










问题
英文
3. Longest Substring Without Repeating Characters
(无重复字符的最长子串)
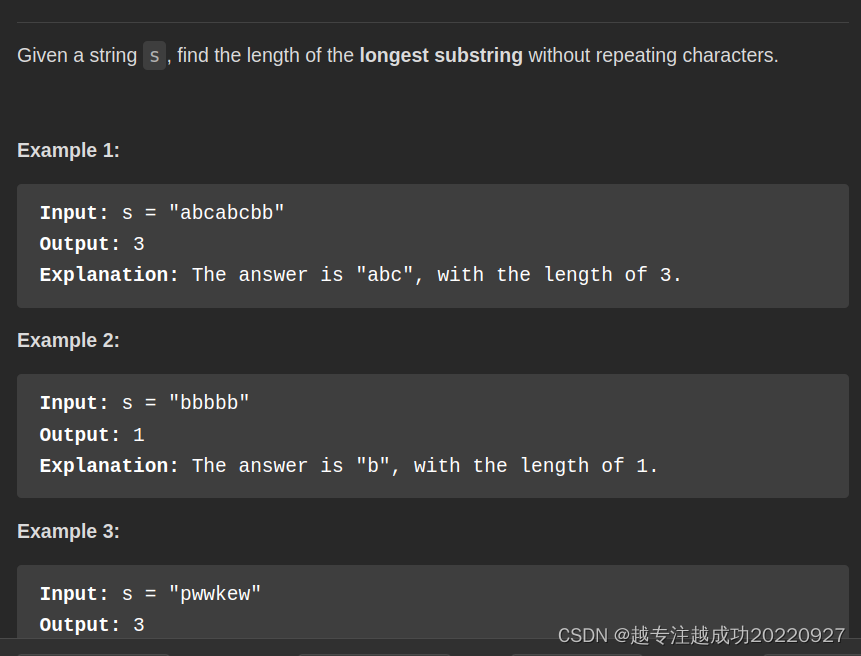
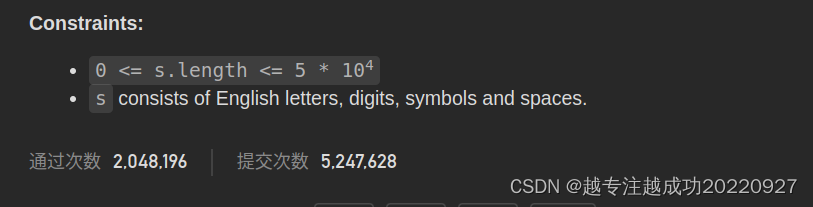
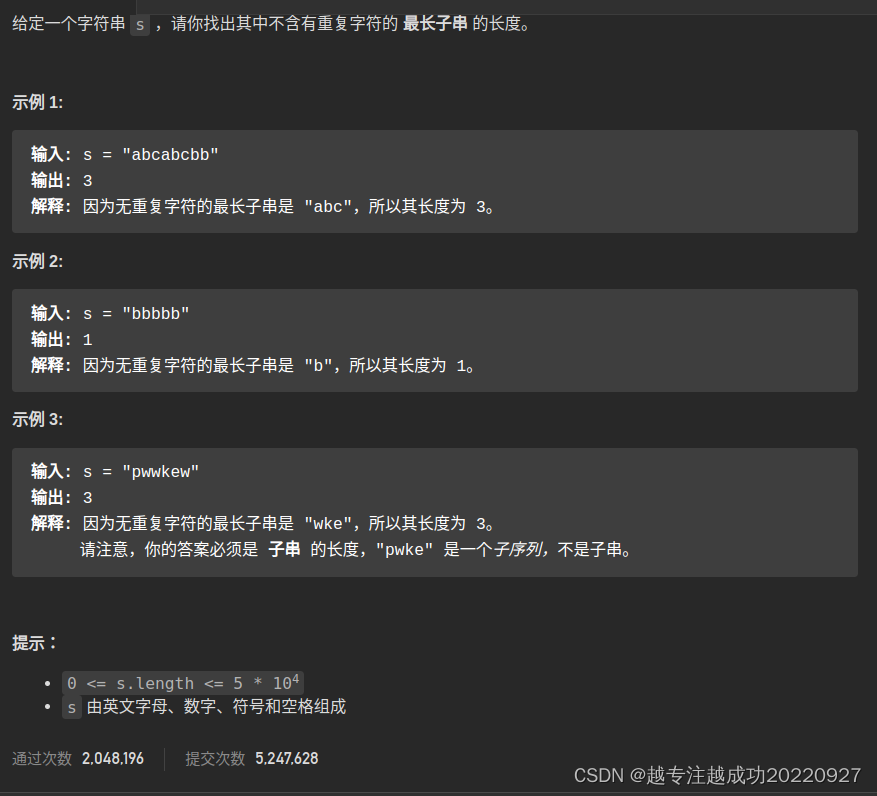
中文
代码
小白的码
#include <iostream>
#include <string>
#include <cstring>
using namespace std;
class SolutionAC {
public:
int lengthOfLongestSubstring(string s)
{
if (s == "")
return 0;
char sSubC[50010];
int arr[130]; // 统计滑动窗口中字符出现是否超过2
int memsize = sizeof(int) * 130;
memset(arr, 0, memsize);
int ssize = s.size();
int index = 0;
int len = 1;
int lentmp;
// int flag = 0; // 作为标记,用来标记是否需要减去多加的。(当前值已经开始重复了,但是被计算在 lentmp中,进而混进了len中
int i;
for (i = 0; i < ssize; i++)
{
arr[s[i]]++;
if (arr[s[i]] > 1)
{
lentmp = i - index; // 每次到临界点时,统计一下最大lentmp,再和len比较
if (lentmp > len) len = lentmp;
while (arr[s[i]] > 1) // 调整窗口,直到不含重复字符
{
index++;
arr[s[index - 1]]--;
}
}
}
lentmp = i - index; // 最后一次统计的lentmp(针对abcdeg.....)
if (lentmp > len) len = lentmp;
return len;
}
};
class SolutionTimeLimitExceeded // 遍历,超时
{
public:
int lengthOfLongestSubstring(string s)
{
if (s == "")
return 0;
int arr[130];
int len = 1;
// int subSize;
int a;
int flag;
char sSubC[50010]; // 用个字符数组来存子串
int ssize = s.size();
int memsize = sizeof(int) * 130;
// int eor = 0;
for (int i = 0; i < ssize; i++)
{
for (int j = len + 1; j <= ssize - i; j++)
{
// cout << s.substr(i, j) << endl;
memset(arr, 0, memsize);
strcpy(sSubC, s.substr(i, j).c_str()); // c_str
flag = 1; // 没有重复字符
// subSize = sSubC.size();
for (int k = 0; k < j; k++)
{
a = sSubC[k];
arr[a]++;
if (arr[a] > 1)
{
flag = 0;
// cout <<"a = " << a << " " << arr[a] << endl;
break;
}
}
if (flag == 1)
{
len = j;
}
}
}
return len;
}
};
int main()
{
string str;
Solution sol;
cin >> str;
cout << sol.lengthOfLongestSubstring(str) << endl;
return 0;
}
大佬的码
class Solution {
public:
int lengthOfLongestSubstring(string s) {
// 哈希集合,记录每个字符是否出现过
unordered_set<char> occ; // occurence 出现
int n = s.size();
// 右指针,初始值为 -1,相当于我们在字符串的左边界的左侧,还没有开始移动
int righPtr = -1, ans = 0;
// 枚举右指针的位置,初始值隐性地表示为 -1
for (int i = 0; i < n; ++i) {
if (i != 0) {
// 指针向右移动一格,移除一个字符(尝试移除重复的字符,直到删除为止,不然进不去下面的 while循环)
occ.erase(s[i - 1]);
}
while (righPtr + 1 < n && !occ.count(s[righPtr + 1])) { // 当哈希集合没有当点指针所指的字符时
// 不断地移动右指针
occ.insert(s[righPtr + 1]);
++righPtr;
}
// 第 i 到 righPtr 个字符是一个无重复字符的子串
ans = max(ans, righPtr + 1 -i);
}
return ans;
}
};
知识点
unordered_set 容器具有以下几个特性:
不再以键值对的形式存储数据,而是直接存储数据的值;
容器内部存储的各个元素的值都互不相等,且不能被修改。
不会对内部存储的数据进行排序
(这和该容器底层采用哈希表结构存储数据有关,
template < class Key,
class Hash = hash<Key>,
class Pred = equal_to<Key>,
class Alloc = allocator<Key> > class unordered_set;
C++ 11中对unordered_set描述大体如下:
无序集合容器(unordered_set)是一个存储唯一
(unique,即无重复)的关联容器(Associative container),
容器中的元素无特别的秩序关系,该容器允许基于值的快速元素检索,
同时也支持正向迭代。
在一个unordered_set内部,元素不会按任何顺序排序,
而是通过元素值的hash值将元素分组放置到各个槽(Bucker,也可以译为“桶”),
这样就能通过元素值快速访问各个对应的元素(均摊耗时为O(1))。
原型中的Key代表要存储的类型,
而hash<Key>也就是你的hash函数,
equal_to<Key>用来判断两个元素是否相等,
allocator<Key>是内存的分配策略。
我们就可以使用「滑动窗口」来解决这个问题:
我们使用两个指针表示字符串中的某个子串(或窗口)的左右边界,
其中左指针代表着「枚举子串的起始位置」,而右指针即为用来向右移动到下一项
在每一步的操作中,当我们将左指针向右移动一格,表示
我们开始枚举下一个字符作为起始位置,然后我们可以不断地向右移动右指针,
但需要保证这两个指针对应的子串中没有重复的字符。
在移动结束后,这个子串就对应着
以左指针开始的,不包含重复字符的最长子串。我们记录下这个子串的长度;
在枚举结束后,我们找到的最长的子串的长度即为答案。
总结
多思考,多动手,多学习!感受生活的充实!
我是用的滑动窗口的思路,代码实现是用 一个含130个整型值的数组对应字符的ASCII 码,来统计字串中是否出现重复的字符,更简单一些!!!
思路大体一致,很明显,自己还有很多很多提升改进的地方!!路漫漫!!!















 178
178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









