







如果你正在考虑发表深度学习论文,强烈建议伙伴们关注一个当前炙手可热的方向:动态注意力机制!它在提升模型处理复杂数据的效率和准确性方面,发挥着不可或缺的作用,绝对是涨点的秘密武器!比如某新模型因引入动态注意力,其鲁棒性提升33%!
这一切的奥秘在于,动态注意力模块能够根据输入数据的内容和上下文,灵活地调整对不同信息部分的关注强度。这让模型得以更加专注于与任务相关的核心内容,轻松忽略那些次要信息,从而提升整体性能!
为帮助大家全面掌握这一方法并有效运用到自己的研究中,我准备了11种创新思路,包括:头部高斯自适应注意力机制GAAM、高斯自适应变换器GAT、PDFormer等。以下放出部分,全部论文PDF版+解析扫码gong重号【沃的顶会】 回复 11注意力 即可全部领取
Dynamic Attentive Graph Learning for Image Restoration
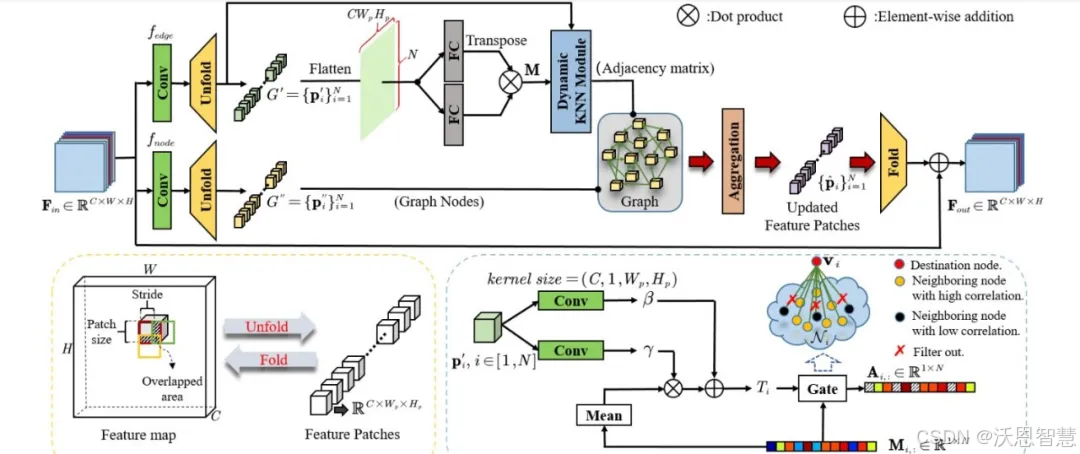
本文提出了一种动态注意图学习模型(DAGL)来探索图像恢复块级别的动态非局部属性。具体来说,作者提出了一种改进的图模型,以对每个节点具有动态和自适应数量的邻居执行逐块图卷积。通过这种方式,图像内容可以通过其连接的邻域的数量自适应地平衡过度平滑和过度锐化的伪影,并且块方式的非局部相关性可以增强消息传递过程。
创新点
1.提出了一种创新的改进图注意力模型专门用于图像修复。与以往的非局部图像修复方法相比,这一模型能够为每个查询项动态分配邻居数量,并基于特征块来构建长程相关性,从而实现更加精细和高效的修复效果。
2.提出的动态注意力图学习方法不仅适用于图像修复,还可以轻松扩展到其他计算机视觉任务,为未来的研究打开了广阔的可能性。
Improving the Robustness of Transformer-based Large Language Models with Dynamic Attention
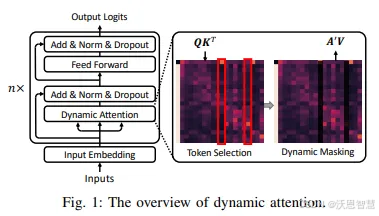
本文中,作者提出了一种名为动态注意力的新方法,用于提高基于Transformer的大型语言模型的鲁棒性,以抵御文本对抗性攻击。动态注意力包括注意力修正和动态建模两个模块,可以与下游任务无关,且不需要额外的成本。该方法通过动态注意力机制显著提高了对抗性攻击的影响,与以前的方法相比提高了最多33%。
创新点
1.提出一种创新的动态注意力机制,它对关键的注意力机制进行了改进,有效减弱对抗样本对输出结果的影响,让模型在无需依赖先验知识的情况下提升了鲁棒性。
2.此方法与多种Transformer架构兼容,包括仅包含编码器的模型、仅包含解码器的模型以及经典的编码-解码模型。
全部论文PDF版+解析扫码gong重号【沃的顶会】 回复 11注意力 即可全部领取
Gaussian Adaptive Attention is All You Need:Robust Contextual RepresentationsAcross Multiple Modalities
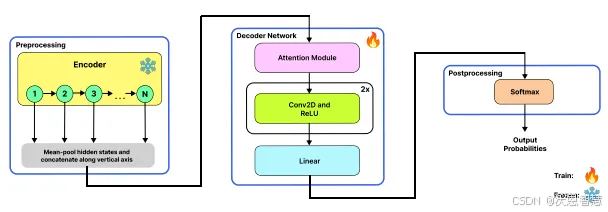
本文提出了一种新的注意力机制—多头部高斯自适应注意力机制(GAAM)和高斯自适应变换器(GAT),旨在提高多模态信息聚合的性能。
创新点
1.提出一种全新的注意力机制——多头部高斯自适应注意力机制,及相应的高斯自适应变换器。这一创新旨在显著提升多模态信息聚合的性能,让不同类型的数据能够更有效地融合,从而推动技术进步与应用拓展。
2.GAAM整合了可学习的均值和方差到注意力机制中,能够在多头部框架下集体模拟任何概率分布,动态重新校准特征重要性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









