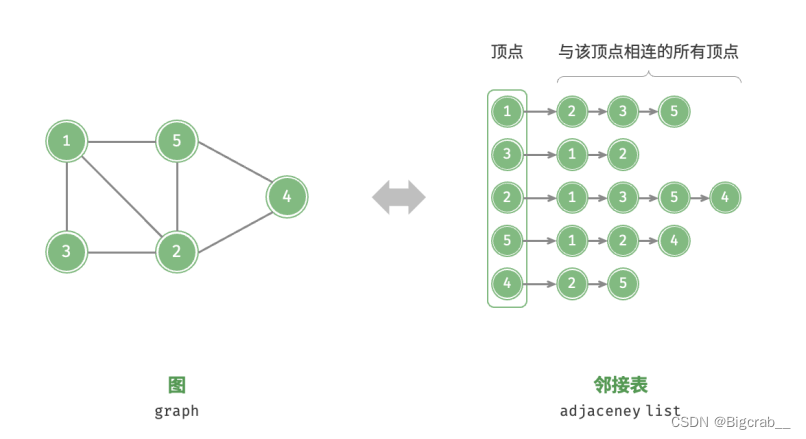
邻接表结构与哈希表中的“链式地址”非常相似,因此我们也可以采用类似方法来优化效率。比
如当链表较长时,可以将链表转化为 AVL 树或红黑树,从而将时间效率从𝑂(𝑛) 优化至 𝑂(log 𝑛) ;还可以把链表转换为哈希表,从而将时间复杂度降低至 𝑂(1) 。
class GraphAdjList:
""" 基于邻接表实现的无向图类"""
def __init__(self, edges):
""" 构造方法"""
# 邻接表,key: 顶点,value:该顶点的所有邻接顶点
self.adj_list = dict()
# 添加所有顶点和边
for edge in edges:
self.add_vertex(edge[0])
self.add_vertex(edge[1])
self.add_edge(edge[0], edge[1])
def size(self) -> int:
""" 获取顶点数量"""
return len(self.adj_list)
def add_edge(self, vet1, vet2):
""" 添加边"""
if vet1 not in self.adj_list or vet2 not in self.adj_list or vet1 == vet2:
raise ValueError()
# 添加边 vet1 - vet2
self.adj_list[vet1].append(vet2)
self.adj_list[vet2].append(vet1)
def remove_edge(self, vet1, vet2):
""" 删除边"""
if vet1 not in self.adj_list or vet2 not in self.adj_list or vet1 == vet2:
raise ValueError()
# 删除边 vet1 - vet2
self.adj_list[vet1].remove(vet2)
self.adj_list[vet2].remove(vet1)
def add_vertex(self, vet):
""" 添加顶点"""
if vet in self.adj_list:
return
# 在邻接表中添加一个新链表
self.adj_list[vet] = []
def remove_vertex(self, vet):
""" 删除顶点"""
if vet not in self.adj_list:
raise ValueError()
# 在邻接表中删除顶点 vet 对应的链表
self.adj_list.pop(vet)
# 遍历其他顶点的链表,删除所有包含 vet 的边
for vertex in self.adj_list:
if vet in self.adj_list[vertex]:
self.adj_list[vertex].remove(vet)
def print(self):
""" 打印邻接表"""
print(" 邻接表 =")
for vertex in self.adj_list:
tmp = [v.val for v in self.adj_list[vertex]]
print(f"{vertex.val}: {tmp},")
效率对比
![![[Pasted image 20230920204255.png]]](https://img-blog.csdnimg.cn/bdeff67657614e38bc214c3ccfc127cc.png)
似乎邻接表(哈希表)的时间与空间效率最优。但实际上,在邻接矩阵中操作边的效率更高,只需要一次数组访问或赋值操作即可。综合来看,邻接矩阵体现了“以空间换时间”的原则,而邻接表体现了“以时间换空间”的原则。
图的遍历
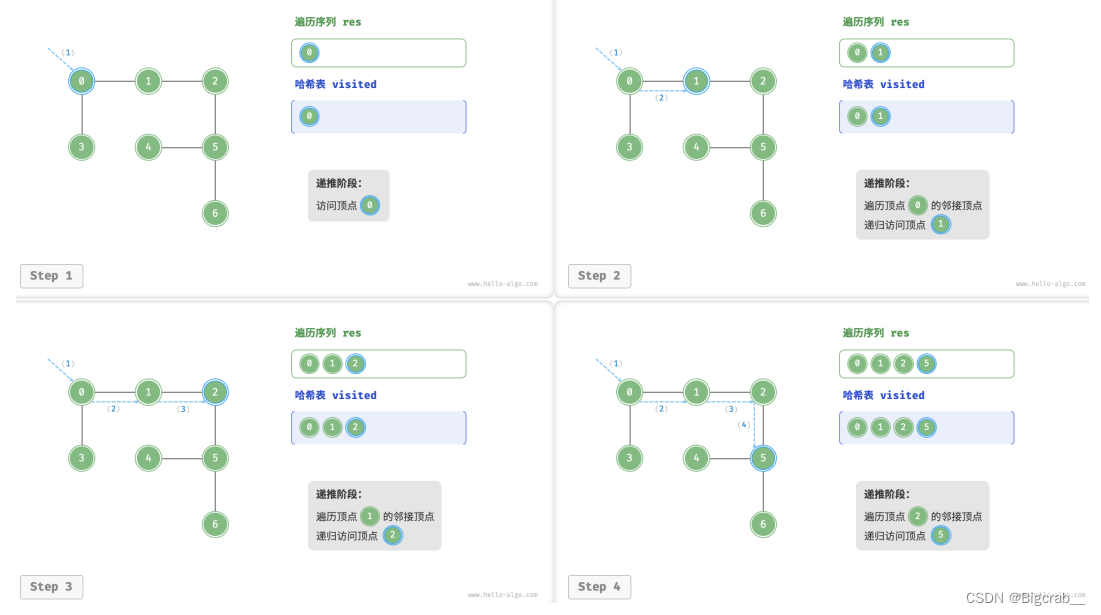
广度优先遍历(BFS)
from collections import deque
def graph_bfs(graph: GraphAdjList):
""" 广度优先遍历 BFS"""
# 使用邻接表来表示图,以便获取指定顶点的所有邻接顶点
# 顶点遍历序列
res = []
# 哈希表,用于记录已被访问过的顶点
visited = set([])
# 队列用于实现 BFS
que = deque([])
# 以顶点 vet 为起点,循环直至访问完所有顶点
while len(que) > 0:
vet = que.popleft() # 队首顶点出队
res.append(vet) # 记录访问顶点
# 遍历该顶点的所有邻接顶点
for adj_vet in graph.adj_list[vet]:
if adj_vet in visited:
continue # 跳过已被访问过的顶点
que.append(adj_vet) # 只入队未访问的顶点
visited.add(adj_vet) # 标记该顶点已被访问
# 返回顶点遍历序列
return res
![![[Pasted image 20230920234821.png]]](https://img-blog.csdnimg.cn/0b0b327fbb704fbf9b342f0fd4bc8443.png)
时间复杂度:所有顶点都会入队并出队一次,使用𝑂(|𝑉 |) 时间;在遍历邻接顶点的过程中,由于是无向图,因此所有边都会被访问2 次,使用 𝑂(2|𝐸|) 时间;总体使用𝑂(|𝑉 | + |𝐸|) 时间。
空间复杂度:列表 res ,哈希表 visited ,队列 que 中的顶点数量最多为|𝑉 | ,使用 𝑂(|𝑉 |) 空间。
深度优先遍历(DFS)
深度优先遍历是一种优先走到底、无路可走再回头的遍历方式
def dfs(graph: GraphAdjList, visited, res, vet):
""" 深度优先遍历 DFS 辅助函数"""
res.append(vet) # 记录访问顶点
visited.add(vet) # 标记该顶点已被访问
# 遍历该顶点的所有邻接顶点
for adjVet in graph.adj_list[vet]:
if adjVet in visited:
continue # 跳过已被访问过的顶点
# 递归访问邻接顶点
dfs(graph, visited, res, adjVet)
def graph_dfs(graph: GraphAdjList, start_vet)
""" 深度优先遍历 DFS"""
# 使用邻接表来表示图,以便获取指定顶点的所有邻接顶点
# 顶点遍历序列
res = []
# 哈希表,用于记录已被访问过的顶点
visited = set()
dfs(graph, visited, res, start_vet)
return res
时间复杂度:所有顶点都会被访问1 次,使用 𝑂(|𝑉 |) 时间;所有边都会被访问2 次,使用𝑂(2|𝐸|)时间;总体使用𝑂(|𝑉 | + |𝐸|)时间。
空间复杂度:列表 res ,哈希表 visited 顶点数量最多为|𝑉 | ,递归深度最大为 |𝑉 |,因此使用𝑂(|𝑉 |)
空间。
重点回顾
- 图由顶点和边组成,可以被表示为一组顶点和一组边构成的集合。
- 相较于线性关系(链表)和分治关系(树),网络关系(图)具有更高的自由度,因而更为复杂。
- 有向图的边具有方向性,连通图中的任意顶点均可达,有权图的每条边都包含权重变量。
- 邻接矩阵利用矩阵来表示图,每一行(列)代表一个顶点,矩阵元素代表边,用1 或 0 表示两个顶点之间有边或无边。邻接矩阵在增删查操作上效率很高,但空间占用较多。
- 邻接表使用多个链表来表示图,第 𝑖 条链表对应顶点 𝑖 ,其中存储了该顶点的所有邻接顶点。邻接表相对于邻接矩阵更加节省空间,但由于需要遍历链表来查找边,时间效率较低。
- 当邻接表中的链表过长时,可以将其转换为红黑树或哈希表,从而提升查询效率。
- 从算法思想角度分析,邻接矩阵体现“以空间换时间”,邻接表体现“以时间换空间”。
- 图可用于建模各类现实系统,如社交网络、地铁线路等。
- 树是图的一种特例,树的遍历也是图的遍历的一种特例。
- 图的广度优先遍历是一种由近及远、层层扩张的搜索方式,通常借助队列实现。
- 图的深度优先遍历是一种优先走到底、无路可走时再回溯的搜索方式,常基于递归来实现。















 368
368











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









