







要使用Elasticsearch进行分组聚合统计,可以使用聚合(aggregation)功能。聚合操作允许您根据指定的条件对文档进行分组,并计算每个分组的聚合结果。
针对普通类型的字段,DSL构建语法:
{
"aggs": {
"agg_name": {
"agg_type": {
"agg_parameters"
}
},
"agg_name2": {
"agg_type": {
"agg_parameters"
}
},
...
}
}
aggs: aggregations关键字的别名,代表着分组
agg_name: 这个是自定义的名字,可以针对你自己的字段命名一个,最好加上_agg后缀
agg_type: 聚合类型
agg_parameters:聚合参数
聚合类型(agg_type)
Elasticsearch中支持多种聚合类型(agg_type)用于不同的聚合操作。以下是一些常用的聚合类型及其功能:
- Terms(词条聚合):按照字段值进行分组,统计每个分组的文档数量。
- Sum(求和聚合):计算指定字段的总和。
- Avg(平均值聚合):计算指定字段的平均值。
- Min(最小值聚合):找出指定字段的最小值。
- Max(最大值聚合):找出指定字段的最大值。
- Stats(统计聚合):计算指定字段的统计信息,包括最小值、最大值、总和、平均值和文档数量。
- Extended Stats(扩展统计聚合):计算指定字段的扩展统计信息,包括最小值、最大值、总和、平均值、标准差和文档数量。
- Cardinality(基数聚合):计算指定字段的唯一值数量。
- Date Histogram(日期直方图聚合):按照时间间隔对日期字段进行分组。
- Range(范围聚合):将文档按照指定范围进行分组,例如按照价格范围、年龄范围等。
- Nested(嵌套聚合):在嵌套字段上执行子聚合操作。
除了上述示例外,Elasticsearch还提供了更多聚合类型,如Geo Distance(地理距离聚合)、Date Range(日期范围聚合)、Filter(过滤聚合)等。
聚合参数(agg_parameters)
在Elasticsearch中,聚合(aggregation)可以使用不同的参数来控制其行为和结果。以下是一些常用的聚合参数:
1. field(字段):指定要聚合的字段。
2. size(大小):限制返回的聚合桶的数量。
3. script(脚本):使用脚本定义聚合逻辑。
4. min_doc_count(最小文档数量):指定聚合桶中文档的最小数量要求。
5. order(排序):按照指定字段对聚合桶进行排序。
6. include/exclude(包含/排除):根据指定的条件包含或排除聚合桶。
7. format(格式):对聚合结果进行格式化。
8. precision_threshold(精度阈值):用于基数聚合的精度控制。
9. interval(间隔):用于日期直方图聚合的时间间隔设置。
10. range(范围):用于范围聚合的范围定义。
具体可用的参数取决于聚合类型和使用的Elasticsearch版本。
DSL查询实践
准备工具: Kibana或者Elasticvue
在这里,我使用Elasticvue
网址:Elasticvue - Elasticsearch gui for the browser
这个工具我是装在火狐上的,连接上后能看到节点信息、集群健康、索引信息等等,也支持REST查询,类似在Kibana使用Devtools差不多。
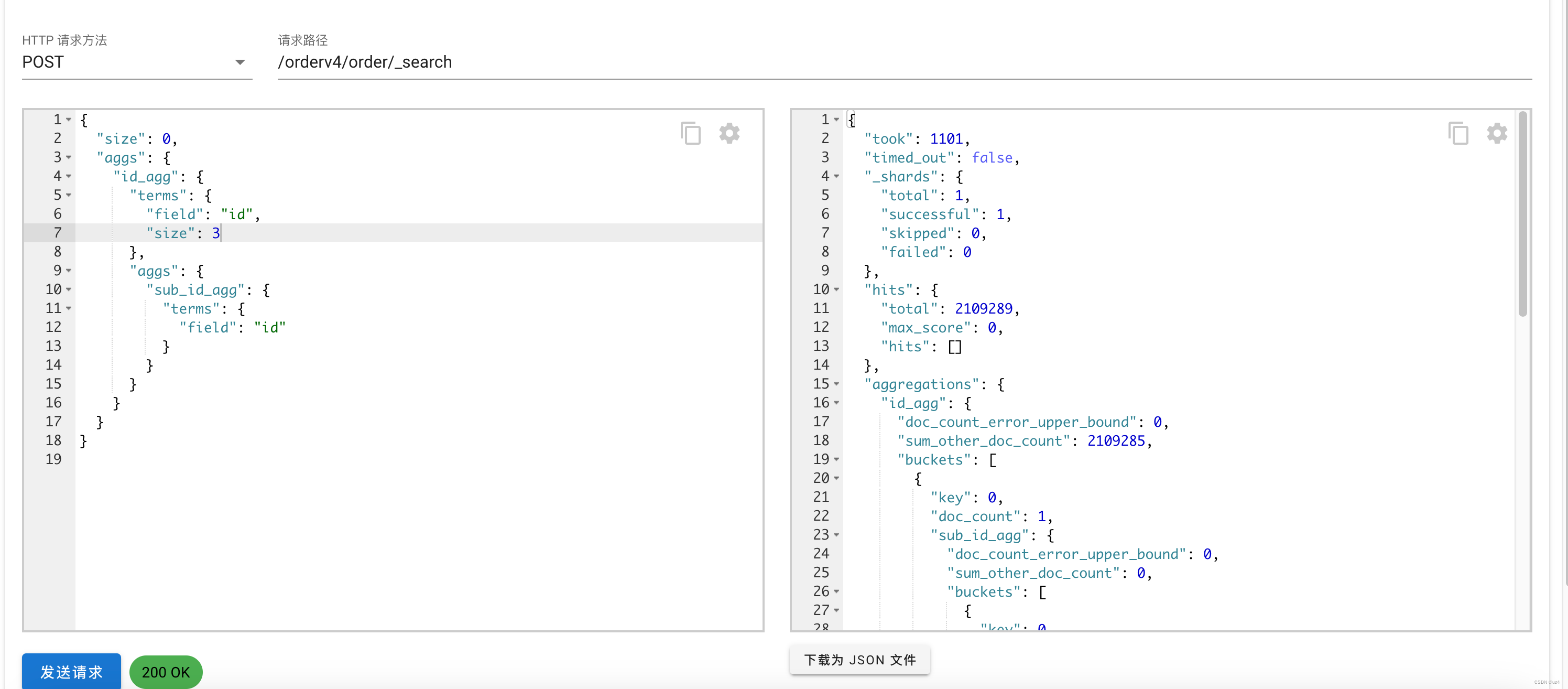
单个分组DSL查询, 求分组后的平均值
{
"size": 0,
"aggs": {
"id_agg": {
"terms": {
"field": "id",
"size": 3 #在有的情况下,如果你的文档数量太多,会导致查询超时、返回数据过多的问题
},
"aggs": {
"sub_id_agg": {
"terms": { #匹配搜索
"field": "id"
}
}
}
}
}
}
这张图上面有几个关键信息
`/orderv4/order/_search` 是一个 Elasticsearch 的 REST API 端点,用于执行针对名为 `order` 的索引的搜索操作。
- /orderv4/order: 表示索引的名称是 `orderv4`,类型(Type)的名称是 `order`。
- 在较新的 Elasticsearch 版本中,类型的概念已经逐渐被弃用,因此索引名称后面的 `/order` 可以省略。
- _search: 表示执行搜索操作。
左侧是DSL请求体,右边是返回结果
took: 执行搜索的时间,单位是毫秒
timed_out:搜索是否超时
_shards:分片执行情况,这里的total代表参与搜索的总分片数
hits:和搜索文档匹配的文档信息,total代表和搜索条件匹配的总文档数
aggregations:里面是聚合结果,id_agg是刚才在dsl查询的时候设置的聚合名称,sum_other_doc_count代表除了bucket里面的文档数量,还有多少条没有展示。buckets里面的key就是文档里面的id的值是多少,doc_count 表示文档数量,换句话来说就是,id = 0 的数量为 1
使用Java构建分组查询
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 添加聚合操作
TermsAggregationBuilder aggregationBuilder = AggregationBuilders.terms("id_agg").field("id");
aggregationBuilder.subAggregation(AggregationBuilders.terms("sub_id_agg").field("id"));
searchSourceBuilder.aggregation(aggregationBuilder);基于nested嵌套类型分组查询
nested(嵌套)是一种特殊的数据类型和查询方式,用于处理嵌套文档结构。它允许在文档中嵌套其他文档,并以一种有层次结构的方式进行索引和查询。
在使用nested查询的时候,先要对你的索引设置Mapping配置。把字段类型设置为nested。
一种是在建索引的时候,就配好Mapping,另外一种方式是直接对索引文档更新。
POST youer_index/_mapping/your_type
{
"properties":{
"item_list":{ # 在Java的ESDO模型里,就代表了一个List<Item>, Item是你自己定义的业务对象
"type":"nested", #给item_list设置嵌套类型
"properties":{
"id":{
"type":"long"
},
"name":{
"type":"string"
},
"price":{
"type":"long"
}
}
}
}
}nested字段DSL查询案例
{
"aggregations":{
"item_list_agg":{
"nested":{
"path":"item_list" # 字段路径必须,不然查不出结果
},
"aggs":{
"sub_item_list_agg":{
"terms":{
"field":"item_list.id"
}
}
}
}
}
}使用Java构建nested分组查询
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 添加聚合操作
AggregationBuilder nested = AggregationBuilders.nested("id_nested_agg", "item_list");
// 构建一个terms
TermsAggregationBuilder terms = AggregationBuilders.terms("id_nested_sub_agg").field("id");
// 将terms加到nested中
nested.subAggregation(terms);
// 添加到最终的查询中
searchSourceBuilder.aggregation(nested);更多的案例,如果有兴趣的朋友可以自己摸索。下面我就分享一个实战中,如何用Java针对普通字段类型和nested字段类型构建查询语句,同时支持返回多个字段值。
import com.github.houbb.heaven.util.lang.StringUtil;
import org.apache.commons.collections.CollectionUtils;
import org.elasticsearch.search.aggregations.AggregationBuilder;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
/**
* @author : kenny
* @since : 2023/5/18
**/
public class AggregationBuilderExample {
/**
* 构造一个单桶分组查询,支持普通字段类型和nested字段类型
* @param aggregationFields
* @return
*/
public static AggregationBuilder buildSingeBucketAggregationBuilder(List<String> aggregationFields) {
if (CollectionUtils.isEmpty(aggregationFields)) {
throw new RuntimeException("Aggregate search requires aggregate fields!");
}
aggregationFields = aggregationFields.stream().filter(StringUtil::isNotEmpty).collect(Collectors.toList());
String aggregationField = aggregationFields.get(0);
int dotIndex = aggregationField.indexOf(".");
AggregationBuilder aggregationBuilder;
if (dotIndex != -1) {
String path = aggregationField.substring(0, dotIndex);
aggregationBuilder = AggregationBuilders.nested(aggregationField + "nested_agg", path);
AggregationBuilder nestedTerms = AggregationBuilders.terms(aggregationField).field(aggregationField).size(1000);
aggregationBuilder = aggregationBuilder.subAggregation(nestedTerms);
}else {
aggregationBuilder = AggregationBuilders.terms(aggregationField + "_agg").field(aggregationField).size(1000);
}
return aggregationBuilder;
}
/**
* 构造一个多桶分组查询,支持普通字段类型和nested字段类型
* @param aggregationFields
* @return
*/
public static List<AggregationBuilder> buildMultiplexBucketAggregationBuilder(List<String> aggregationFields){
if (CollectionUtils.isEmpty(aggregationFields)) {
throw new RuntimeException("Aggregate search requires aggregate fields!");
}
aggregationFields = aggregationFields.stream().filter(StringUtil::isNotEmpty).collect(Collectors.toList());
List<AggregationBuilder> aggregations = new ArrayList<>();
for (String field : aggregationFields){
int dotIndex = field.indexOf(".");
AggregationBuilder aggregationBuilder;
if (dotIndex != -1) {
String path = field.substring(0, dotIndex);
aggregationBuilder = AggregationBuilders.nested(field + "_nested_agg", path);
AggregationBuilder nestedTerms = AggregationBuilders.terms(field).field(field).size(1000);
aggregationBuilder = aggregationBuilder.subAggregation(nestedTerms);
}else {
aggregationBuilder = AggregationBuilders.terms(field).field(field).size(1000);
}
aggregations.add(aggregationBuilder);
}
return aggregations;
}
}针对于结果的解析我们同样也构造一个解析方法
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* @author : kenny
* @since : 2023/5/18
**/
public class AggregationResultParserExample {
/**
* 针对单桶聚合统计
* @param json ES执行搜索之后返回的MetricAggregation信息
* @return
*/
public static Map<String, Integer> parseSingleBucketAggregations(String json) {
JSONObject jsonObject = JSONObject.parseObject(json);
if (jsonObject == null){
return null;
}
Map<String, Integer> resultMap = new HashMap<>();
try {
internal_ParseSingBucketAggregations(jsonObject, resultMap);
}catch (Exception ex){
// 处理你自己的异常
}
return resultMap;
}
private static void internal_ParseSingBucketAggregations(JSONObject jsonObject, Map<String, Integer> map) {
for (Map.Entry<String, Object> entry : jsonObject.entrySet()) {
String key = entry.getKey();
Object value = entry.getValue();
if (value instanceof JSONObject) {
JSONObject childObject = (JSONObject) value;
if (childObject.containsKey("key") && childObject.containsKey("doc_count")) {
String childKey = childObject.getJSONObject("key").getString("value");
int docCount = childObject.getJSONObject("doc_count").getIntValue("value");
map.put(childKey, docCount);
}
internal_ParseSingBucketAggregations(childObject, map);
} else if (value instanceof JSONArray) {
JSONArray childArray = (JSONArray) value;
for (Object element : childArray) {
if (element instanceof JSONObject) {
JSONObject childObject = (JSONObject) element;
internal_ParseSingBucketAggregations(childObject, map);
}
}
}
}
}
/**
* 解析多桶分组统计
* @param json ES执行搜索之后返回的MetricAggregation信息
* @return
*/
public static Map<String, List<Map<String, Object>>> parseMultiplexBucketAggregations(String json) {
JSONObject jsonRoot = JSONObject.parseObject(json);
if (jsonRoot == null){
return Collections.emptyMap();
}
Map<String, List<Map<String, Object>>> resultMap = new HashMap<>();
try {
internal_ParseMultiplexBucketAggregations(jsonRoot, "", resultMap);
}catch (Exception ex){
// 处理你自己的异常
}
return resultMap;
}
private static void internal_ParseMultiplexBucketAggregations(JSONObject jsonObject, String prefix, Map<String, List<Map<String, Object>>> resultMap) {
for (Map.Entry<String, Object> entry : jsonObject.entrySet()) {
String key = entry.getKey();
Object value = entry.getValue();
if (value instanceof JSONObject) {
JSONObject childObject = (JSONObject) value;
if (childObject.containsKey("buckets")) {
List<Map<String, Object>> bucketList = new ArrayList<>();
JSONArray buckets = childObject.getJSONObject("buckets").getJSONArray("elements");
for (int i = 0; i < buckets.size(); i++) {
JSONObject bucket = buckets.getJSONObject(i);
Map<String, Object> bucketMap = new HashMap<>();
JSONObject bucketMembers = bucket.getJSONObject("members");
for (Map.Entry<String, Object> bucketEntry : bucketMembers.entrySet()) {
String bucketKey = bucketEntry.getKey();
Object bucketValue = bucketEntry.getValue();
if (bucketValue instanceof JSONObject) {
JSONObject valueObject = (JSONObject) bucketValue;
if (valueObject.containsKey("value")) {
bucketMap.put(bucketKey, valueObject.get("value"));
}
}
}
bucketList.add(bucketMap);
}
resultMap.put(prefix + key, bucketList);
} else {
internal_ParseMultiplexBucketAggregations(childObject, prefix + key + "_", resultMap);
}
}
}
}
}














 1987
1987











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









