







 本文介绍了如何使用sklearn和Gensim库实现LDA主题模型,包括基础版的代码示例,参数解释,如n_topics、jieba分词应用,以及如何计算困惑度和使用pyLDAvis进行可视化。同时提到了补充版中的参数调优和Gensim库在英文文本处理上的优势。
本文介绍了如何使用sklearn和Gensim库实现LDA主题模型,包括基础版的代码示例,参数解释,如n_topics、jieba分词应用,以及如何计算困惑度和使用pyLDAvis进行可视化。同时提到了补充版中的参数调优和Gensim库在英文文本处理上的优势。
一、实用代码
实现LDA模型的库有:sklearn库的LaterntDirichleAllocation和Gensim库
(一)基础版
当前已运行的LDA模型是基于sklearn的LaterntDirichleAllocation实现的,参考的博文如下:
基于sklearn实现LDA主题模型(附实战案例)_sklearn lda-CSDN博客
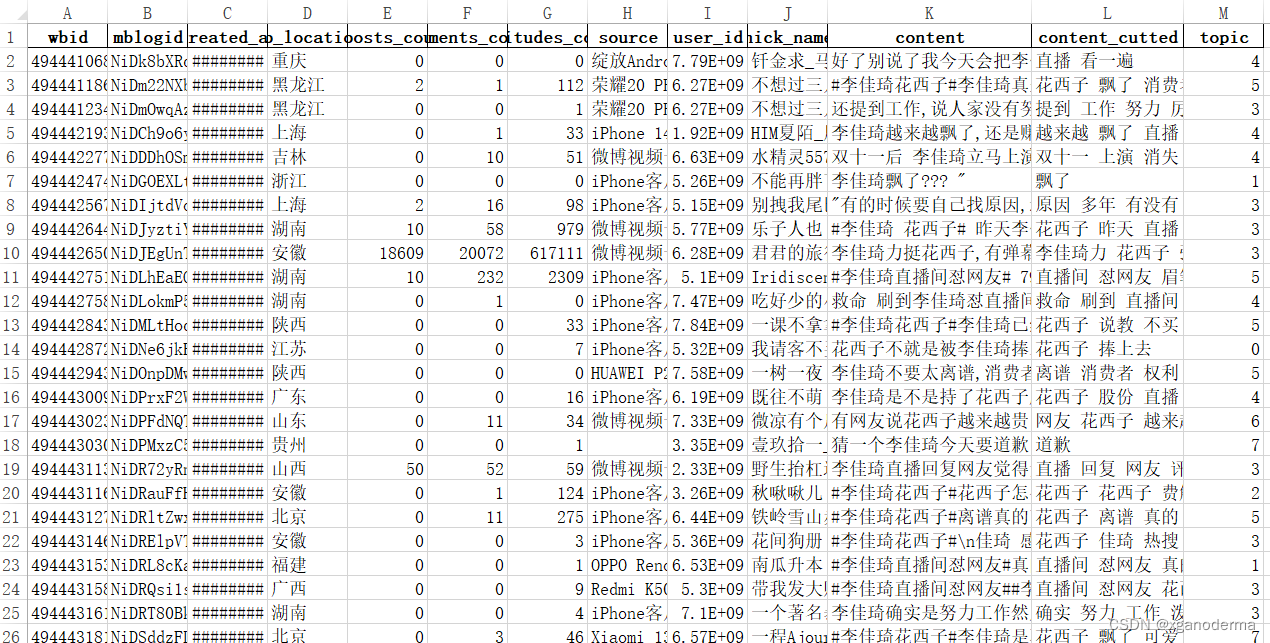
该代码能实现:以xlsx格式导入数据,选择基于其中例如“content”的一列文本进行主题聚类。运用jieba分词,可以添加txt格式的用户自定义的停用词表与用户词典。特征提取过程中,可设置特征词最低出现次数。模型建立采用LaterntDirichleAllocation公式,可设置每个主题打印出的特征词数量,各种参数意义见附录。实现pyLDAvis可视化及perplexity困惑度计算。具体结果如下:
1.下图所示结果是主题-特征词,但是不带分布概率

2.下图所示是输出的文档,带有分词结果及文档-主题映射,同样的问题也是不带分布概率
3.在实现主题建模后就可以用以下命令计算困惑度:
lda.perplexity(tf)获取当前困惑度,算出来的结果是370.8014436804044,收敛性不够好,还需继续训练。
4.pyLDAvis可视化结果,会在目录下生成一个html文件

使用pyLDAvis实现可视化的过程中需要注意“pyLDAvis.sklearn”已经更新为“pyLDAvis.lda_model”,要对应修改下面2、5行位置的代码:
import pyLDAvis
import pyLDAvis.lda_model
pyLDAvis.enable_notebook()
pic = pyLDAvis.lda_model.prepare(lda, tf, tf_vectorizer)
pyLDAvis.save_html(pic, 'lda_pass'+str(n_topics)+'.html') # 将可视化结果打包为html文件
pyLDAvis.show(pic,local=False)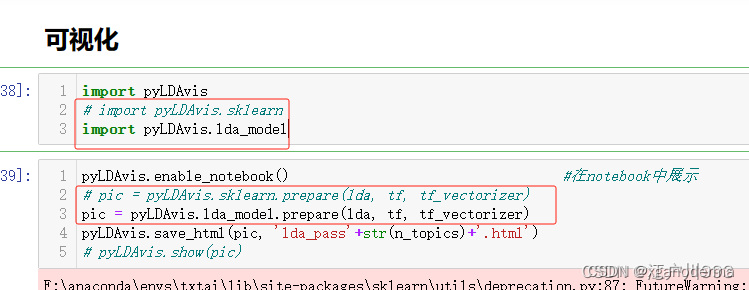
5.主题困惑度计算及手肘法图
(目前代码运行不出来)
困惑度可参考下文[有相应代码和原理]
折肘法+困惑度确定LDA主题模型的主题数_困惑度确定主题数-CSDN博客
(二)补充版
下面这篇文章涉及调参及分布概率,可作进一步研究:
【sklearn】利用sklearn训练LDA主题模型及调参详解_lda训练并使用-CSDN博客
下面这篇文章是使用Gensim库建立的LDA模型,核心包是re、gensim、spacy和pyLDAvis。此外,我们需要使用matplotlib、numpy和panases以进行数据处理和可视化。可以得到每个主题下关键词的分布概率,即权重。也可以得到气泡图可视化、困惑度、一致性分数。但是对英文文本进行的,分析中文文本需要修改。而且没有对文档的主题归类。
二、模型参数解释
(一)sklearn LDA API 中文解释
下面对LaterntDirichleAllocation相关的参数进行解释:
from sklearn.decomposition import LatentDirichletAllocation
n_topics = 8,
lda = LatentDirichletAllocation(n_components=n_topics, max_iter=50,
learning_method='batch',
learning_offset=50,
doc_topic_prior=0.1,
topic_word_prior=0.01,
random_state=666)
lda.fit(tf)
#Class sklearn.decomposition.LatentDirichletAllocation(n_topics=10, doc_topic_prior=None, topic_word_prior=None, learning_method=None, learning_decay=0.7, learning_offset=10.0, max_iter=10, batch_size=128, evaluate_every=-1, total_samples=1000000.0, perp_tol=0.1, mean_change_tol=0.001, max_doc_update_iter=100, n_jobs=1, verbose=0, random_state=None)参数:
1) n_topics: 即我们的隐含主题数K,需要调参。K的大小取决于我们对主题划分的需求,比如我们只需要类似区分是动物,植物,还是非生物这样的粗粒度需求,那么K值可以取的很小,个位数即可。如果我们的目标是类似区分不同的动物以及不同的植物,不同的非生物这样的细粒度需求,则K值需要取的很大,比如上千上万。此时要求我们的训练文档数量要非常的多。
2) doc_topic_prior:即我们的文档主题先验Dirichlet分布θd的参数α。一般如果我们没有主题分布的先验知识,可以使用默认值1/K。
3) topic_word_prior:即我们的主题词先验Dirichlet分布βk的参数η。一般如果我们没有主题分布的先验知识,可以使用默认值1/K。
4) learning_method: 即LDA的求解算法。有 ‘batch’ 和 ‘online’两种选择。 ‘batch’即我们在原理篇讲的变分推断EM算法,而”online”即在线变分推断EM算法,在”batch”的基础上引入了分步训练,将训练样本分批,逐步一批批的用样本更新主题词分布的算法。默认是”online”。选择了‘online’则我们可以在训练时使用partial_fit函数分布训练。不过在scikit-learn 0.20版本中默认算法会改回到”batch”。建议样本量不大只是用来学习的话用”batch”比较好,这样可以少很多参数要调。而样本太多太大的话,”online”则是首先了。
5)learning_decay:仅仅在算法使用”online”时有意义,取值最好在(0.5, 1.0],以保证”online”算法渐进的收敛。主要控制”online”算法的学习率,默认是0.7。一般不用修改这个参数。
6)learning_offset:仅仅在算法使用”online”时有意义,取值要大于1。用来减小前面训练样本批次对最终模型的影响。
7)max_iter :EM算法的最大迭代次数。
8)total_samples:仅仅在算法使用”online”时有意义, 即分步训练时每一批文档样本的数量。在使用partial_fit函数时需要。
9)batch_size: 仅仅在算法使用”online”时有意义, 即每次EM算法迭代时使用的文档样本的数量。
10)mean_change_tol :即E步更新变分参数的阈值,所有变分参数更新小于阈值则E步结束,转入M步。一般不用修改默认值。
11) max_doc_update_iter: 即E步更新变分参数的最大迭代次数,如果E步迭代次数达到阈值,则转入M步。
方法:
1)fit(X[, y]):利用训练数据训练模型,输入的X为文本词频统计矩阵。
2)fit_transform(X[, y]):利用训练数据训练模型,并返回训练数据的主题分布。
3)get_params([deep]):获取参数
4)partial_fit(X[, y]):利用小batch数据进行Online方式的模型训练。
5)perplexity(X[, doc_topic_distr, sub_sampling]):计算X数据的approximate perplexity。
6)score(X[, y]):计算approximate log-likelihood。
7)set_params(**params):设置参数。
8)transform(X):利用已有模型得到语料X中每篇文档的主题分布。
(二)Gensim LDA API 中文解释
下面对gensim.models.ldamodel.LdaModel相关的参数进行解释:
# Build LDA model
lda_model = gensim.models.ldamodel.LdaModel(corpus=corpus,
id2word=id2word,
num_topics=20,
random_state=100,
update_every=1,
chunksize=100,
passes=10,
alpha='auto',
per_word_topics=True)参数:
1)num_topics :需要预先定义的主题数量;
2)chunksize :每个训练块(training chunk)中要使用的文档数量;
3)alpha :影响主题稀疏性的超参数;
4)passess :训练评估的总数。
















 844
844











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









