






后面会持续更新,目前只总结到这里
目前已经更新:
当前:计算机网络-----面试知识总结二
如何理解TCP是面向字节流的而UDP是面向报文的
首先对于UDP来说UDP只是对上层的消息进行添加UDP请求头来封装成一个UDP报文的,一个UDP就对应一个完整的用户消息,所以接收方在接收到UDP报文之后就能取出对应的用户消息,接收方接收消息是通过操作系统中有一个UDP的队列,接收到消息放在队列尾部然后会从头部以此取出UDP报文
对于TCP来说TCP也是传输层的协议,会对上一层的报文进行分段住处理支持超市重传、流量控制、用塞避免、以及解决了可以解决糊涂窗口综合症等,使得存在粘包问题(一个TCP报文中可能出现多个消息的内容),解决粘包问题常用的有三种方法
- 固定TCP消息的长度使得一个TCP也能作为一个完整的消息,缺点就是不灵活,比如我定义TCp长度为64字节,那如果消息长度超过了,那就得重新定义了
- 自定义结构体,结构体包含消息长度以及对应的消息

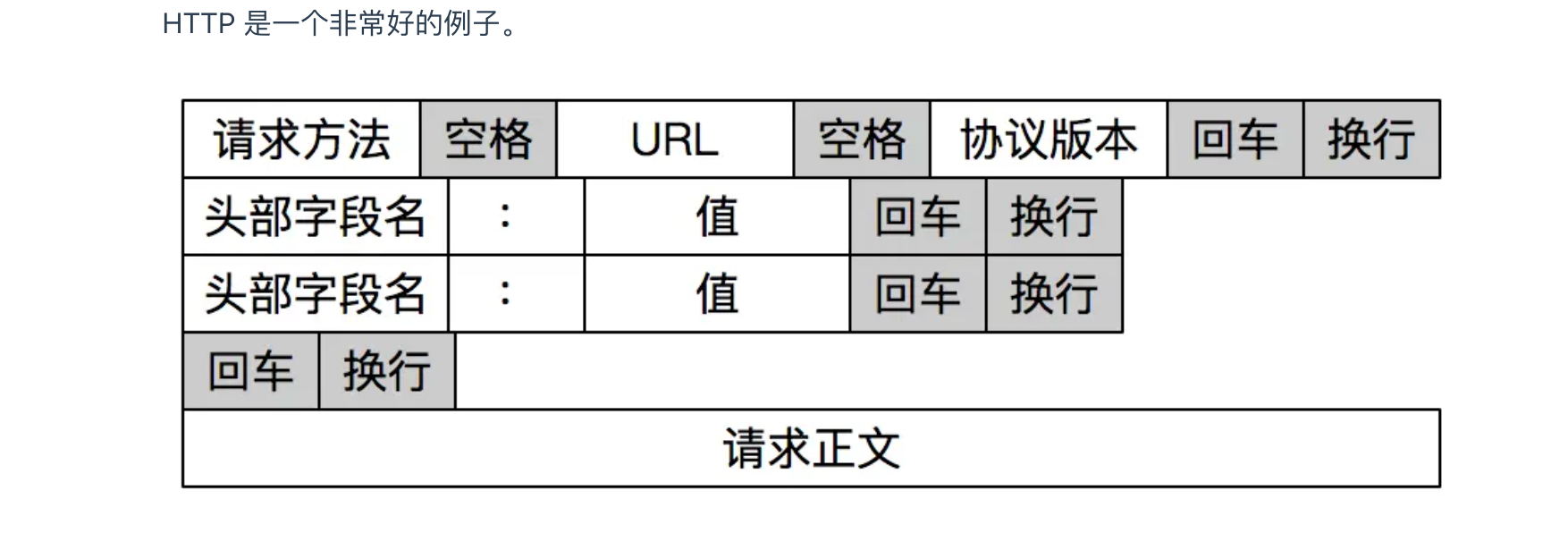
- 使用特殊字符作为标识符,比如HTTP中使用空格+回车表示边界
UDP怎么实现可靠传输
总述
UDP是通过QUICK协议来实现可靠的传输的,UDP+QUICK完成传输是真正意义上的解决了对头阻塞问题,并且可以实现流量控制以及用塞避免等
对于解决对头阻塞是通过,每个Stream都有自己的一个滑动窗口,彼此窗口之间相互不影响,所以当某个Stream阻塞也只会影响本Stream对其他的没影响,
而对于流量控制来说,QUICK氛围了两个力度,一个细粒度的控制及Stream级别的滑动窗口,一个粗粒度的控制Connection级别的流量控制(即所有Stream总汇的窗口)
如何解决对头阻塞
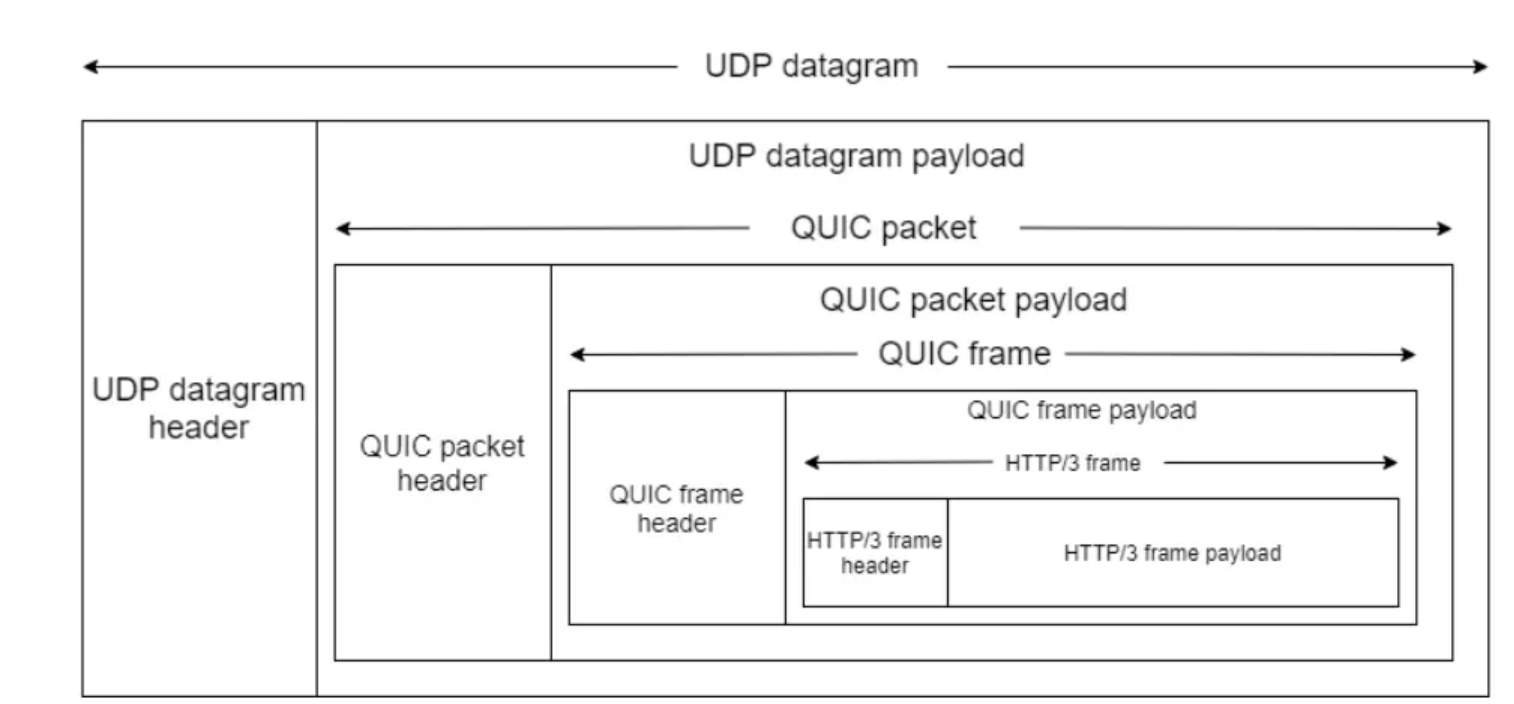
首先来看看UDP+QICK协议对应的格式
QUIC packet header
对于外层的QUIC packet header格式
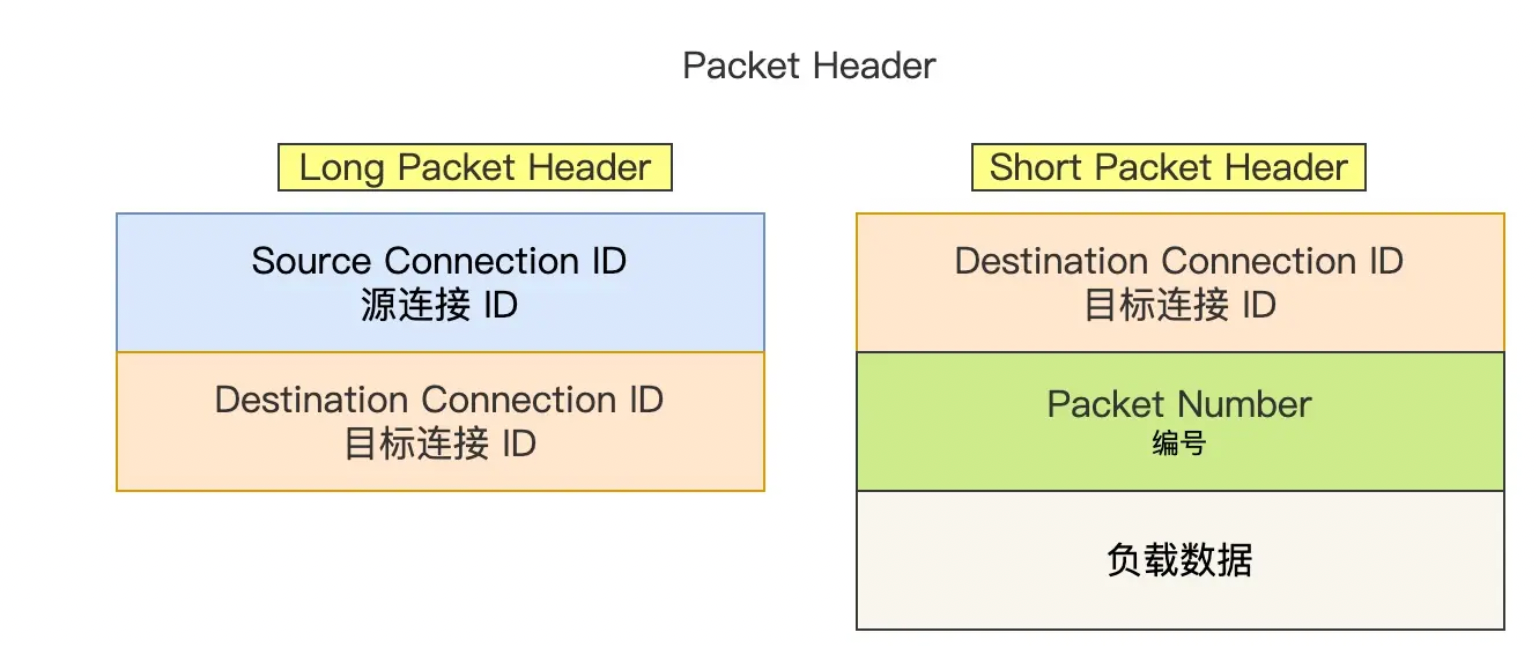
之所以有这两两种格式其作用是不同的
对于
- Long Packet Header来说主要是用来首次建立连接所用,用来记录原链接ID,以及目标连接ID
- Short Packet Header来收就是建立好连接后的数据传输所用,有三个属性,一个目的连接ID,包编号(每一个包编号是严格递增的,就算是超时重传同样的包的包ID也是递增的,接收单依靠下内部Frame格式中的Stream ID+Offset偏移量来唯一确定某个包资源),第三个属性就是对应携带的数据,负载数据就是内层QUICK frame的内容了
注意这里包ID严格递增的作用如下:
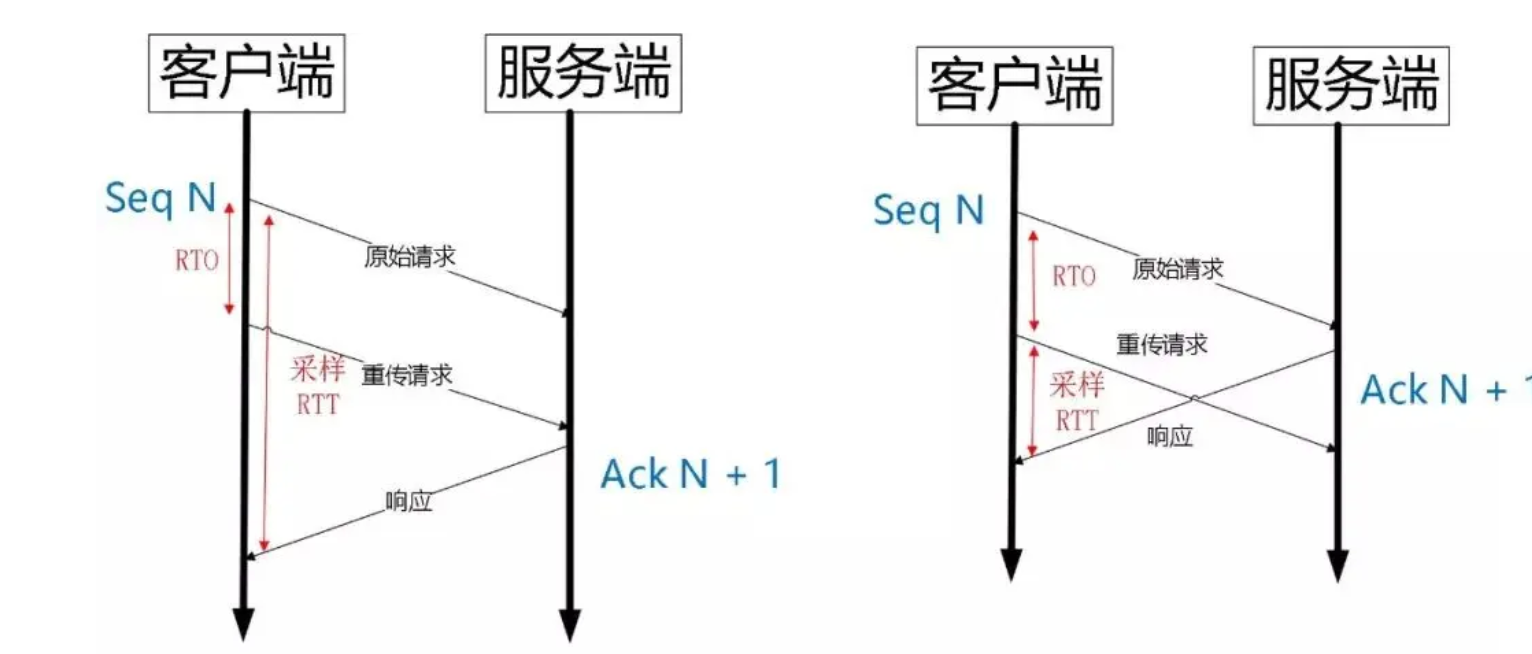
- 因为是使用UDP+UQUIC来实现可靠传输,那么同样要具有超时重传等功能,使用递增的包ID可以准确的确认RTT时间,因为对于TCP来说当遇到超时重传时,由于重传的序列号是一样的,因此在接收到回复的ack时不知道这个响应是一开始的请求还是重传的请求,那么计算往返时间RTT时就不准确,而重传时间RTO是根据RTT来计算的,所以回影响超时时间,从而对整个超时重传产生影响,而使用递增的包ID后,对于每个请求都有一个唯一的表示,就算是重传的包的包ID也是递增的,因此在进行ack的时候就能准确计算RTT
- 由于包ID的递增设计,就可以让数据包不再像TCP那样进行顺序确认,可以进行乱序确认,当数据包Packet N丢失后,只要有新的已接受的数据,当前窗口就会继续往后移动,即后面的数据也会进行ack,当进行重传将丢失的包重新递增编号后进行重传ack后放在对应的窗口位置,这样就解决了对头阻塞问题
简单来说的话就是:
- 可以更加精确计算 RTT,没有 TCP 重传的歧义性问题;
- 可以支持乱序确认,因为丢包重传将当前窗口阻塞在原地,而 TCP 必须是顺序确认的,丢包时会导致窗口不滑动
QUIC Frame Header
一个packet可以对应多个 Frame包

我这里只举例 Stream 类型的 Frame 格式,Stream 可以认为就是一条 HTTP 请求,它长这样:
简单来说一个外层 QUIC Packet 的负载对应多个QUIC Frame,每一个 Frame 都有明确的类型,针对类型的不同,功能也不同,自然格式也不同。比如常用的Stream格式,其中结合上面ack判断是否是同一个包就是根据Steam ID+Offset偏移字节(类似于tcp中的seq序号)
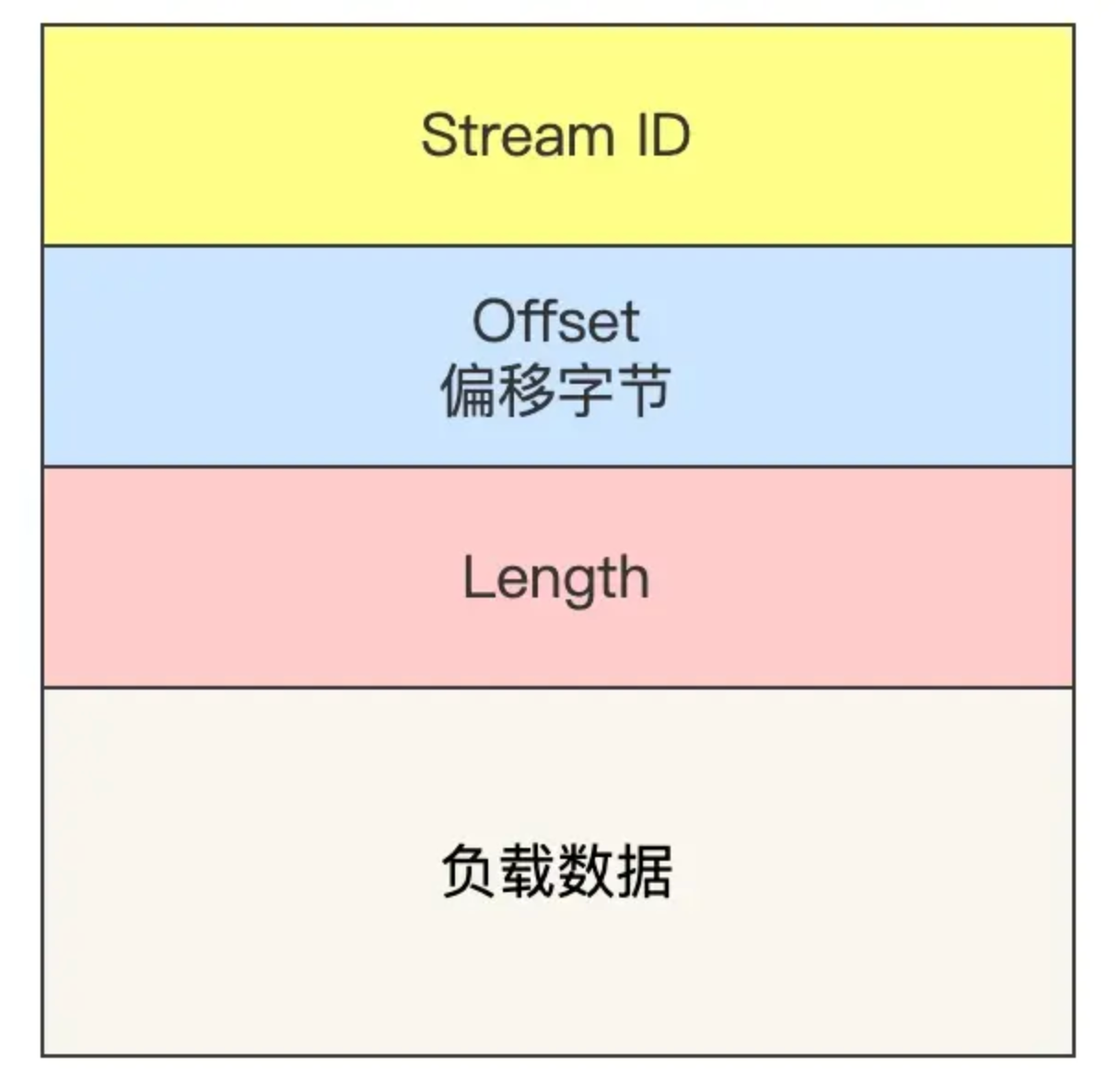
如何实现乱序确认ack
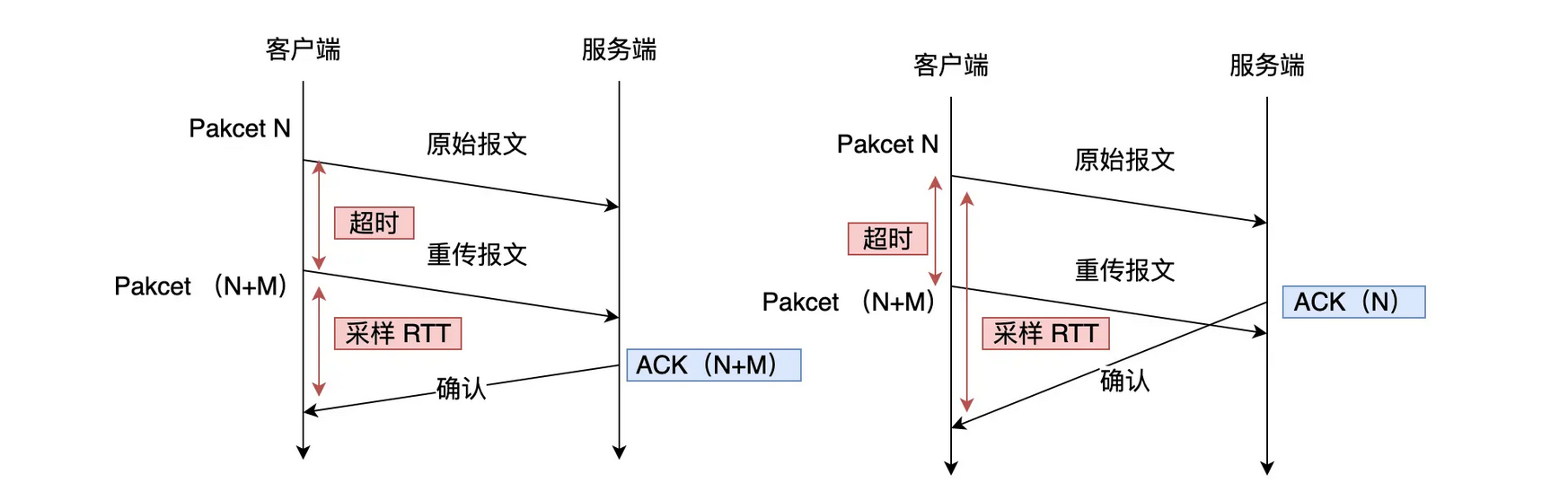
对于确认包资源来说对一一次传送的包资源是通过Stream ID+Offset来确认的,重传之后的外层包ID是递增的
对于TCP来说如果出现丢包,那么触发超时重传时必须等重传的资源到了,那么才能拿到下一次请求的序列号进行请求,而对于QUIC来说是通过Stream ID+Offset来保证顺序的
即总的来说,QUIC 通过单向递增的 Packet Number,配合 Stream ID 与 Offset 字段信息,可以支持乱序确认而不影响数据包的正确组装,摆脱了TCP 必须按顺序确认应答 ACK 的限制,解决了 TCP 因某个数据包重传而阻塞后续所有待发送数据包的问题。
如何解决对头阻塞
核心就是对于QUIC来说,由于每个Stream对应一个滑动窗口,然后每个窗口相互独立,因此当某个Stream发生阻塞,其他Stream也可正常工作,而只需要重传丢失的stream即可
首先看看TCP的对头阻塞:
TCP 队头阻塞的问题,其实就是接收窗口的队头阻塞问题。
接收方收到的数据范围必须在接收窗口范围内,如果收到超过接收窗口范围的数据,就会丢弃该数据,比如下图接收窗口的范围是 32 ~ 51 字节,如果收到第 52 字节以上数据都会被丢弃。
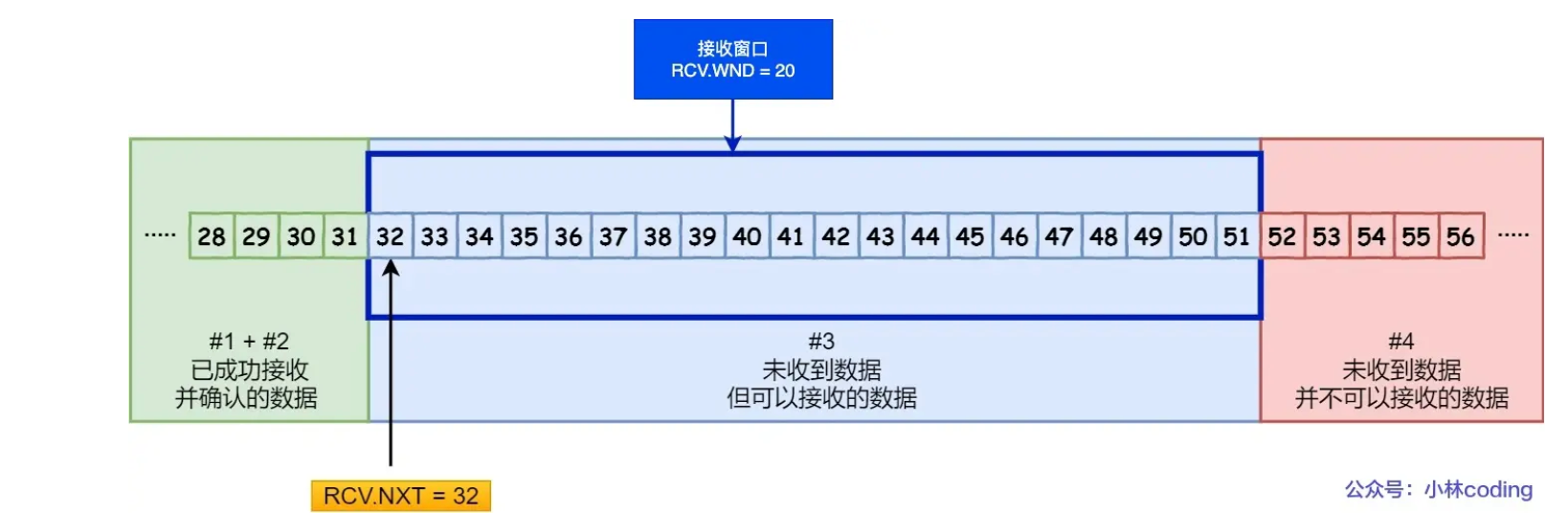
当窗口内前面的数据没有按序到达比如32,33没有到达,会导致导致接收窗口的队头阻塞问题,是因为 TCP 必须按序处理数据,也就是 TCP 层为了保证数据的有序性,只有在处理完有序的数据后,滑动窗口才能往前滑动,否则就停留,停留「接收窗口」会使得应用层无法读取新的数据。
HTTP中的队头阻塞:
- HTTP/2与TCP的关系:
- HTTP/2使用单个TCP连接来复用多个stream。每个stream都独立管理其帧(frame)的发送和接收,但所有这些帧都通过同一个TCP连接传输。
- 当TCP连接上的某个stream的数据包丢失时,TCP的重传机制会触发,而不是HTTP/2层。TCP不关心哪些数据属于哪个stream,它只关心序列号和数据完整性。
- 如果某个stream的数据包丢失,TCP会进行超时重传或快速重传(如果收到足够的重复ACK)。一旦丢失的数据包被重新传输并成功接收,TCP连接上的接收窗口可以继续向前移动,并且相应的ACK会被发送。
- 滑动窗口与ACK:
- TCP的滑动窗口机制用于流量控制和拥塞控制。窗口的滑动是基于数据的成功接收和ACK的发送。
- 如果某个stream的数据包丢失,但其他stream的数据正常传输,TCP的滑动窗口仍然会根据已接收的数据移动,并且ACK会基于已接收到的数据发送。丢失的数据包会在TCP的重传机制下被重新传输。
- 一旦丢失的数据包被成功接收,并且接收窗口允许,TCP会发送一个ACK来确认新的接收位置,并可能调整窗口大小以反映更多的接收空间。
怎么实现流量控制
QUIC 的 每个 Stream 都有各自的滑动窗口,不同 Stream 互相独立,队头的 Stream A 被阻塞后,不妨碍 StreamB、C的读取。而对于 HTTP/2 而言,所有的 Stream 都跑在一条 TCP 连接上,而这些 Stream 共享一个滑动窗口,因此同一个Connection内,Stream A 被阻塞后,StreamB、C 必须等待。
QUIC 实现了两种级别的流量控制,分别为 Stream 和 Connection 两种级别:
- Stream 级别的流量控制:Stream 可以认为就是一条 HTTP 请求,每个 Stream 都有独立的滑动窗口,所以每个 Stream 都可以做流量控制,防止单个 Stream 消耗连接(Connection)的全部接收缓冲。
- Connection 流量控制:限制连接中所有 Stream 相加起来的总字节数,防止发送方超过连接的缓冲容量。
对于Stream级别的流量控制
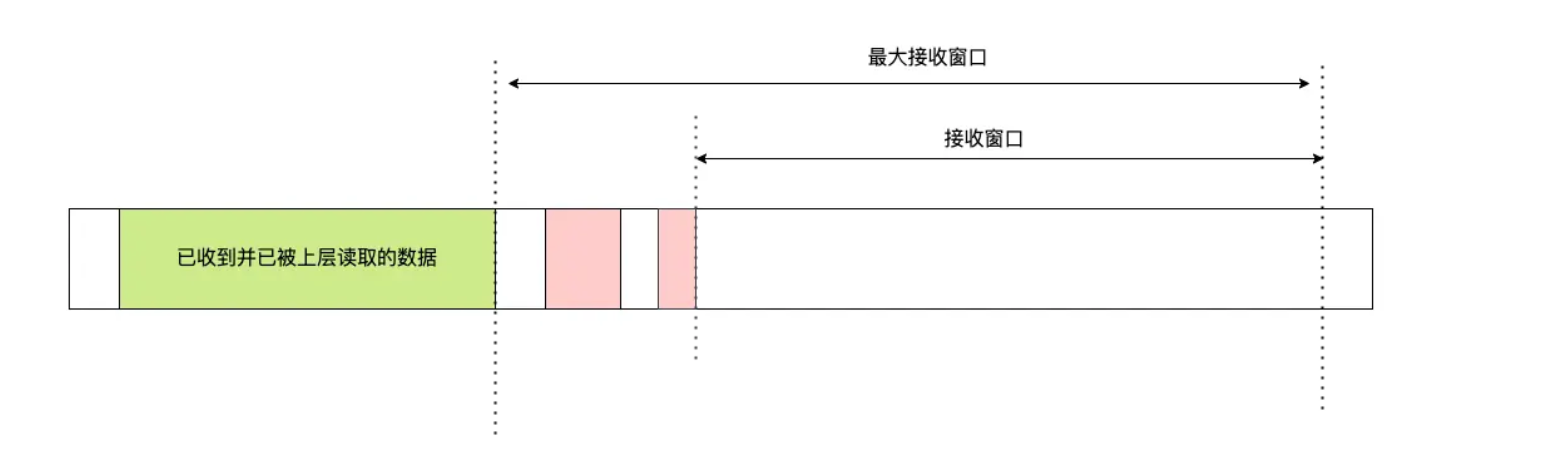
对应的窗口如下
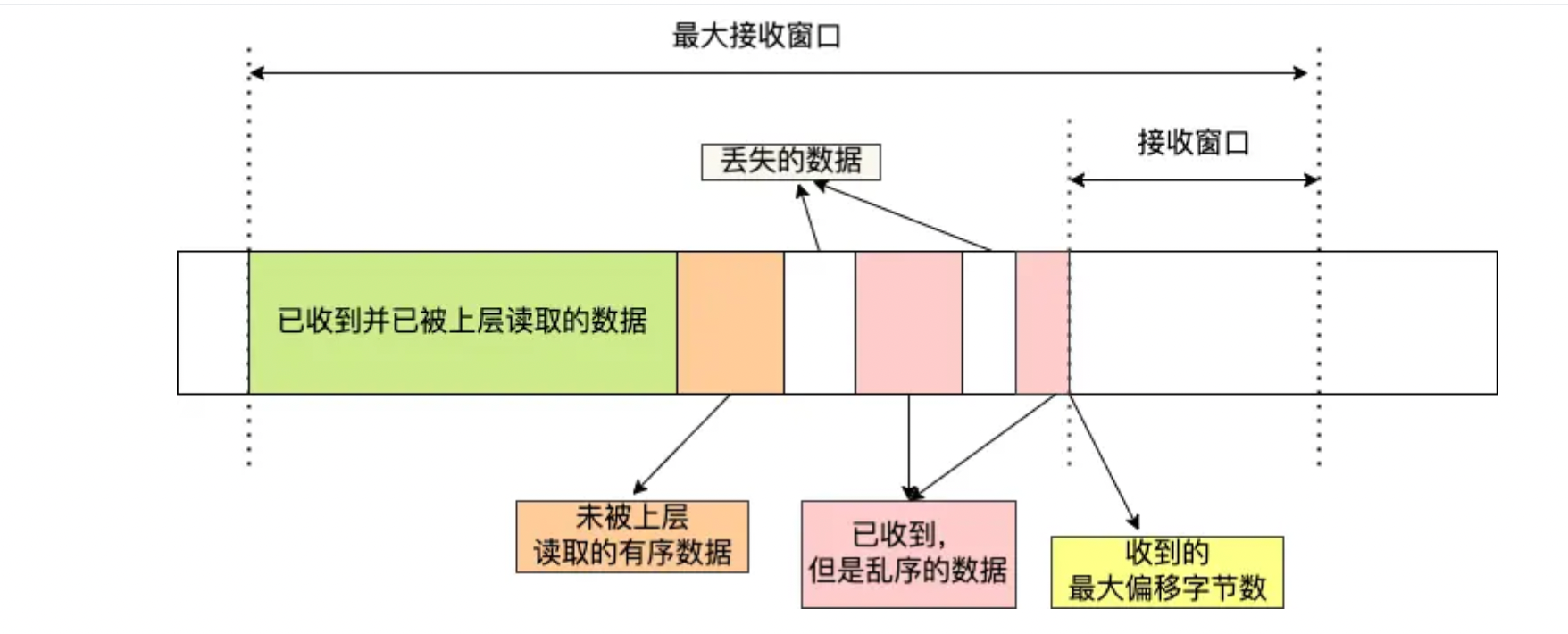
最大接收窗口中接受了对应数据后占用了对应的窗口位置,即上面的收到的最大便宜字节数,他不想tcp那样进行控制,将是移动窗口后再返回对应的接收窗口大小,而是返回当前剩余窗口大小即接收窗口 = 最大窗口数 - 接收到的最大偏移数。
当接收到已经被商城读取的数据大小达到了最大窗口的一般的时候就可以移动窗口了,如果说没有按序到达的超过了一般那么久不行进行滑动知道超时重传之后才能滑动窗口,但是这并不影响整体的,因为每个Stream有一个滑动窗口
Connection 流量控制
而对于 Connection 级别的流量窗口,其接收窗口大小就是各个 Stream 接收窗口大小之和。理解Connectioin级别就是对于Stream级别的窗口的一个总汇
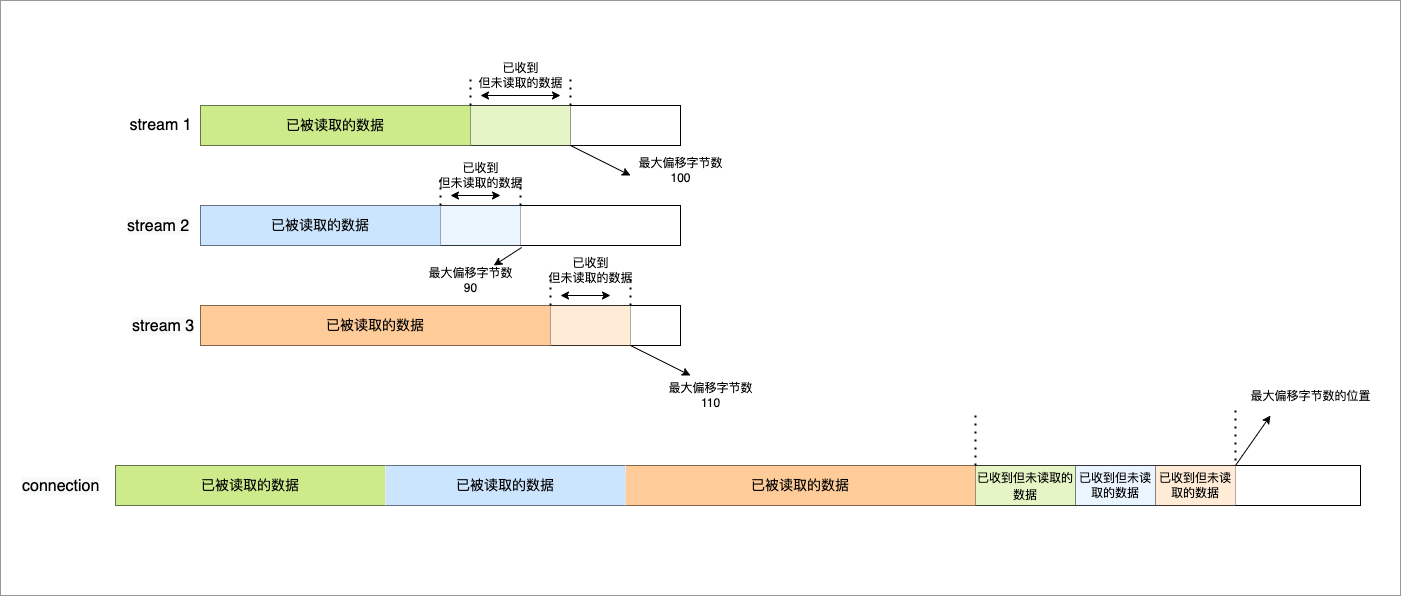
上图所示的例子,所有 Streams 的最大窗口数为 120,其中:
- Stream 1 的最大接收偏移为 100,可用窗口 = 120 - 100 = 20
- Stream 2 的最大接收偏移为 90,可用窗口 = 120 - 90 = 30
- Stream 3 的最大接收偏移为 110,可用窗口 = 120 - 110 = 10
那么整个 Connection 的可用窗口 = 20 + 30 + 10 = 60
QUIC 对拥塞控制改进
QUIC 协议当前默认使用了 TCP 的 Cubic 拥塞控制算法(我们熟知的慢开始、拥塞避免、快重传、快恢复策略),同时也支持 CubicBytes、Reno、RenoBytes、BBR、PCC 等拥塞控制算法,相当于将 TCP 的拥塞控制算法照搬过来了。
QUIC 是如何改进 TCP 的拥塞控制算法的呢?
主要原因是:QUIC 是处于应用层的,应用程序层面就能实现不同的拥塞控制算法,不需要操作系统,不需要内核支持。
传统的 TCP 拥塞控制,必须要端到端的网络协议栈支持,才能实现控制效果。而内核和操作系统的部署成本非常高,升级周期很长,所以 TCP 拥塞控制算法迭代速度是很慢的。而ß
TCP 更改拥塞控制算法是对系统中所有应用都生效,无法根据不同应用设定不同的拥塞控制策略。但是因为 QUIC 处于应用层,所以就可以针对不同的应用设置不同的拥塞控制算法,这样灵活性就很高了。
注意我都是对小林coding上的知识进行学习总结的大家想要详细学习可以去小林coding进行学习
参考博客(小林coding):4.6 如何理解是 TCP 面向字节流协议? | 小林coding















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









