







Gensim = “Generate Similar”
The algorithms in Gensim, such as Word2Vec, FastText, Latent Semantic Indexing (LSI, LSA, LsiModel), Latent Dirichlet Allocation (LDA, LdaModel) etc, automatically discover the semantic structure of documents by examining statistical co-occurrence patterns within a corpus of training documents. These algorithms are unsupervised, which means no human input is necessary – you only need a corpus of plain text documents.
Gensim中的算法,如Word2Verc、FastText、潜在语义索引(LSI、LSA、LsiModel)、潜在狄利克雷分配(LDA、LdaModel)等,通过检查训练文档语料库中的统计共现模式,自动发现文档的语义结构。这些算法是无监督的,这意味着不需要人工输入——你只需要一个纯文本文档的语料库。
一、安装
pip install --upgrade gensim
二、文本预处理
- Document: 文档,文档字符串 即:“这是一段话”
- Corpus: 语料,文档字符串列表 即:[“这是一段话”, “这是一段话”]
- Vector: 向量,应该最好懂 即词在空间中的位置表
- Bow Corpus:文档分词元组化后的语料列表,元组第一个位置是词对应dictionary的id,第二个是文档中该词出现的次数
2.1 中文语料处理
中文语料:无大小写问题,标点符号问题,词之间无空格,无时态词,需要分词
这里我们使用清华的分词工具Thulac进行分词;
def chinese_process(text_corpus, stoplist=[], k=0, punctuation='"#$%&'()*+,-/:;<=>@[\]^_`{|}~⦅⦆「」、\u3000、〃〈〉《》「」『』【】〔〕〖〗〘〙〚〛〜〝〞〟〰〾〿–—‘’‛“”„‟…‧﹏﹑﹔·.!?。。'):
"""
text_corpus: 语料
stoplist: 需要删除的词
k:过滤次数小于等于k次的词
punctuation:需要删除的标点符号
"""
import thulac
from collections import defaultdict
model = thulac.thulac(seg_only=True)
texts = [[word for word in model.cut(document, text=True).split() if word not in stoplist] for document in text_corpus]
frequency = defaultdict(int)
for text in texts:
for token in text:
frequency[token] += 1
processed_corpus = [[token for token in text if frequency[token] > k] for text in texts]
return processed_corpus
测试:
text_corpus = [
'实验室abc计算机应用的人机界面',
'用户对计算机系统响应时间的看法调查',
'EPS用户界面管理系统',
'EPS的系统与人系统工程测试',
'用户感知的响应时间与误差测量的关系',
'随机二进制无序树的生成',
'树中路径的交集图',
'图子Ⅳ树的宽度和井的拟序',
'图表未成年人调查'
]
print(chinese_process(text_corpus))
# [['实验室', 'abc', '计算机', '应用', '的', '人', '机界', '面'],
# ['用户', '对', '计算机', '系统', '响应', '时间', '的', '看法', '调查'],
# ['EPS', '用户', '界面', '管理', '系统'],
# ['EPS', '的', '系统', '与', '人', '系统工程', '测试'],
# ['用户', '感知', '的', '响应', '时间', '与', '误差', '测量', '的', '关系'],
# ['随机', '二进制', '无序', '树', '的', '生成'],
# ['树', '中', '路径', '的', '交集', '图'],
# ['图子', 'Ⅳ', '树', '的', '宽度', '和', '井', '的', '拟序'],
# ['图表', '未成年人', '调查']]
2.2 英文语料处理
英文语料:大小写问题,标点符号问题,词之间有空格, 词有不同形式,需要分词
def english_process(text_corpus, stoplist=[], k=0, punctuation='!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~'):
"""
text_corpus: 语料
stoplist: 需要删除的词
k:过滤次数小于等于k次的词
punctuation:需要删除的标点符号
"""
from collections import defaultdict
import re
texts = [[word for word in re.sub(r'[{}]+'.format(punctuation), '', document).lower().split() if word not in stoplist] for document in text_corpus]
frequency = defaultdict(int)
for text in texts:
for token in text:
frequency[token] += 1
processed_corpus = [[token for token in text if frequency[token] > k] for text in texts]
return processed_corpus
测试:
text_corpus = [
"Human machine interface for lab abc computer applications",
"A survey of user opinion of computer system response time",
"The EPS user interface management system",
"System and human system engineering testing of EPS",
"Relation of user perceived response time to error measurement",
"The generation of random binary unordered trees",
"The intersection graph of paths in trees",
"Graph minors IV Widths of trees and well quasi ordering",
"Graph minors A survey",
]
stoplist = set('for a of the and to in'.split(' '))
print(english_process(text_corpus, stoplist))
# [['human', 'machine', 'interface', 'lab', 'abc', 'computer', 'applications'],
# ['survey', 'user', 'opinion', 'computer', 'system', 'response', 'time'],
# ['eps', 'user', 'interface', 'management', 'system'],
# ['system', 'human', 'system', 'engineering', 'testing', 'eps'],
# ['relation', 'user', 'perceived', 'response', 'time', 'error', 'measurement'],
# ['generation', 'random', 'binary', 'unordered', 'trees'],
# ['intersection', 'graph', 'paths', 'trees'],
# ['graph', 'minors', 'iv', 'widths', 'trees', 'well', 'quasi', 'ordering'],
# ['graph', 'minors', 'survey']]
2.3 BOW语料建立
首先把语料进行处理后,得到二维列表,然后将二维列表传入gensim库中的corpus.dictionary模块建立字典,然后根据字典对处理后的语料进行生成BOW语料
text_corpus = [
"Human machine interface for lab abc computer applications",
"A survey of user opinion of computer system response time",
"The EPS user interface management system",
"System and human system engineering testing of EPS",
"Relation of user perceived response time to error measurement",
"The generation of random binary unordered trees",
"The intersection graph of paths in trees",
"Graph minors IV Widths of trees and well quasi ordering",
"Graph minors A survey",
]
# 中文语料处理
text_corpus = chinese_process(text_corpus)
# 建立字典
dictionary = gensim.corpora.Dictionary(text_corpus)
# dictionary.token2id {'abc': 0, '人': 1,'实验室': 2, '应用': 3, ...}
bow_corpus = [dictionary.doc2bow(item) for item in text_corpus]
# [[(0, 1), (1, 1), (2, 1), (3, 1), (4, 1), (5, 1), (6, 1), (7, 1)],
# [(5, 1), (6, 1), (8, 1), (9, 1), (10, 1), (11, 1), (12, 1), (13, 1), (14, 1)],
# [(11, 1), (13, 1), (15, 1), (16, 1), (17, 1)],....]
三、模型使用
3.1 word2vec
Word2Vec 是一种词向量模型,它使用浅层神经网络将单词嵌入到低维向量空间中。结果是一组词向量,其中在向量空间中靠近的向量根据上下文具有相似的含义,而彼此相距较远的词向量具有不同的含义。
word2vec 有两种出名的模型,两种加速方式,如果理解可以在此自由配置,
论文实现:Efficient Estimation of Word Representations in Vector Space [CBOW and Skip-gram]
sg : {0, 1}, optional
Training algorithm: 1 for skip-gram; otherwise CBOW.
hs : {0, 1}, optional
If 1, hierarchical softmax will be used for model training.
If 0, hierarchical softmax will not be used for model training.
negative : int, optional
If > 0, negative sampling will be used, the int for negative specifies how many “noise words” should be drawn (usually between 5-20).
If 0, negative sampling will not be used.
模型相关代码:
text_corpus = [['实验室', 'abc', '计算机', '应用', '的', '人', '机界', '面'],
['用户', '对', '计算机', '系统', '响应', '时间', '的', '看法', '调查']]
word2vec = gensim.models.Word2Vec(
sentences=text_corpus,
min_count=1,
window=3,
vector_size=100,
)
# 输出word向量
word2vec.wv['中']
# array([ 0.00480066, -0.00362838, -0.00426481, 0.00121976, -0.0041273, ... dtype=float32)
# 计算两个词之间的相似性
word2vec.wv.similarity('图表','图子')
# 0.13703643
# 类似于king-man+woman=queen
word2vec.wv.most_similar(positive=['图子', '图表'], negative=['中'])
# [('系统工程', 0.1806158870458603),('感知', 0.17817144095897675),('界面', 0.13787229359149933),...]
# 找不和其他匹配的项
word2vec.wv.doesnt_match(['图子', '图表', '中'])
# '中'
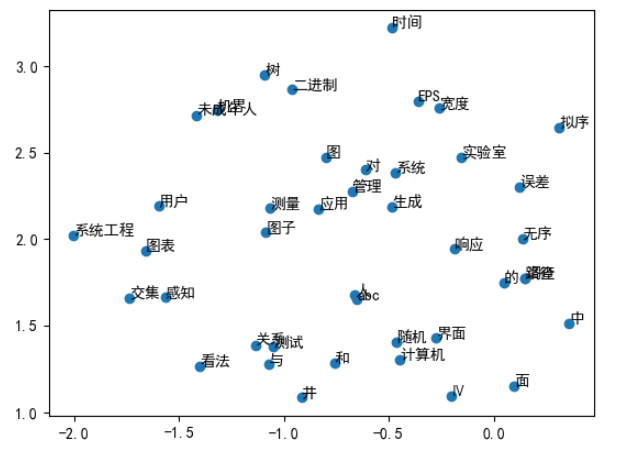
词向量可视化 这里使用的是TSNE算法进行的降维
from sklearn.manifold import TSNE
import numpy as np
import matplotlib.pyplot as plt
# 中文设置
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
def reduce_dimensions(model):
num_dimensions = 2
# 提取vectors和labels
vectors = np.asarray(model.wv.vectors)
labels = np.asarray(model.wv.index_to_key)
# 降维
tsne = TSNE(n_components=num_dimensions, random_state=0)
vectors = tsne.fit_transform(vectors)
x_vals = [v[0] for v in vectors]
y_vals = [v[1] for v in vectors]
return x_vals, y_vals, labels
x,y,label = reduce_dimensions(word2vec)
plt.scatter(x,y)
for x_,y_,label_ in zip(x,y,label):
plt.text(x_, y_, label_)
plt.show()
可视化结果如下:














 786
786











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









