







Amazon Redshift是一种快速、可扩展、安全且完全托管的云数据仓库,可以帮助用户通过标准SQL语言简单、经济地分析各类数据。相比其他任何云数据仓库,Amazon Redshift可实现高达三倍的性能价格比。数万家客户正在借助Amazon Redshift每天处理EB级别的数据,借此为高性能商业智能(BI)报表、仪表板应用、数据探索和实时分析等分析工作负载提供强大动力。
我们很激动地为Amazon Kinesis Data Streams发布了Amazon Redshift流式摄取功能,借此用户无需事先将数据存储在Amazon Simple Storage Service(Amazon S3)中,即可将Kinesis数据流摄取到云数据仓库中。流式摄取可以帮助用户以极低延迟,在几秒钟内将数百MB数据摄取到Amazon Redshift云数据仓库集群。
本文将介绍如何围绕Amazon Redshift云数据仓库创建Kinesis数据流,生成并加载流式数据,创建物化视图,并查询数据流并对结果进行可视化呈现。此外本文还讲介绍流式摄取的好处和常见用例。
云数据仓库有关流式摄取的需求
很多客户向我们反馈称想要将批处理分析能力进一步拓展为实时分析能力,并以低延迟高吞吐量的方式访问自己存储在数据仓库中的流式数据。此外,还有很多客户希望将实时分析结果与数据仓库中的其他数据源相结合,借此获得更丰富的分析结果。
Amazon Redshift流式摄取的主要用例均具备这样的特征:用于处理不断生成的(流式)数据,并且需要在数据生成后很短的时间(延迟)里处理完成。从IoT设备到系统遥测,从公共事业服务到设备定位,数据来源五花八门。
在流式摄取功能发布前,如果希望从Kinesis Data Steams摄取实时数据,需要将数据暂存至Amazon S3,然后使用COPY命令加载。这通常会产生数分钟的延迟,并且需要在从数据流加载数据的操作之上建立数据管道。但现在,用户已经可以直接从数据流摄取数据。
解决方案概述
Amazon Redshift流式摄取可让用户直接连接到Kinesis Data Streams,彻底消除了通过Amazon S3暂存数据并载入集群所导致的延迟和复杂性。借此,用户可以使用SQL命令连接并访问流式数据,并直接在数据流的基础上创建具体化试图,借此简化数据管道。物化视图亦可包含ELT(提取、加载和转换)管道所需的SQL转换。
定义了物化视图后,即可刷新视图以查询最新流式数据。这意味着我们可以使用SQL对流式数据执行下游处理和转换,并且无需付出额外成本,随后即可使用原有的BI和分析工具进行实时分析。
Amazon Redshift流式摄取会作为数据流的使用者来完成自己的工作,物化视图则可看作所要使用的流式数据的登陆区。刷新物化视图时,Amazon Redshift计算节点会将每个数据分片分配给一个计算切片。每个计算切片会开始处理所分配数据分片中的数据,直到物化视图达到与数据流对等的程度。物化视图的第一次刷新可从数据流的TRIM_HORIZON中获取数据,后续刷新则可从上一次刷新所产生的最后一个SEQUENCE_NUMBER中读取数据,直到其状态与流式数据实现对等。整个流程如下图所示。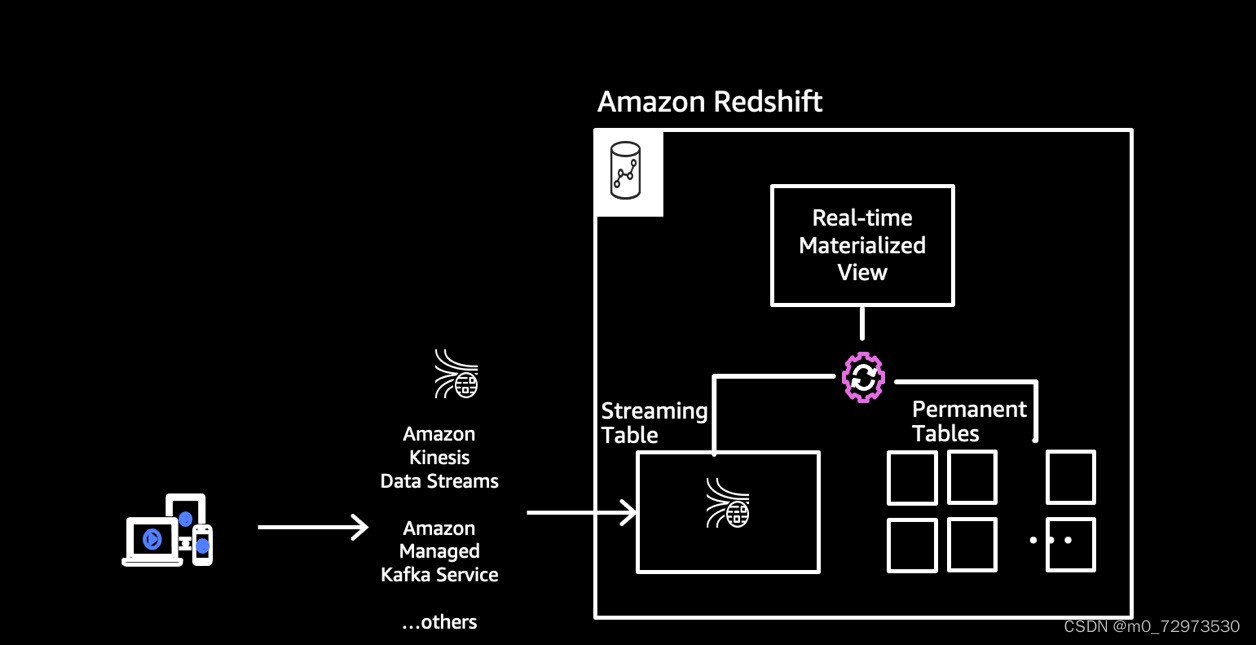
在Amazon Redshift中设置流式摄取需要执行两个步骤。首先,我们需要创建一个外部Schema以映射至Kinesis Data Streams,随后需要创建一个物化视图以便从数据流中拉取数据。物化视图必须能够增量维护。
创建Kinesis数据流
首先我们需要创建接收流式数据的Kinesis数据流。
1. 在Amazon Kinesis控制台中选择Data streams。
2. 选择Create data stream。
3.
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 623
623











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









